



注:部分代码演示如果因长度问题观看不便利,可粘贴到idea中观看
一、集合框架体系
1、数组:存储多个数据的容器
(1)数组长度是固定的 int[] arr = new int[4];
(2)数组只能存储同一种类型,比如上面的数组就只能存储int类型的数据
(3)数组用法单一,只能通过下标取值赋值
(4)数组内元素可以重复
(5)数组元素有顺序(存值时的顺序)
public class Demo1 {
public static void main(String[] args) {
Collection<String> strs = new ArrayList<>();
strs.add("狗蛋");
strs.add("狗蛋1");
strs.add("狗蛋2");
System.out.println(strs);
}
}
2、集合(collection):存储多个数据容器,用于开发!
(1)集合长度不固定
(2)集合可以存储不同类型,但是!一般开发种必须是同一个类型的数据!
(3)集合是一系列的类,可以创建对象,有丰富的方法可以操作数据
(4)有些集合可以重复(list),有些集合不允许重复(set),有些集合有序的(List),有些集合是无序的(HashSet),而且有些集合还会排序(TreeSet)
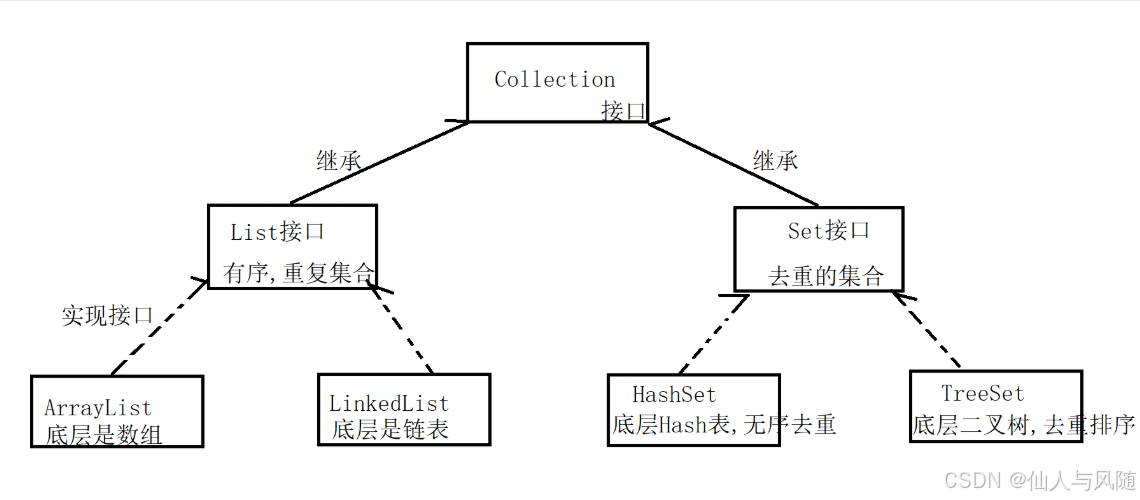
(1)Collection是集合层次的父接口,定义了所有集合共性操作
(2)Collection有两个常用子接口:List,Set
(3)List接口集合,主要特征是有序,允许重复元素的集合【记住】
(4)Set接口集合,主要特征是元素去重【记住】
(5)List接口有两个常用实现类
ArrayList,底层是数组,也是允许元素重复,数据有序
LinkedList,底层是链表,也是允许元素重复,数据有序
(6)Set接口有两个常用实现类
HashSet,底层是hash表,存储的元素无序且去重
TreeSet,底层是二叉树,存储的元素是排序且去重
二、Collection、list介绍
1、Collection父接口
定义了一部分集合的共性操作,并不完整
2、List是Collection的子接口,有序允许重复的集合
(1)定义了一些方法,可以对位置进行精准控制
(2)即可以按照下标插入、删除、查询、修改集合元素
3、List是接口,不能直接用,常使用其子实现类Arraylist和linkedlist
三、ArrayList
1、方法演示
public class Demo1 {
public static void main(String[] args) {
//创建一个空的集合
//List<String> list1 = new ArrayList<>();
List list = new ArrayList();
//list集合容器没有带泛型的,就是没有对数据进行约束!!!
System.out.println(list);//[]
//向空的集合中添加数据
//1.有序的(按照添加的顺序来的!!!)2.可重复的
list.add("张三");
list.add(23.4);
list.add(true);
list.add('男');
list.add("张三");
System.out.println("添加值以后的数据:" + list);
//2.还可以指定插入数据
list.add(2, "李四");
System.out.println("中间插入的数据是:" + list);//中间插入的数据是:[张三, 23.4, 李四, true, 男, 张三]
//3.获取指定下标的元素
Object o = list.get(0);
String st = (String)o;
System.out.println(st);
//所以发现特别扯犊子!!!不用!!! 用泛型!
//4.按照下标修改元素
list.set(0, "狗蛋");
System.out.println(list);//[狗蛋, 23.4, 李四, true, 男, 张三]
//5.按照下标删除元素
list.remove(1);
System.out.println(list);//[狗蛋, 李四, true, 男, 张三]
}
}
2、泛型
public class Demo2 {
public static void main(String[] args) {
/**
* 集合确实可以允许存储不同类型数据
* 但是大部分情况下,集合只会存储同一类型
* -----------
* 目前这种情况,设计时存储的是Object
* 取出数据也是Object,需要使用对应数据类型时需要强转
* 但是强制转换有风险
* ---------------------
* 所以,在JDK1.5时引入泛型 ,通过泛型就可以解决这个问题
*/
//开发就这样用的!!!
List<Integer> list = new ArrayList<>();
list.add(23);
list.add(23);
list.add(23);
list.add(23);
System.out.println(list);//[23,23,23,23]
List<Double> list1 = new ArrayList<>();
list1.add(8.9);
list1.add(8.9);
list1.add(8.9);
list1.add(8.9);
System.out.println(list1);
List<String> list2 = new ArrayList<>();
list2.add("张三");
list2.add("张三");
list2.add("张三");
list2.add("张三");
list2.add("张三");
System.out.println(list2);
}
}
3、ArrayList的方法
/**
* 演示ArrayList其他方法
*/
private static void show3() {
ArrayList<Integer> l1 = new ArrayList<>( );
l1.add(11);
l1.add(22);
l1.add(33);
System.out.println("原始l1:" + l1 );
ArrayList<Integer> l2 = new ArrayList<>( );
l2.add(10);
l2.add(20);
l2.add(30);
// 将另外一个集合中的全部元素加入当前集合
l1.addAll(l2);
System.out.println("addAll后: " + l1);
// 移除当前集合中,存在于参数集合相同的元素
l1.removeAll(l2);
System.out.println("移除后:" + l1 );
// 判断集合是否为空
System.out.println(l1.isEmpty( ));
// 存储的元素的个数
int size = l1.size( );
System.out.println("集合元素个数:" + size );
// 判断集合是否包含某个元素
System.out.println(l1.contains(11));
// 先创建整型数组
Integer[] integers = new Integer[l1.size()];
// 再将集合转成数组
Integer[] array = l1.toArray(integers);
System.out.println(Arrays.toString(array));
// 清空集合
l1.clear();
System.out.println("清空后: " + l1 );
// 判断集合是否为空
System.out.println(l1.isEmpty( ));
}
4、迭代
迭代就是集合的遍历
(1)使用for循环
public class Demo1 {
public static void main(String[] args) {
List<Integer> list1 = new ArrayList<>();
list1.add(22);
list1.add(33);
list1.add(44);
list1.add(55);
list1.add(66);
//开发不用!!!
for (int i = 0; i < list1.size(); i++) {
System.out.println(list1.get(i));
}
}
}
(2)使用迭代器遍历
public class Demo3 {
public static void main(String[] args) {
List<String> list1 = new ArrayList<>();
list1.add("狗蛋");
list1.add("鸡蛋");
list1.add("蛋蛋");
System.out.println(list1);//
// [狗蛋, 鸡蛋, 蛋蛋]
// |
//1获取集合相关的迭代器
//iterator 这个对象可以对年数据进行迭代效果!!!i
Iterator<String> iterator = list1.iterator();
//如果迭代具有更多的元素,则返回true
// System.out.println(iterator.hasNext());//true
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}
(3)增强for循环
public class Demo2 {
public static void main(String[] args) {
List<Integer> list1 = new ArrayList<>();
list1.add(22);
list1.add(33);
list1.add(44);
list1.add(55);
list1.add(66);
/**
* 增强for循环的语法格式:
* for (数据类型 临时变量 : 集合) {
*
* }
* 执行流程: 将冒号后面集合 挨个迭代出来赋值给临时变量
*/
//快捷键打出 iter就可以,就近原则
for (Integer i : list1) {
System.out.println(i);
}
}
}
5、底层原理(面试)
(1)Arraylist底层是数组实现的
(2)刚new创建完的初始容量默认是0,第一次加入元素会扩容到10
(3)当元素放满10个时,加入第11个元素就会触发扩容,扩容为原来的1.5倍数(通过右移一位算出来),扩容到1.5倍后,再利用Arrays.copyOf把原数组的元素拷贝到新数组
扩容的源码:
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
//如果触发了这个扩容, 每次扩1.5倍 oldCapacity >> 1 相当于除以2 (x + x/2)
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
elementData = [1,2,3,4]
elementData = Arrays.copyOf(elementData, 6);
elementData = [1,2,3,4,0,0]
6、扩展
ArrayList里面不仅仅能放8大基本数据类型,也能放引用数据类型(例如 String , 对象 等等)
class Employee {
private String name;
private Integer age;
public Employee() {
}
public Employee(String name, Integer age) {
this.name = name;
this.age = age;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public Integer getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(Integer age) {
this.age = age;
}
public String toString() {
return "Employee{name = " + name + ", age = " + age + "}";
}
}
public class Demo1 {
public static void main(String[] args) {
List<Employee> emps = new ArrayList<>();
emps.add(new Employee("奥特曼", 21));
emps.add(new Employee("满满", 22));
emps.add(new Employee("豆满", 23));
for (Employee emp : emps) {
System.out.println(emp.getName() + ":" + emp.getAge());
}
}
}
四、LinkedList(了解)
LinkedList也是List实现类,大部分方法与ArrayList一模一样用法,不再演示
1、特殊方法
除了基本的方法与ArrayList一样之外,LinkedList还提供一些比较特殊的操作头尾的方法
public static void main(String[] args) {
LinkedList<Integer> l1 = new LinkedList<>( );
l1.add(11);
l1.add(22);
l1.add(33);
// 获得头 尾操作
Integer first = l1.getFirst( );
Integer last = l1.getLast( );
System.out.println(first );
System.out.println(last );
}
2、底层原理
LinkedList底层是双向链表
(1)链表在内存中是不连续的
(2)通过链域里面的前驱节点和后继节点记录上一个/下一个元素的位置
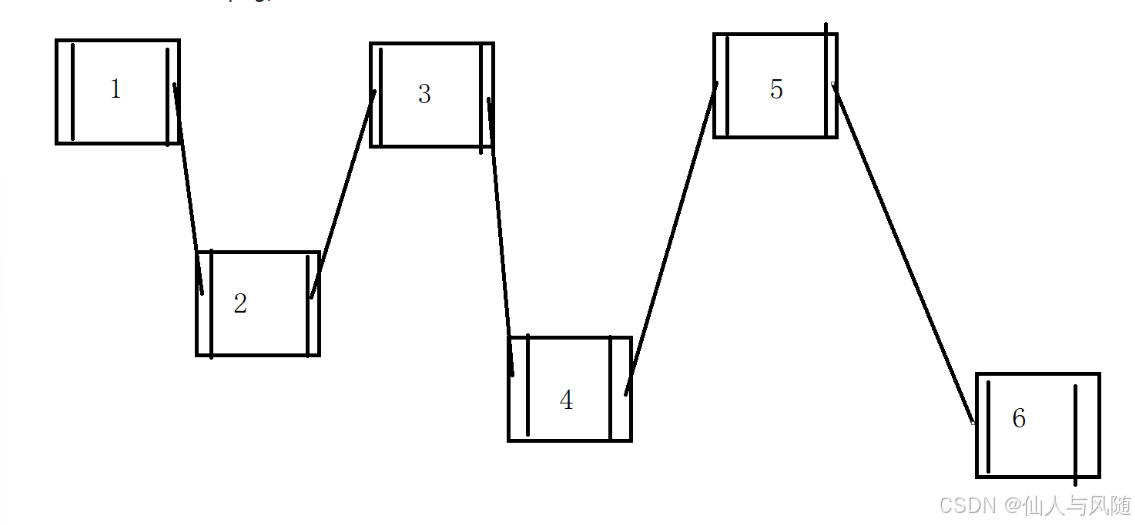
五、ArrayList和LinkedList的主要使用区别
1、ArrayList
(1)ArrayList查询、修改速度快,插入、删除速度慢
(2)因为插入、删除时一个下标的数据动了其他的下标都要跟着动
(3)查询、修改时只需要找到下标就可以,时间复杂度为O(1)
2、LinkedList
(1)LinkedList插入、删除速度快,查询、修改速度慢
(2)因为插入、删除只需要找到一个数据的前驱和后继就可以
(3)查询、修改速度慢是因为无法通过下标寻找,只能从第一个节点一直往后找
六、Set
1、Set是Collection的子接口
2、规定所存储的元素不允许重复且无序
(1)HashSet的无序是将存储的元素随机排序
(2)TreeSet的"无序" 是指将存储的元素给排序了
3、Set接口一般用两个实现类
(1)HashSet,存储的元素是无序且去重
(2)TreeSet,存储的元素排序且去重
七、HashSet
是Set接口的实现类,存储的元素是无序且去重,不保证线程安全
1、HashSet的方法
public static void main(String[] args) {
// 创建空集合
HashSet<Integer> set = new HashSet<>( );
System.out.println("初始空集合:" + set );
// 添加元素(去重,且无序)
boolean r1 = set.add(31);
System.out.println("第1次添加元素:" + r1 );
boolean r2 = set.add(31);
System.out.println("第12次添加相同元素:" + r2 );
set.add(21);
set.add(11);
set.add(51);
set.add(41);
System.out.println("加入元素后:" + set );
int size = set.size( );
System.out.println("集合大小:" + size );
System.out.println("是否为空: "+ set.isEmpty() );
System.out.println("是否包含:" + set.contains(11) );
// set.clear();
// System.out.println("清空集合后:"+ set );
// 遍历
for (Integer s : set){
System.out.println(s );
}
// 通过指定集合创建Set
HashSet<Integer> set2 = new HashSet<>(set);
System.out.println("set2初始:" + set2 );
}
2、底层实现原理
HashSet底层是HashMap,HashMap的底层实现是哈希表
|
// 创建HashSet时,会创建HashMap public HashSet(){ map = new HashMap<>(); } |
|
//向hashSet中存储元素,其实向HashMap中存储 public boolean add(E e){ return map,put(e,PERSENT) == null; } |
3、去重原理
(1)先调用存储的元素的hashcode方法,获得哈希值
(2)然后与集合中的元素的地址值判断,如果不一样直接存储
(3)如果存储的元素的地址值与集合中存在的元素的地址值一样,再比较equals方法,判断对象属性是否相同
(4)如果equals也判断相同,即认为重复,不存储
(5)如果equals判断不相同,即认为不重复,存储
八、TreeSet
TreeSet是Set集合的实现类,也是不允许重复元素,但是它存储的元素有序!!会对存储的元素默认按照`自然顺序`排序,另外此类也是不保证线程安全
1、TreeSet的方法
大部分方法都是常规方法,正常使用(添加,遍历,删除,大小,清空..)
public static void main(String[] args) {
// 使用空参构造创建TreeSet集合
// 没有指定排序规则,默认是按照元素的自然顺序排序
TreeSet<Integer> ts = new TreeSet<>( );
/**
* 去重,且排序
*/
ts.add(3);
ts.add(3);
ts.add(2);
ts.add(5);
ts.add(1);
ts.add(4);
for (Integer i : ts) {
System.out.println(i );
}
}
2、排序去重的原理
(1)要想利用TreeSet排序,存储的元素(Student)必须实现Comparable接口,重写comparTo方法
|
int compareTo(T o) //将此对象与指定的对象进行比较以进行排序。 返回一个负整数,零或正整数,因为该对象小于,等于或大于指定对象。 |
(2)当调用add方法存储元素时,会调用元素的compareTo进行运算。
如果返回负数,放在二叉树左侧
如果返回正数,放在二叉树右侧
如果返回0,去重元素不放
class Student implements Comparable<Student>{
private String name;
private Integer age;
public Student() {
}
public Student(String name, Integer age) {
this.name = name;
this.age = age;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public Integer getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(Integer age) {
this.age = age;
}
public String toString() {
return "Student{name = " + name + ", age = " + age + "}";
}
@Override
public int compareTo(Student o) {
return this.age - o.age;
}
}
public class Demo2 {
public static void main(String[] args) {
Set<Student> set = new TreeSet<>();
set.add(new Student("张三", 18));
set.add(new Student("李四", 17));
set.add(new Student("王五", 19));
set.add(new Student("赵六", 16));
set.add(new Student("天气", 17));
System.out.println(set);
}
}
3、指定比较器
自然排序其实就是指 实现了Comparable接口的,创建TreeSet集合时不指定排序规则,默认就是就这种自然排序

比较器排序, 在创建集合时传入自定义的比较器对象,存储元素时就会使用自定义的方法实现排序
|
特性 |
|
|
|
定义位置 |
由类自身实现 |
由外部类或匿名类实现 |
|
方法 |
|
|
|
排序方式 |
只能定义一种排序方式 |
可以定义多种排序方式 |
|
使用场景 |
自然排序规则 |
自定义多种排序规则 |
|
灵活性 |
不灵活,只能排序成一种方式 |
灵活,可以根据需要调整排序方式 |
public class MyIntegerComparator implements Comparator<Integer> {
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
}
class Student {
private String name;
private Integer age;
public Student() {
}
public Student(String name, Integer age) {
this.name = name;
this.age = age;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public Integer getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(Integer age) {
this.age = age;
}
public String toString() {
return "Student{name = " + name + ", age = " + age + "}";
}
}
class MyComparator implements Comparator<Student> {
@Override
public int compare(Student o1, Student o2) {
return o1.getAge().compareTo(o2.getAge());
}
}
public class Demo1 {
public static void main(String[] args) {
//第二种方式比较
//Set<Student> set = new TreeSet<>(Comparator接口对象);
//构造方法形参是 一个即接口, 实参是这个接口的实现类对象
Set<Student> set = new TreeSet<>(new MyComparator());
set.add(new Student("张三", 18));
set.add(new Student("李四", 17));
set.add(new Student("王五", 19));
set.add(new Student("赵六", 16));
set.add(new Student("天气", 13));
System.out.println(set);
}
}
4、总结
(1)HashSet 存自定义对象 重写 equlas和hashCode
(2)TreeSet 存自定义对象 实现 Comparable 接口 重写 comparTo方法
九、Map
1、概念
Map是一种映射关系的集合,能从键映射到值,它是一种特殊的集合,一次存储一对元素(键值对),即Map是双列集合
2、HashMap【重点】
HashMap是Map的实现
(1)底层实基于Hash表(jdk1.8以后底层是数组+链表+红黑树)
(2)允许存储null值null键
(3)HashMap不保证线程安全
(4)Hashtable是线程安全的,不允许null值与null键,其余与HashMap一样
方法演示:
public static void main(String[] args) {
// 创建空的map集合
HashMap<Integer, String> map = new HashMap<>( );
// 添加元素(键不允许重复,值可以重复)
// 元素是无序
String v1 = map.put(2, "二");
System.out.println(v1 );// null,返回的是此key所对应之前的value
String v2 = map.put(2, "贰");
System.out.println(v2 );// 二
map.put(22, "贰");
map.put(32, "贰");
map.put(42, "贰");
map.put(52, "贰");
// 输出结果
System.out.println(map );
// v get(Object key) // 通过键找值
String v = map.get(22);
System.out.println(v );
// 判断是否包含某个键
System.out.println(map.containsKey(22));
// 判断是否包含某个值
System.out.println(map.containsValue("22"));
// 集合大小(尺寸),元素个数
System.out.println(map.size() );
// 根据键删除整个键值对,返回v
String remove = map.remove(22);
System.out.println("删除键22,返回对应的值:"+remove );
System.out.println("删除后:" + map );
// 清空集合
map.clear();
System.out.println("清空后:" + map );
}
3、迭代遍历【重点】
Map集合没有提供直接的遍历Map集合的方法,但是提供了
(1)键集set<K> KeySet() 专门遍历键
(2)值集Collection<V> values 专门遍历值
(3)键值映射集Set<Map.Entry<K,V>> entrySet 专门遍历键值对
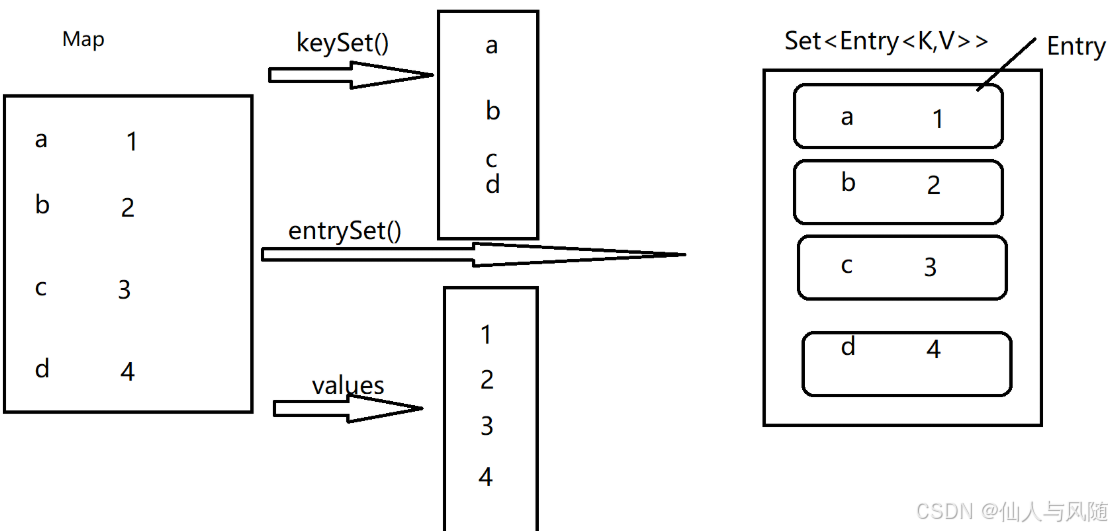
演示遍历键集:
HashMap<String,Integer> map = new HashMap<>( );
map.put("A",1);
map.put("B",2);
map.put("C",3);
map.put("D",4);
// 获得键的集合
Set<String> keySet = map.keySet();
// 遍历集合,得到所有的键
for(String key:keySet){
System.out.println(key );
}
演示遍历值集:
// 获得值的集合
Collection<Integer> values = map.values( );
// 遍历
for (Integer v : values){
System.out.println(v );
}
演示遍历键值映射集合:
// 获得键值映射集合
// Map.Entry是Map内的内部接口,代表一项键值对
Set<Map.Entry<String,Integer>> entrySet = map.entrySet();
// 遍历
for(Map.Entry<String,Integer> entry : entrySet) {
String key = entry.getKey( );
Integer value = entry.getValue( );
System.out.println(key+"="+value );
}
4、底层原理
HashMap底层是数组+链表+红黑树
(1)HashMap底层的hash表就是一个数组,容量是16
(2)数据存储的是链表
(3)当put存储键值对时,算出key的hash值,当作数组的索引,存储到数组中。
如果这个位置没有元素,直接存储;
如果这个位置有元素,当做链表挂着;
如果此链表长度>8且数组长度大于64时,链表转为红黑树
(4)存储元素达到阈值:初始容量*加载因子=16*0.75会扩容成2倍·
5、去重原理
(1)先调用key的hashCode判断地址是否相同,如果不一样,直接存储
(2)如果地址值一样,调用equals方法判断内容
(3)equals判断不一样,直接存储
(4)equals判断一样,去重,不存储
6、实际应用
/*需求: 键盘输入一个英文字符串,例如"abcabcabc",计算出此字符串中每个字符出现的次数
思路: 字符和次数有关联,即映射, a-->3
- 得到字符串中每个字符
- 创建一个map存储,字符当键,次数当值
- 判断map中是否包含字符(判断是否包含键)
- 如果这个字符不存在,说明第1次出现,即存储该字符,次数1
- 如果这个字符存在,取出该字符对应的次数,+1,后再存储*/
public class Pracitce {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.println("请输入一串英文字符");
String word = sc.next();
char[] charArray = word.toCharArray();
HashMap<Character,Integer> map = new HashMap<>();
for (char c : charArray) {
if (map.containsKey(c)){ //已包含说明不是第一次
Integer count = map.get(c);
count++;
map.put(c,count);
}else{
map.put(c,1); //不包含就是第一次走else直接字母
}
}
System.out.println(map);
}
}
解析
/**
* charArray = [a,b,c,a,b,c,a,b];
* 循环第一次: map.containsKey(a) falsemap.put(a, 1);map={a=1}
* 循环第二次: map.containsKey(b) false map.put(b, 1);map={a=1,b=1}
* 循环第三次: map.containsKey(c) false map.put(c, 1);map={a=1,b=1,c=1}
* 循环第四次: map.containsKey(a) true map.get(a); count=2map.put(a, 2) map={a=2,b=1,c=1}
* 循环第五次: map.containsKey(a) true map={a=2,b=2,c=1}
* 循环第6次: map.containsKey(a) true map={a=2,b=2,c=2}
* 循环第7次: map.containsKey(a) true map={a=3,b=3,c=2}
*/
十、File【熟悉,为IO流做基础】
1、构造方法
(1)File(String pathname)
通过将给定的路径名字符串转换为抽象路径名来创建新的 File实例
(2)File(String parent, String child)
从父路径名字符串和子路径名字符串创建新的 File实例。
public class Demo1 {
public static void main(String[] args) {
//File(String pathname)
//通过将给定的路径名字符串转换为抽象路径名来创建新的 File实例
File file = new File("c:/aaa/1.txt");
System.out.println(file);//c:\aaa\1.txt
//作为初学者 咱们需要咋理解? 把一个电脑中文件或者文件夹变成了一个对象
/*File(String parent, String child)
从父路径名字符串和子路径名字符串创建新的 File实例。*/
File file1 = new File("c:/aaa", "1.txt");
System.out.println(file1);//c:\aaa\1.txt
//File(File parent, String child)
//从父抽象路径名和子路径名字符串创建新的 File实例。
File fileParent = new File("c:/aaa");
File file2 = new File(fileParent, "1.txt");
System.out.println(file2);//c:\aaa\1.txt
}
}
2、关于路径
public class Demo2 {
public static void main(String[] args) {
File file = new File("c:/aaa/1.txt");
File file1 = new File("C:\\aaa\\1.txt");
//注意:【/ 是windows系统linux系统都是可以的!!!\\ 只能windows系统可以的】
System.out.println(File.separator);
File file2 = new File("c:" + File.separator + "aaa" + File.separator + "1.txt" );
System.out.println(file2);
}
}
3、演示基本用法
(1)绝对路径和相对路径以及创建文件
public static void main(String[] args) throws IOException {
// 通过路径创建对象
/**
* 路径写法
* - 绝对路径(位置精准)
*/
File file = new File("E:\\a.txt");
// 获得文件的绝对路径
String absolutePath = file.getAbsolutePath( );;
System.out.println("file的绝对路径:"+absolutePath );
// 判断文件是否存在
// false 不存在,true存在
System.out.println(file.exists() );
// 通过判断是否存在,来决定要不要创建这个文件
if (!file.exists()){ // 不存在
// 创建文件
file.createNewFile();
}
System.out.println("-------------------" );
/**
* 相对路径,相对于当前项目
*/
File file2 = new File("a.txt");
System.out.println(file2.exists() );
file2.createNewFile();
// 获得对象的绝对路径(详细信息)
String absolutePath2 = file2.getAbsolutePath( );
System.out.println("file2的绝对路径:" + absolutePath2 );
}
(2)通过两级目录创建对象
private static void show2() {
// 通过子父级路径(字符串形式)创建对象
File file = new File("E:\\test", "justdoit.jpg");
System.out.println(file.exists() );
// 通过父级文件对象+子级路径创建对象
File parent = new File("E:\\test");
File file2 = new File(parent, "justdoit.jpg");
System.out.println(file2.equals(file) );
}
(3)删除文件/文件夹(删除空)
delete( );
private static void show3() {
File file = new File("E:\\test\\justdoit.jpg");
// 删除文件,特别注意不经过回收站
boolean delete = file.delete( );
if (delete) {
System.out.println("删除成功" );
}
File file2 = new File("E:\\test");
// 删除空文件夹,有内容无法删除该文件
boolean delete2 = file2.delete( );
System.out.println(delete2 );
}
(4)创建文件createNewFile(),
创建文件夹
mkdir()
mkdirs()
private static void show4() {
File file = new File("E:\\test");
// 创建文件夹(单层文件)
boolean mkdir = file.mkdir( );
System.out.println("创建文件夹是否成功:"+ mkdir );
File file2 = new File("E:\\test\\a\\b");
// 创建多层文件夹
boolean mkdir2 = file2.mkdirs( );
System.out.println("创建多层文件夹是否成功:"+ mkdir2 );
}
(5)判断文件类型
isDirectory() 判断是否是文件夹
isFile() 判断是否是文件
private static void show5() {
File file = new File("E:\\test\\a.txt");
// 判断是否是文件夹
System.out.println("是否是文件夹:"+file.isDirectory() );//false
// 判断是否是文件
System.out.println("是否是文件:" +file.isFile());//true
}
(6)查找文件夹内部
String[] list(); 展示当前文件夹下面的所有文件和文件夹的名字
File[] listFiles(); 返回的是当前文件夹下面的所有的文件和文件夹对象
private static void show6() {
File file = new File("E:\\test");
// 获得文件夹下的所有内容,以字符串数组返回
// 用法就是按照字符串的特性去使用(针对字符串操作)
// 例如: 通过判断后缀找到txt文件
String[] list = file.list( );
for (String s : list) {
if (s.endsWith("txt")){
System.out.println(s );
}
}
System.out.println("-----------" );
// 获得文件夹下的所有内容,以文件对象数组返回
// 获得文件对象,按照文件对象去用!(文件删除,重命名,判断文件类型)
// 例如: 删除其中文件
File[] files = file.listFiles( );
for (File f : files) {
if (f.isFile()){
f.delete();
}
}
}
(7)文件重命名
private static void show7() {
File file = new File("E:\\test\\a\\a.txt");
File f = new File("E:\\test\\a2.txt");
/**
* 重命名前面位置一致: 就是重命名
* 重命名前面位置不一致: 就是剪切并重命名
*/
boolean b = file.renameTo(f);
System.out.println("重命名:" + b );
}
总结:常用的方法
- **字符串路径创建对象 File(String f)**
- **判断文件是否存在 exists()**
- **创建文件 createNewFile()**
- **创建文件夹 mkdir**
- **删除文件 delete**
- **获得完整路径 getAbsolutePath**
十一、IO流
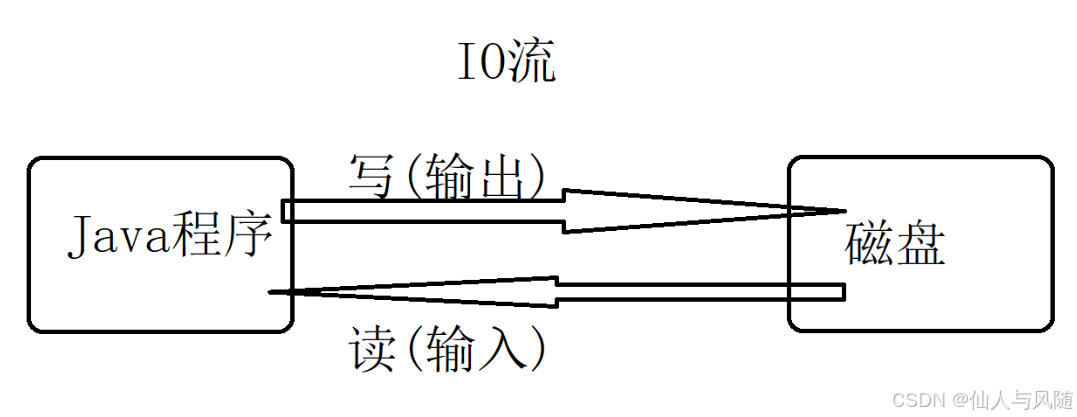
1、介绍
I就是Input,输入
O就是Output,输出
流 一个比喻,数据就像水流一样流动传递
2、常用类
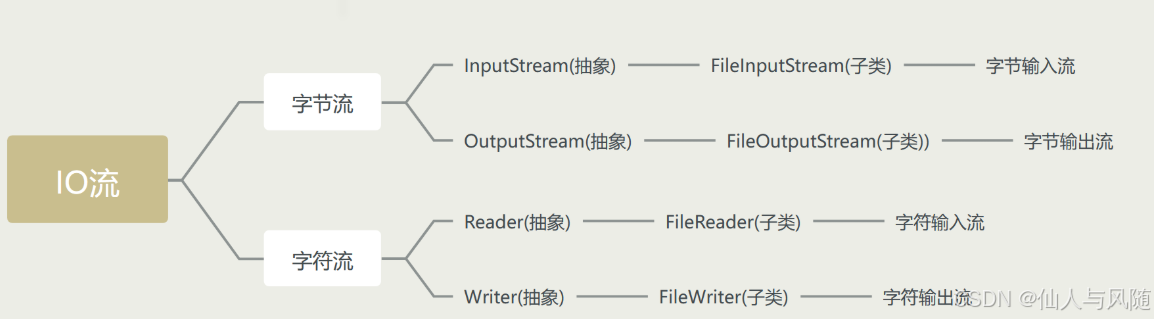
操作的文件类型不一样,使用的类不一样,基本只使用字节流
(1)操作二进制文件(图像资源,图片,音频,视频) 使用字节流【主要、重要】
(2)操作字符文件(文本,txt), 使用字符流【根本没用】
3、常用方法
(1)凡是读取数据,方法名都是read()
(2)凡是写出数据,方法名都是write()
(3)但是无论读写,只要使用IO流,用完一定使用close()关闭流
十二、字节流
1、字节输入流
//ps: 使用字节在读取字符数据,是为了演示得到效果
// 真正实操时得使用字节读取二进制文件
public static void main(String[] args) throws IOException {
// 传入文件对象或者文件路径创建字节输入流
FileInputStream fis = new FileInputStream("a.txt");
// 读取数据(输入)
// read一次读取一个字节
// int d1 = fis.read( );
// System.out.println(d1 );
//
// int d2 = fis.read( );
// System.out.println(d2 );
//
// int d3 = fis.read( );
// System.out.println(d3 );
//
// // 读完到末尾,返回-1
// int d4 = fis.read( );
// System.out.println(d4 );
// ------ 以上读取比较麻烦,不能一下读完,建议是循环操作 -----
int length ;
while ((length = fis.read()) != -1) {
System.out.println(d );
}
// 操作完,一定关流
fis.close();
}
2、也可以使用try-catch完成代码
public static void show2() {
FileInputStream fis = null;
try {
fis = new FileInputStream("a.txt");
int d = -1;
while ((d = fis.read( )) != -1) {
System.out.println(d);
}
} catch (Exception e) {
System.out.println("IO异常" );
e.printStackTrace( );
} finally {
try {
fis.close();
}catch (Exception e){
System.out.println("关流异常" );
e.printStackTrace();
}
}
}····
3、字节输出流
public static void main(String[] args) {
FileOutputStream fos = null;
try{
// 以指定文件创建输出流对象
// 1)文件不存在会创建出来!!!
// 2)如果文件有内容,默认是覆盖重写
// 3)可以在创建对象时指定第2个参数true,就会拼接内容
//fos = new FileOutputStream("b.txt");
fos = new FileOutputStream("b.txt",true);
// 写出数据(一次写一个)
fos.write(98);
} catch (Exception e){
e.printStackTrace();
} finally {
// 关流
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
4、拷贝图片【重点】
拷贝图片就是读+写数据;是边读边写
public static void main(String[] args) throws Exception{
// 读
FileInputStream fis = new FileInputStream("E:\\zy.jpg");
// 写
FileOutputStream fos = new FileOutputStream("D:\\zy.jpg");
// 边读边写
int d;
while ((d = fis.read()) != -1) {
fos.write(d);
}
// 结束
fis.close();
fos.close();
}
5、缓冲字节流
原始的字节流是一次读取/写出一个字节,大文件时候非常慢!!!
可以提供一个数组,一次读取数组长度这么多个数据,也可以一次写出数组长度这么多个数据。O体系中提供了这么操作的类: 缓冲字节流
(1)缓冲字节输入流BufferedInputStream
(2)缓冲字节输出流BufferedOutputStream
初步演示使用:
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
/**
* --- 天道酬勤 ---
*
* @author QiuShiju
* @date 2024/3/13
* @desc 拷贝大文件
* 使用原始字节流读写一个太慢
* 使用缓冲区字节流进行改造,可以一次读写多个!!!
*/
public class Demo4_copy {
public static void main(String[] args) throws Exception{
// 读
FileInputStream fis = new FileInputStream("E:\\1.mp3");
// 创建缓冲字节输入流
BufferedInputStream bis = new BufferedInputStream(fis);
// 写
FileOutputStream fos = new FileOutputStream("E:\\2.mp3");
// 创建缓冲字节输出流
BufferedOutputStream bos = new BufferedOutputStream(fos);
// 边读边写
int d;
while ((d = bis.read()) != -1) {
bos.write(d);
}
// 结束
bis.close();
bos.close();
}
}
强烈对比
public class Demo4 {
public static void main(String[] args) throws IOException {
//三种对比
copyWMV(); //不知道多少毫秒了,起码上万毫秒
copyWMV1(); //56毫秒
}
public static void copyWMV() throws IOException {
long start = System.currentTimeMillis(); //开始时间
FileInputStream fis = new FileInputStream("d:/aaa/bbbbb/2.wmv"); //从bbbbb中读入到java
FileOutputStream fos = new FileOutputStream("d:/aaa/ccccc/3.wmv"); //从java中读出到ccccc
//边读边写即可
int length;
while ((length = fis.read()) != -1){
fos.write(length);
}
//关闭流
fos.close();
fis.close();
long end = System.currentTimeMillis(); //结束时间
System.out.println(end - start); //差值
}
public static void copyWMV1() throws IOException {
long start = System.currentTimeMillis();
//==========华丽的分割线===============
FileInputStream fis = new FileInputStream("d:/aaa/bbbbb/2.wmv"); //从bbbbb中读入到java
BufferedInputStream bis = new BufferedInputStream(fis);
FileOutputStream fos = new FileOutputStream("d:/aaa/ccccc/2.wmv"); //从java中读出到ccccc
BufferedOutputStream bos = new BufferedOutputStream(fos);
//边读边写即可
byte[] buf = new byte[4 * 1024];
int length;
while ((length = bis.read(buf)) != -1){
bos.write(length);
}
//关闭流
bos.close();
bis.close();
long end = System.currentTimeMillis();
System.out.println(end - start);
}
}
6、IO总结
(1)记住读写的方法,读:read,写:write
(2)如果发现读写比较慢,想到使用数组和缓冲区来提高效率
(3)实际开发时,如果需要IO操作,一般使用别人封装好的工具类


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









