






 本文详细介绍使用TensorFlow从CSV文件读取数据的方法,包括如何设置文件队列、读取行数据、解析CSV记录和批处理数据。适用于数据集较大且需要高效处理的场景。
本文详细介绍使用TensorFlow从CSV文件读取数据的方法,包括如何设置文件队列、读取行数据、解析CSV记录和批处理数据。适用于数据集较大且需要高效处理的场景。
TensorFlow程序读取数据一共有3种方法:
- 供给数据(Feeding): 在TensorFlow程序运行的每一步, 让Python代码来供给数据。
- 从文件读取数据: 在TensorFlow图的起始, 让一个输入管线从文件中读取数据。
- 预加载数据: 在TensorFlow图中定义常量或变量来保存所有数据(仅适用于数据量比较小的情况)
第一种大家很熟悉不用多说, 第三种采用比如np.loadtxt 等函数一次性载入所有数据,如果数据很大会很慢。
重点谈一谈对第二种方法的体会:
假如我们的数据为一个.csv文件:
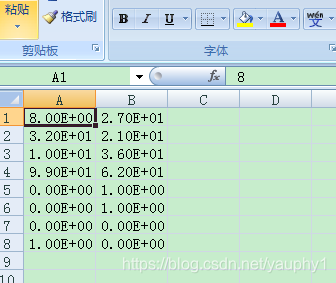
那么用以下的代码可以读取:
# coding=utf-8
import tensorflow as tf
import os
import csv
#要保存后csv格式的文件名
filenames = ['./new.csv']
#file_name_string="'D:/dataTest.csv'"
#filename_queue = tf.train.string_input_producer([file_name_string])
filename_queue = tf.train.string_input_producer(filenames, shuffle=False, num_epochs=1)
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
print(value)
# Default values, in case of empty columns. Also specifies the type of the
# decoded result.
record_defaults = [[1.0],[1.0]]
data = tf.decode_csv(value, record_defaults=record_defaults)
data_batch = tf.train.batch([data], batch_size=4, capacity=200, num_threads=2)
#features = tf.concat(0, [col1, col2, col3])
init_local_op = tf.local_variables_initializer()
with tf.Session() as sess:
# Start populating the filename queue.
sess.run(init_local_op)
tf.global_variables_initializer().run()
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(2):
# Retrieve a single instance:
example= sess.run([data_batch])
print(example)
coord.request_stop()
coord.join(threads)
执行的结果为:
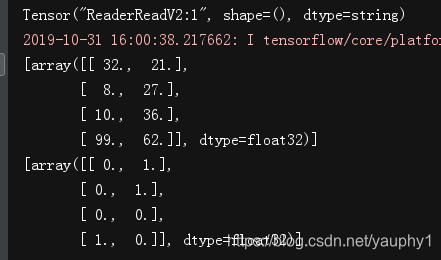
如果有数据有很多列, 列举不过来呢?
只需把 record_defaults = [[1.0],[1.0]] 修改为
record_defaults = list([1.0] for i in range(2))
就可以了, 数据有多少列就填多大!
Done!


















 1011
1011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









