



 本文介绍了在Java中使用JDBC执行多次查询的过程,包括数据库连接、Statement对象操作,以及MyBatis中ResultSet和Statement的释放策略。同时讨论了maven-shade-plugin和maven-assembly-plugin在打包中的应用,以及PCIe的基础知识和CAS入门实战中的票证验证技术。
本文介绍了在Java中使用JDBC执行多次查询的过程,包括数据库连接、Statement对象操作,以及MyBatis中ResultSet和Statement的释放策略。同时讨论了maven-shade-plugin和maven-assembly-plugin在打包中的应用,以及PCIe的基础知识和CAS入门实战中的票证验证技术。
1.(转) 操作系统——MBR与显存
https://www.cnblogs.com/hawkJW/p/13651701.html
2.Statement执行多次查询
在Java中,使用JDBC的Statement对象来执行SQL语句进行数据库查询时,可以通过以下步骤进行:
-
加载数据库驱动。
-
创建数据库连接。
-
创建Statement对象。
-
执行查询并处理结果。
-
关闭Statement对象和数据库连接。
以下是执行多次查询的示例代码:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class MultipleQueriesExample {
public static void main(String[] args) {
String url = "jdbc:mysql://localhost:3306/your_database";
String user = "your_username";
String password = "your_password";
try {
// Step 1: Load the driver
Class.forName("com.mysql.cj.jdbc.Driver");
// Step 2: Establish a connection
try (Connection conn = DriverManager.getConnection(url, user, password);
// Step 3: Create a statement
Statement statement = conn.createStatement()) {
// Step 4: Execute queries
String query1 = "SELECT * FROM your_table WHERE condition1";
String query2 = "SELECT * FROM your_table WHERE condition2";
// Execute query 1
ResultSet rs1 = statement.executeQuery(query1);
// Process results of query 1
while (rs1.next()) {
// Retrieve by column name
int id = rs1.getInt("id");
String name = rs1.getString("name");
// ...
}
rs1.close();
// Execute query 2
ResultSet rs2 = statement.executeQuery(query2);
// Process results of query 2
while (rs2.next()) {
// Retrieve by column name
int id = rs2.getInt("id");
String name = rs2.getString("name");
// ...
}
rs2.close();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}JDBC定义了接口,又定义了使用方式
mybatis示例:
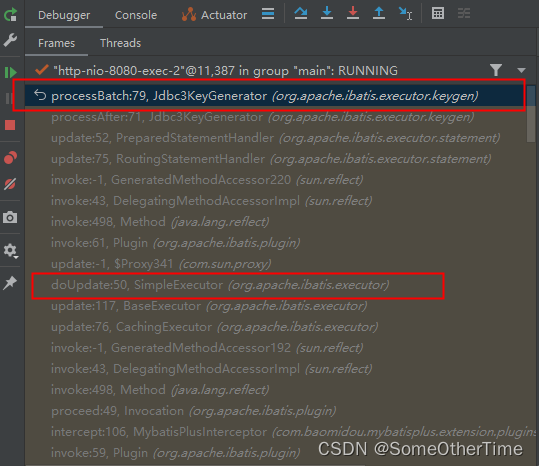
mybatis每次请求先释放ResultSet,再释放Statement
释放Statement
org.apache.ibatis.executor.SimpleExecutor#doUpdate
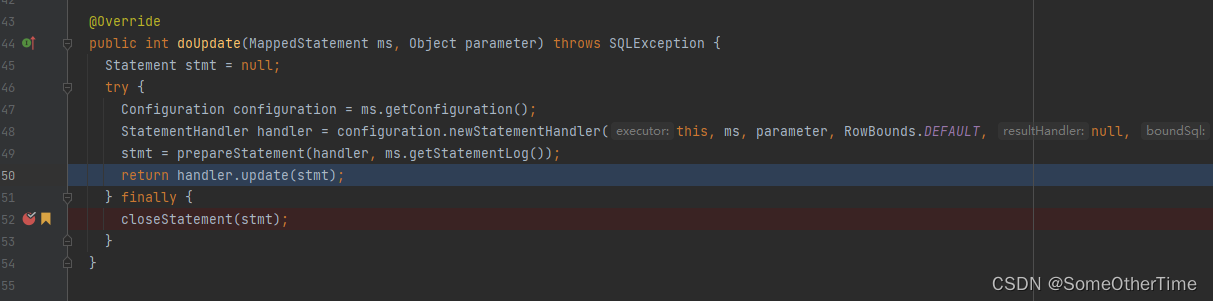
org.apache.ibatis.executor.keygen.Jdbc3KeyGenerator#processBatch
释放ResultSet
3.maven-shade-plugin和maven-assembly-plugin打包插件
Java选手必看打包插件:maven-shade-plugin和maven-assembly-plugin - 墨天轮
4.原来PCIe这么简单,一定要看!
原来PCIe这么简单,一定要看! 来源:内容来自公众号「Linux阅码场」,作者:木叶 ,谢谢。硬盘是大家都很熟悉的设备,一路走来,从HDD到SSD,从... - 雪球
5.CAS 入门实战
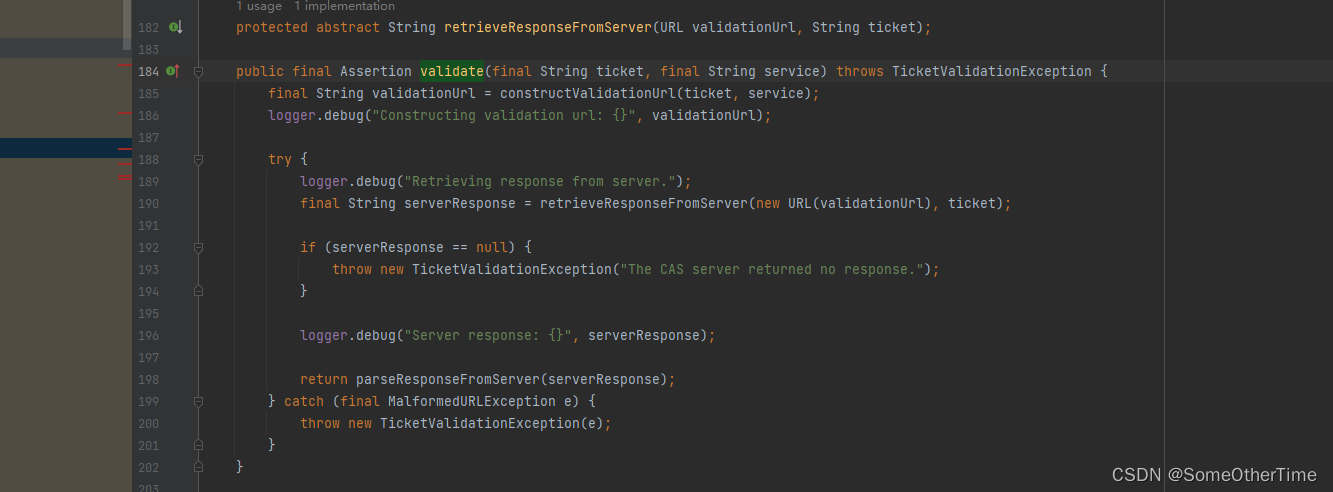
org.jasig.cas.client.validation.AbstractCasProtocolUrlBasedTicketValidator#retrieveResponseFromServer
org.jasig.cas.client.validation.AbstractUrlBasedTicketValidator#validate
https://blog.51cto.com/wuyongyin/5321466
6.破解
Some keys for testing - jetbra.in

















 1465
1465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









