




 本文深入探讨XGBoost机器学习算法,包括其在Kaggle竞赛中的广泛应用,以及其在梯度提升树、损失函数、近似算法等方面的优化策略。文章详细解释了XGBoost如何通过子采样、权值收缩和稀疏数据处理来防止过拟合,并介绍其在并行计算和缓存处理方面的高效设计。
本文深入探讨XGBoost机器学习算法,包括其在Kaggle竞赛中的广泛应用,以及其在梯度提升树、损失函数、近似算法等方面的优化策略。文章详细解释了XGBoost如何通过子采样、权值收缩和稀疏数据处理来防止过拟合,并介绍其在并行计算和缓存处理方面的高效设计。
1. Abstract
Boosting tree是一种有广泛应用的技术。听到boosting一词都知道它是一种迭代的更新的逐步降低模型整体的误差的办法如Adboost,当年Adboost跟SVM统治了整个机器学习界。最近我阅读了XGboost(下面简称XGB)论文,想跟大家分享一下自己的读后感,也自己的学习做个笔记。首先先说说XGB在实战上面的成就吧。
以机器学习竞赛网站Kaggle举办的挑战为例。在2015年Kaggle博客发布的29个挑战获胜解决方案3中,17个解决方案使用XGBoost。
在这些解决方案中,八个单独使用XGBoost来训练模型,而其他大多数人则将XGBoost与神经网络合并在一起。
可见XGB在kaggle上是大杀伤力武器,除了实战以外XGB在理论上面也是state-of-the-art。
1.相对GBDT来说,XGB在增加二阶梯度有更高的精度。
2.XGB的节点划分策略带有进行预排序,利用样本在损失函数上面的二阶梯度作为权值。
3.XGB对稀疏的特征划分方式。
4.在处理特征的粒度上进行多线程的优化。
5.使用近似算法替代每个样本逐个判断最佳分裂点的Exact Greedy Algorithm算法。
2.Main Work
2.1 Tree Boosting with Loss function
给定一个数据集D中有n个样本,每个样本有m维特征。通过训练数据集D,我们得到K棵树。这K棵树累加的值为我们的预测值。
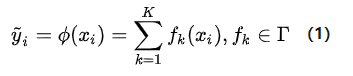
这是Boosting Tree的最终预测结果。其中f_{k}(x_{i}) 是样本 x_{i} 在第k棵树的叶子上的权值。因此我们也可以这样定义样本 x_{i} 在第k棵树上的的权值:
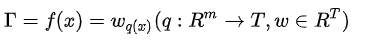
有了输出值,我们就可以代入损失函数当中,损失函数可以是Mean Square Error,也可以是Cross entropy Loss。当然这个不是特别重要,因为我们最后要的是他们梯度。最后我们加上我们的Regularized Learning Objective,整个损失函数就出来了。
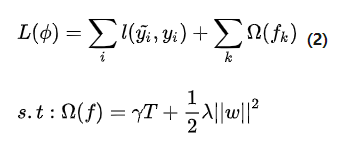
那我们就有优化的目标了。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 464
464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









