



1.排名函数使用
创建表:
create table TEST
(
pName varchar(20),
cName varchar(50),
pState int
) ;
insert into TEST values ('GS', 'LZ', 234) ;
insert into TEST values ('GS', 'BY', 34) ;
insert into TEST values ('GS', 'DX', 4) ;
insert into TEST values ('GS', 'LN', 67) ;
insert into TEST values ('GS', 'GN', 67) ;
insert into TEST values ('GS', 'QY', 67) ;
insert into TEST values ('SX', 'XA', 34) ;
insert into TEST values ('SX', 'YA', 85) ;
insert into TEST values ('SX', 'BJ', 254) ;
insert into TEST values ('SX', 'HZ', 99) ;
insert into TEST values ('SX', 'XY', 100) ;
insert into TEST values ('SX', 'SL', 23) ;
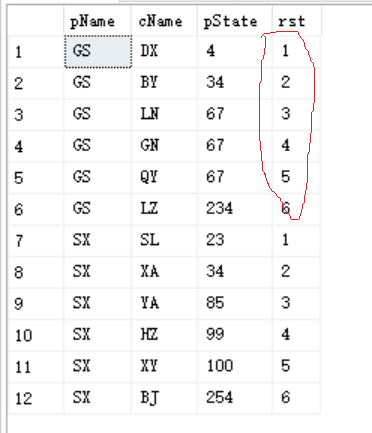
1)row_number() 的使用
--row_number()
--特点是,这个函数不需要考虑是否并列,哪怕根据条件查询出来的数值相同也会进行连续排名
select pName, cName, pState,
row_number() over(partition by pName ORDER BY pState) AS rst
from TEST ;
执行结果:
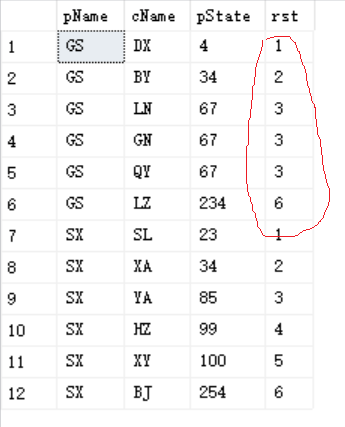
2)rank()
--特点是,假如是对学生排名,使用这个函数,成绩相同的两名是并列,下一位同学空出所占的名次。
select pName, cName, pState,
rank() over(partition by pName ORDER BY pState) AS rst
from TEST ;
执行结果:
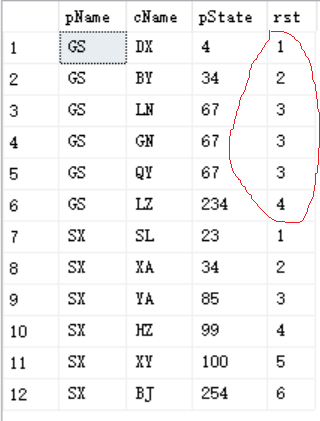
3)dense_rank()
--dense_rank()
--与ran() over的区别是,两名学生的成绩并列以后,下一位同学并不空出所占的名次
select pName, cName, pState,
dense_rank() over(partition by pName ORDER BY pState) AS rst
from TEST ;
执行结果:
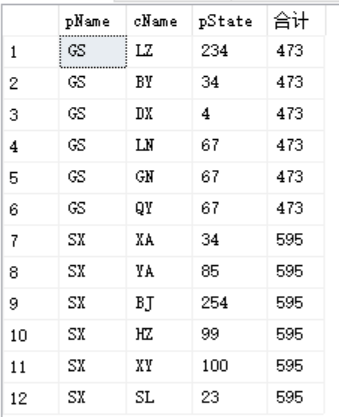
2.结合聚合函数
--sum
--vg、count、max、min、first_value、last_value与sum用法一模一样
select *,SUM(pState)over(partition by pName) as 合计
from TEST
执行结果:
3.分许函数
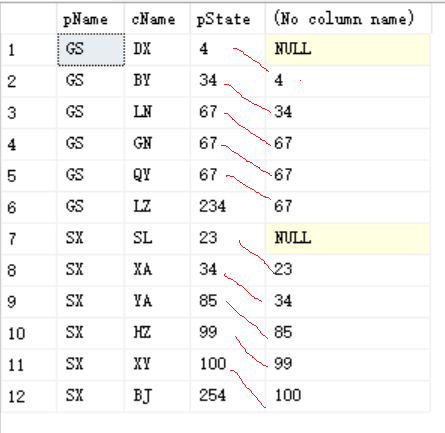
1)lag()
--lag
--这个函数可以取出某个字段前第n条记录的值
select *,lag(pState,1)over(partition by pName order by pState)
from TEST
执行结果:
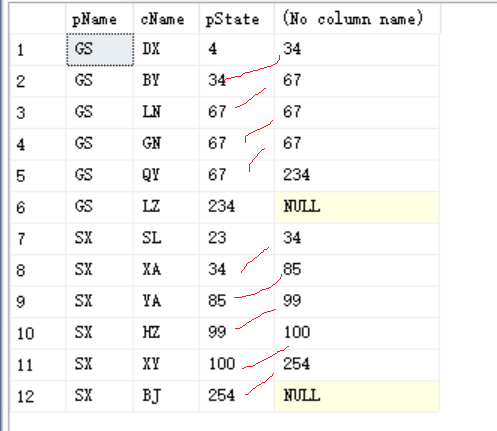
2)lead()
--lead
--这个函数可以取出某个字段后第n条记录的值
select *,lead(pState,1)over(partition by pName order by pState)
from TEST
执行结果:
原文链接:https://blog.youkuaiyun.com/tang_xuming/article/details/79197163

















 540
540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









