






学习记录
首先将test.csv,file.csv放同一个文件夹
模型建立
import torch
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
#输入的模型特征是6维
self.linear1 = torch.nn.Linear(6,4)
self.linear2 = torch.nn.Linear(4,1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self,x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
return x加载数据集
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'
import torch
from torch.utils.data import Dataset,DataLoader
class TitannikDataset(Dataset): #需要特征和标签
def __init__(self, X, y):
self.len = X.shape[0]
X = X.values.astype("float32")#.values dataframe to numpy
y = y.values.astype("float32")
# TypeError: expected np.ndarray(got DataFrame)
self.x_data = torch.from_numpy(X) #numpy to tensor
self.y_data = torch.from_numpy(y)
def __getitem__(self,index):
return self.x_data[index],self.y_data[index]
def __len__(self):
return self.len
#加载数据
def create_train_loader(x_train, y_train):
dataset = TitannikDataset(x_train, y_train)
train_loader = DataLoader(dataset=dataset, shuffle=True, batch_size=32, drop_last=True, num_workers=2)
return train_loader训练数据并保存模型
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'
import torch
import ModelDemo
import pandas as pd
from torch.utils.data import Dataset,DataLoader
train = pd.read_csv("train.csv")#此时是dataframe
#取五个最相关的特征
x_train =train[["Pclass", "Sex", "SibSp", "Parch", "Fare"]]
#独热编码
x_train = pd.get_dummies(x_train)#DataFrame
#print(type(x_train))
y_train =train[["Survived"]]#DataFrame
#print(type(y_train))
class TitannikDataset(Dataset): #需要特征和标签
def __init__(self, X, y):
self.len = X.shape[0]
X = X.values.astype("float32")#.values dataframe to numpy
y = y.values.astype("float32")
# TypeError: expected np.ndarray(got DataFrame)
self.x_data = torch.from_numpy(X) #numpy to tensor
self.y_data = torch.from_numpy(y)
def __getitem__(self,index):
return self.x_data[index],self.y_data[index]
def __len__(self):
return self.len
#加载数据
model =ModelDemo.Model()
criterion = torch.nn.BCELoss(reduction="mean")
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
dataset = TitannikDataset(x_train,y_train)#要传入特征 和 标签
train_loader = DataLoader(dataset = dataset,shuffle=True,batch_size=32,drop_last=True,num_workers=2)
def train(epoch):
#取出小批量
for i,data in enumerate(train_loader,0):
input,label =data
y_pred = model(input)
loss = criterion(y_pred,label)
optimizer.zero_grad()#梯度置零
loss.backward()
optimizer.step()
print("epoch :", epoch, i, loss.item())
if epoch%200== 199:
torch.save(model.state_dict(), "model/model_taitan.pth")
torch.save(optimizer.state_dict(), "model/optimizer_taitan.pth")
print("epoch :{}训练次数为:{},损失值为:{}".format(epoch,i, loss.item()))
if __name__ == '__main__':
for epoch in range(200):
print({"————————第{}轮测试开始——————".format(epoch+ 1)})
train(epoch)
进行数据测试
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'
import torch
import numpy as np
import pandas as pd
from ModelDemo import Model
test = pd.read_csv("test.csv")
x_test =test[["Pclass", "Sex", "SibSp", "Parch", "Fare"]]
x_test = pd.get_dummies(x_test)
x_test_id = test[["PassengerId"]]
model =Model()
if os.path.exists('model/model_taitan.pth'):
print("ok")
model.load_state_dict(torch.load("model/model_taitan.pth"))
#optimizer.load_state_dict(torch.load("model/optimize_taitan.pth"))
def test ():
with torch.no_grad():
x_test_ =x_test.values.astype(np.float32)
x_test_ =torch.Tensor(x_test_)
#datafrom to numpy .values
#numpy to tensor torch.from_numpy
y_pred = model (x_test_)
y_pred_label = torch.where(y_pred>=0.5,torch.tensor([1.0]),torch.Tensor([0.0]))
y_pred_label = y_pred_label.flatten()#torch.Size([418])
print(y_pred_label.shape)#torch.Size([418, 1])
y_pred_label = y_pred_label.to(torch.int64) #提交测试集需要整数
output = pd.DataFrame({'PassengerId': x_test_id.PassengerId, 'Survived': y_pred_label})
output.to_csv('my_predict.csv', index=False)
if __name__ == '__main__':
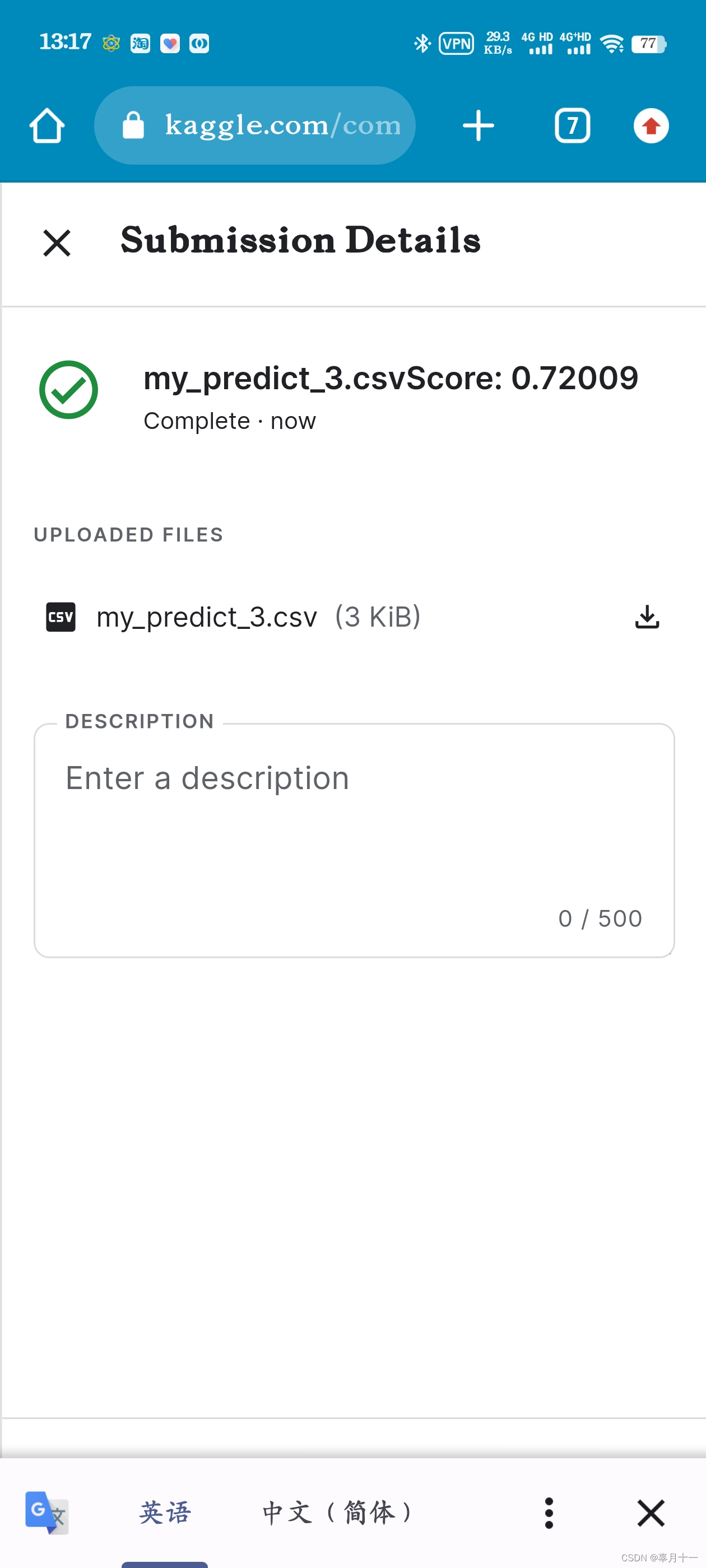
test()提交结果


















 656
656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











