







 本文详细介绍了使用Maven、Spring框架、MyBatis分页插件及Swagger工具进行前后端分离开发的过程,涵盖数据库设计、接口API实现、前端Vue界面搭建等内容。
本文详细介绍了使用Maven、Spring框架、MyBatis分页插件及Swagger工具进行前后端分离开发的过程,涵盖数据库设计、接口API实现、前端Vue界面搭建等内容。
1、数据库模型设计,使用powerDesigner将数据库结构生成pdm文件,便可以直接使用其SQL语句生成数据库;
2、新建maven工程, 根据引入的catalog,会将java api 代码和web页面分成两个模块, 两个模块各自有resource目录,其中
web模块中有config目录,用来配置数据库以及spring框架等信息:
数据库配置:
jdbc.driver=com.mysql.jdbc.jdbc2.optional.MysqlXADataSource
jdbc.url=jdbc:mysql://XXXXXX?useUnicode=true&characterEncoding=utf-8
jdbc.username=XXX
jdbc.password=XXX
jdbc.reconnect=true
在数据库的使用方面,如果不使用框架配置的话,也是可以自己用java代码连接的:
private static Connection getConn() {
Connection conn = null;
try {
Class.forName("com.mysql.jdbc.Driver"); //classLoader,加载对应驱动
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
String url = "jdbc:mysql://localhost:3306/test";
String username = "root";//数据库账户,一般为root
String password = "****";//数据库密码
try{
conn = DriverManager.getConnection(url, username, password);
} catch (SQLException e) {
e.printStackTrace();
}
return conn;
}
其他关于框架的配置信息在spring-mvc.xml 中, web模块负责后面放在tomcat容器中运行。
此处注意如果在运行后访问之后要有页面显示的话,记得在webapp 下的 WEB-INF 目录下添加index.html,访问路径记得使用IP+端口,然后就是项目路径:
而java API 模块中则负责后台业务逻辑,传统的分成处理: Controller 、service、Dao、Entity,以及数据库执行语句放在mapper中:
当然还有测试代码,有自己的包和位置,注意,测试模块有自己的数据库以及其他资源配置文件,在测试时需要同步修改:
3、为了使自己的后台接口能够很好地给前端阅读和使用,需要引入swagger工具来展示:
具体就是在pom.xml文件中引入jar包:
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.4.0</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.4.0</version>
</dependency>
然后增加一个配置类来启动:
@EnableSwagger2
@Configuration("areaSwaggerConfig")
public class SwaggerConfig {
}
因为这个类的放置目录在基准目录下,已经在sping-mvc.xml中配置了扫描,所以不用单独加扫描注解:

4 接口API实现
配置表用来给用户添加配置使用,所以基本的增删改查接口全部需要。
行政区划表由于是查询信息,对外只需要提供查询接口即可。
这其中主要是对注解的学习使用,刚开始不太了解,都是依葫芦画瓢,边用边学:
@RestController 这个注解在业务控制层中比controller注解要多一层东西,如果不用这个会报错;
@RequestMapping 用来指定访问路径的,暂时这么理解;
method = {RequestMethod.POST, RequestMethod.GET} 注意这种配置必须加好,后面对接前端会知道使用哪种方式操作。
@Autowired 自动装载,这个感觉还比较熟悉;
@ApiOperation 这个感觉就是一个说明作用,在swagger中可以描述接口作用;
@ModelAttribute 这个很重要,在swagger中如果要传对象参数,有了它才能真正传进来;
@CommonDao 这个是DAO层的注解,表明数据库的操作在哪个库,是通用库还是业务站点库;
@Service 这个是服务实现类中加的,没有它会报找不到对应的服务,应该就是在实例化对象的时候靠它了吧;
@Test 测试代码运行用的,这个貌似要在继承了 AbstractControllerTest 这个类中才能用,而且在使用时还发现个问题就是
像上面的那些@service @autowired 注解不是随便在一个类中加上都可以用的,需要在这种测试类中才行,了解到的是需要在spring框架管理的类中才能使用;
另外再说一下返回值处理WebResponse,这个可以设置参数,返回结果给前端,有统一定义。
5、数据库SQL语句
由于查询的要求为返回精确匹配和模糊匹配的结果集合,并且精确匹配排在前面。刚开始由于对于在mapper.xml中使用sql不熟悉,所以在java代码中来实现,即通过使用Criteria 来设置了两个不同类型的查询条件,分别返回两个结果集之后,在将其按照顺序加入到另外一个列表集合中,返回给前端:
private void setCriteria(Criteria cri, Area area, String type){
if (null == cri || null == area || null == type) {
return ;
}
Integer id = area.getId();
Integer parentId = area.getParentId();
String code = area.getCode();
String cityCode = area.getCityCode();
String name = area.getName();
String mergerName = area.getMergerName();
String shortName = area.getShortName();
String mergerShortName = area.getMergerShortName();
String level = area.getLevel();
String zipCode = area.getZipCode();
String pinYin = area.getPinYin();
String jianPin = area.getJianPin();
String firstChar = area.getFirstChar();
String lng = area.getLng();
String lat = area.getLat();
String remark = area.getRemark();
// 通过area各个非空字段,模糊匹配后得到返回结果
if (null != id) {
// 整型变量不用模糊查询
cri.andIdEqualTo(id);
}
if (null != parentId) {
// 整型变量不用模糊查询
cri.andParentIdEqualTo(parentId);
}
if ("like".equals(type)) {
if(StringUtils.isNotBlank(code)){
cri.andCodeLike("%"+code+"%");
}
if(StringUtils.isNotBlank(cityCode)){
cri.andCityCodeLike("%"+cityCode+"%");
}
if(StringUtils.isNotBlank(name)){
cri.andNameLike("%"+name+"%");
}
if(StringUtils.isNotBlank(mergerName)){
cri.andMergerNameLike("%"+mergerName+"%");
}
if(StringUtils.isNotBlank(shortName)){
cri.andShortNameLike("%"+shortName+"%");
}
if(StringUtils.isNotBlank(mergerShortName)){
cri.andMergerShortNameLike("%"+mergerShortName+"%");
}
if(StringUtils.isNotBlank(level)){
cri.andLevelLike("%"+level+"%");
}
if(StringUtils.isNotBlank(zipCode)){
cri.andZipCodeLike("%"+zipCode+"%");
}
if(StringUtils.isNotBlank(pinYin)){
cri.andPinYinLike("%"+pinYin+"%");
}
if(StringUtils.isNotBlank(jianPin)){
cri.andJianPinLike("%"+jianPin+"%");
}
if(StringUtils.isNotBlank(firstChar)){
cri.andFirstCharLike("%"+firstChar+"%");
}
if(StringUtils.isNotBlank(lng)){
cri.andLngLike("%"+lng+"%");
}
if(StringUtils.isNotBlank(lat)){
cri.andLatLike("%"+lat+"%");
}
if(StringUtils.isNotBlank(remark)){
cri.andRemarkLike("%"+remark+"%");
}
} else if ("equal".equals(type)) {
if(StringUtils.isNotBlank(code)){
cri.andCodeEqualTo(code);
}
if(StringUtils.isNotBlank(cityCode)){
cri.andCityCodeEqualTo(cityCode);
}
if(StringUtils.isNotBlank(name)){
cri.andNameEqualTo(name);
}
if(StringUtils.isNotBlank(mergerName)){
cri.andMergerNameEqualTo(mergerName);
}
if(StringUtils.isNotBlank(shortName)){
cri.andShortNameEqualTo(shortName);
}
if(StringUtils.isNotBlank(mergerShortName)){
cri.andMergerShortNameEqualTo(mergerShortName);
}
if(StringUtils.isNotBlank(level)){
cri.andLevelEqualTo(level);
}
if(StringUtils.isNotBlank(zipCode)){
cri.andZipCodeEqualTo(zipCode);
}
if(StringUtils.isNotBlank(pinYin)){
cri.andPinYinEqualTo(pinYin);
}
if(StringUtils.isNotBlank(jianPin)){
cri.andJianPinEqualTo(jianPin);
}
if(StringUtils.isNotBlank(firstChar)){
cri.andFirstCharEqualTo(firstChar);
}
if(StringUtils.isNotBlank(lng)){
cri.andLngEqualTo(lng);
}
if(StringUtils.isNotBlank(lat)){
cri.andLatEqualTo(lat);
}
if(StringUtils.isNotBlank(remark)){
cri.andRemarkEqualTo(remark);
}
}
//return cri;
}
// 将精确匹配和模糊匹配结果进行排序组装
// result = new ArrayList<>();
// //精确匹配
// result.addAll(areas);
// //模糊匹配
// result.addAll(areaLike);
// System.out.println("=====selectAreaByConfig result=" + (result == null ? null : result.toString()));
// records = new PageList<>();
// records.addAll(areas);
// records.addAll(areaLike);
// records = new PageList<>();
// records.addAll(record1);
这种功能是能够实现,但是后面遇到的问题就是分页不能兼容。那么接下来就说分页的事情吧,为啥要用分页呢,还不是因为数据量太大,一个子 慢 。。。。 因为从网上找到的我国新政区划五级联动信息有七十多万条记录,如果一次查询全部吐出来,那真是急死个人呢。
使用的分页查询框架为:
https://github.com/miemiedev/mybatis-paginator
其主要原理看了下,应该就是先根据索引,查询出符合条件的总条数,然后根据传入的每页显示条数,来计算出页数,然后每次返回的结果就会根据传入参数来设置sql语句中的offset 和 limit 参数了。其实我也还是不懂,这种在查询总条数的时候应该也还是很耗时,但是事实胜于雄辩,可能是在返回结果集的时候限制了条数,能够起到很大的作用,来缩短时间。
使用方法比较简单,就是在接口中增加PageParam pageParam 参数,
在接口增加如下参数:
PageModel pgResult = new PageModel(pageParam);
PageBounds pageBounds = new PageBounds(pageParam.getPageNo(), pageParam.getPageSize());
PageList<Area> records = null;
records = areaMapper.selectAreaByConfig(fields, areaExample,
areaExampleLike, pageBounds);
// 返回对应的配置字段信息, 匹配查询条件
if (records != null){
pgResult.setTotal(records.getPaginator().getTotalCount());
pgResult.setRows(records);
}
return pgResult;
由于这个分页框架是直接对SQL语句进行增加offset 和 limit 参数处理,因为不能使用前面那种在java代码中对结果集进行排序处理,所有的动作都需要在SQL语句中完成,包括查询、排序、去重等等。
so, 我们来聊聊SQL语句,mybatis:
最终的语句:
<select id="selectAreaByConfig" resultMap="BaseResultMap" parameterType="com.XXXXXX.area.entity.AreaExample" >
select DISTINCT ${fields} FROM (
select ${fields}, 1 as orderField
from hz_sys_area
<if test="_parameter != null" >
<include refid="query_By_Example1_Where_Clause" />
</if>
union
select ${fields}, 2 as orderField
from hz_sys_area
<if test="_parameter != null" >
<include refid="query_By_Example2_Where_Clause" />
</if>
ORDER BY orderField
) AS AREA_TABLE
</select>
其实主要思路就是根据将精确和模糊匹配的两个条件分别查询,然后联合union, 最后根据各自新增定义的排序字段排序,然后再从这个结果集中选择最终结果,并且增加了distinct 字段来去重,当然这里面的ID 是不会有重复的,因为数据库信息是自己的控制插入的行政区划信息。
当然这其中主要是学习mybatis框架中的对于数据库操作的用法,例如参数如何传递,_parameter 以及param1, param2 等等默认参数变量的用法,还有就是# 和 $ 的区别和用法等。
5、前端界面vue
关于前端界面的实现,主要是用别人搭好的框架,因为之前没有开发过前端,只是有个感性的认识。按照目前前端那边流行的用法,就是要用vue框架,这个东西运行环境需要装Node.js ,搞好之后通过npm install 命令安装一些依赖库(package.json),然后npm start 命令来启动前端。
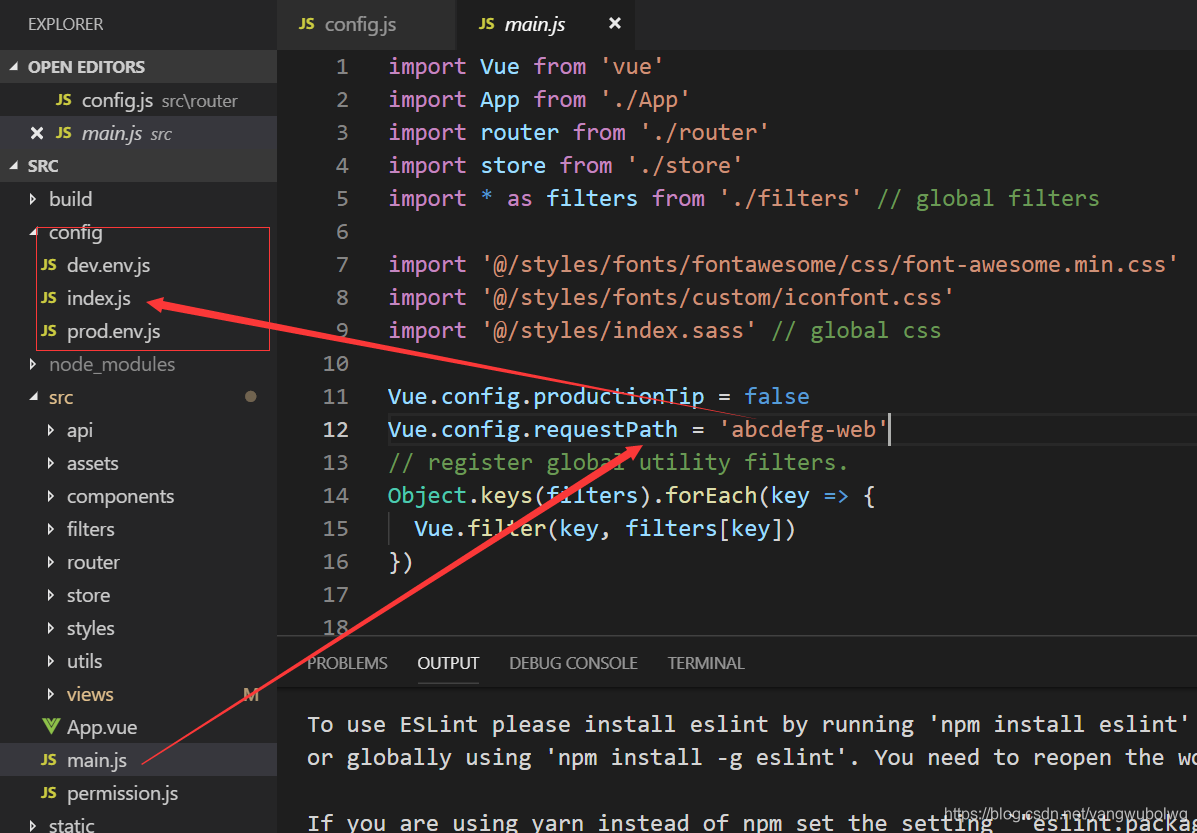
其中需要说明的就是有个路由配置,即启动什么项目,对应的项目的后端接口地址,需要进行配置:
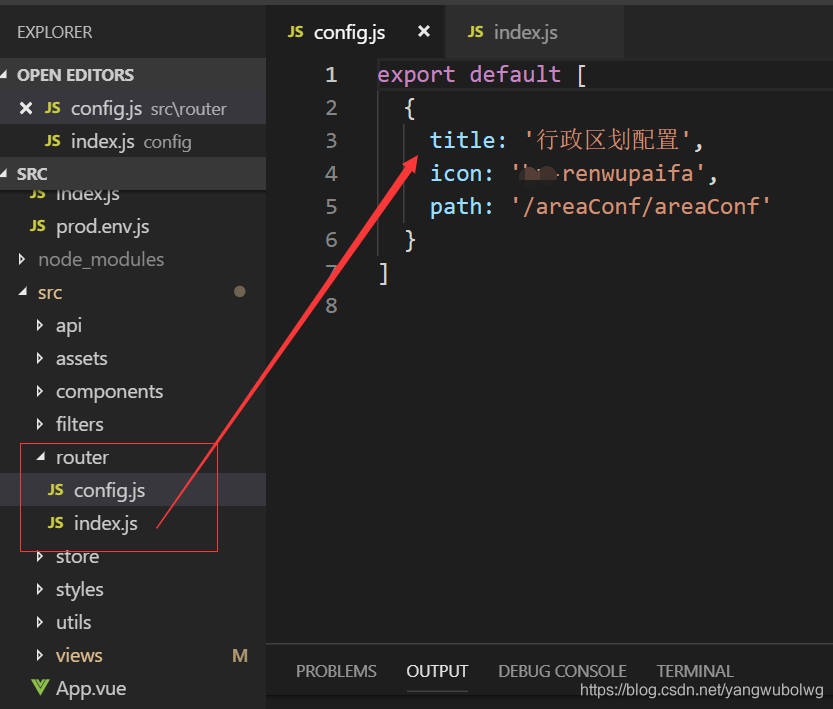
然后就是具体界面中对于各个菜单的配置:
具体界面的实现在vue文件中,目前的理解为整体文件分三部分:
模板template
数据data
方法method
还有后端接口的调用,可以单独放置在一个api.js文件中,通过回调来传递数据参数。
最后又依葫芦画瓢,吭哧吭哧将这个列表界面和增删改查界面做出来了:
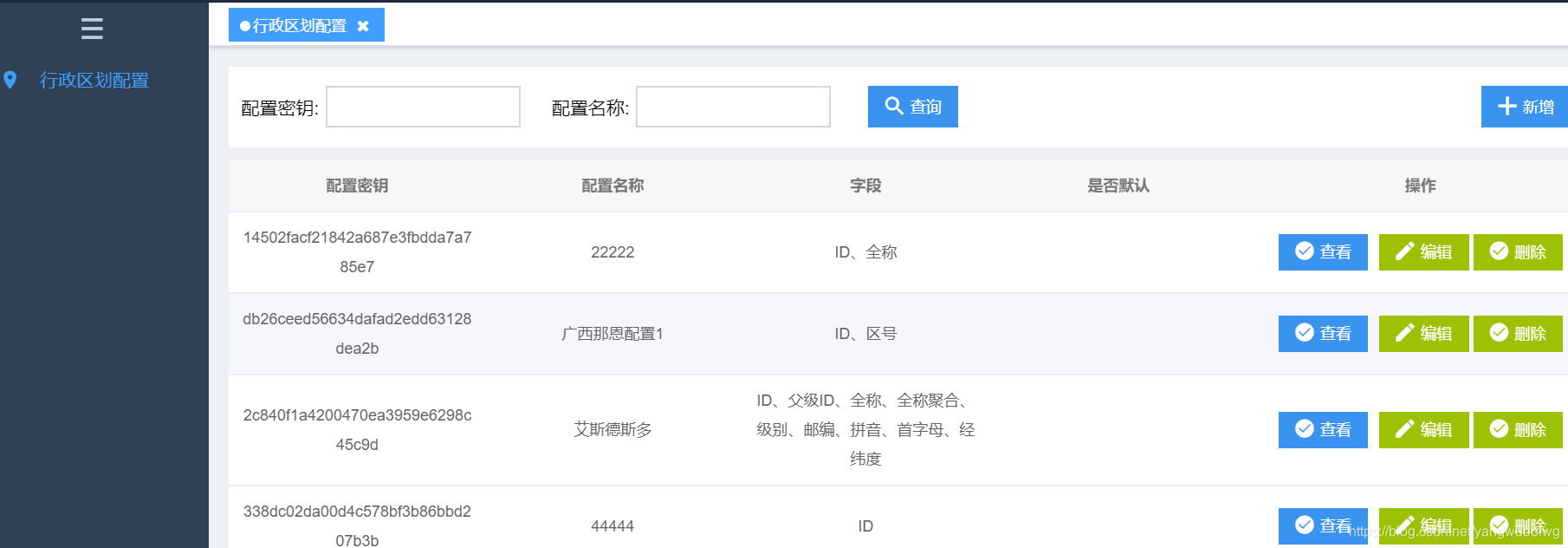
总体来说还是挺有意思的,新东西挺多,所以感觉学到了东西,对于一块白纸来说,一滴墨水已经够了。

















 2649
2649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









