






我的配置(linux)
这里是在阿里云的DSW交互式建模的示例。
下载anaconda
apt-get updateapt-get install libgl1-mesa-glx libegl1-mesa libxrandr2 libxrandr2 libxss1 libxcursor1 libxcomposite1 libasound2 libxi6 libxtst6wget https://mirrors.ustc.edu.cn/anaconda/archive/Anaconda3-2024.06-1-Linux-x86_64.shbash Anaconda3-2024.02-1-Linux-x86_64.sh随后是一群协议,一直按enter键就好了
然后让输入yes/no
输yes
后面的直接enter
source ~/.bashrc然后重启terminal
配置anaconda镜像
查看当前库
conda config --show channels删除原库
conda config --remove channels defaults配置清华镜像库
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
创建新的conda虚拟环境命令(后面有创建这里就看)
conda create -n <虚拟环境名称> python=<py大版本,如3.10或3.9>这里要输入y
conda activate <虚拟环境名称>看一下新的python环境里的包
pip listLanchain-Chatchat依赖配置
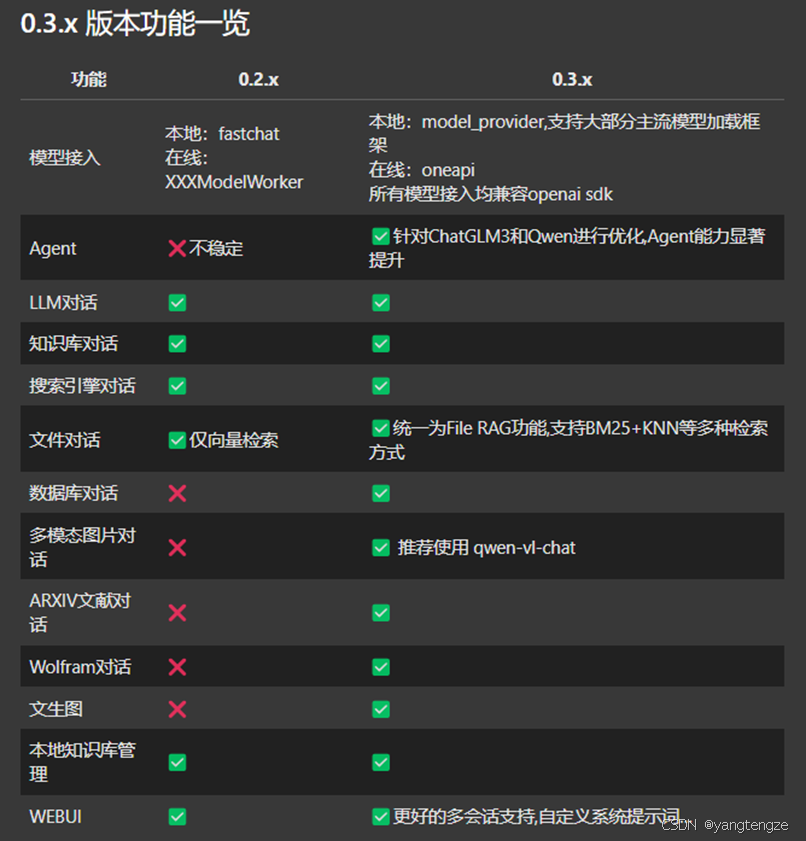
Git clone https://github.com/chatchat-space/Langchain-ChatchatLangchain-chatchat0.3版本功能:
创建conda虚拟环境
不用anaconda环境的要先具备python环境
python -m venv <虚拟环境名称>这时会生成一个文件夹,文件夹名称就是<虚拟环境名称>,这里假设<虚拟环境名称>为venv
./venv/bin/activate若没权限就
source ./venv/bin/activate测试
pip list接下来就是创两个虚拟环境(Langchain环境、Xinference环境)
后面就大差不差了。
注意建两个环境,并且要在两个命令行启动
Langchain环境
conda create -n langchain python=3.10conda activate langchainpip install langchain-chatchat -U
Xinference环境
conda activate xinferenceconda activate xinferencepip install "xinference[all]"启动xinference
xinference-local --host 0.0.0.0 --port 9997
注意ctrl+左键点击http://0.0.0.0:9997
Xinference使用
启动GLM4
进入http://0.0.0.0:9997页面
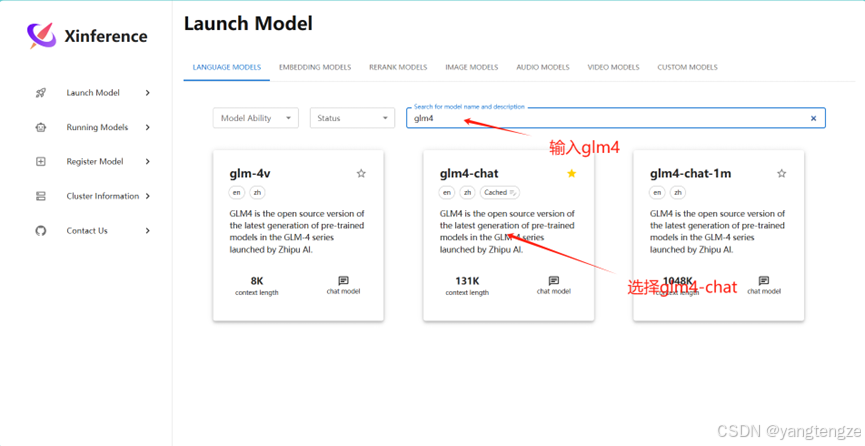
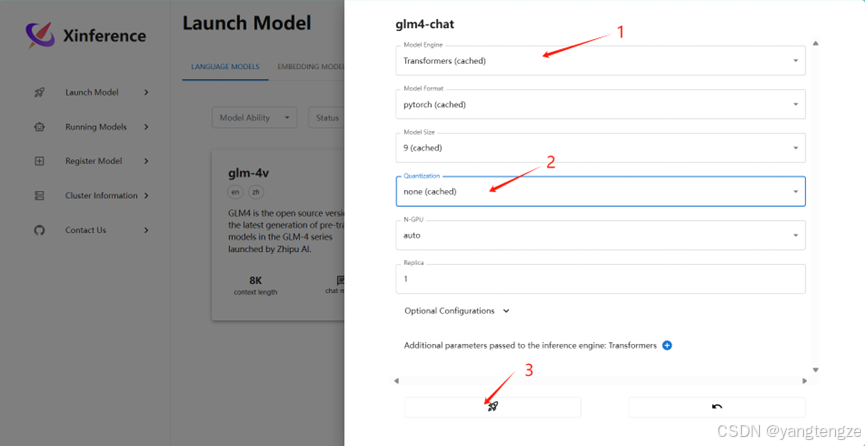
这是在xinference终端看到

就表示部署成功了。(如果这里不显示,终端显示一致,就刷新就好了,虽说他说不要刷新)
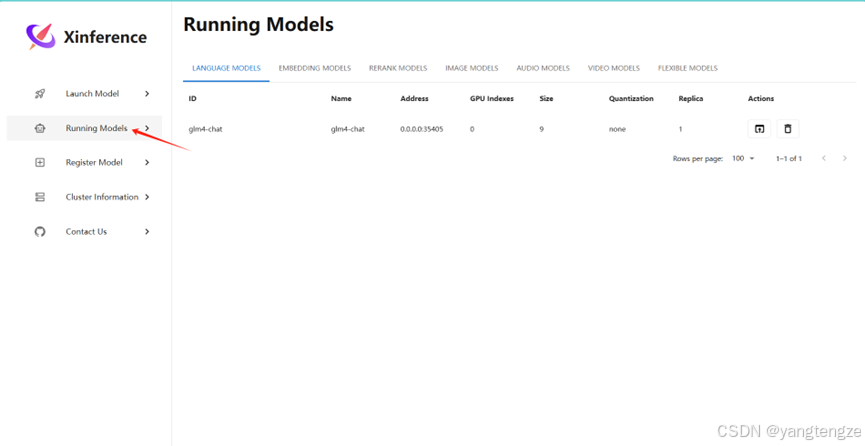
启动bge-large-zh-v1.5

这是看到终端有以下显示就部署成功了
xinference是这么显示的

测试GLM4
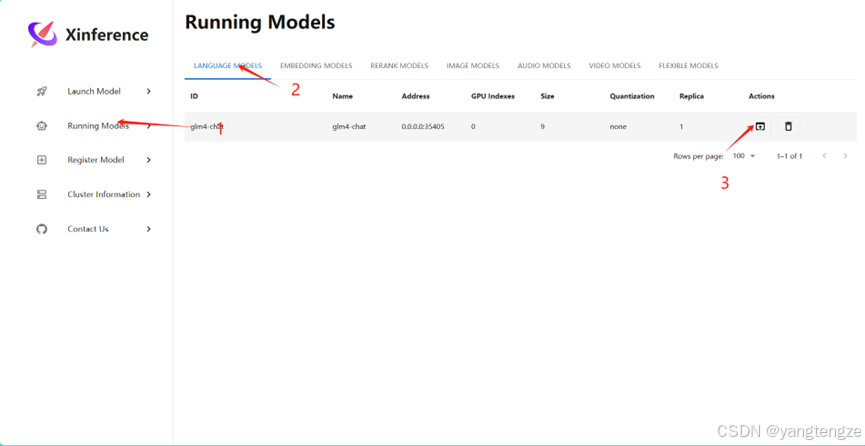
点击后跳转页面。
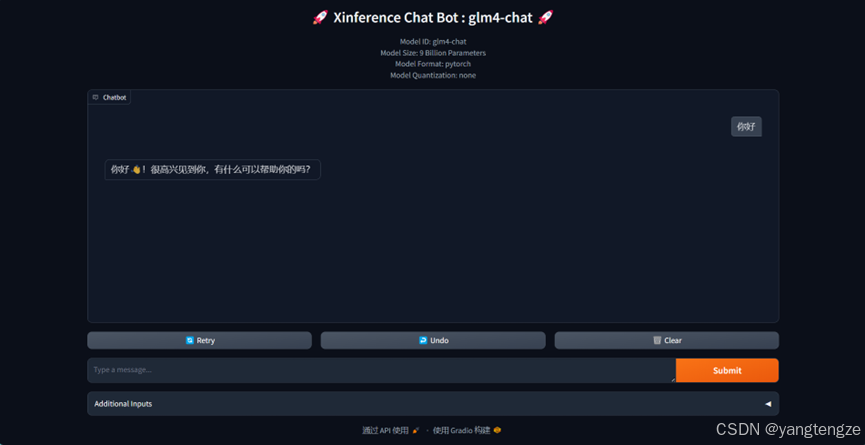
上面都没错误就成功了,接下来配置Langchain-chatchat的环境配置
langchain-Chatchat环境配置
注意先启动xinference和模型。
切换到Langchain环境
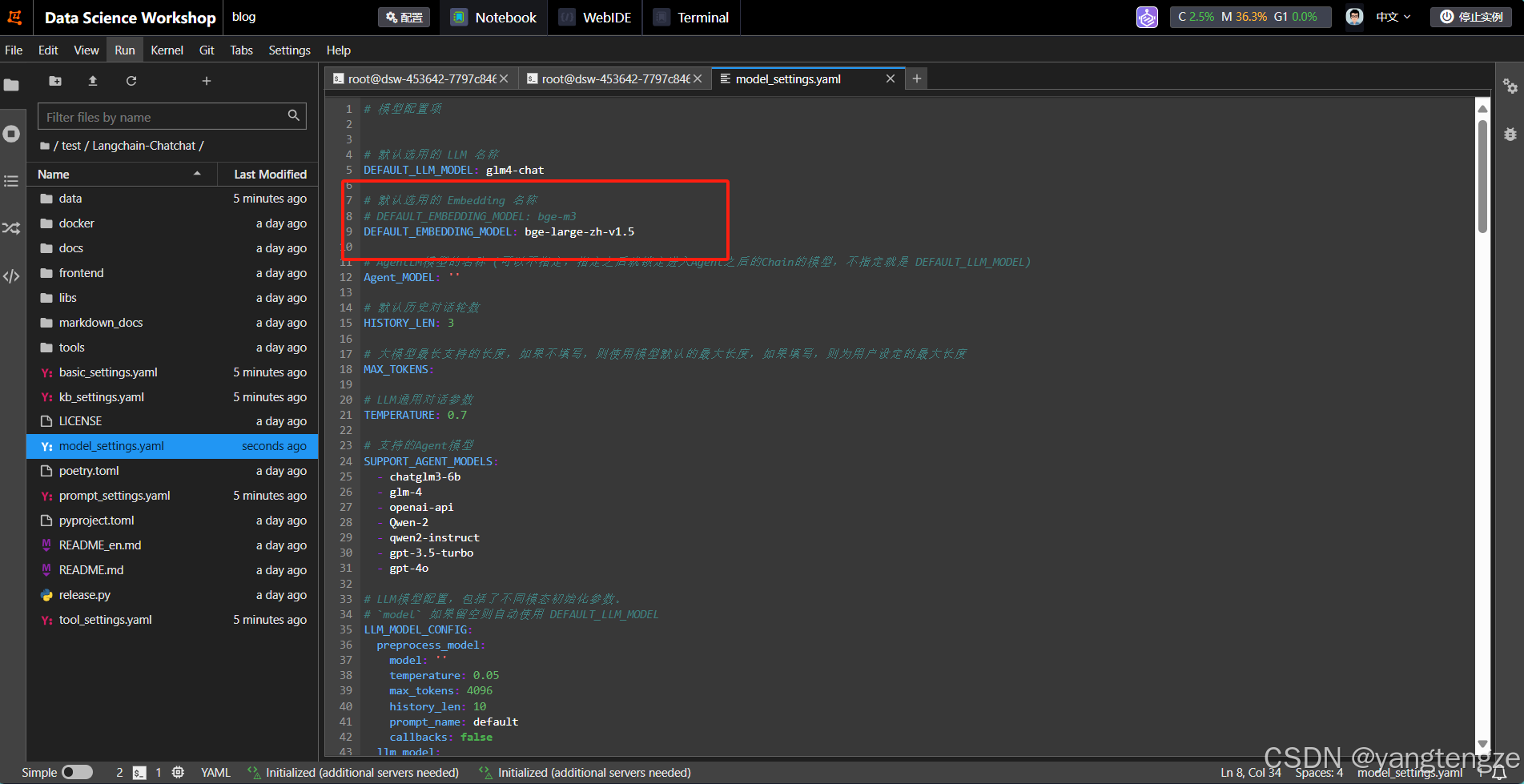
chatchat init修改model settings.yaml文件
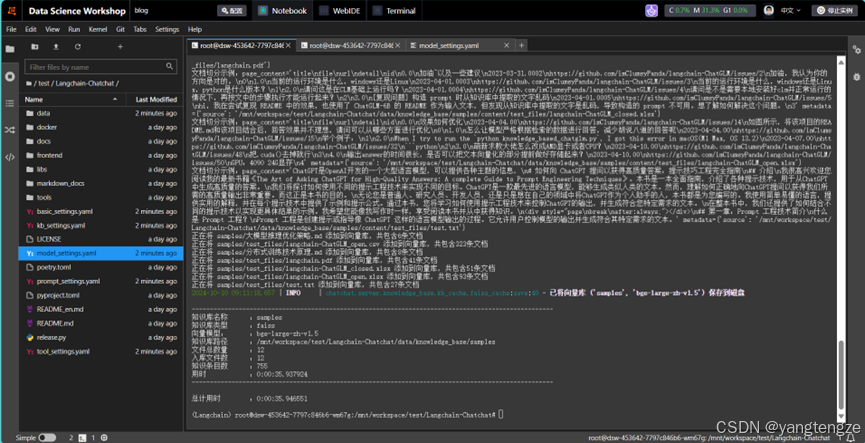
chatchat kb -r显示如下就没问题了。
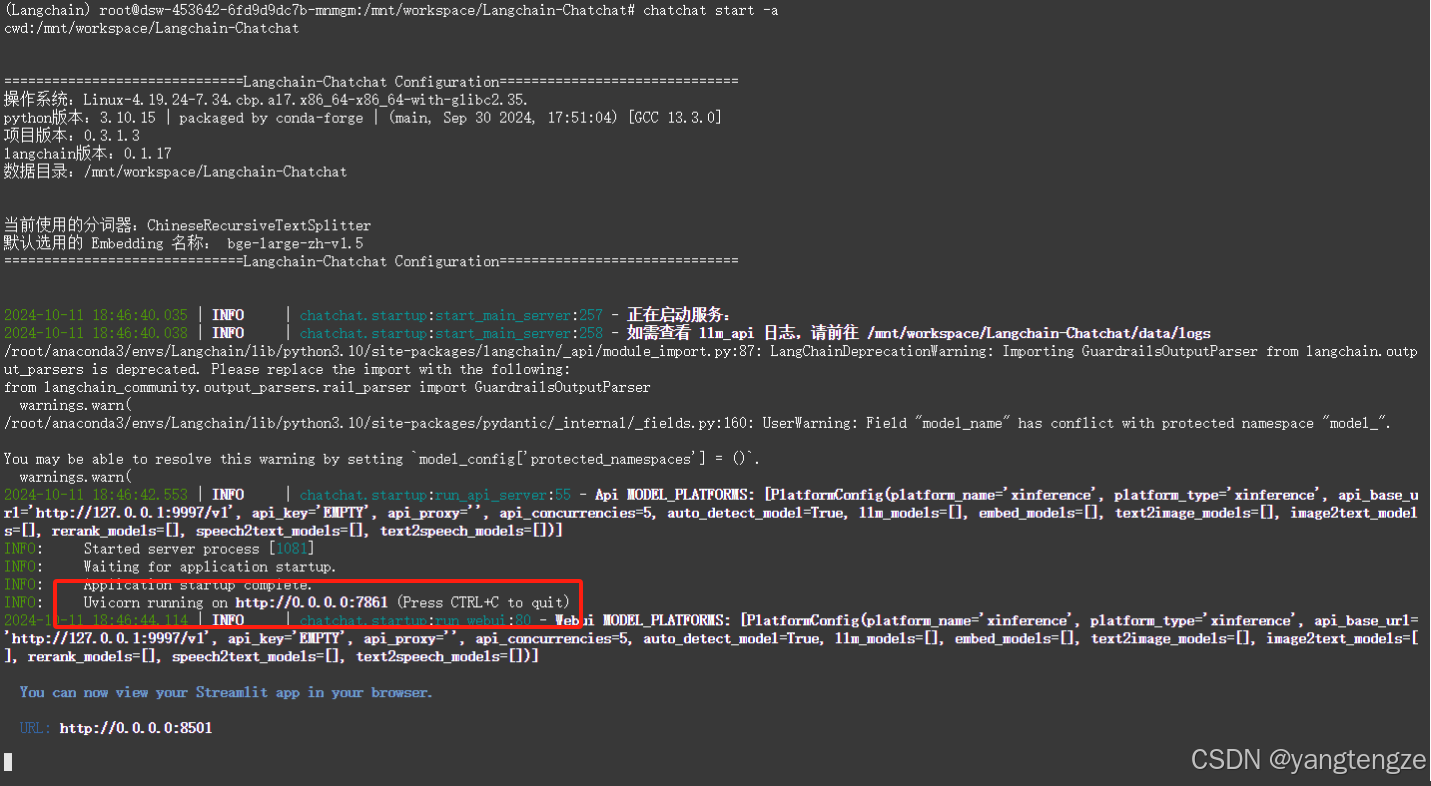
chatchat start -a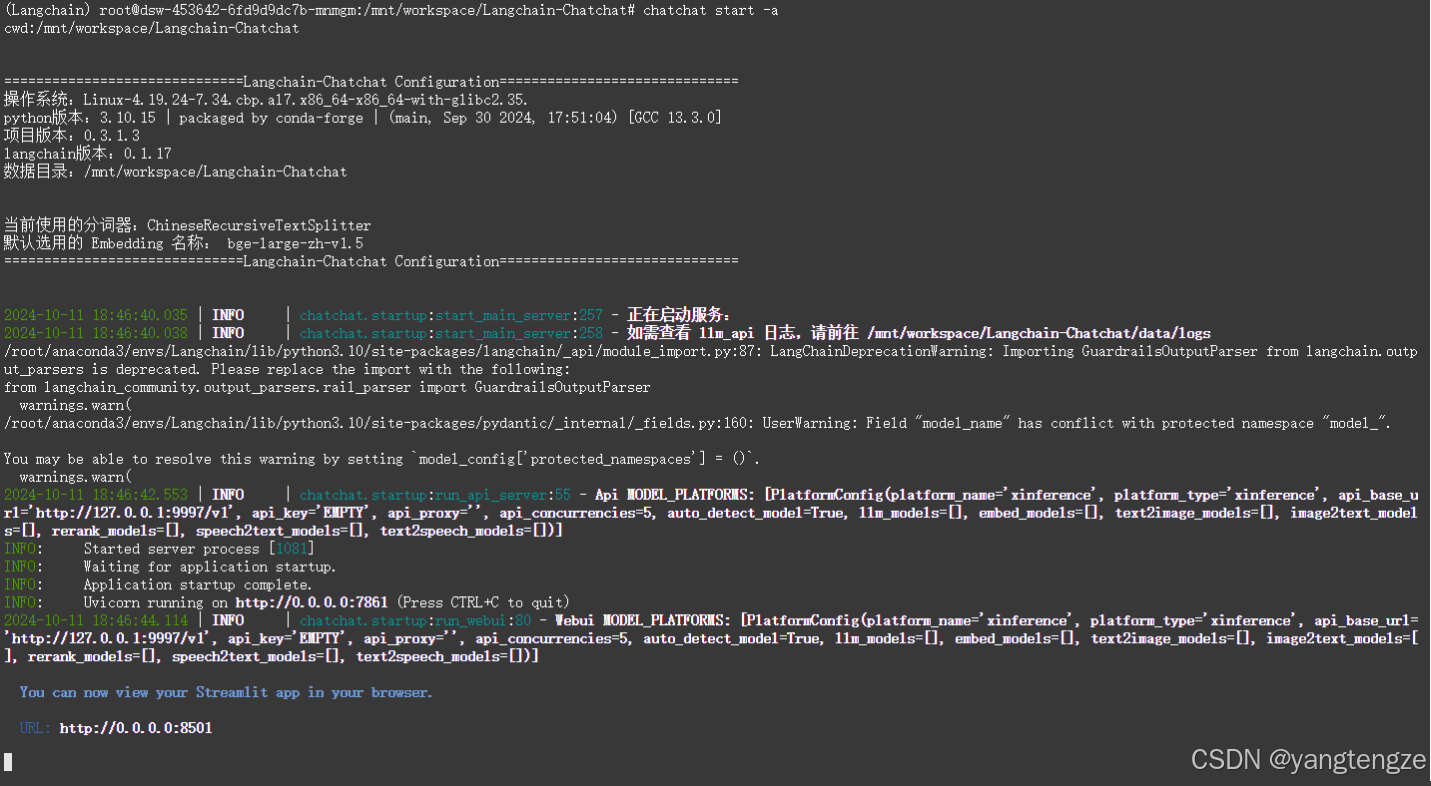 点开http://0.0.0.0:8501,最好ctrl 并点一下,没报错就好了。
点开http://0.0.0.0:8501,最好ctrl 并点一下,没报错就好了。
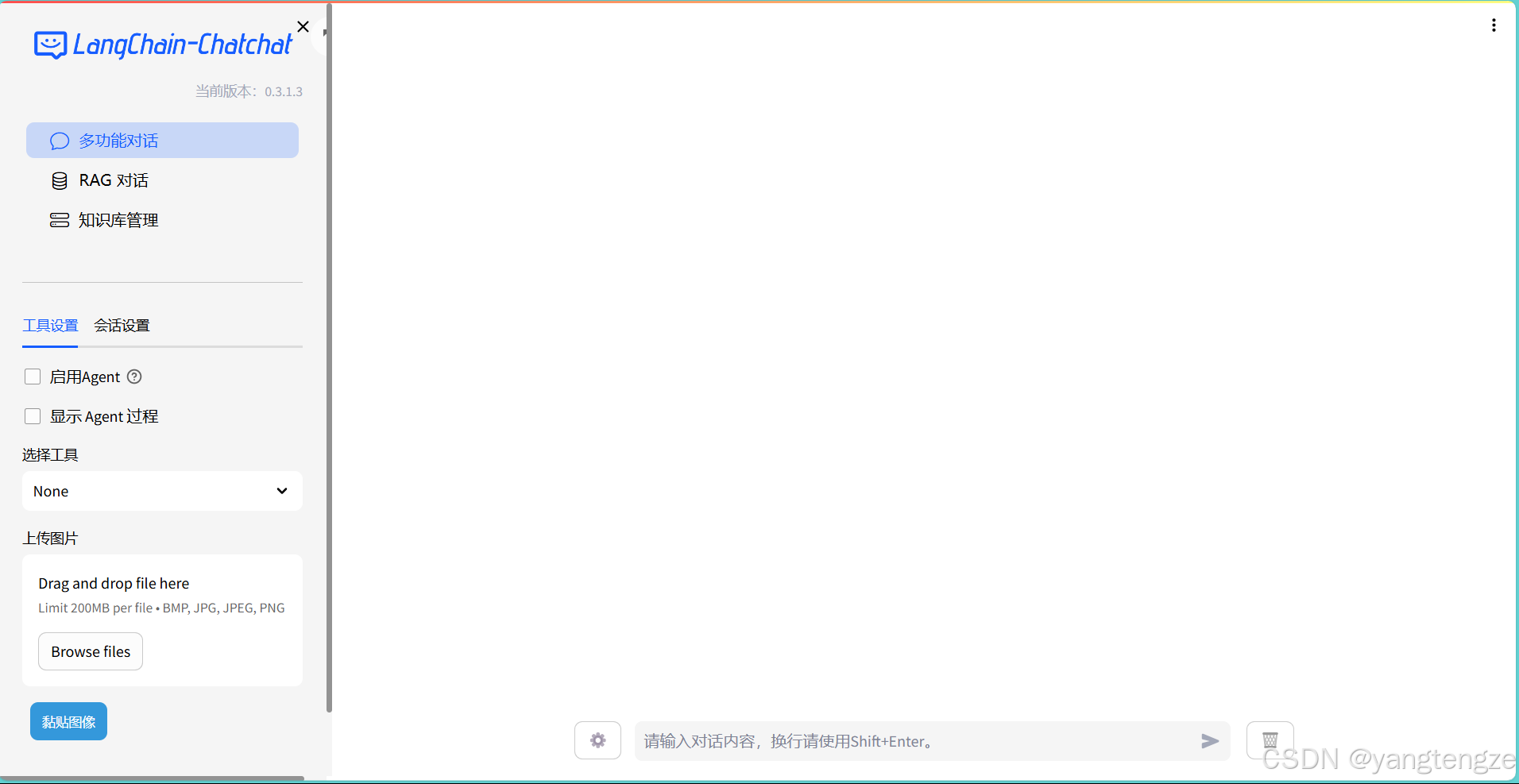
启动后直接点击RAG对话进行提问就行了。
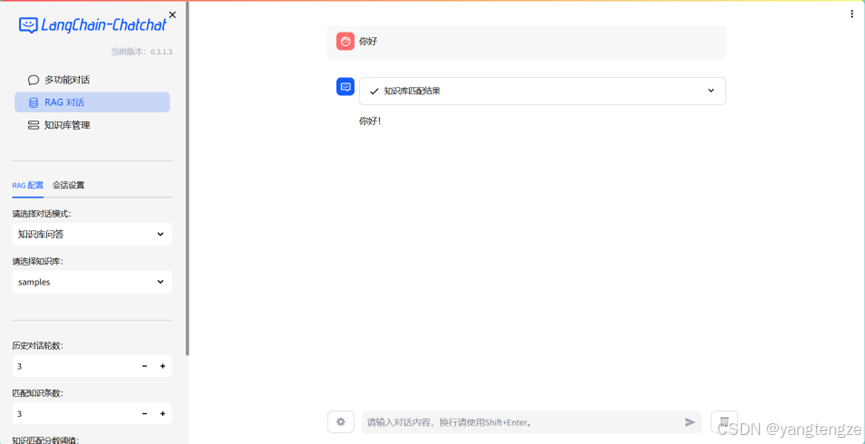
使用Langchain的API Server工具以备后续其他程序调用这里是python调用
测试API Server
进入http://0.0.0.0:7861,最好ctrl 并点一下
点击post方法的与知识库对话
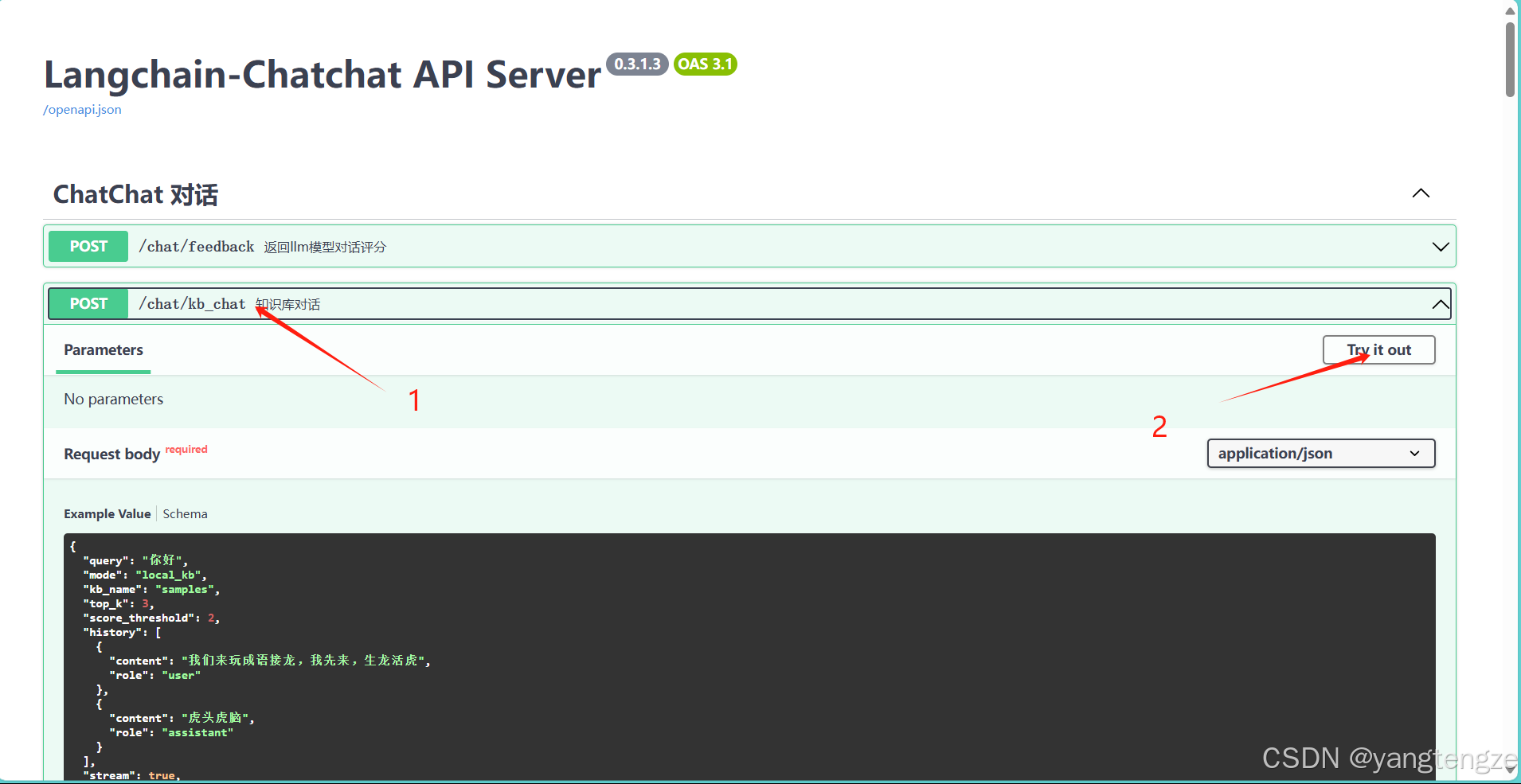
然后点击execute执行就是测试了。
运用API Server 这里用python
api.py 文件(注意只取api.py文件)
git clone https://github.com/yangtengze/Langchain-RAG-GLM4.git(小插曲)这是文件内容,也感谢大家访问我的GitHub: https://github.com/yangtengze
在Langchain环境下运行api.py 就可以用了。
streamlit run api.py当然也可以其他方式调用。(如js、等等,这里是示例而已,后续也会更新)
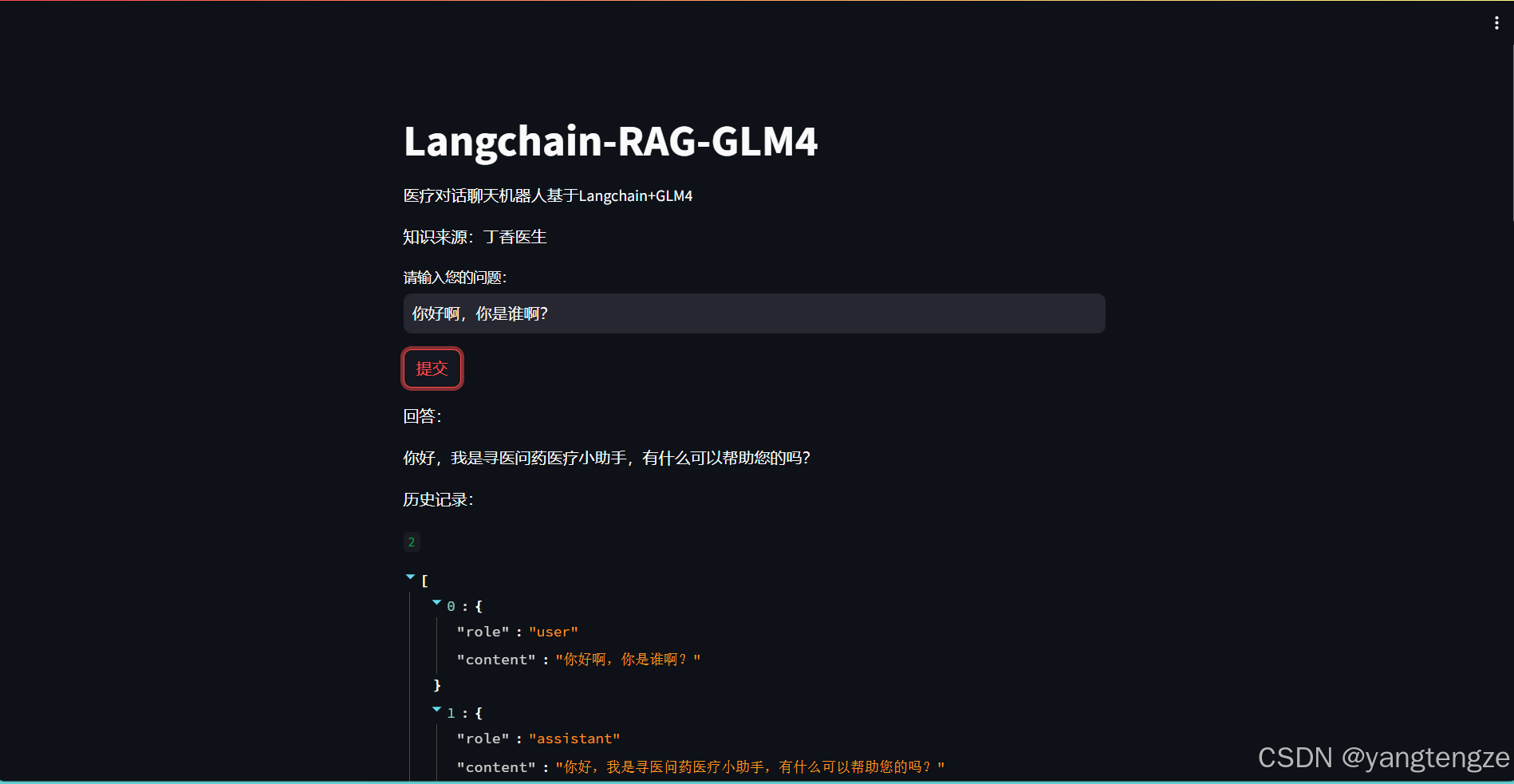
这里再展示下效果:

















 1951
1951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









