



在为yolo模型添加模块时,总是会涉及ultralytics/nn/tasks.py源码的修改。但一般是直接照搬的人家的工作,一直不清晰到底是咋修改的。这里记录一下对tasks.py源码中parse_model这个重要函数的学习,以便后续新增模块时能实现自主修改。
核心函数parse_model
输入参数
def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
d (dict): 一个包含模型结构定义的字典。通常是从 yolov8n.yaml 这样的 YAML 配置文件读取并解析得到的。
ch (int): 输入通道数(Input Channels)。通常是 3(RGB 图像)。
verbose (bool): 是否打印模型的详细信息(如每层的输出形状),用于调试。
返回值
return torch.nn.Sequential(*layers), sorted(save)
torch.nn.Sequential(*layers): 一个 torch.nn.Sequential 对象,它包含了整个神经网络的所有层,按顺序堆叠。
sorted(save): 输出层排序列表,包含所有需要保存其输出的层的索引(从 0 开始)。这些层的输出通常会被后续的 Neck(如 PAN-FPN)或 Head 使用。
核心功能
- 读取配置:
从字典 d 中提取关键信息,如:
d[‘backbone’]: 主干网络的层定义。
d[‘head’]: 检测头的层定义。
d[‘anchors’]: 锚框设置(如果使用)。
d[‘nc’]: 类别数量。 - 初始化:
创建一个空的 nn.Sequential 容器 model。
创建一个列表 save 用于记录哪些层的输出需要被保存(供后续层使用)。
创建一个列表 c2 用于记录每一层的输出通道数,方便下一层配置。 - 逐层构建网络:
函数会遍历 backbone 和 head 中定义的每一层。
对于每一层定义(如 [-1, 1, Conv, [64, 3, 2]]),它会:
[-1, …]: 表示该层的输入来自前一层(-1 表示上一层,-2 表示上上层,6 表示第 6 层的输出)。
1: 表示该模块(如 Conv)需要重复的次数。
Conv: 表示模块的类名(在代码中会映射到 nn.Conv2d 或自定义的 Conv 模块)。
[64, 3, 2]: 传递给 Conv 模块的参数,如 [out_channels, kernel_size, stride]。 - 动态计算输入通道:
对于每一层,函数会根据其输入来源(f)查找之前层的输出通道数 c2[f],作为当前层的输入通道 c1。 - 实例化模块并添加到模型:
根据模块名(如 Conv, Bottleneck, SPPF)和参数,动态创建 PyTorch 模块实例。
将该实例添加到 model 这个 Sequential 容器中。 - 记录需要保存输出的层:
如果某一层的索引出现在后续层的输入定义中(如 f in [4, 6]),则将其索引添加到 save 列表中。
最终 save 会被排序并去重。 - 打印模型信息(如果 verbose=True):
打印每层的序号、输出形状、参数数量等,方便用户检查模型结构。
parse_model 函数就像是一个 “模型装配工厂”:
输入: 一份“设计图纸”(model.yaml 解析成的字典 d)。
过程: 按照图纸上的指令,一层一层地创建 PyTorch 模块,并将它们连接起来。
输出: 一个完整的、可训练的 PyTorch 神经网络模型(model)和一个记录关键节点的列表(save)。
它是 YOLO 实现高度模块化和可配置化的关键,允许用户通过修改简单的 YAML 文件来定义复杂的网络结构。
示例
假设 d[‘backbone’] 中有一行:
[[-1, 1, Conv, [64, 3, 2]]]
parse_model 会:
- 读取这一行。
- 发现输入来自 -1(上一层)。
- 获取上一层的输出通道数作为 c1。
- 创建一个 Conv 模块,参数为 [64, 3, 2](即输出 64 通道,3x3 卷积核,stride=2)。
- 将这个 Conv 层添加到 model 中。
- 记录当前层的输出通道数 c2 = 64。
- 如果后续层要用到这一层的输出,就将其索引加入 save。
函数详解
import ast
# Args
# 定义一个布尔变量 legacy,用于控制是否启用兼容旧版本模式,不同版本的 YOLO 可能在某些模块(如 BottleneckCSP)的实现上有细微差别。设置 legacy=True 可以确保旧模型能正确加载。
legacy = True # backward compatibility for v3/v5/v8/v9 models
# 定义一个变量 max_channels,表示通道数的最大限制。
max_channels = float("inf")
# 从配置字典 d 中提取三个关键参数:类别数、激活函数 和 尺度
nc, act, scales = (d.get(x) for x in ("nc", "activation", "scales"))
# 从配置字典 d 中提取三个缩放因子:深度倍率、宽度倍率 和 关键点形状。与上面不同,这里提供了默认值 1.0
depth, width, kpt_shape = (d.get(x, 1.0) for x in ("depth_multiple", "width_multiple", "kpt_shape"))
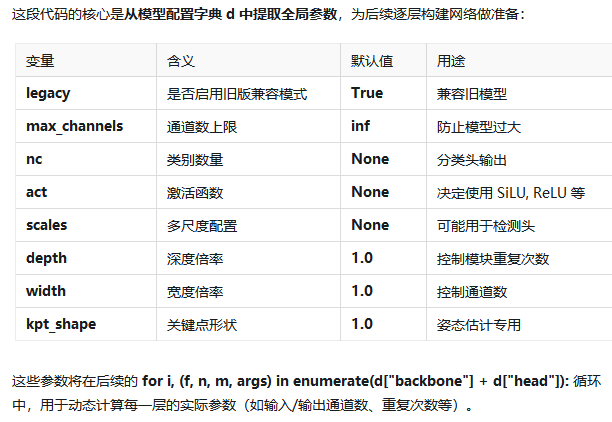
depth_multiple (深度倍率):
控制模型中重复模块的数量。
例如,Bottleneck 模块在 yolov8n.yaml 中可能重复 1 次,在 yolov8x.yaml 中可能重复 3 次。depth = 0.33 或 depth = 1.0 就是这个倍率。
width_multiple (宽度倍率):
控制模型中每一层的通道数。
例如,yolov8n 的 width=0.25,表示所有卷积层的通道数都乘以 0.25,使模型更小更快。
kpt_shape (关键点形状):
用于姿态估计(Pose Estimation) 模型。
表示每个对象的关键点数量和维度(如 [17, 3] 表示 17 个关键点,每个点有 x, y, visible 三个值)。
默认 1.0 表示不是姿态估计模型。
# scales 通常是一个字典,定义了不同模型尺寸(如 n, s, m, l, x)对应的 depth, width, max_channels.
# 这里首先检查之前从配置字典 d 中提取的 scales 变量是否存在且不为空。
if scales:
scale = d.get("scale")
# 如果用户没有指定scale(即 scale 为 None, "", 或不存在),则自动选择一个默认的 scale。
if not scale:
# 从 scales 字典的所有键(如 ['n', 's', 'm', 'l', 'x'])中,取第一个作为默认的 scale。
# 为什么是第一个? 通常排序是 n < s < m < l < x,取最小的 n 作为默认值比较安全。
# 示例: 如果 scales.keys() = ['n', 's', 'm'],则 scale = 'n'。
scale = tuple(scales.keys())[0]
LOGGER.warning(f"WARNING ⚠️ no model scale passed. Assuming scale='{scale}'.")
depth, width, max_channels = scales[scale]
# 作用: 检查之前提取的 act 变量是否存在(即配置文件中指定了激活函数)
# act 的值: 通常是字符串,如 "silu", "relu", "leaky_relu"。
if act:
# 重新定义Conv 模块的默认激活函数
Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = torch.nn.SiLU()
# 如果 verbose=True,则打印当前使用的激活函数。
if verbose:
LOGGER.info(f"{colorstr('activation:')} {act}") # print
# 如果 verbose=True,打印一个表头,用于后续显示每一层的详细信息
if verbose:
LOGGER.info(f"\n{'':>3}{'from':>20}{'n':>3}{'params':>10} {'module':<45}{'arguments':<30}")
这段代码完成了以下关键任务:
模型缩放 (Scales):
根据用户指定或默认的 scale(如 ‘n’),从 scales 字典中加载对应的 depth, width, max_channels。
这是 YOLO 实现 n/s/m/l/x 多尺寸模型的核心机制。
激活函数 (Activation):
动态设置 Conv 模块的默认激活函数(如 SiLU)。
使模型配置更加灵活。
日志输出:
在 verbose 模式下,打印激活函数信息和一个清晰的表头,为后续逐层打印模型结构做准备。
这三步确保了模型能够根据配置文件灵活地调整大小和行为,并提供清晰的构建过程日志,是 parse_model 函数中承上启下的关键部分。
# ch 变成了一个列表,用于记录每层的输出通道数。
ch = [ch]
# layers 用于收集所有模块实例
# save 用于记录需要保存输出的层索引
# c2 初始化为输入通道数
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
# 所有基础模块(Conv, Bottleneck, C2f, Detect, Segment 等)用于识别“标准模块”,可能采用通用创建流程
# 与普通 set 不同,frozenset 一旦创建就不能修改(不能添加或删除元素)。
base_modules = frozenset(
{
Classify, # YOLO 中用于图像分类任务的模块
...
}
)
# 支持重复参数的模块(BottleneckCSP, C2f, C3 等)用于识别“可重复模块”,需要根据 n 参数创建多个实例
repeat_modules = frozenset( # modules with 'repeat' arguments
{
BottleneckCSP, # YOLOv5 中的一个关键模块
...
}
)
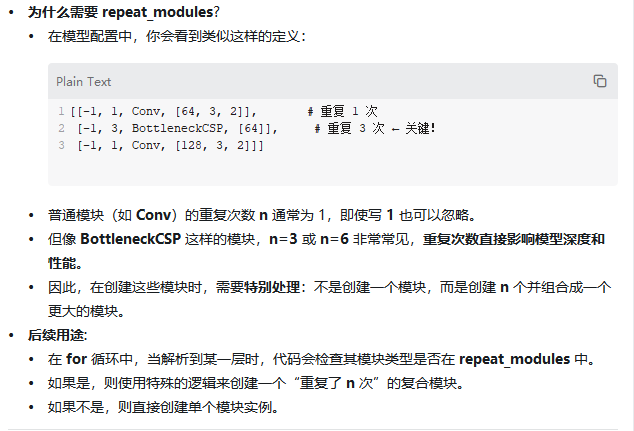
下面我们来深入解析 parse_model 函数的核心部分——这个庞大的 for 循环。它是整个函数的“引擎”,负责逐层解析配置、创建模块、计算通道数,最终构建出完整的 PyTorch 模型。
# d["backbone"] + d["head"]: 将主干网络和检测头的配置拼接成一个长列表
# enumerate(...): 遍历这个列表,同时获取索引 i 和每一层的定义 (f, n, m, args)
# f (from): 输入来源层的索引。-1 表示上一层,6 表示第 6 层
# n (number): 该模块重复的次数
# m (module): 模块的类名(字符串或类对象)
# args (arguments): 传递给模块构造函数的参数列表
for i, (f, n, m, args) in enumerate(d["backbone"] + d["head"]): # from, number, module, args
# 这里将 m(可能是字符串)转换为真正的 Python 类对象。 m 现在是一个可以调用的类(如 torch.nn.Conv2d)
# 三种情况:1."nn.Conv2d": 提取 "Conv2d",从 torch.nn 中获取类。 2."torchvision.ops.DeformConv2d": 提取 "DeformConv2d",从 torchvision.ops 中获取类。 3."Conv": 直接从当前模块的全局命名空间 globals() 中查找 Conv 类。
m = (
getattr(torch.nn, m[3:])
if "nn." in m
else getattr(__import__("torchvision").ops, m[16:])
if "torchvision.ops." in m
else globals()[m]
) # get module
# 将 args 列表中的字符串参数转换为实际的 Python 对象
for j, a in enumerate(args):
if isinstance(a, str):
# contextlib.suppress(ValueError): 安静地忽略 ast.literal_eval 可能抛出的 ValueError(如果字符串无法解析)
with contextlib.suppress(ValueError):
# 示例:
# args = [64, 'k'],如果 k = 3,则 'k' 会被替换为 3。
# args = [64, '[3, 3]'],'[3, 3]' 会被 ast.literal_eval 解析为列表 [3, 3]。
args[j] = locals()[a] if a in locals() else ast.literal_eval(a)
# 根据全局的 depth_multiple 因子调整模块的重复次数。 n_: 用于打印,记录原始的 n(缩放前)。 if n > 1: 只有当 n > 1 时才应用缩放,避免对单次模块(如 n=1 的 Conv)进行不必要的计算。
# 示例:
# 配置中 n=3,depth=0.33 → n = round(3 * 0.33) = 1
# 配置中 n=6,depth=1.0 → n = 6
n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gain
########################## 核心逻辑:根据不同模块类型处理 args 和 c2 ##########################################
# 这是循环中最复杂、最关键的 if-elif 链,根据不同模块类型动态计算输入/输出通道数 c1/c2 并调整参数 args
# 情况 1: m in base_modules (如 Conv, C2f, BottleneckCSP)
if m in base_modules:
# c1 = ch[f]: 输入通道数来自输入来源层 f 的输出通道。
# c2 = args[0]: 原始配置中的输出通道数
c1, c2 = ch[f], args[0]
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output) # # 如果不是分类头输出
# make_divisible(..., 8): 确保通道数是 8 的倍数(有利于 GPU 计算效率)
# width: 宽度倍率,用于缩放通道数(如 width=0.25 → 通道数 × 0.25)。
# args.insert(2, n): 对于 repeat_modules,将 n 作为模块的第三个参数传入(如 C2f(c1, c2, n=3, ...))。
c2 = make_divisible(min(c2, max_channels) * width, 8)
# 其他特殊模块处理
if m is C2fAttn: # set 1) embed channels and 2) num heads
args[1] = make_divisible(min(args[1], max_channels // 2) * width, 8)
args[2] = int(max(round(min(args[2], max_channels // 2 // 32)) * width, 1) if args[2] > 1 else args[2])
args = [c1, c2, *args[1:]] # 插入 c1, c2 作为前两个参数
if m in repeat_modules: # 如 BottleneckCSP, C2f
args.insert(2, n) # number of repeats # 将重复次数 n 插入到 args[2]
n = 1 # 重置 n,因为模块内部已处理重复
if m is C3k2: # for M/L/X sizes
legacy = False
if scale in "mlx":
args[3] = True
if m is A2C2f:
legacy = False
if scale in "lx": # for L/X sizes
args.extend((True, 1.2))
# 情况 2: m is AIFI (RT-DETR 的注意力模块)
elif m is AIFI:
args = [ch[f], *args] ## 输入通道作为第一个参数
# 情况 3: m in {HGStem, HGBlock} (Hourglass 模块)
elif m in frozenset({HGStem, HGBlock}):
c1, cm, c2 = ch[f], args[0], args[1] # 多个通道参数
args = [c1, cm, c2, *args[2:]]
if m is HGBlock:
args.insert(4, n) # number of repeats # n 作为第 5 个参数
n = 1
# 情况 4: m is ResNetLayer (ResNet 风格模块)
elif m is ResNetLayer:
c2 = args[1] if args[3] else args[1] * 4 # bottleneck 结构输出通道翻 4 倍
# 情况 5: m is torch.nn.BatchNorm2d
elif m is torch.nn.BatchNorm2d:
args = [ch[f]] # BN 层只需要输入通道数
# 情况 6: m is Concat (拼接层)
elif m is Concat:
c2 = sum(ch[x] for x in f) # 输出通道 = 所有输入层通道之和
# 情况 7: m in {Detect, Segment, Pose, ...} (检测/分割头)
elif m in frozenset({Detect, WorldDetect, Segment, Pose, OBB, ImagePoolingAttn, v10Detect}):
args.append([ch[x] for x in f]) # 将所有输入层的通道数列表作为最后一个参数
if m is Segment:
args[2] = make_divisible(min(args[2], max_channels) * width, 8) # 缩放内部通道
if m in {Detect, Segment, Pose, OBB}:
m.legacy = legacy # 设置 legacy 属性
# 情况 8: m is RTDETRDecoder
elif m is RTDETRDecoder: # special case, channels arg must be passed in index 1
args.insert(1, [ch[x] for x in f]) # 通道列表作为第 2 个参数
elif m is CBLinear:
c2 = args[0]
c1 = ch[f]
args = [c1, c2, *args[1:]]
elif m is CBFuse:
c2 = ch[f[-1]]
elif m in frozenset({TorchVision, Index}):
c2 = args[0]
c1 = ch[f]
args = [*args[1:]]
# 默认情况,c2 = ch[f](输出通道等于输入通道,如 nn.Identity)
else:
c2 = ch[f]
# 目的: 实例化模块。n > 1: 创建一个包含 n 个 m(*args) 实例的 Sequential。 n == 1: 直接创建单个模块 m(*args)。 m_: 最终的模块实例。
# 为模块实例 m_ 添加自定义属性,便于后续调试和分析。
m_ = torch.nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace("__main__.", "") # module type # 模块类型字符串
m_.np = sum(x.numel() for x in m_.parameters()) # number params # 参数数量
m_.i, m_.f, m_.type = i, f, t # attach index, 'from' index, type # 附加索引、输入来源、类型
# 打印每一层的详细信息,形成一个清晰的模型结构表。
if verbose:
LOGGER.info(f"{i:>3}{str(f):>20}{n_:>3}{m_.np:10.0f} {t:<45}{str(args):<30}") # print
# 将输入来源层 f 的索引加入 save 列表(排除 -1),表示这些层的输出需要被保存。
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_) # 将创建好的模块 m_ 加入 layers 列表
if i == 0:
ch = []
ch.append(c2) # 将当前层的输出通道数 c2 加入 ch 列表,供下一层使用。
return torch.nn.Sequential(*layers), sorted(save) # 最终返回
#torch.nn.Sequential(*layers): 将所有模块按顺序组合成一个完整的模型。
#sorted(save): 返回需要保存输出的层索引列表,用于后续的特征融合(如 PAN-FPN)
这个 for 循环是 parse_model 的心脏,它实现了:
- 通用性: 通过 if-elif 链处理数十种不同类型的模块。
- 可配置性: 支持 depth_multiple 和 width_multiple 进行模型缩放。
- 自动化: 自动推断输入通道数,无需在配置中显式写出。
- 灵活性: 支持复杂的连接方式(如多输入 Concat、跨层连接)。
- 可读性: 在 verbose 模式下打印详细的模型结构表。
正是这个循环,使得 YOLO 能够通过简单的 YAML 配置文件,灵活地构建出从轻量级 yolov8n 到大型 yolov8x 的各种模型。


















 1812
1812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









