









unicode
在开始这个问题之前首先提出几个问题,希望读者能带着这几个问题去看这篇文章
问题1
一个汉字究竟占几个字节?
问题2
我在网页上能看到一些外文像韩文日文或者特殊符号,自己却打不出来?
问题3
如何理解C/C++中的char、wchar_t 、char16_t和char32_t这几种类型?
起源
计算机只能处理数字,不能处理文本,那么对计算机操作文本就需要进行一定的编码。
计算机通过设计8位(1个字节)的二进制编码进行操作文本,因为计算机不是中国发明的,一开始计算机语言是26英文字母、数字和一些符号,2^8-1=255个编码已经完全能够适应,这就是早起的ASCII编码。
然而随着世界的发展,并且各个国家都有自己的语言,上述的编码已经不够用了,各个国家自己制定自己的文字的编码规则。中国大陆制定了GB2312,日本就是JIT标准,中国香港,中国台湾对应的是BIG5标准。
这里的GB2312,采用两个字节,因此编码范围就从0xA1A1 -0xFEFE,这个范围可以表示23901个汉字,但实际上里面包含6763个汉字和682个符号。这种方法好处就是和ASCII不会发生冲突,并且能够实现英文和汉字同时显示。
BIG5,香港和台湾用的比较多,繁体,范围: 0xA140 - 0xF9FE, 0xA1A1 - 0xF9FE,每个字由两个字节组成,其第一字节编码范围为0xA1~0xF9,第二字节编码范围为0x40-0x7E与0xA1-0xFE,总计收入13868个字(包括5401个常用字、7652 个次常用字、7个扩充字、以及808个各式符号)。
其他国家也会出现类似的问题,那么每个国家的语言就都成“方言”了,只能处理自己国家的文本。很显然,这样做不利于国际的沟通和交流。那么,这个时候unicode就出来大显身手了。unicode通过数字来处理字符,保证前256个字符的同时,而且使得各个国家各个字符都互相兼容。
在表示一个Unicode的字符时,通常会用“U+”然后紧接着一组十六进制的数字来表示这一个字符,那么总的可表示的字符即为2^16-1=65535。那么65535个字符就完全能把世界上语言都装进去吗,回答是不能。因为还有其他的十六个平面,我们常用的就是基本文本平面BMP,也叫零号平面。
文本平面的概念就是Unicode中的一个编码区段。编码从U+0000至U+FFFF,总共有这样的17个平面。
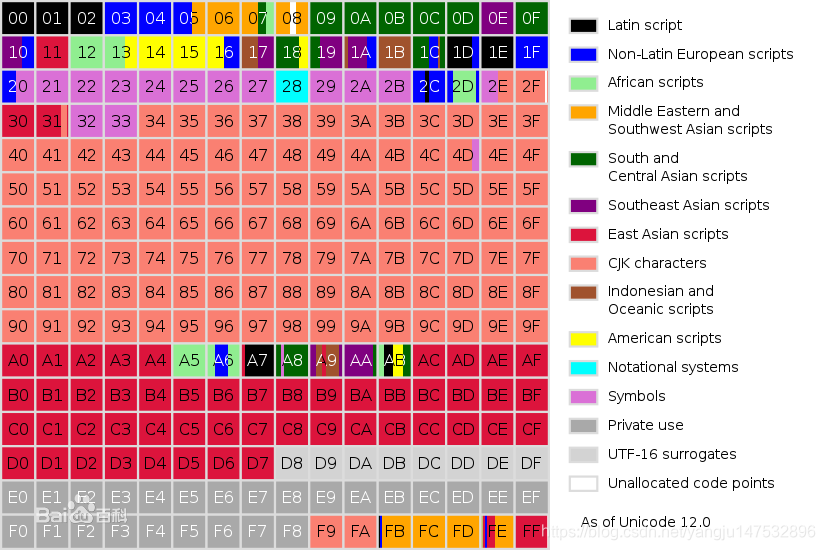
上图表示为第零平面,看起来跟元素周期表类似。有不同的颜色分类,还有未开发未使用的格子。其中每个写着数字的格子代表256个码点,不同的颜色对应不同的文本含义,详见下述阐释,具体可以参照百度百科。
黑 = 拉丁文字及符号
浅蓝 = Linguistic scripts
蓝 = 其他欧洲文字
橘 = Middle Eastern and SW Asian scripts
浅橘 = 非洲文字
绿 = 南亚文字
紫 = 东南亚文字
红 = 东亚文字
浅红 = 中日韩汉字
黄 = Aboriginal scripts
紫红 = 符号
深灰 = Diacritics
浅灰 = UTF-16surrogates and private use
蓝青 = Miscellaneous characters
白 = 未使用
直观表示unicode
说了这么多,完全还不是很明白这个到底怎么用?
感觉用不到,平时的话跟我们有什么关系?
还有这个对我学习或者编程有什么帮助?
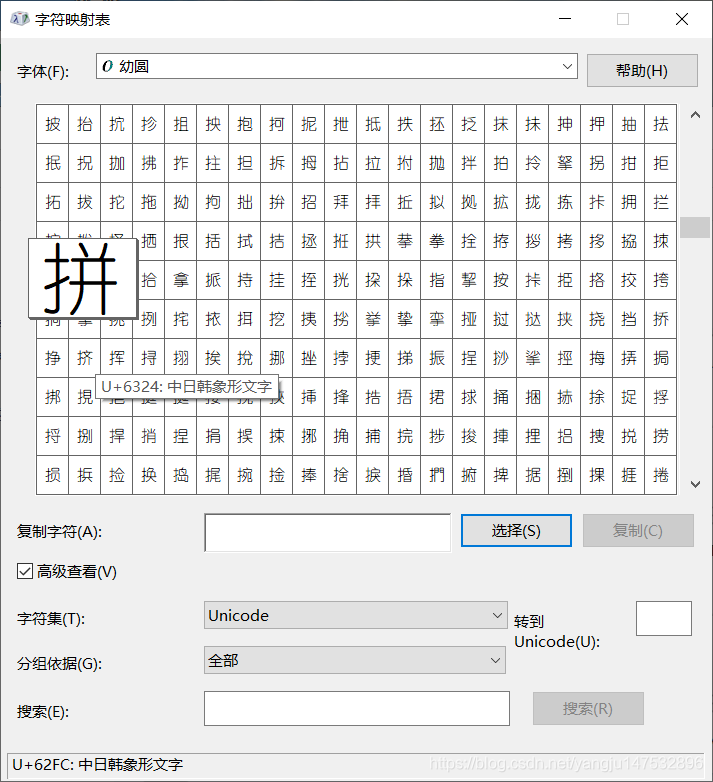
其实unicode的作用还是很大的,可能平时察觉不到,但我们其实已经用上了。在Windows操作系统当中,以电脑win10为例子。我们在C:\Windows\Fonts中,左侧的边框栏中选出查找字符,可以跳出如下图所示的字符映射表。仔细观察左下角可以发现惊喜,所有的字符都有对应的unicode码值。
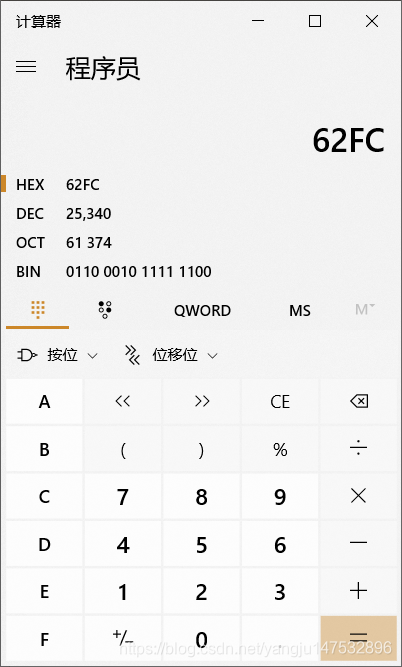
例如打开字体幼圆,选择“拼”这个中文字,左下角显示U+62FC。通过程序员模块在计算机中得出转化为十进制的25340。我们在电脑中打开Ms中的word,按住Alt键,然后在敲入25340,可以发现这个时候word出现了“拼”这个字。同理,在“拼”这个字的后面按住Alt键然后再按X键,可以发现“拼”这个字转化为四位的十六进制0x62FC,这号对应字符映射表的值。当然也可以尝试在记事本中同样操作。
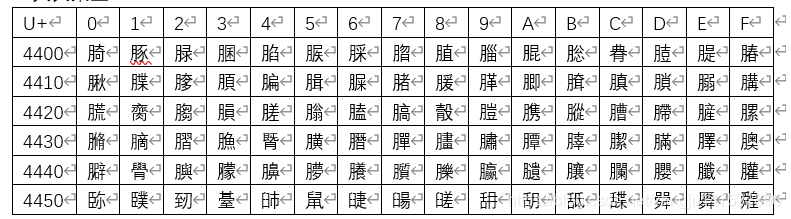
接下来就是部分的编码表,如下表所示。
因为已经通过上述的操作例子熟悉了unicode编码,那么下面的表中的值也会很好的理解,第一个汉字为“䐀”,unicode码值为U+4400,转化成十进制为17408,在Ms的Word中按住Alt+17408即可得到这个“䐀”的汉字。
除此之外,还可以在电脑中设置非unicode程序的语言,在语言和区域中,选择管理,可以发现如果不支持unicode程序,那么就是用中文设置,如下图所示。
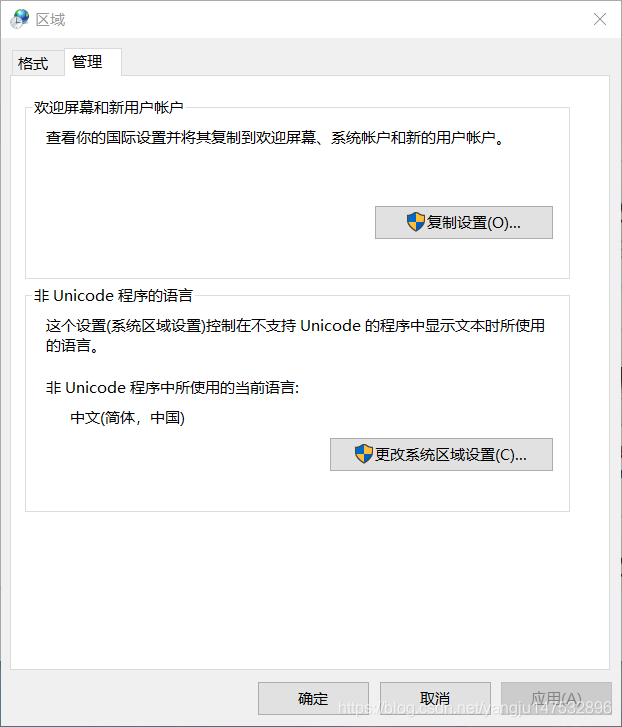
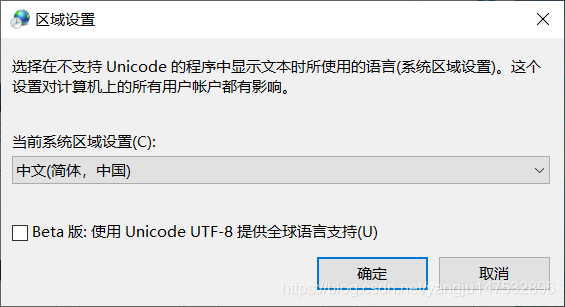
可以看到在这里出现了Unicode UTF-8,那这又是什么呢?
那么计算机当中一直出现的UTF-8,UTF-16,UTF-32又是什么编码呢?
编码方案
UTF-8,UTF-16,UTF-32是数字转换到程序数据的编码方案。
这里还得讲一个叫UCS的。如果说unicode是要统一所有国家的文本的编码,这个时候发现另外有一个叫iso的组织也在搞这个,他们的编码叫做UCS。
unicode和UCS的异同:
unicode有多种编码方式:UTF-8,UTF-16,UTF-32
UCS有两种形式:UCS-2和UCS-4
兼容方式:不完全兼容,UTF-16是UCS-2的扩展,UTF-32是UCS-4的子集
这里发现出现了好多新的概念,UCS-2和UCS-4
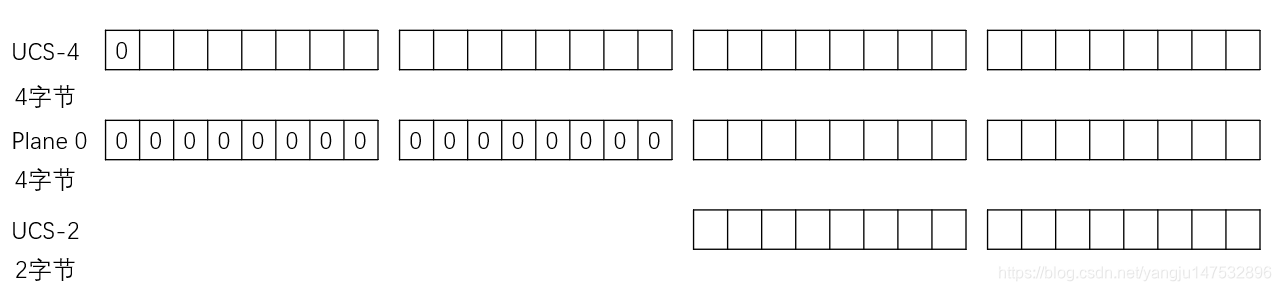
可以知道,UCS-2是16位,即216=65536个码值,UCS-4是31位,最高面位0,即231=2147483648个码值。UCS-4根据最高位为0的最高字节分成27=128个group。每个group再根据次高字节分为256个plane。每个plane根据第3个字节分为256行,每行包含256个cells。当然同一行的cells只是最后一个字节不同,其余都相同。group 0的plane 0被称作Basic Multilingual Plane, 即BMP。或者说UCS-4中,高两个字节为0的码位被称作BMP。将UCS-4的BMP去掉前面的两个零字节就得到了UCS-2。
UTF-8
UTF-8是变长度的编码,主要为了解决符号在网络中传输的浪费问题,就出现了UTF-8编码。
| Unicode十六进制 | UTF-8二进制 |
|---|---|
| 000000-00007F | 0xxxxxxx |
| 000080-0007FF | 110xxxxx 10xxxxxx |
| 000800-00FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 010000-10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
从上边可以发现一些特征,这个UTF-8也是需要unicode码值的,但是在位数较小的时候,可以得到很简洁的方式,在计算机程序或者网络传输可以大大增加效率。
举四个例子来说明这个到底怎么转化。
example1
在0x00-0x7F范围内的字符,UTF-8编码需要7位。
英文字母“A”在unicode编码是第65个编码,十六进制表示为0x41,转化成二进制,在首位添加0,即为0100 0001,这个就是UTF-8二进制表示方法。其实对于0x00-0x7F之间的字符,UTF-8编码与ASCII编码完全相同,用十六进制表示也为0x41。
example2
在000080-0007FF范围内的字符,UTF-8编码需要11位。
希腊字母“α”在unicode编码是第945个编码,十六进制表示为0x03B1,转化成二进制,
0011 1011 0001,取其中的后11位,分别按顺序填充至UTF-8二进制的编码中,即为
11001110 10110001,再转化成十六进制表示为0xCE 0xB1,这个即为UTF-8的存储的程序数据
example3
在000800-00FFFF范围内的字符,UTF-8编码需要16位。
中文汉字“博”在unicode编码是第21338个编码,十六进制表示为0x535A,转化成二进制,
0101 0011 0101 1010,可以发现这个二进制正好是16位,依次按顺序填充至UTF-8二进制的编码中,即为11100101 10001101 10011010,再转化成十六进制表示为0xE5 0x8D 0x9A,正好为三个字节,可以发现汉字在unicode编码是二个字节,但是在UTF-8这个范围内汉字的字节是三个。
example4
在010000-10FFFF范围内的字符,UTF-8编码需要21位。
在这个范围内的编码,已经不属于基本文本平面BMP了,在Msword中可能是显示不出文本的。
举一个简单的十六进制编码为“0x1011C”,转化成二进制的形式,0001 0000 0001 0001 1100,依次按照顺序填充至UTF-8二进制的编码中(这里边不足21位在首位添加0),即为
11110000 10010000 10000100 10011100,再转化成十六进制表示为0xF0 0x90 0x84 0x9C,这个范围内的UTF-8字节数为四个。
那说了这么多UTF-8是其中一种编码方案,前文起源中也GB2312也是编码方案。 那么两者的区别是什么?
通过下面的表格来具体说明UTF-8和GB2312的区别,并且我们一般汉字的网页都是GB2312的编码方案,类似腾讯、网易等,UTF-8一般是少数民族频道,类似藏语,维语等等。
| 项目\编码方案 | UTF-8 | GB2312 |
|---|---|---|
| 通用形式 | 支持目前各个国家的语言 | 只支持中文和常见英文 |
| 相互转换 | 可以对照编码规律转化unicode | 无规律,只能查表转化unicode |
| 汉字的字节 | 3个字节或者4个字节 | 2个字节 |
| 存储大小 | 体积较大 | 相对轻小 |
UTF-16
相对于UTF-8来说多数情况是以两个字节存储,但UTF-16无法兼容于ASCII编码。
UTF-16可看成是UCS-2的父集。在没有辅助平面字符(即其他16个辅助平面)前,UTF-16与UCS-2所指的是同一的意思。
| Unicode十六进制 | UTF-16 |
|---|---|
| 0000-0FFFF | 对应unicode编码 |
| 010000-0EFFFF | 非专用区 |
| 0F0000-10FFFF | 专用区 |
看到这边就有疑问了,什么是专用区和非专用区,两者之间的编码方式有什么区别。
Unicode标准将平面15和平面16都作为专用区
除了基本文本平面以外,UTF-16的编码,需要经过U’=U-0x10000处理,然后在讲他们依次填入高低位,形如110110xxxxxxxxxx 110111xxxxxxxxxx,空缺部分为20位,(即便是U+10FFFF经过
U-0x10000处理得到的也是20位的二进制数。)
高位合并取值范围是110110 0000000000-110110 1111111111,十六进制范围为0xD800-0xDBFF
低位合并取值范围是110111 0000000000-110111 1111111111,十六进制范围为0xDC00-0xDFFF
| 处理过的高低位十六进制 | 替代形式 |
|---|---|
| D800-DB7F | 高位替代 |
| DB80-DBFF | 高位专用替代 |
| DC00-DFFF | 低位替代 |
把高位DB80-DBFF范围和低位DC00-DFFF取出来合并,可以得到总的范围DB80 DC00-DBFF DFFF
写成二进制的形式是1101101110000000 1101110000000000-1101101111111111 1101111111111111,
将高低位去除得到范围1110 0000 0000 0000 0000-1111 1111 1111 1111 1111,十六进制表示
0xE0000-0xFFFFF再经过反向处理U=U’+0x10000得到unicode编码0xF0000-0x10FFFF。这个正好对应上述的专用区,他们是平面15和平面16。
example1
在基本文本平面BMP中(U<0x10000),UTF-16的编码就是U对应的16位整数,即跟unicode编码没有区别,在这个范围UTF-16是两个字节。
“编码”二字分别对应十六进制0x7F16,0x7801,UTF-16的编码也为0x7F16和0x7801。
example2
超过基本文本平面BMP(U>0x10000),UTF-16编码会有明显的区别,这里的UTF-16为四个字节。
今天日期为2020/3/20,那么取unicode编码0x20320,经过U’=U-0x10000处理得到0x10320,转化成二进制的形式为0001 0000 0011 0010 0000,然后在高低位依次加进去最终得到
1101100001000000 1101111100100000,在转化成十六进制可以得到0xD840 0xDF20。
通过例子可以知道,目前支撑我们继续使用 UTF-16 的理由主要是考虑到它是双字节的,在计算字符串长度、执行索引操作时速度很快。
UTF-32
相对于UTF-16来说多数情况是以四个字节存储,UTF-32编码就是其对应的32位的unicode编码。
UTF-32 是一个 UCS-4 的子集,使用32-位元的码值,只在0到10FFFF的字码空间。
这里首先要讲的就是字节序,用来表示大端(BE)和小端(LE)。
字节序:指多字节数据在计算机内存中存储或者网络传输时各字节的存储顺序。
字节序对于单字节的无影响,在多字节中会使用得到,下表通过两个例子来说明。
| Unicode编码 | UTF-16BE | UTF-16LE | UTF32-BE | UTF32-LE |
|---|---|---|---|---|
| 0x007F16 | 7F16 | 16 7F | 00 00 7F16 | 16 7F 00 00 |
| 0x020320 | D8 40 DF20 | 20 DF 40 D8 | 00 02 03 20 | 20 03 02 00 |
大端(BE)跟我们通常熟悉比较常见的储存顺序,而小端(LE)的存在也能满足一些方面的需要。
问题回答
1.一个汉字究竟占几个字节?
准确的来说汉字2-4个字节。不同的编码方式下得到的是不同的字节。
采用GB2312方式的编码,字节数为2;
UTF-8编码是变长编码,通常汉字占3个字节,扩展B区以后的汉字占四个字节。
2.我在网页上能看到一些外文像韩文日文或者特殊符号,自己却打不出来?
1)在Ms的Word中,可以尝试用Unicode编码对照系统中韩文的字符映射表来打韩文字,不需要安装额外的语言包。
2)在浏览器中,需要在系统安装语言包,使得键盘可以对照着打印出韩文的字符
3.如何理解C/C++中的char、wchar_t 、char16_t和char32_t这几种类型?
其中char16_t char32_t是C++当中新增的类型。
wchat_t是C/C++的字符类型,unicode编码的字符一般以wchar_t类型存储,在windows下就是unicode码值的UTF-16编码值。
例如“慕课网”这三个汉字
对应的unicode码值为0x6155,0x8BFE,0x7F51
转化为对应的二进制0110 0001 0101 0101,1000 1011 1111 1110,0111 1111 0101 0001
正好对应000800-00FFFF范围的1110xxxx 10xxxxxx 10xxxxxx码值区
分别为11100110 10000101 10010101 ,11101000 10101111 10111110,11100111 10111101 10010001
转化成16进制即为0xE6 8595,0xE8 AFBE,0xE7 BD91
char data_utf8[]={0xE6,0x85,0x95,0xE8,0xAF,0xBE,0xE7,0xBD,0x91};//UTF-8编码
char16_t data_utf16[]={0x6155,0x8BFE,0x7F51}; //UTF-16编码
char32_t data_utf32[]={0x00006155,0x00008BFE,0x00007F51};//UTF-32编码
参考
[1] xiangjuan314,unicode和usc区别
[2] 百度百科“通用字符”
[3] 百度百科“unicode”
[4] softman11,彻底搞懂字符编码(unicode,mbcs,utf-8,utf-16,utf-32,big endian,little endian…)
[5] Mr_Lsz,C++:wchar_t 和C++新增类型:char16_t char32_t
[6] 大家网大学三年级
[7] nodeathphoenix,宽字符wchar_t和窄字符char区别和相互转换
[8] xrzx,unicode详解又一篇


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









