









 本文介绍了Python中的re模块使用方法及正则表达式基础语法,包括match、search、findall等函数的区别,以及如何匹配单个字符、多个字符、边界等。
本文介绍了Python中的re模块使用方法及正则表达式基础语法,包括match、search、findall等函数的区别,以及如何匹配单个字符、多个字符、边界等。
【Python】正则表达式总结
一,re模块
1,过程
re模块的一般过程如下
expression - > pattern object -> match object -> result
对应的代码如下:
import re
pa = re.compile('some_express')
ma = pa.match(str1)
ma.group()
2,常用方法
常用方法有:
match()
search()
findall()
sub()
split()
前三种方法容易弄混,他们之间存在着差异,
import re
mo_by_match = re.match(r'\d{3}','ab123x12122sa')
mo_by_search = re.search(r'\d{3}', 'ab123x12122sa')
mo_by_findall = re.findall(r'\d{3}', 'ab123x12122sa')
mo_by_findall2 = re.findall(r'(\d{3})(.)', 'ab123x12122sa')
print(mo_by_match)
print(mo_by_search)
print(mo_by_findall)
print(mo_by_findall2)
结果:
None #未匹配
<_sre.SRE_Match object; span=(2, 5), match=‘123’> # 返回第一个匹配字符串
[‘123’, ‘121’] #字符串列表
[(‘123’, ‘x’), (‘121’, ‘2’)] #元组列表
(1)match和search都是测试正则表达式与字符串是否匹配,不同的是,match要求字符串的第一个字符就能匹配上正则表达示,也就是说match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回none。而search则不同,如果字符串开头不能匹配,即会继续往后匹配,直接匹配成功或者到字符串结束。
(2)search和findall都是扫描整个字符串,search返回一个match对象,包含匹配到的“第一个”字符串,而findall返回一个所有匹配字符串组成的列表,并不是返回match对象。
(3)findall还有另一个特殊用法,如果调用一个有“()”进行分组的正则表达式时,会返回一个元祖列表,每一个元组都是匹配的结果。
(4)sub()传入三个参数pattern, repl, string,pattern为表达式,string为被替换的字符串,repl是用于替换,“repl can be either a string or a callable; If it is a callable, it’s passed the match object and must return a replacement string to be used.”
举个例子
str1 = 'I am 23 years old'
def add_age(match):
age = int(match.group())
age = age + 1
return str(age)
new_age = re.sub(r'\d+',add_age,str1)
print(new_age)
sub中已经将match对象传入add_age中,match对象是re.match(r’\d+’,str1)的返回,计算出结果返回,再进行替换str1中数字,至于match对象是如何让传递的,我也没弄明白,只能根据代码注释猜测下,
(5)re模块split()是str.split()的升级版,
举个简单粗暴的例子:
str2 = 'Split:the source string,by the occurrences#of the pattern'
result = re.split(r':| |,|#',str2)
print(result)
[‘Split’, ‘the’, ‘source’, ‘string’, ‘by’, ‘the’, ‘occurrences’, ‘of’, ‘the’, ‘pattern’]
如果用str.split()就没法对str2进行切分,但是使用re.split()可以应对,虽然粗暴些。
二,正则表达式语法
1,匹配单个字符
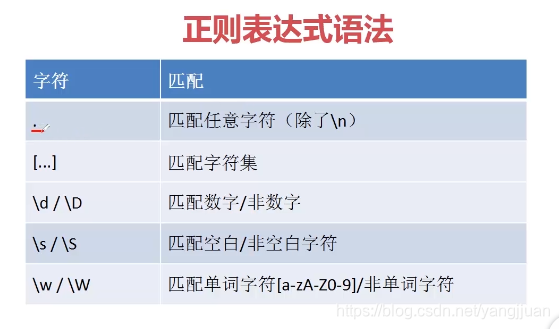
(1)“."称为“通配符”,匹配除了换行符“\n”,一个“.”只匹配一个字符,
(2)“[…]”可以用于建立自己的字符分类,比如[A-Z0-9]匹配大写字母和数字,此外,在[]中的正则表达式符号都会被自动转义,不需要使用反斜杠转义,比如匹配一个问号,可以是[?]。
(3)可以在“[…]”的开头加入“^”,表示非该字符集,[^A-Z0-9]表示非大写字母和数字。
2,匹配多个字符
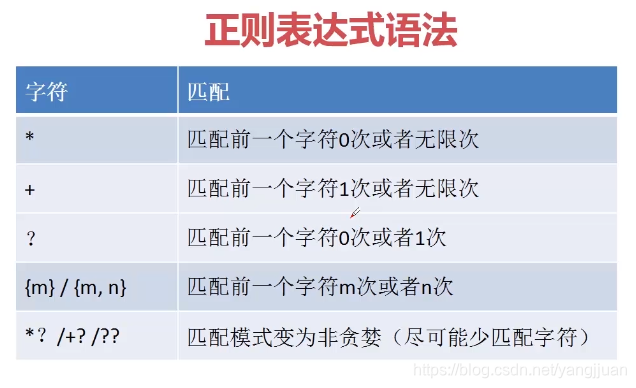
(1).*的组合匹配除换行符外的所有字符,但是可以通过传入re,DOTALL就可以匹配换行符在内的所有字符。如果是eclipse的Pydev使用这个参数时会报错,但是其实是正确的,可以按照这个修改
window – preferences – pydev – editor – code analysis – Undefined – undefined variable from import将错误改成警告。
(2)如果限定了匹配次数m,则会根据m值进行匹配,也可以设定一个范围m至n次
(3)贪心与非贪心,Python默认使用“贪心”的匹配模式,会尽可能的匹配更长的字符串,举个例子,可以匹配3,4,5,但是匹配到次数为5的字段串。
ma = re.match(r'(.)+','Split:the source string,by the occurrences#of the patter')
print(ma.group())
结果:Split:the source string,by the occurrences#of the patter
通过在末尾添加“?”,可以采用“非贪心”模式,尽可能匹配最短的字符串,举个例子
ma = re.match(r'(.)+?','Split:the source string,by the occurrences#of the patter')
print(ma.group())
结果:S
"+"匹配1次或者无限次,这里只匹配一次。
3,边界匹配

(1)如果同时使用^和$,则整个字符串需要与之间的内容完全匹配。
\A,\Z目前还没用过,感觉应该和^,$类似吧
4,分组匹配
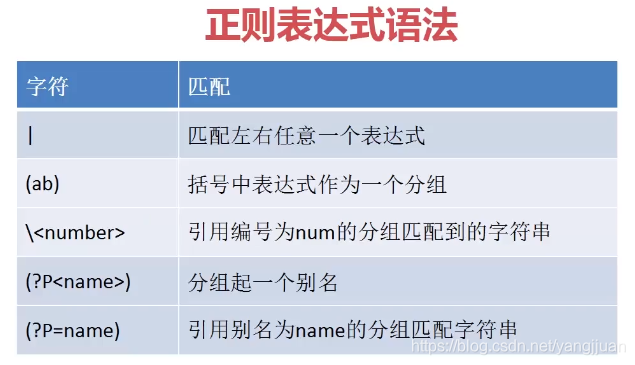
(1)|与() 一起使用,可以指定几种可选的模式,举个例子,匹配多种邮箱号:
[\w]{6,10}@(163|126|qq).com
(2)引用编号的分组,举个例子
ma = re.search(r'<([\w]+>)([\w]+)</\1', '<h1>Python</h1>')
print(ma.group()) #<h1>Python</h1>
\1代表第一个分组:[\w]+>,表达式等价于<([\w]+>)([\w]+)</[\w]+>,只是有点冗长。
(3)分组起别名,可以看成是赋值给一个变量,然后就可以使用这个变量,
ma = re.search(r'<(?P<h1>[\w]+>)([\w]+)</(?P=h1)', '<h1>Python</h1>')
print(ma.group()) #<h1>Python</h1>
分组:[\w]+>赋给h1,然后在后面使用h1这个变量,?P是大写P,不是小写
5,高阶正则表达式
除了前面的语法,正则还有些高级些的语法,比如(?:…),(?=…),(?<=…),(?!..),(?<!..),个人觉得这些不太好理解,需要实际遇到后,结合实际问题再去理解会好些,把前面的基本语法弄懂,并结合实际问题使用熟练就够了。有几篇详细的博文可以参考
http://www.cnblogs.com/symbol441/articles/957950.html
http://www.cnblogs.com/xiashengwang/p/3988573.html
参考:
《Python编程快速上手》

















 1051
1051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









