







今天简单的介绍一下BERT的模型输入
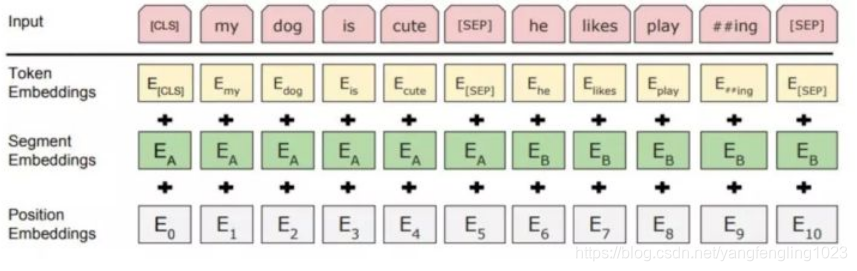
上图显示的是BERT输入表示
总述:输入嵌入分别是token embeddings, segmentation embeddings 和position embeddings 的总和
BERT最主要的组成部分便是,词向量(token embeddings)、段向量(segment embeddings)、位置向量(position embeddings)
词向量:是模型中关于词最主要的信息
段向量:是因为BERT里面的下一句的预测任务,所以会有两句拼接起来,上句与下句,上句有上句段向量,下句则有下句段向量,也就是图中A与B。此外,句子末尾都有加[SEP]结尾符,两句拼接开头有[CLS]符
位置向量:是因为 Transformer 模型不能记住时序,所以人为加入表示位置的向量
之后这三个向量拼接起来的输入会喂入BERT模型,输出各个位置的表示向量
最近在做基于BERT的阅读理解,所以对BERT进行了进一步的学习,将自己平时的学习的过程进行了简单的记录


















 1103
1103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











