



推荐资料:
CUDA编程入门
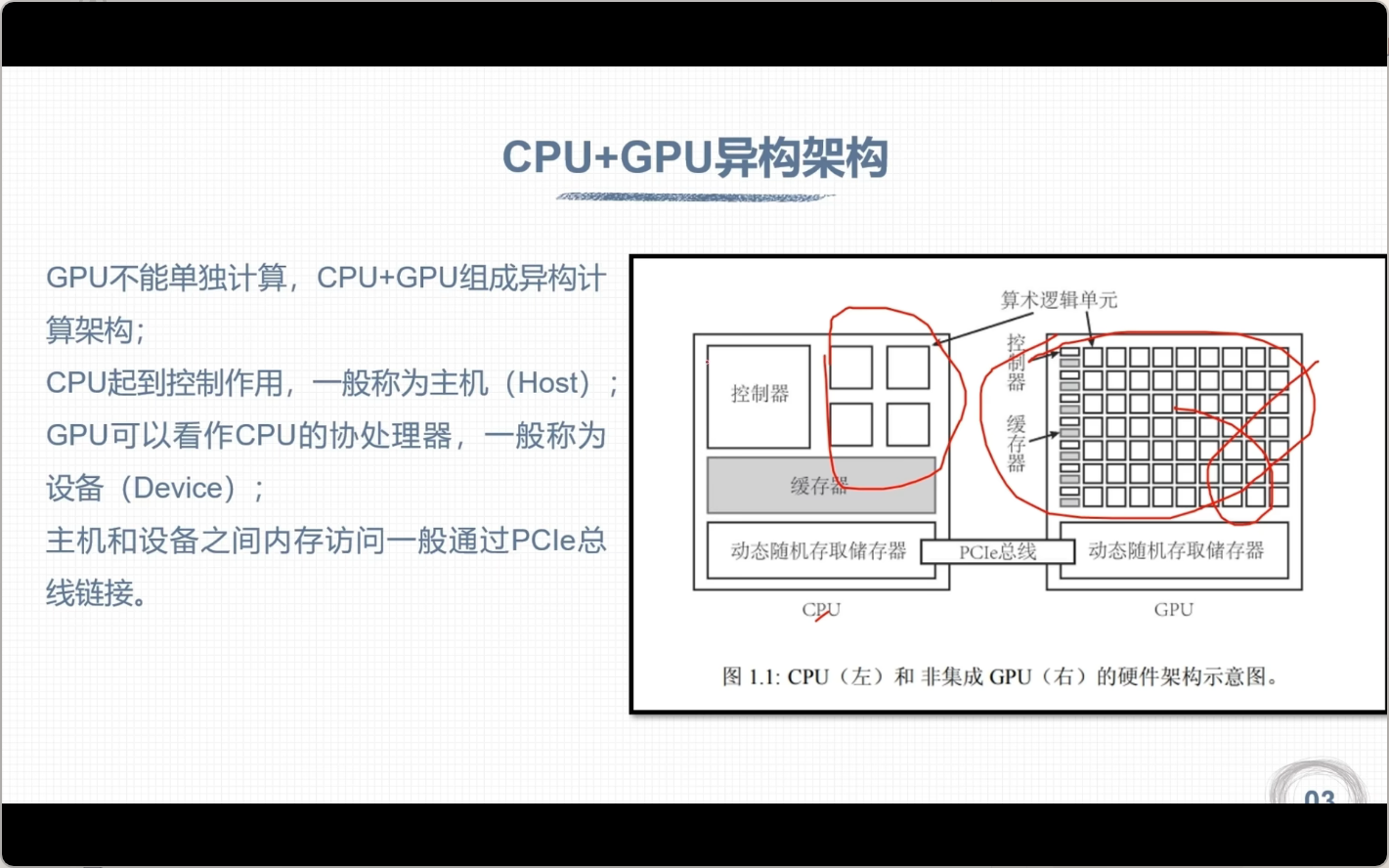
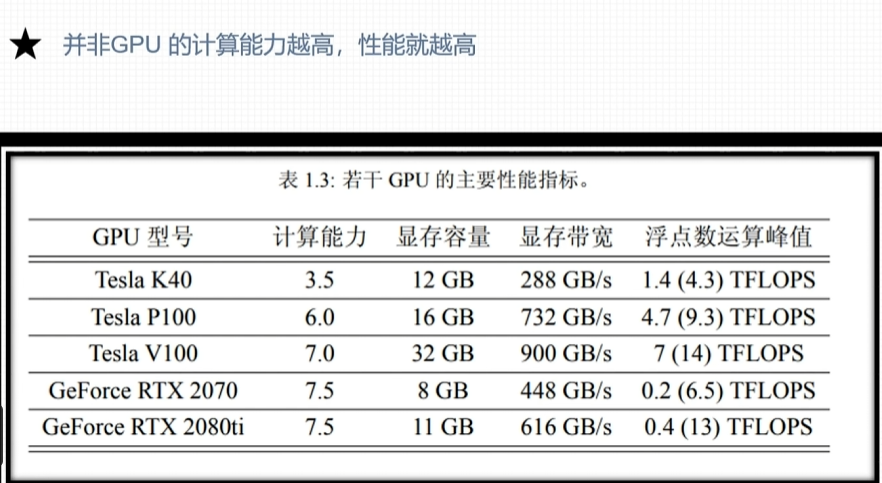
CPU与GPU区别
- CPU适合处理逻辑运算,GPU适合数据运算
- GPU性能指标,核心数,GPU显存容量,GPU计算峰值,显存带宽

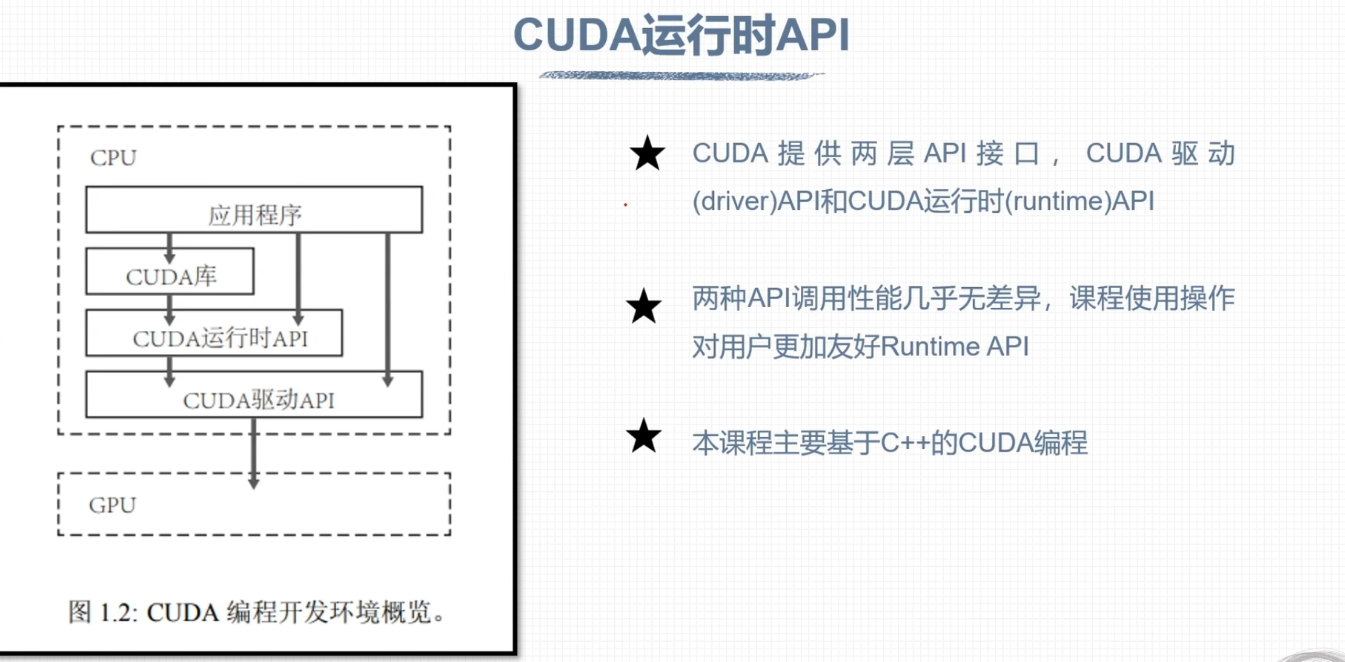
CUDA




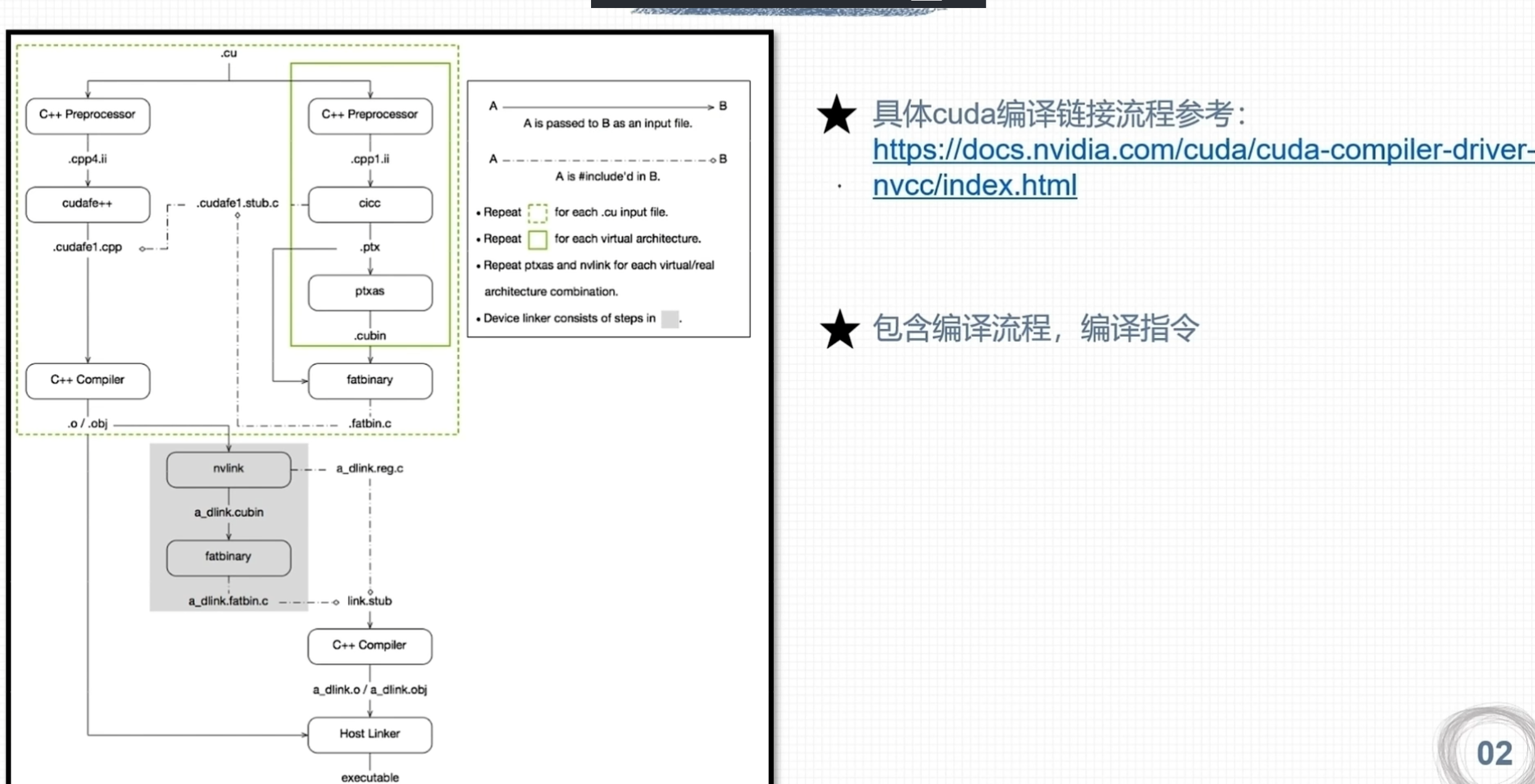
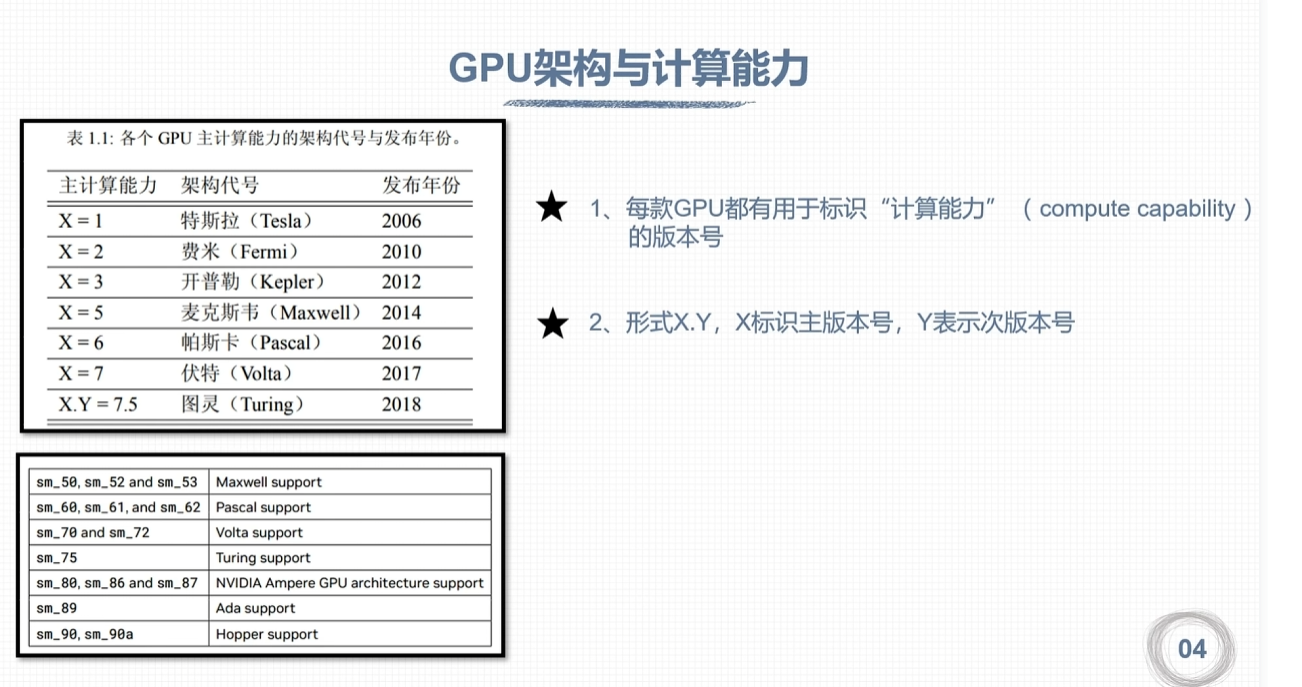
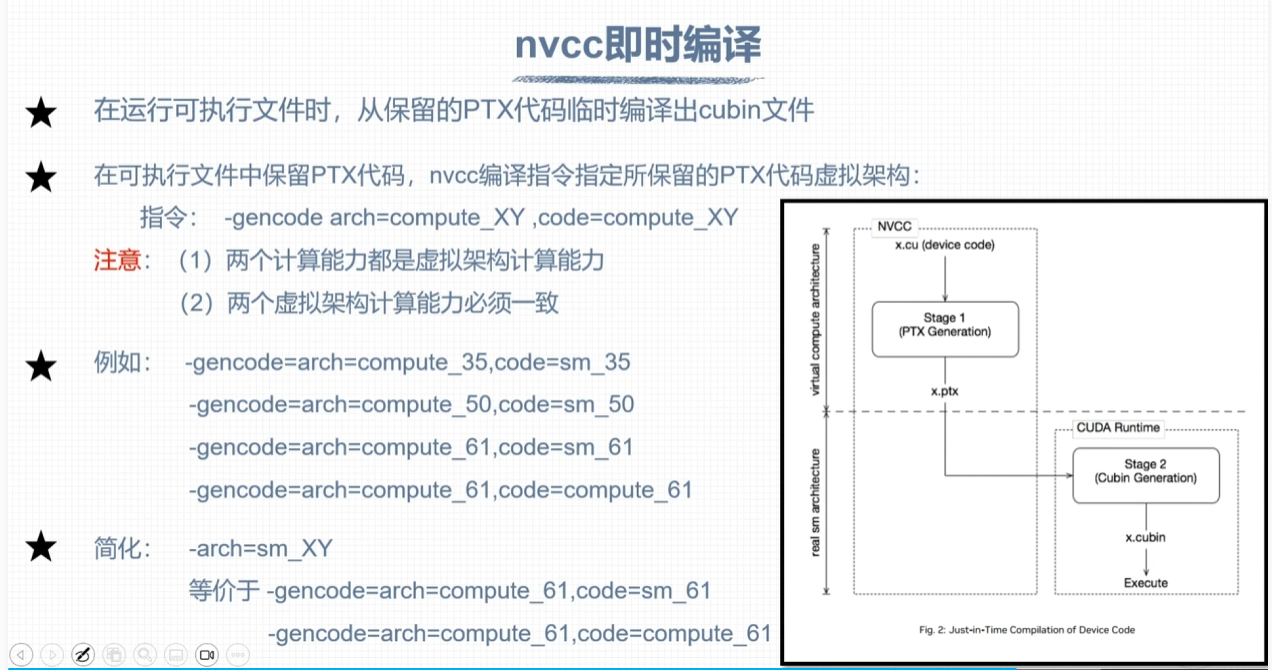
nvcc编译流程与GPU计算能力


PTX (Parallel Thread Execution) 代码
PTX (Parallel Thread Execution) 是一种由 NVIDIA 定义的虚拟汇编语言(Virtual Assembly Language)。它不是针对特定硬件芯片的机器码,而是 CUDA 编程模型中的一个中间层表示(Intermediate Representation, IR)。
你可以把 PTX 理解为 GPU 世界的 Java 字节码。它是一种标准的、跨代、跨架构的指令集,用于连接 CUDA 编译器和实际的 GPU 硬件。
- cuda代码的编译流程
[ .cu 源文件 ] ──> (nvcc 编译器前端) ──> [ PTX 代码 ] ──> (GPU 驱动程序/JIT 编译器) ──> [ 实际机器码 (SASS) ] ──> [ GPU 硬件 ]









nvidia-smi指令



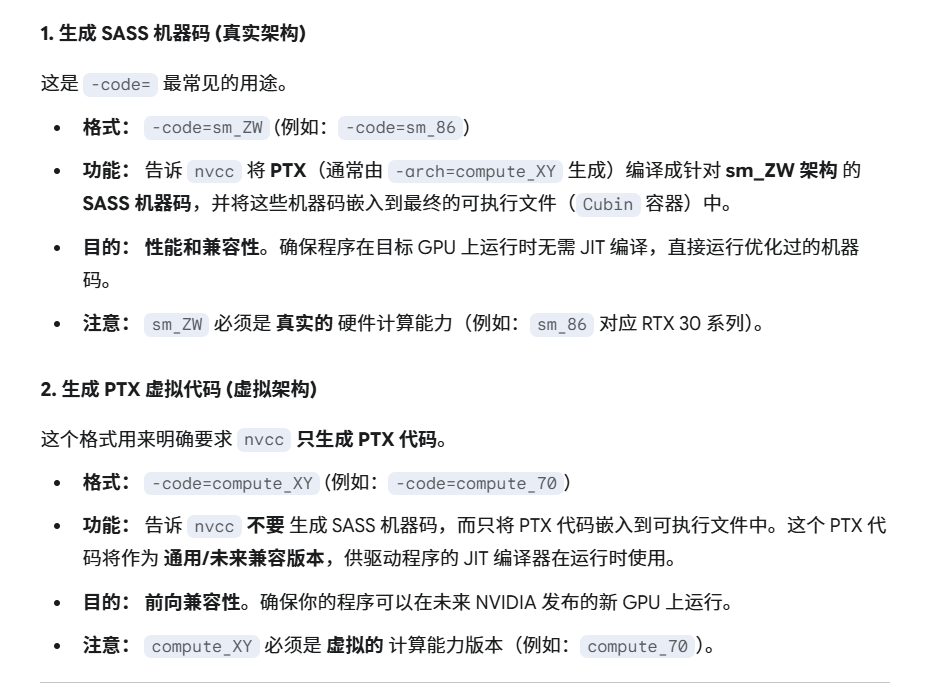
–arch
- 代表计算能力


–code

Hello
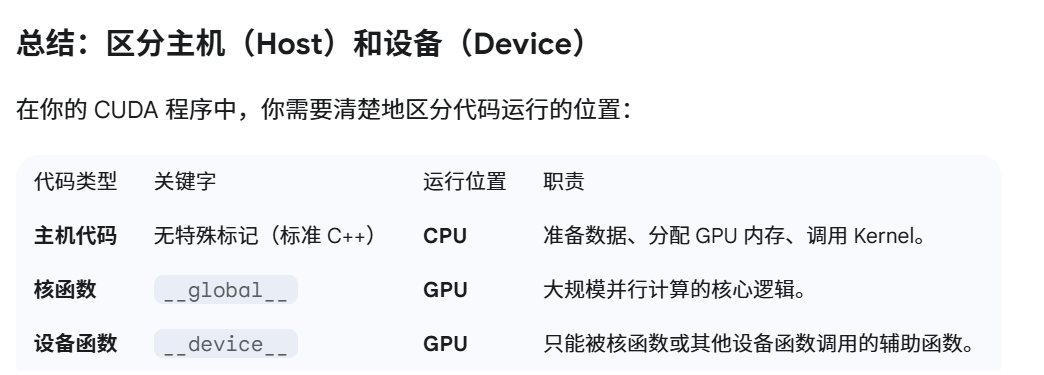
主机(Host)和设备(Device)
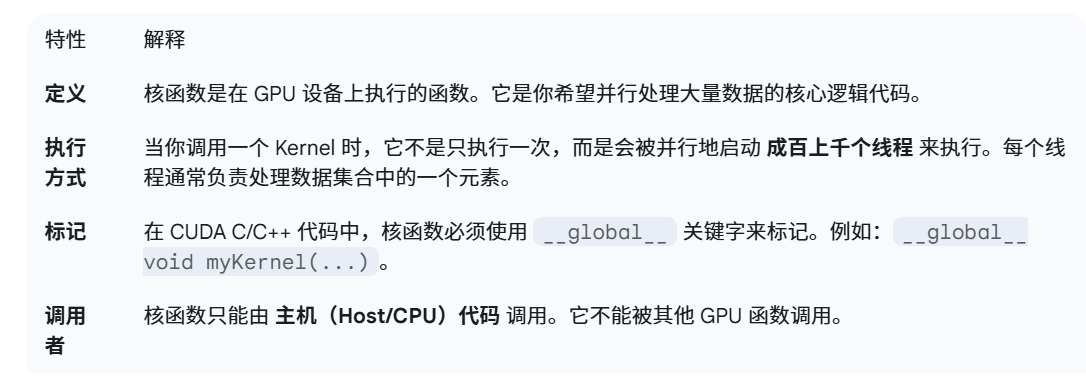
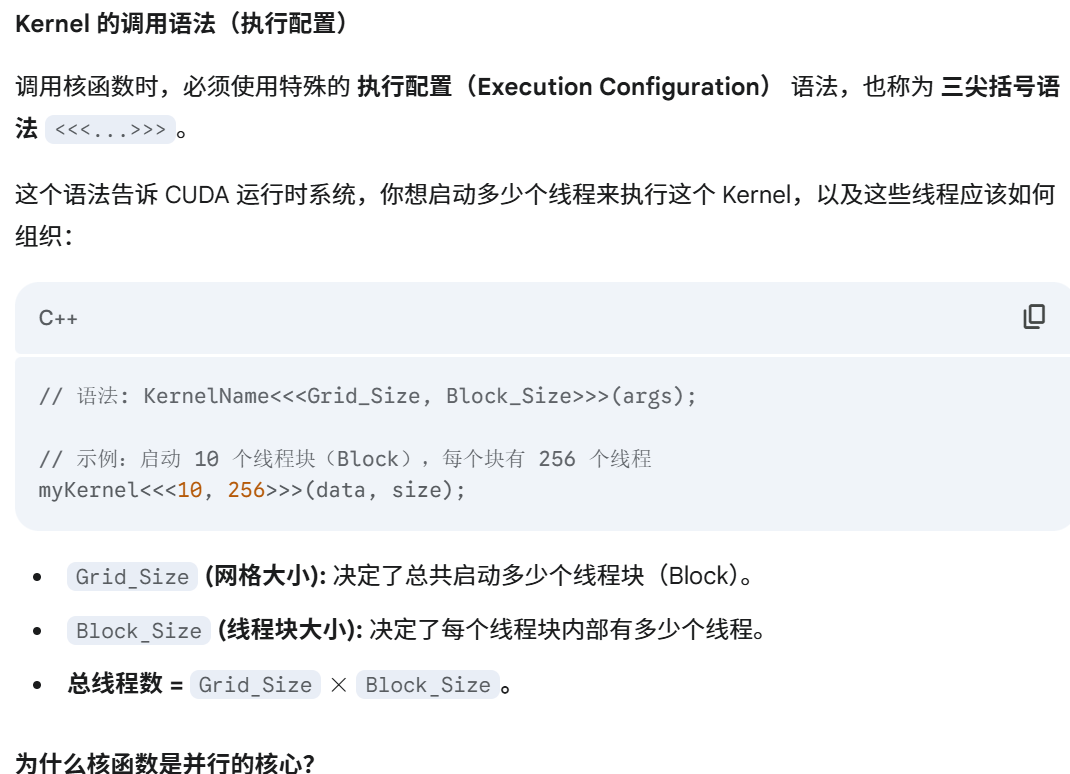
CUDA 核函数 (Kernel)


变长参数,静态变量,函数指针
核函数具有异步性,意思是需要主机代码去等待核函数执行完成,可以通过cudaDeviceSynchronize函数进行同步

CUDA程序兼容性问题



nvcc即时编译

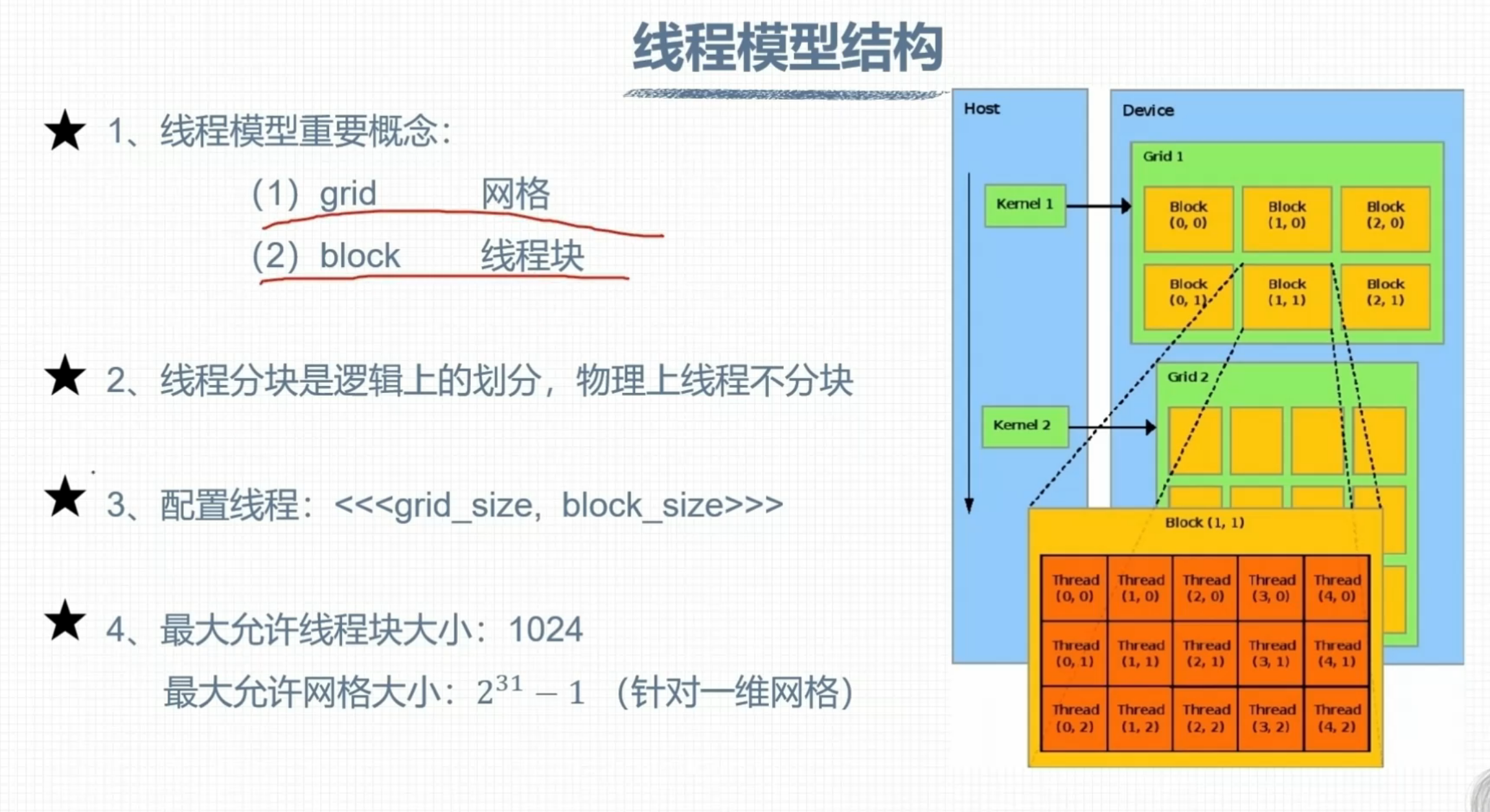
CUDA线程模型
线程模型结构

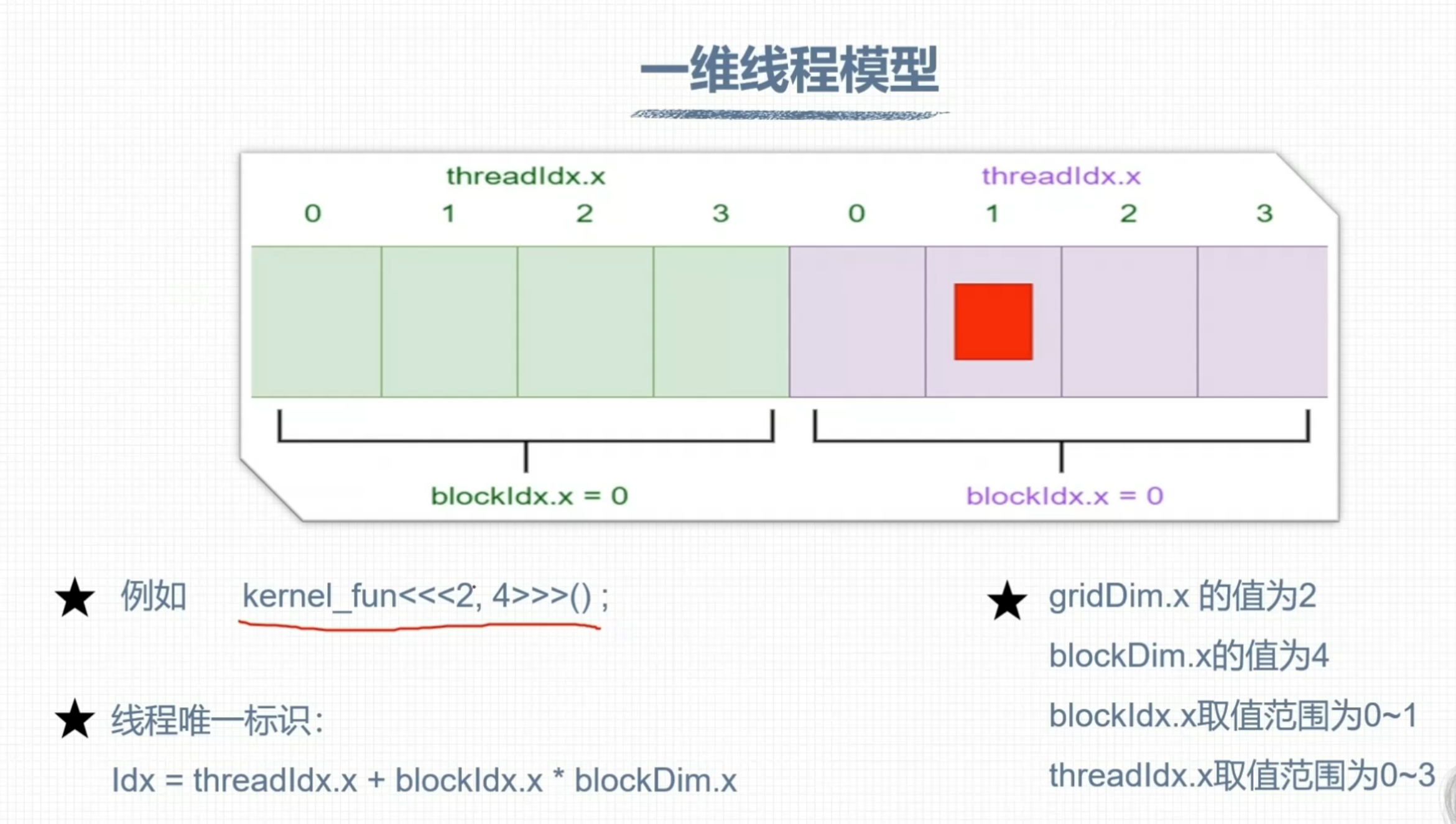
threadIdx
blockIdx

线程组织管理





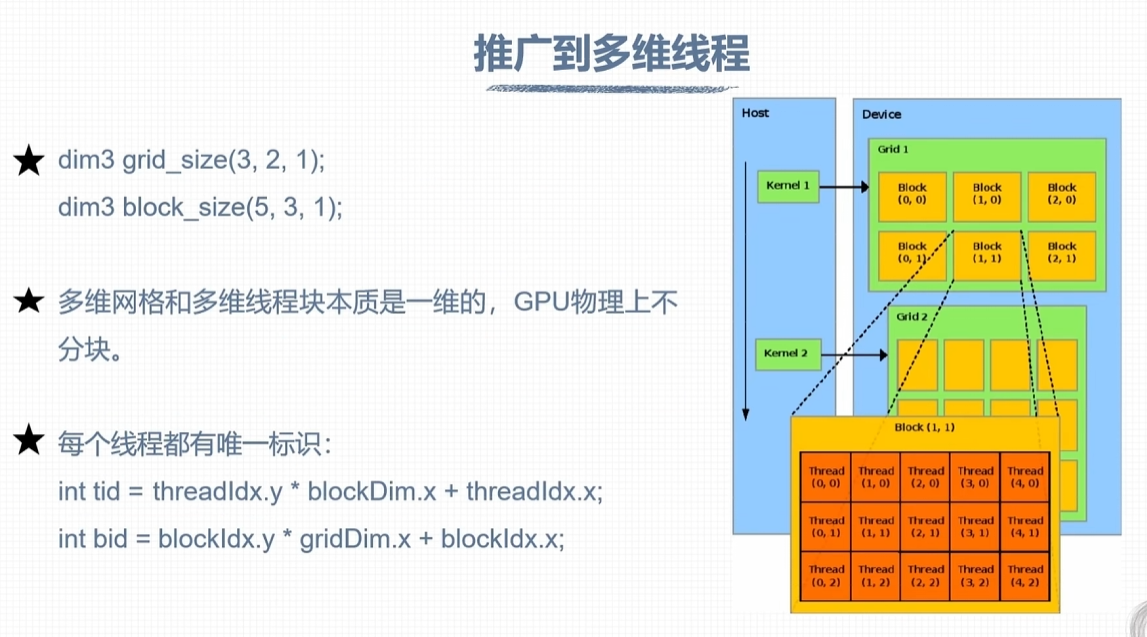
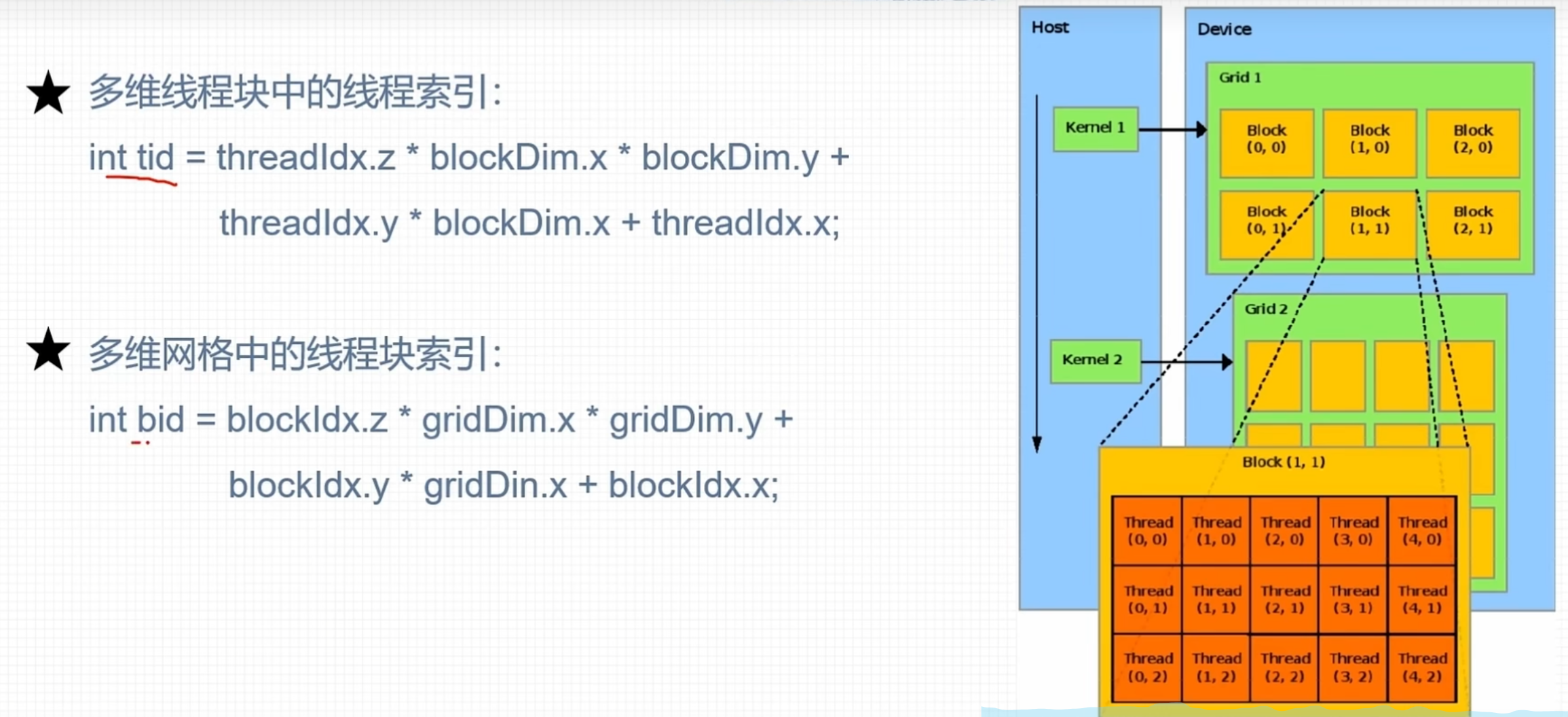
网格和线程块限制

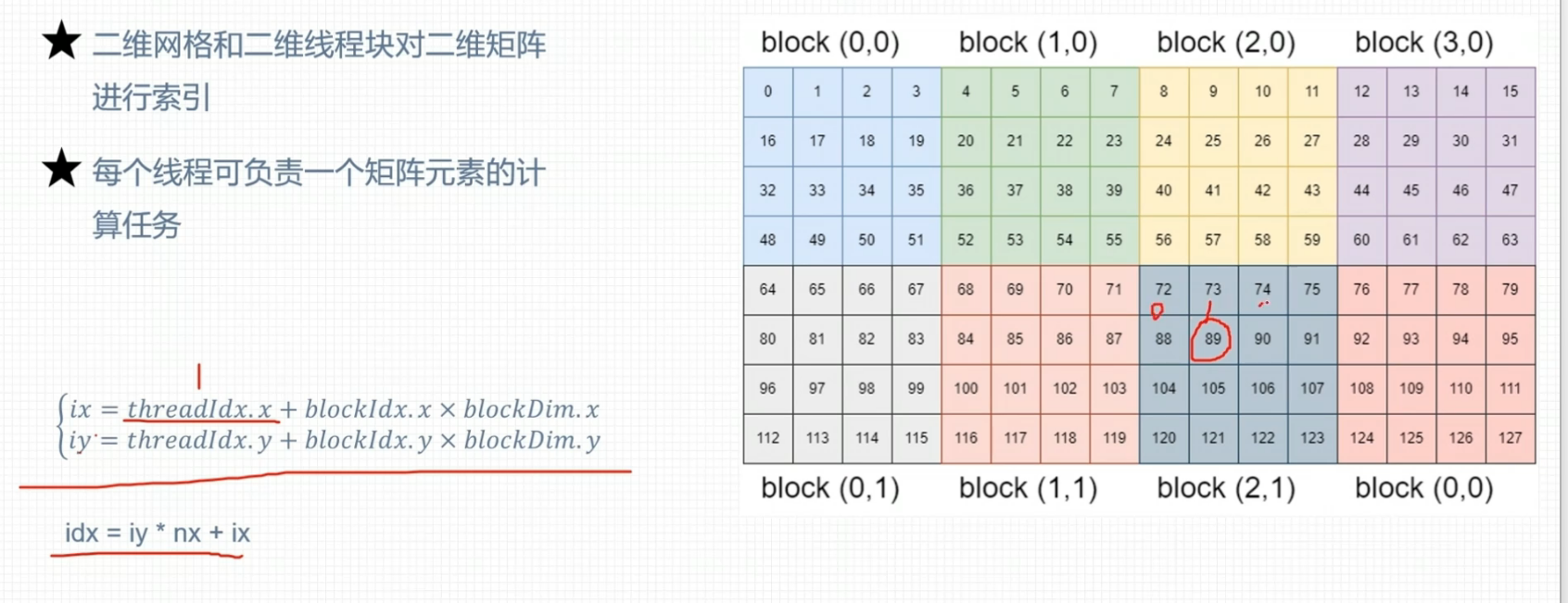
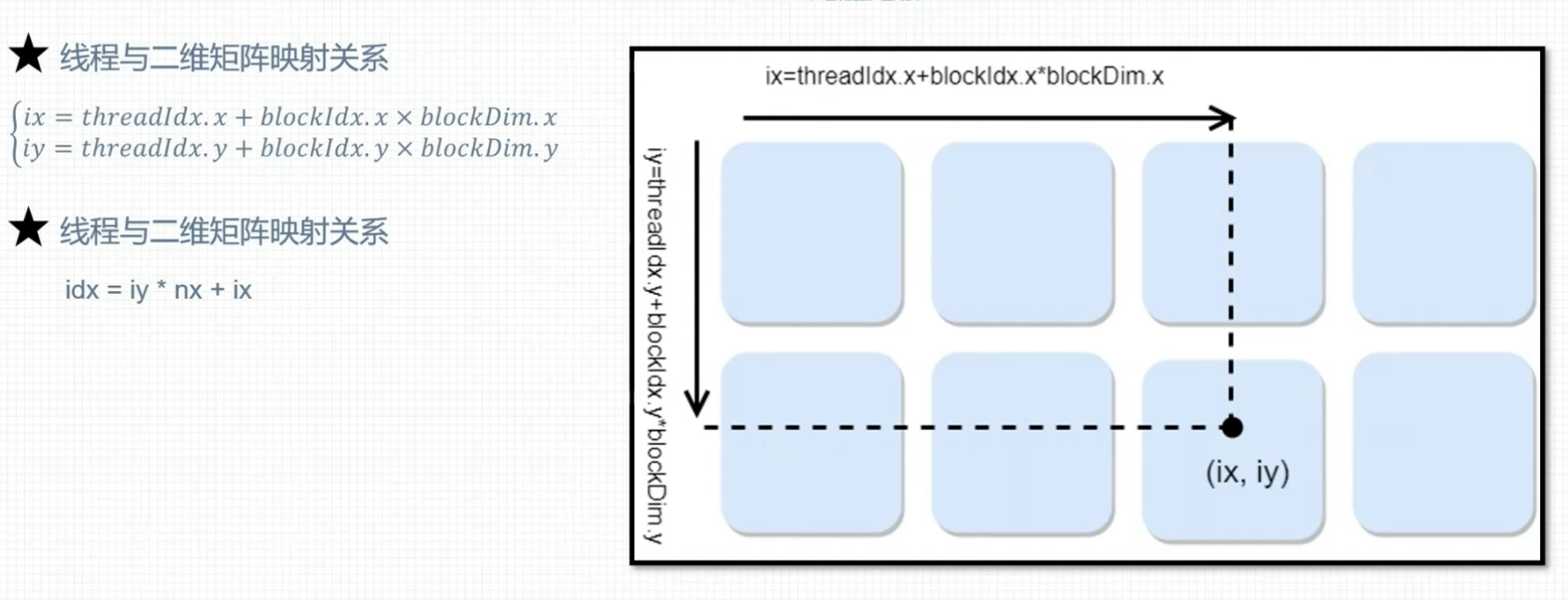
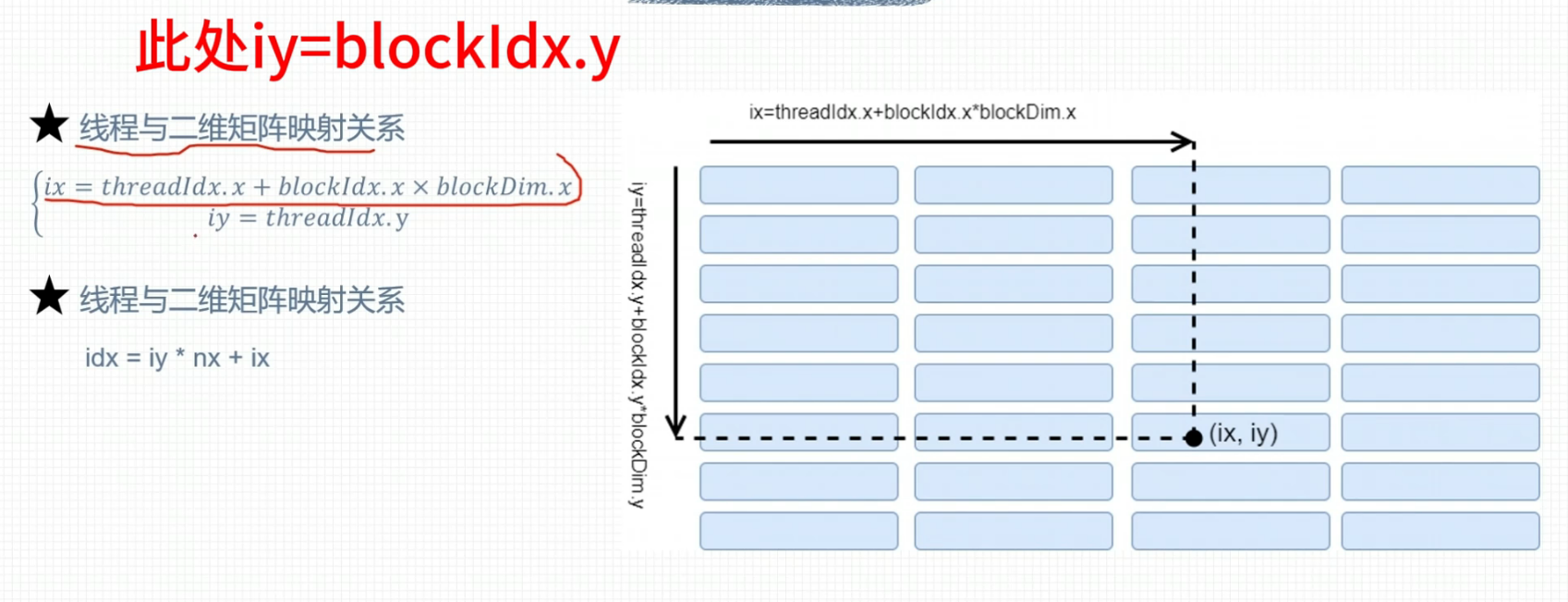
线程全局索引计算方式
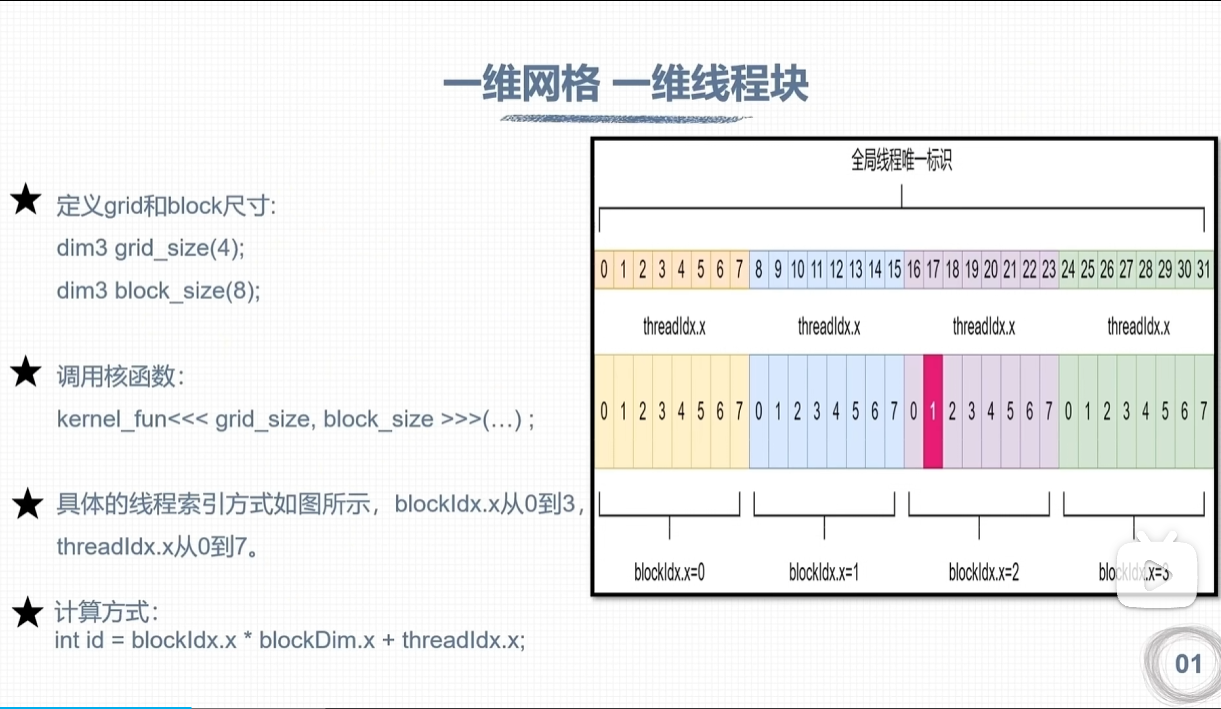
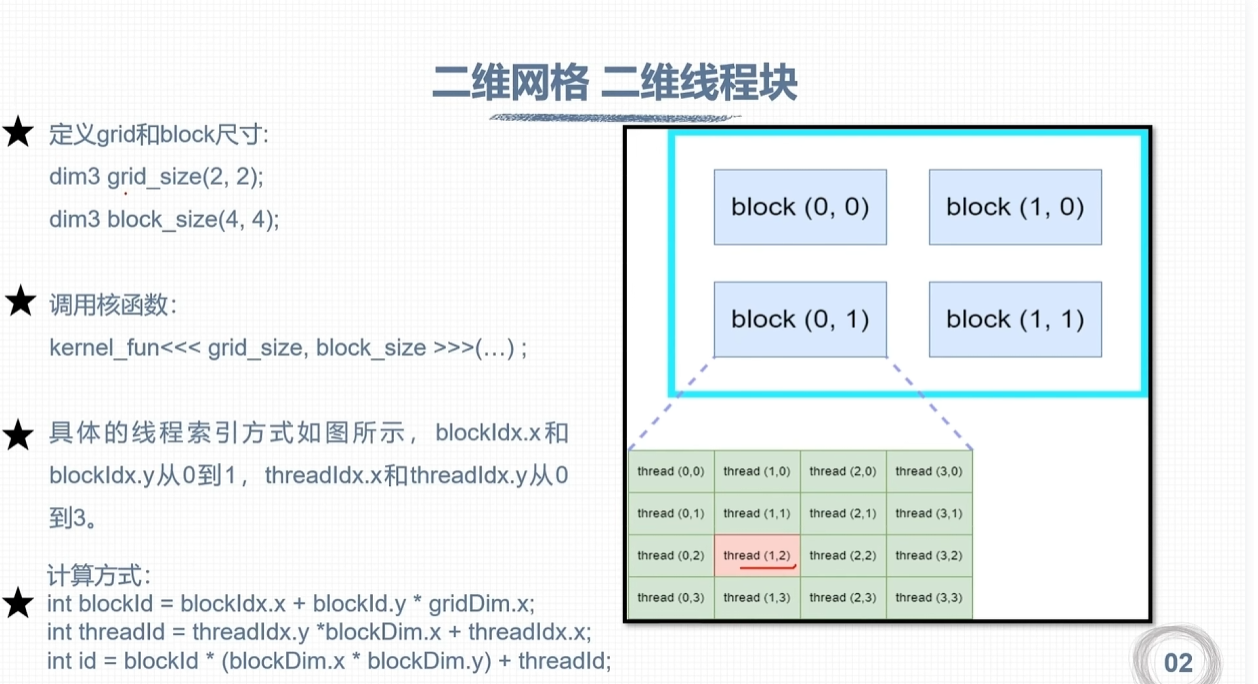
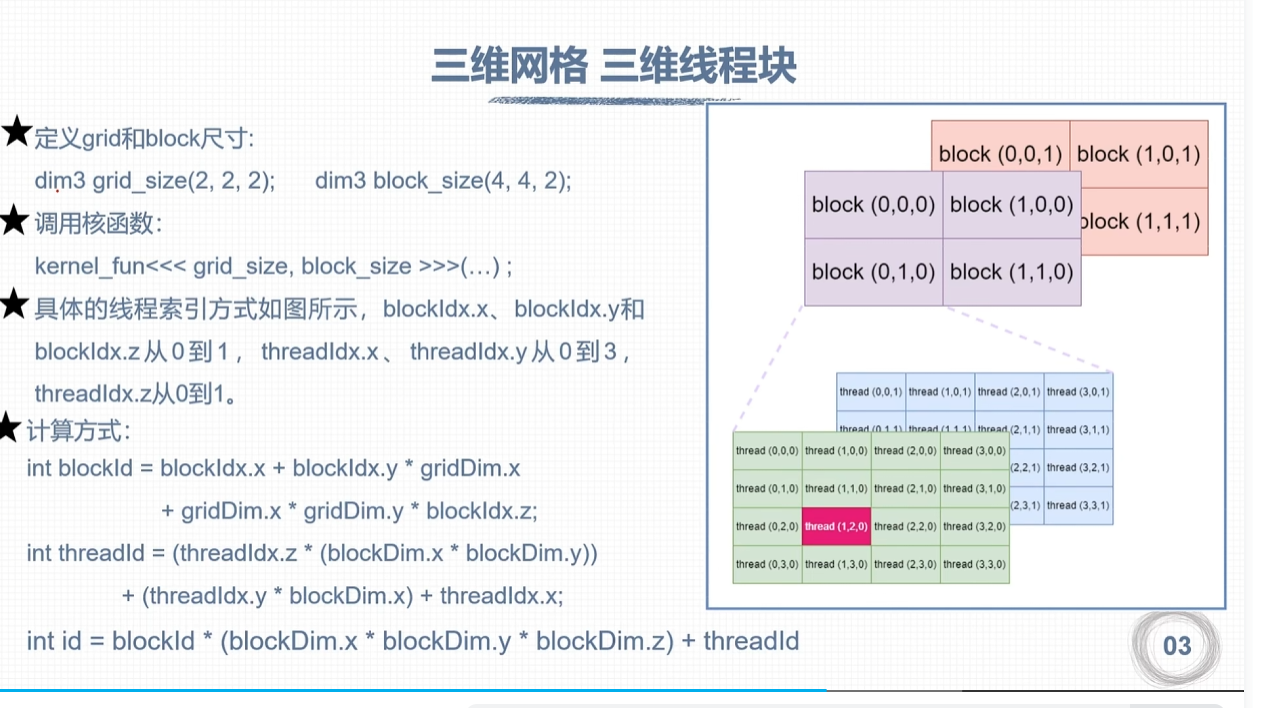



CUDA矩阵加法运算程序
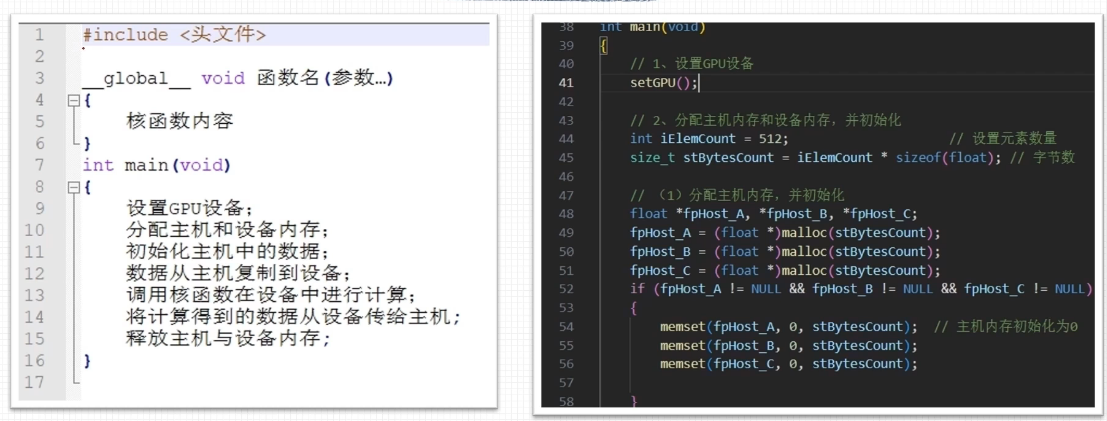
CUDA程序基本框架
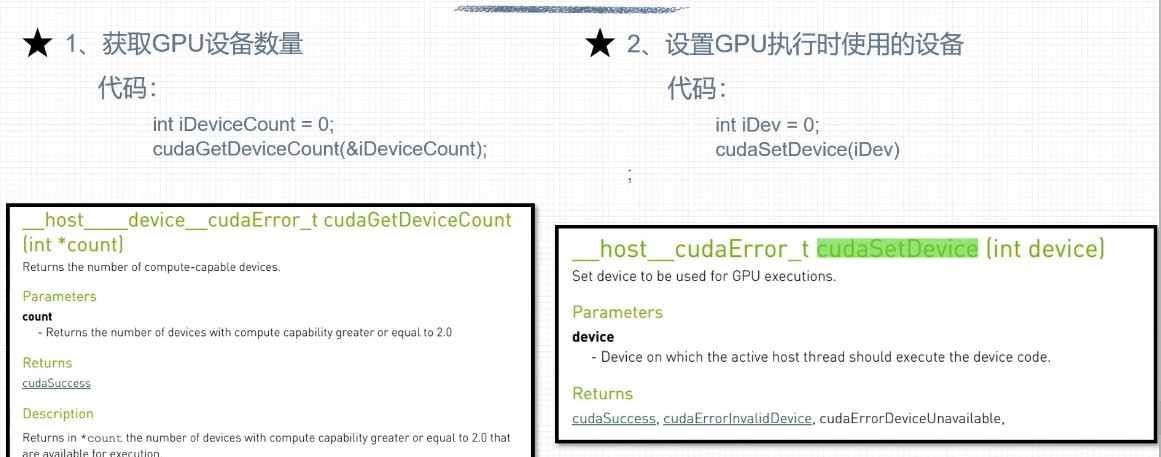
设置GPU设备
#include<stdio.h>
__global__ void kernel(void){
printf("Hello World from GPU!\n");
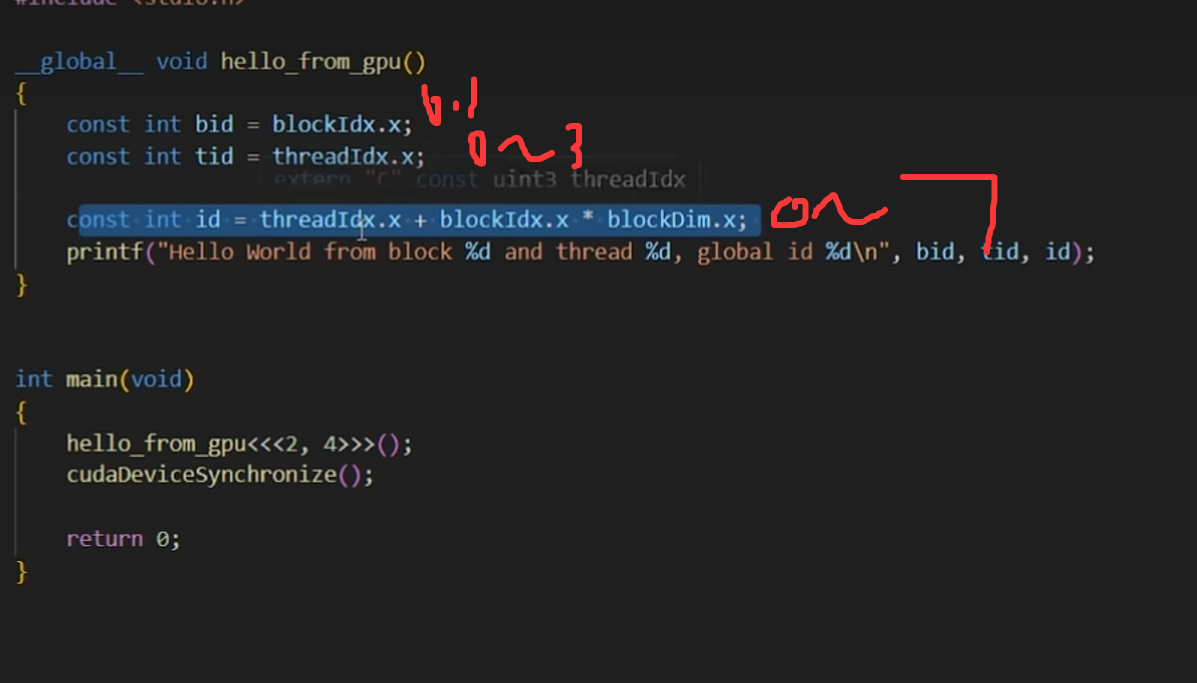
const int bid = blockIdx.x;
const int tid = threadIdx.x;
const int id = threadIdx.x+blockIdx.x*blockDim.x;
printf("bid=%d, tid=%d, id=%d\n", bid, tid, id);
}
int main(void)
{
// 检测计算机GPU的数量
int deviceCount = 0;
cudaError_t error_id = cudaGetDeviceCount(&deviceCount);
if (error_id != cudaSuccess) {
printf("cudaGetDeviceCount returned %d\n-> %s\n", (int)error_id, cudaGetErrorString(error_id));
printf("Result = FAIL\n");
exit(EXIT_FAILURE);
}
if (deviceCount == 0)
printf("There are no available device(s) that support CUDA\n");
else
printf("Detected %d CUDA Capable device(s)\n", deviceCount);
// 设置执行
int iDevice = 0;
error_id = cudaSetDevice(iDevice);
if (error_id != cudaSuccess) {
printf("cudaSetDevice returned %d\n-> %s\n", (int)error_id, cudaGetErrorString(error_id));
printf("Result = FAIL\n");
exit(EXIT_FAILURE);
}
return 0;
}
//nvcc test.cu -o test -arch=sm_86
内存管理
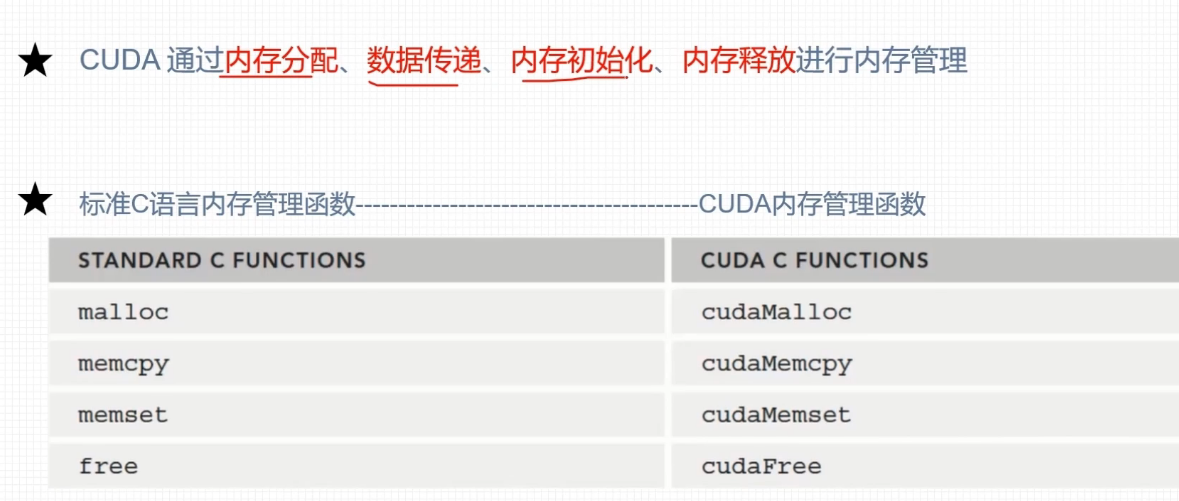
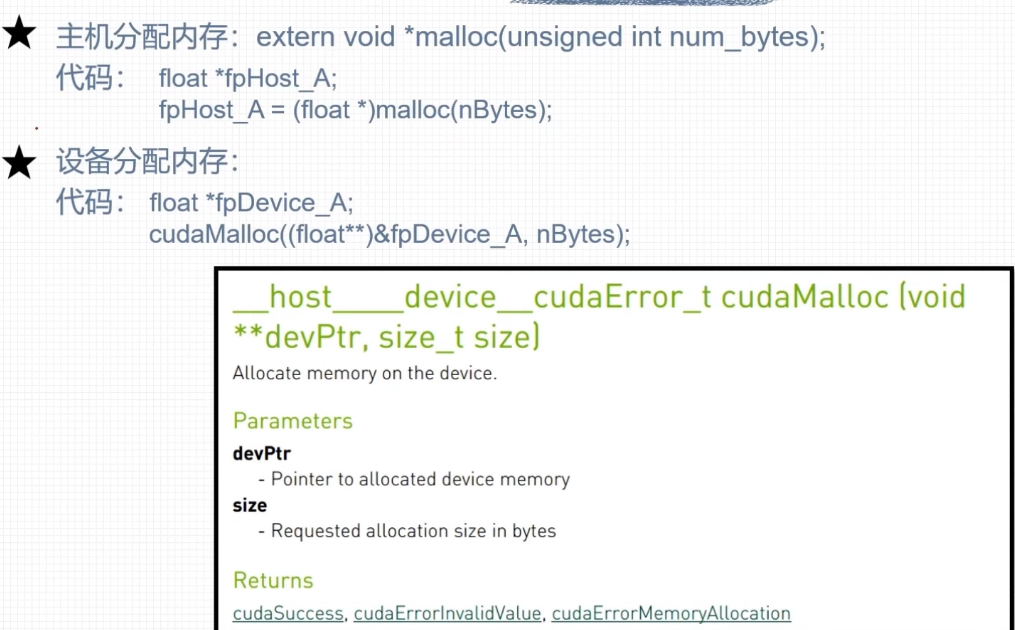



CPU的计算方式

GPU的计算方式
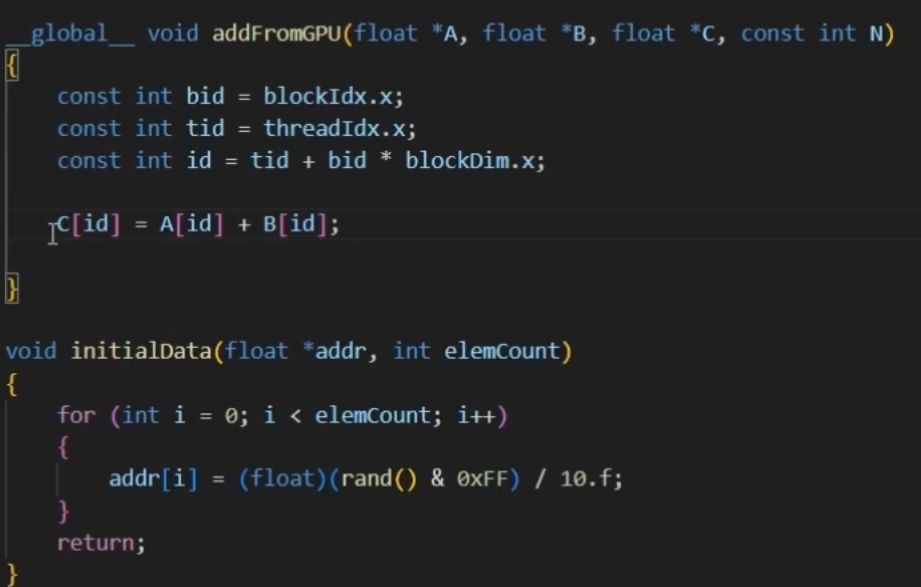
#include<stdio.h>
#include "./tools/common.cuh"
__global__ void VecAdd(const float* A, const float* B, float* C, int N)
{
// 计算机当前线程的id
int id = blockDim.x * blockIdx.x + threadIdx.x;
if (id < N)
{
C[id] = A[id] + B[id];
}
}
int main(void)
{
// 设置GPU设备
setGPU();
// 分配主机内存和设备内存,并初始化
int iElemCount = 512; // 设置元素数量
size_t stBytesCount = iElemCount * sizeof(float); // 字节数
// (1) 分配主机内存,并初始化
float *foHost_A,*foHost_B, *foHost_C;
foHost_A = (float*)malloc(stBytesCount);
foHost_B = (float*)malloc(stBytesCount);
foHost_C = (float*)malloc(stBytesCount);
if(foHost_A==NULL || foHost_B==NULL || foHost_C==NULL)
{
printf("Host Memory Allocate Failed.\n");
return -1;
}
else
{
memset(foHost_A, 0, stBytesCount);
memset(foHost_B, 0, stBytesCount);
memset(foHost_C, 0, stBytesCount);
printf("Host Memory Allocate Succeed.\n");
}
//(2) 分配设备内存
float *foDev_A, *foDev_B, *foDev_C;
cudaMalloc((float**)&foDev_A, stBytesCount);
cudaMalloc((float**)&foDev_B, stBytesCount);
cudaMalloc((float**)&foDev_C, stBytesCount);
if(foDev_A==NULL || foDev_B==NULL || foDev_C==NULL)
{
printf("Device Memory Allocate Failed.\n");
return -1;
}
else
{
cudaMemset(foDev_A, 0, stBytesCount);
cudaMemset(foDev_B, 0, stBytesCount);
cudaMemset(foDev_C, 0, stBytesCount);
printf("Device Memory Allocate Succeed.\n");
}
// (3)初始化主机中的数据
for(int i=0; i<iElemCount; i++)
{
foHost_A[i] = (float)i;
foHost_B[i] = (float)i*10.0f;
foHost_C[i] = (float)i*10.1f;
}
// (4)将主机内存的数据拷贝到设备内存
cudaMemcpy(foDev_A, foHost_A, stBytesCount, cudaMemcpyHostToDevice);
cudaMemcpy(foDev_B, foHost_B, stBytesCount, cudaMemcpyHostToDevice);
cudaMemcpy(foDev_C, foHost_C, stBytesCount, cudaMemcpyHostToDevice);
printf("Host to Device MemCpy Succeed.\n");
// (5)设置线程数和块数,并启动核函数
dim3 block(32);
dim3 grid(iElemCount/32);
VecAdd<<<grid, block>>>(foDev_A, foDev_B, foDev_C, iElemCount);
cudaDeviceSynchronize();
// (6) 将计算得到的数据从设备内存拷贝到主机内存
cudaMemcpy(foHost_C, foDev_C, stBytesCount, cudaMemcpyDeviceToHost);
printf("Device to Host MemCpy Succeed.\n");
// 打印foDev_A, foDev_B, foDev_C的前10个数据
for(int i=0; i<10; i++)
{
printf("A[%d]=%f, B[%d]=%f, C[%d]=%f\n", i, foHost_A[i], i, foHost_B[i], i, foHost_C[i]);
}
// 释放主机内存和设备内存
if(foHost_A) free(foHost_A);
if(foHost_B) free(foHost_B);
if(foHost_C) free(foHost_C);
if(foDev_A) cudaFree(foDev_A);
if(foDev_B) cudaFree(foDev_B);
if(foDev_C) cudaFree(foDev_C);
return 0;
}
//nvcc test.cu -o test -arch=sm_86
自定义设备函数

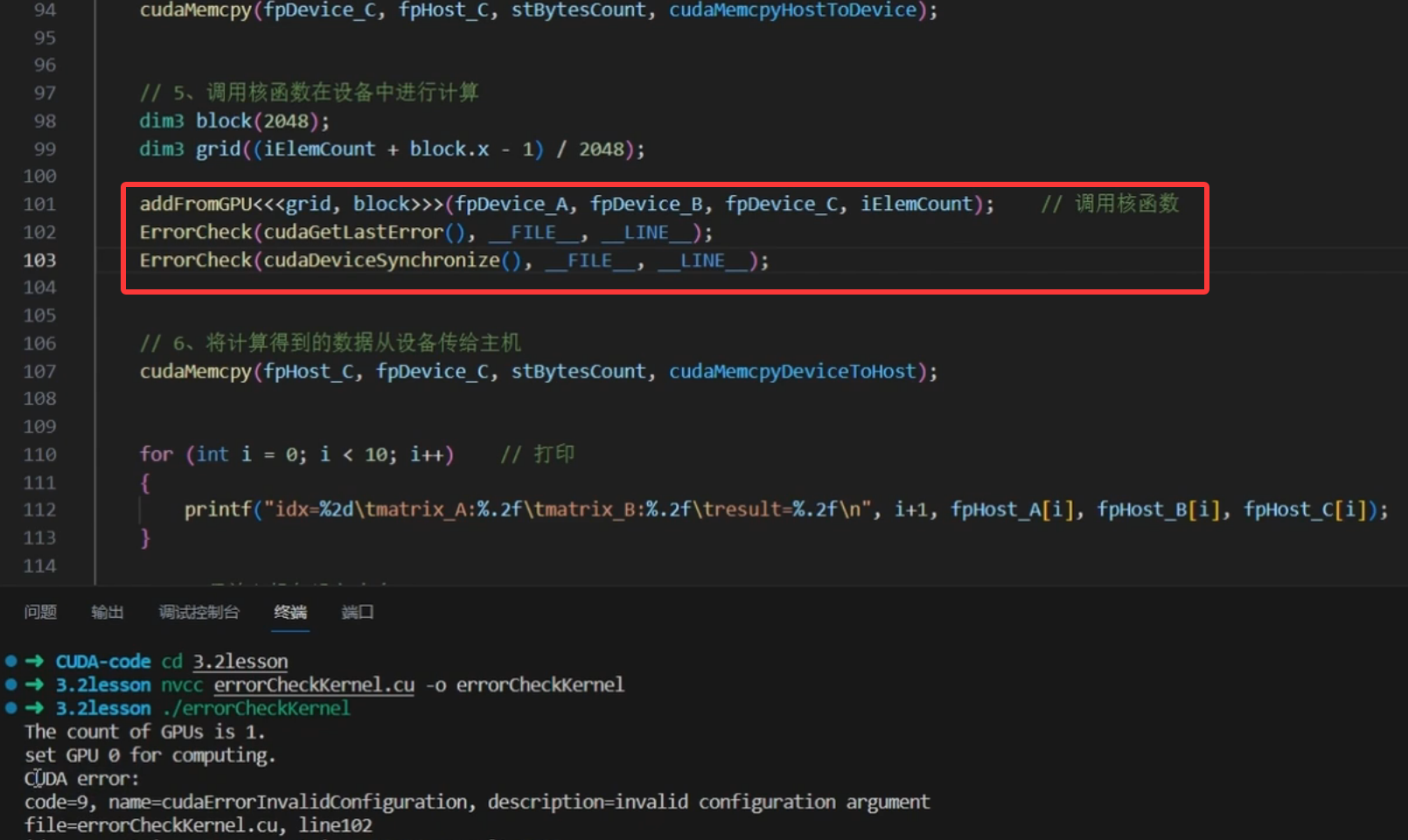
CUDA错误检查
运行时API错误代码

错误检查函数


检查核函数

CUDA记时
事件记时

nvprof性能刨析

运行GPU信息查询
运行时API查询GPU信息

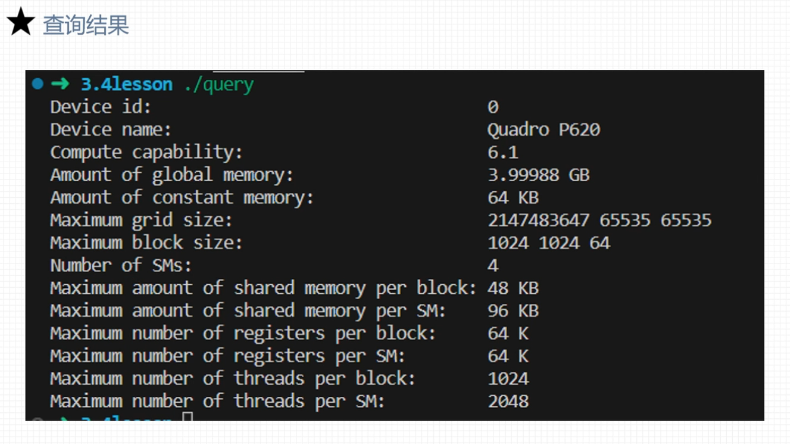
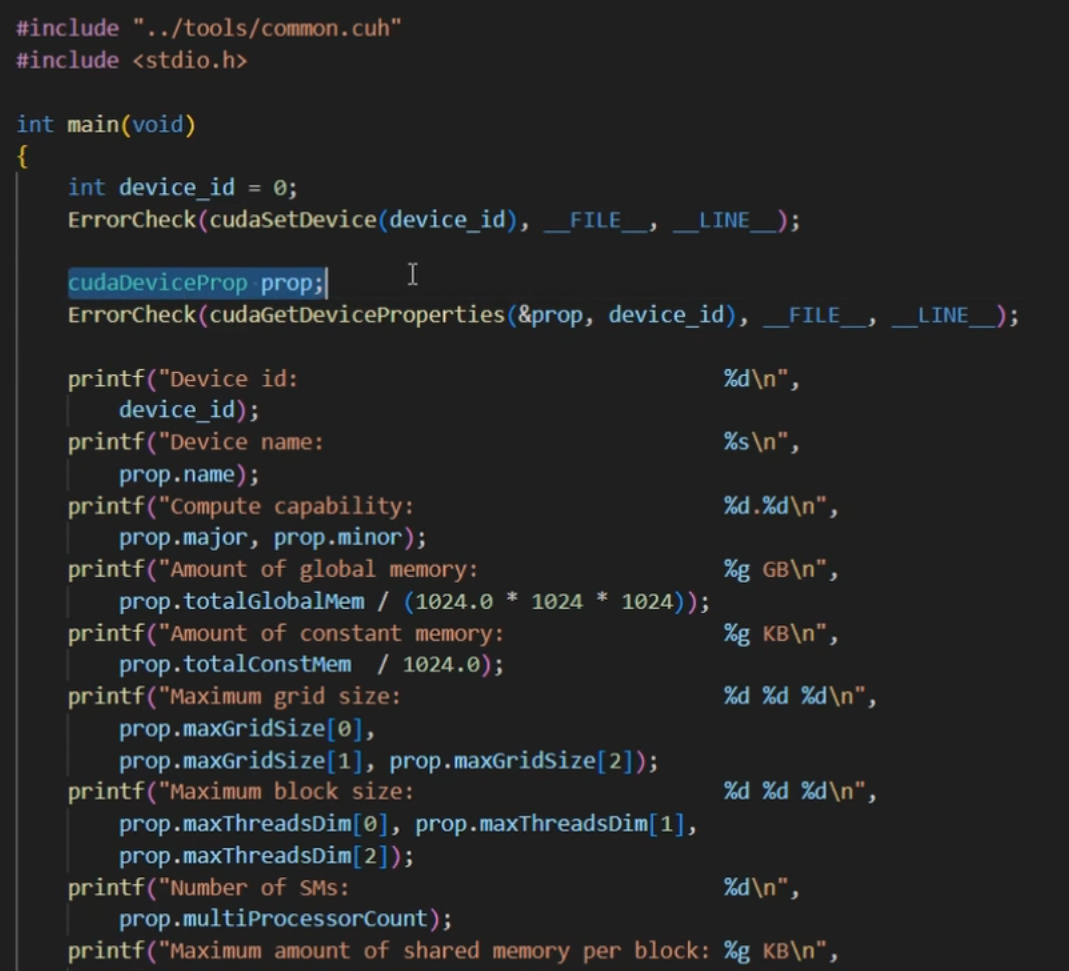
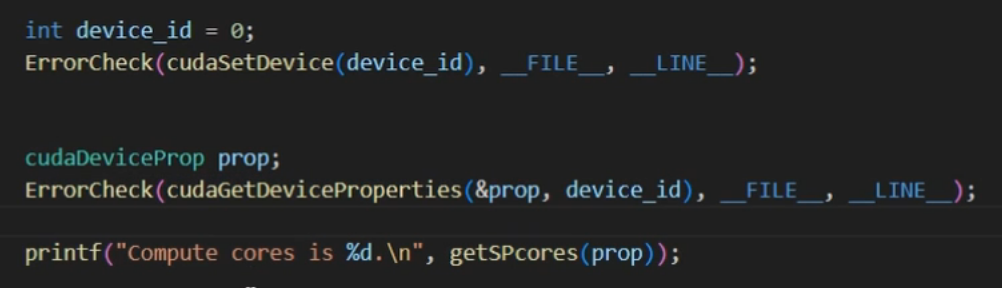
查询GPU计算核心数量

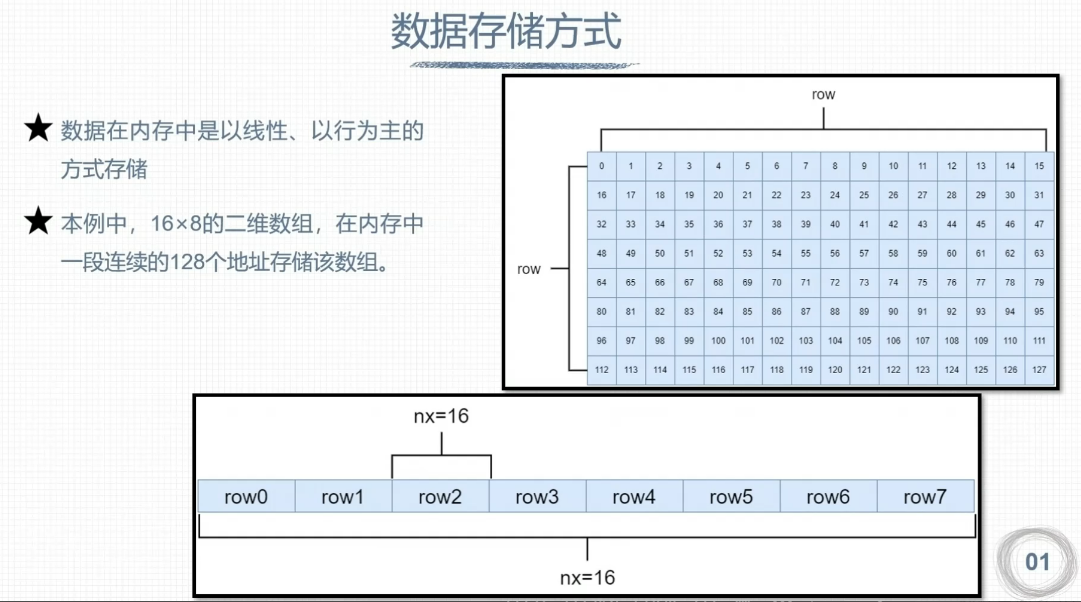
组织线程模型
二维网格二维线程块
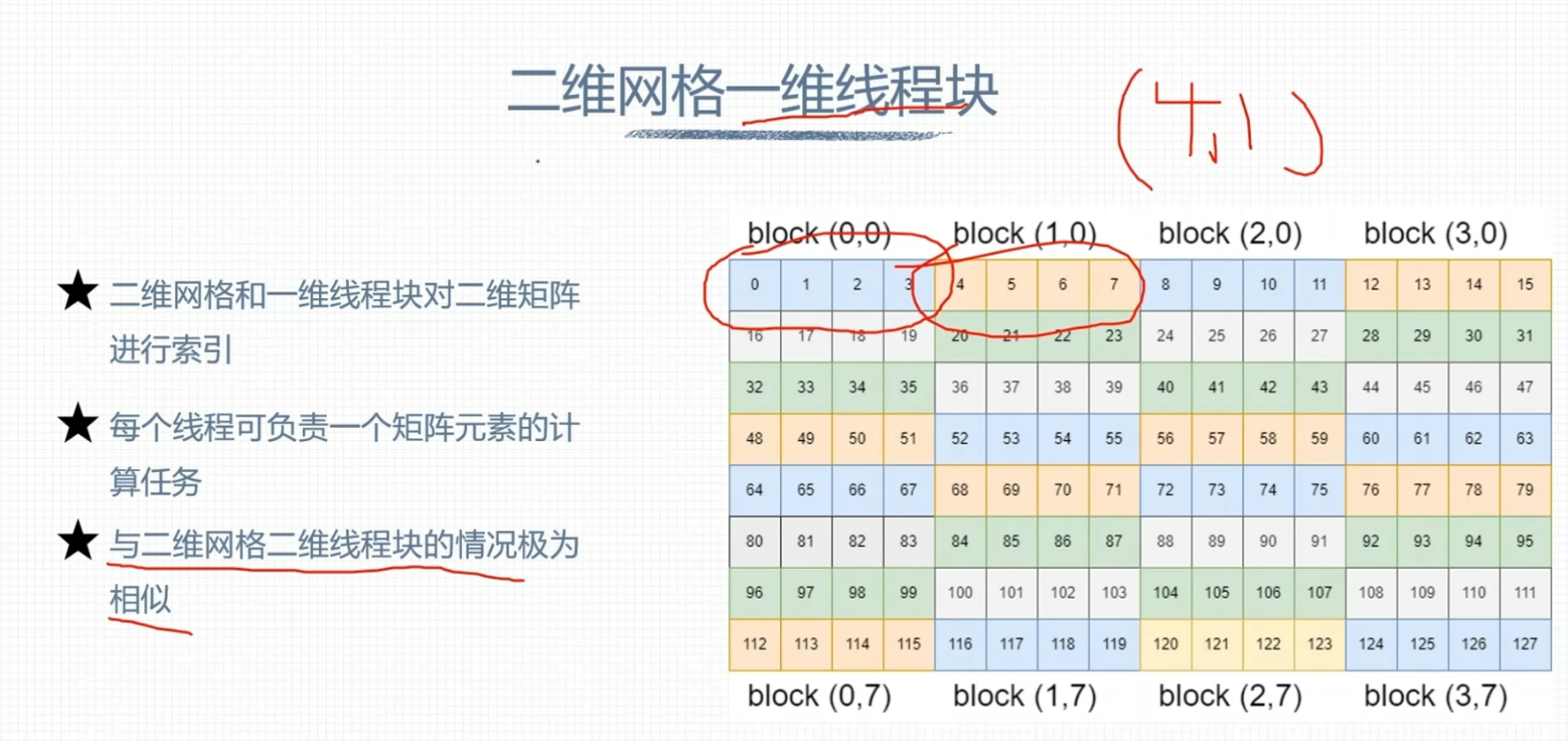
二维网格一维线程块
一维网格一维线程块
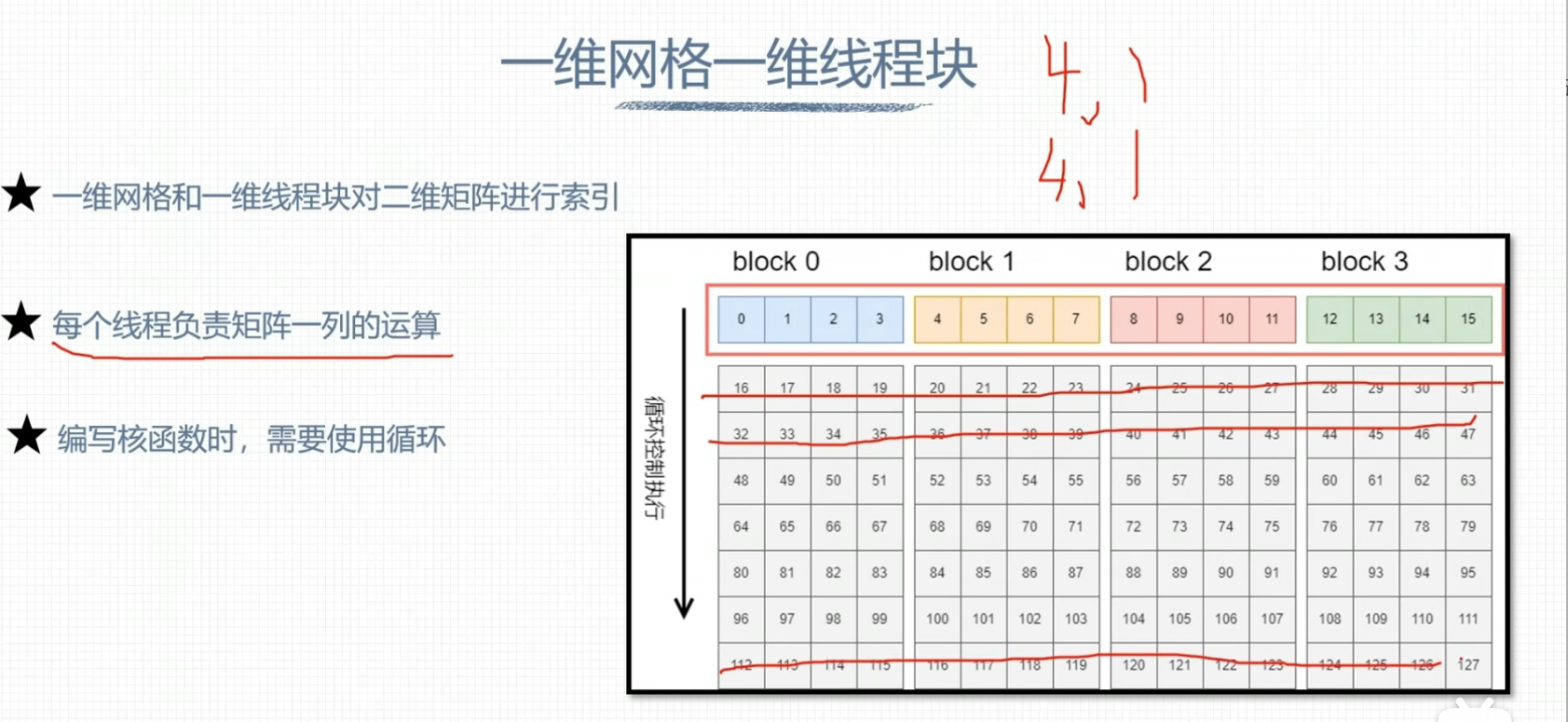
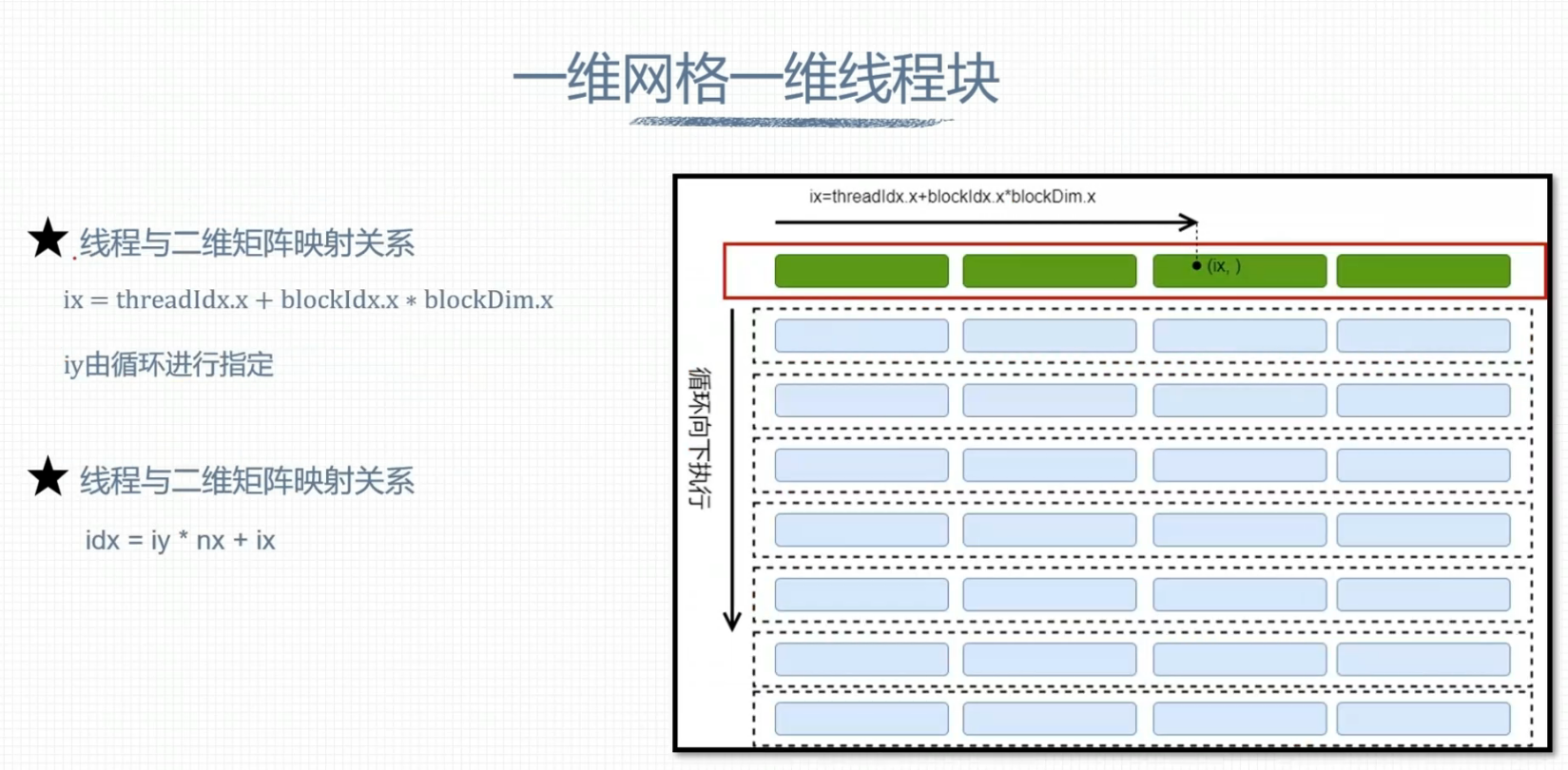
GPU硬件资源
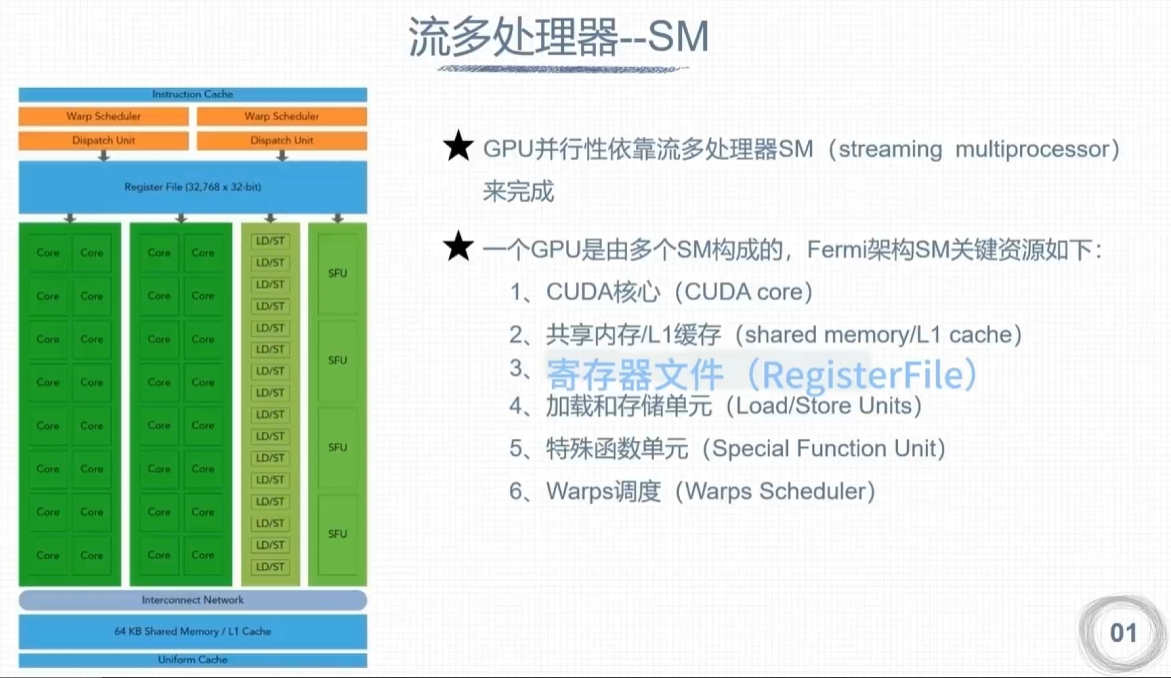
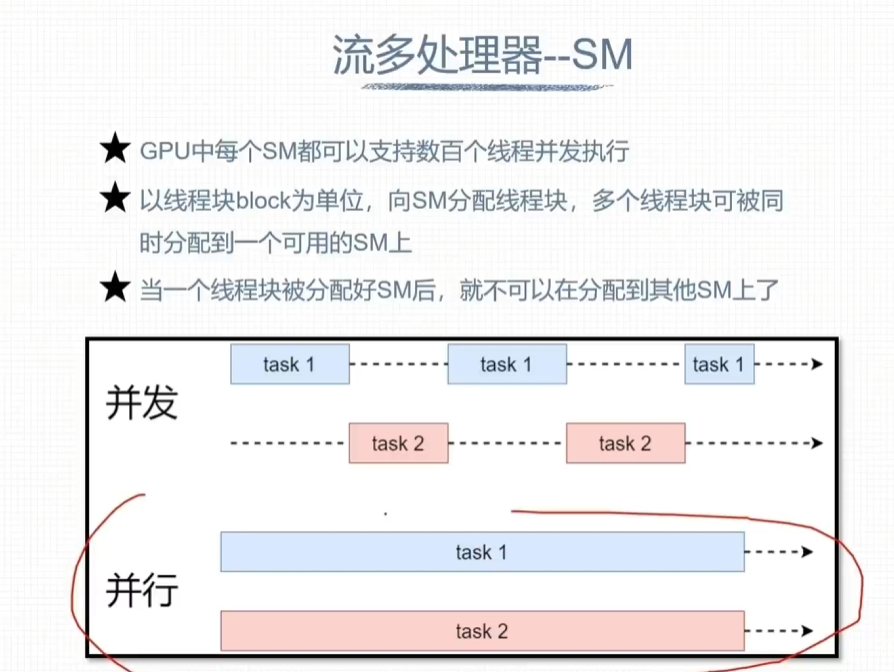
流多处理器 – SM
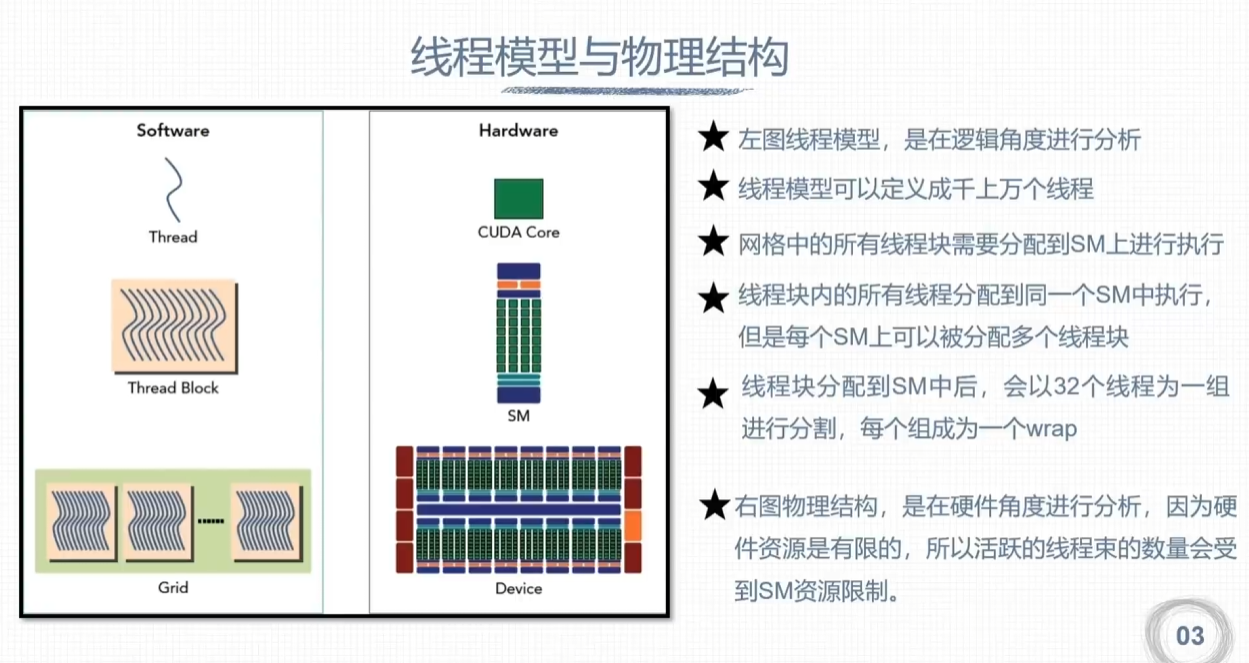
线程模型与物理结构
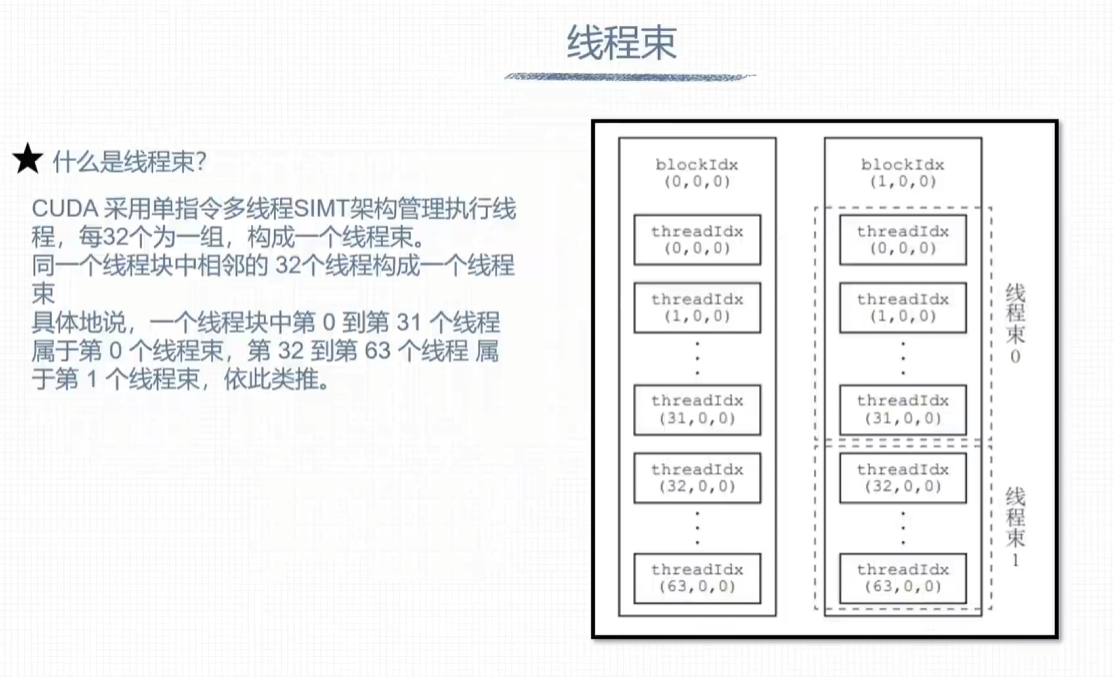
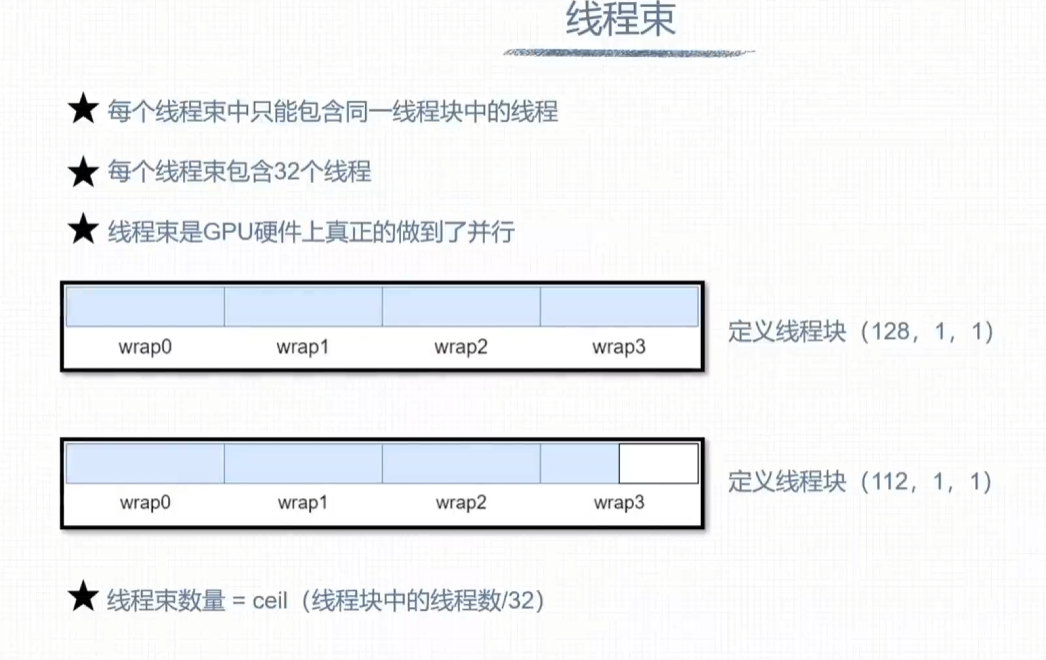
线程束
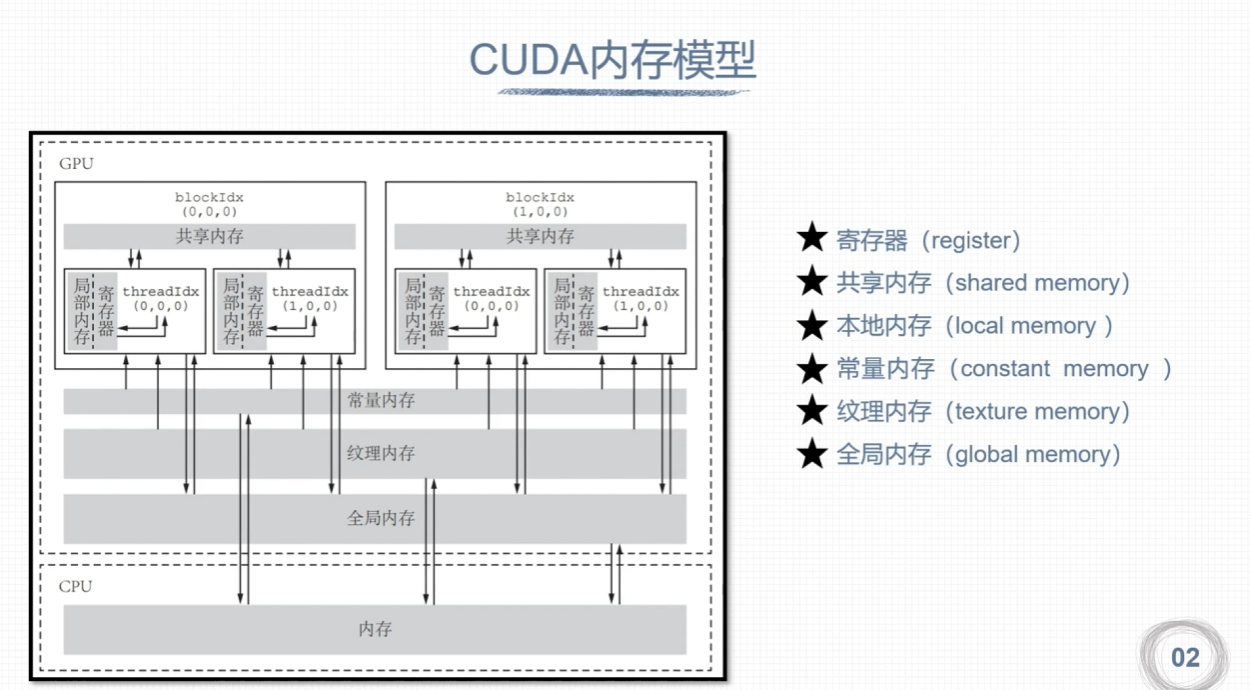
CUDA内存
内存结构层次特点

CUDA内存
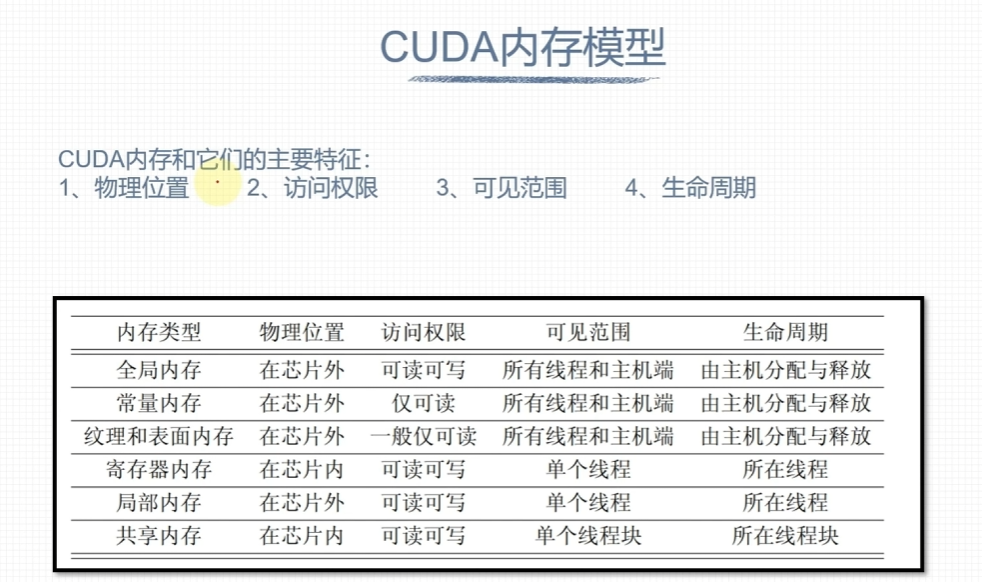
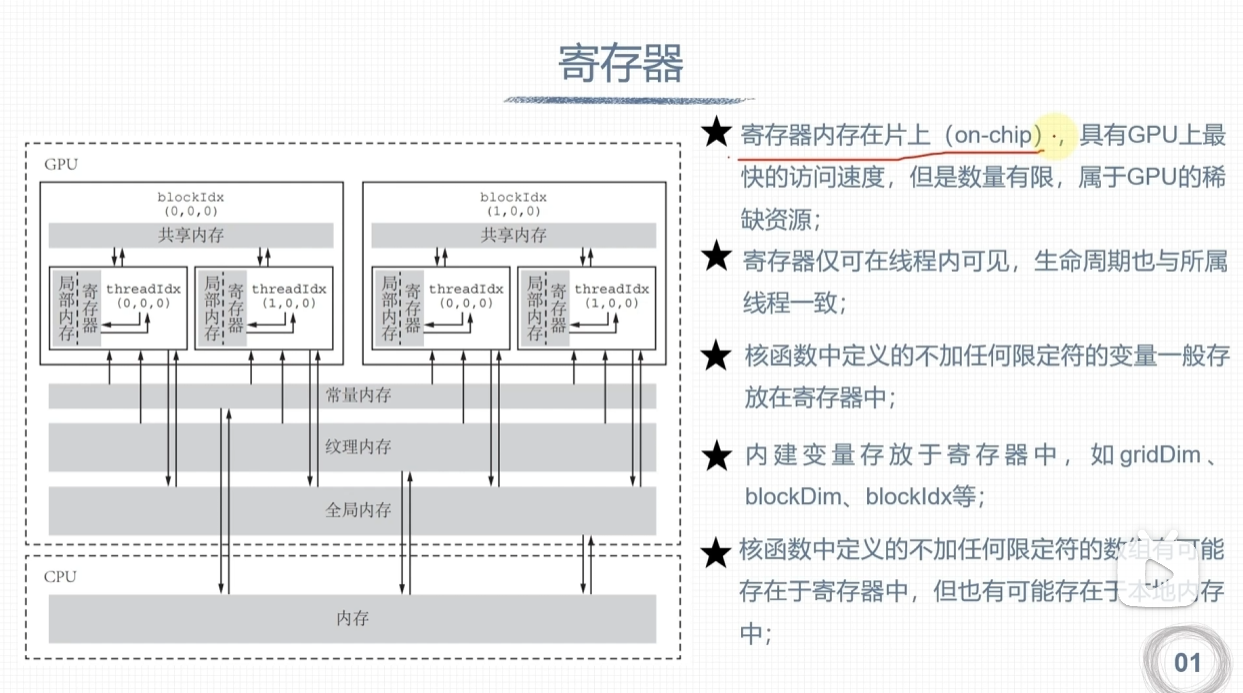
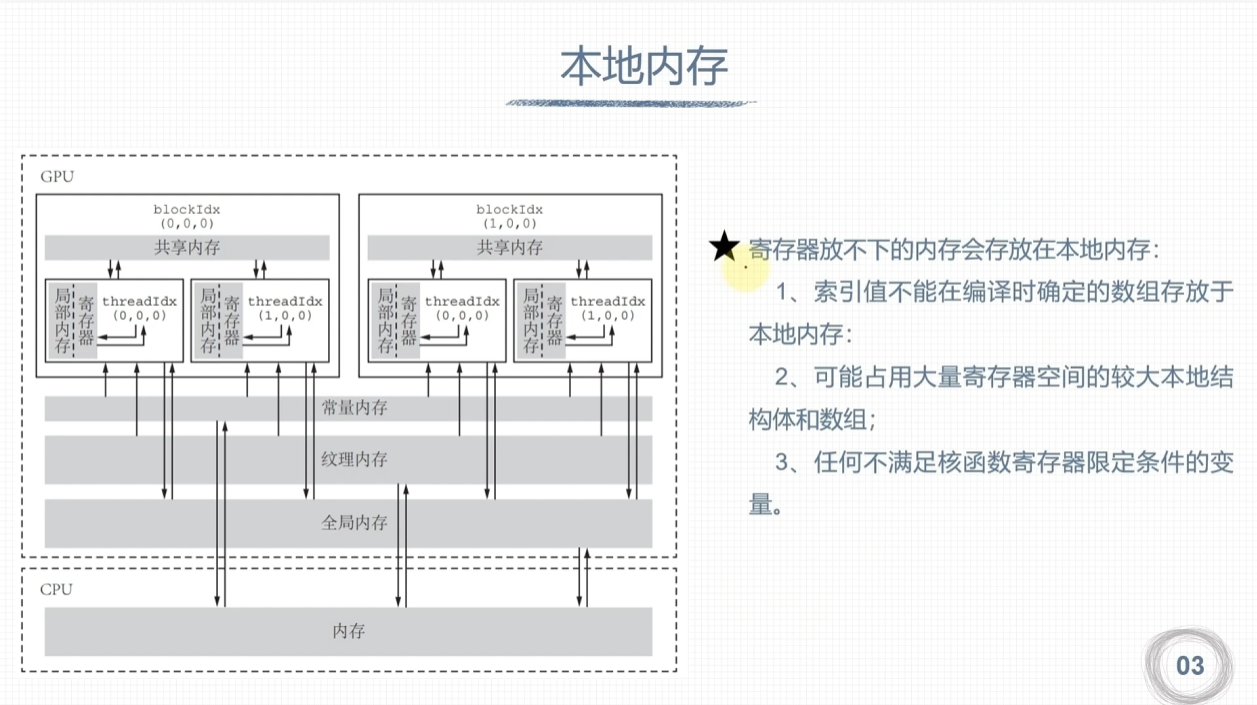
寄存器和本地内存



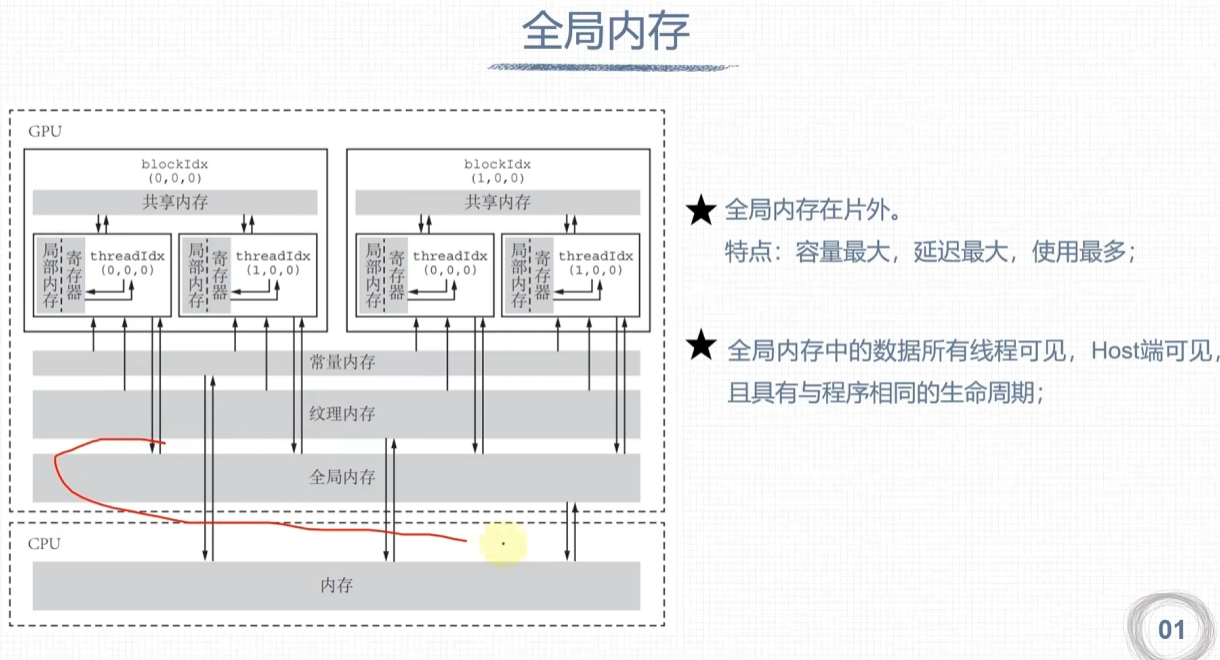
全局内存

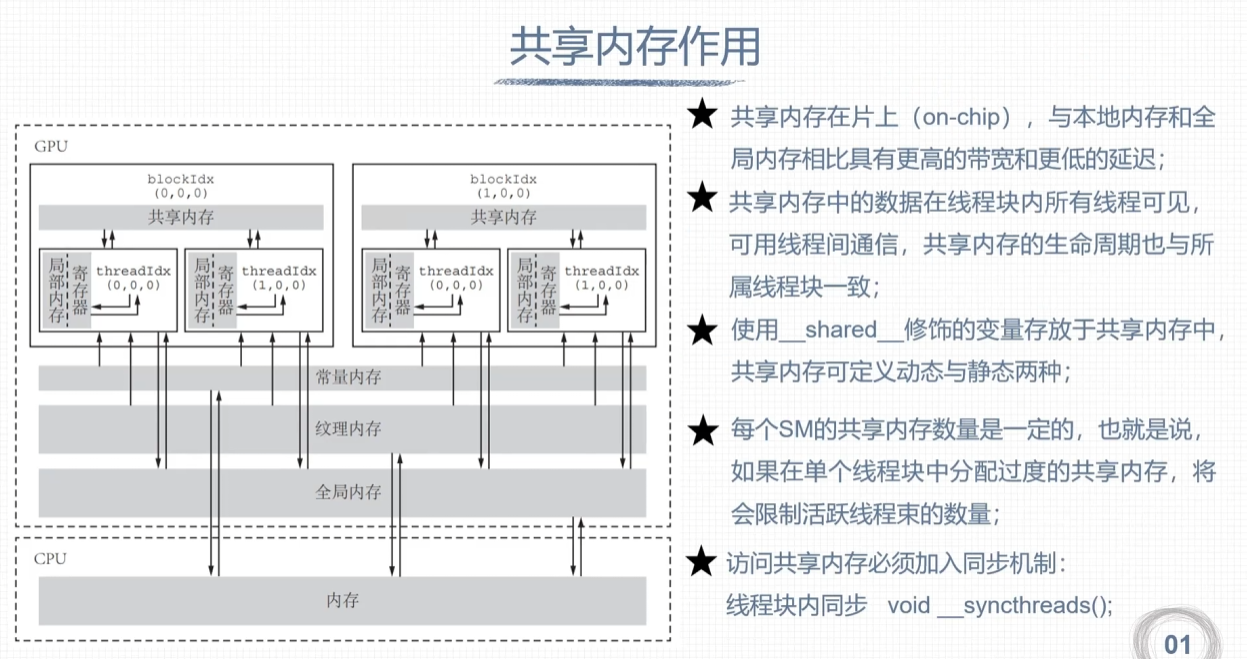
共享内存
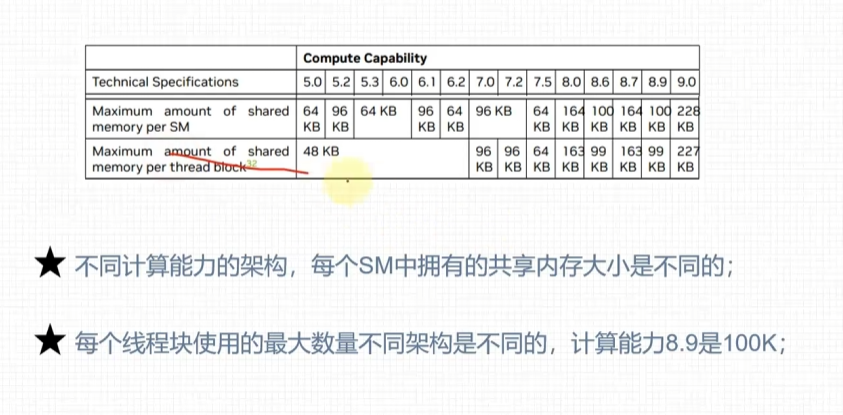


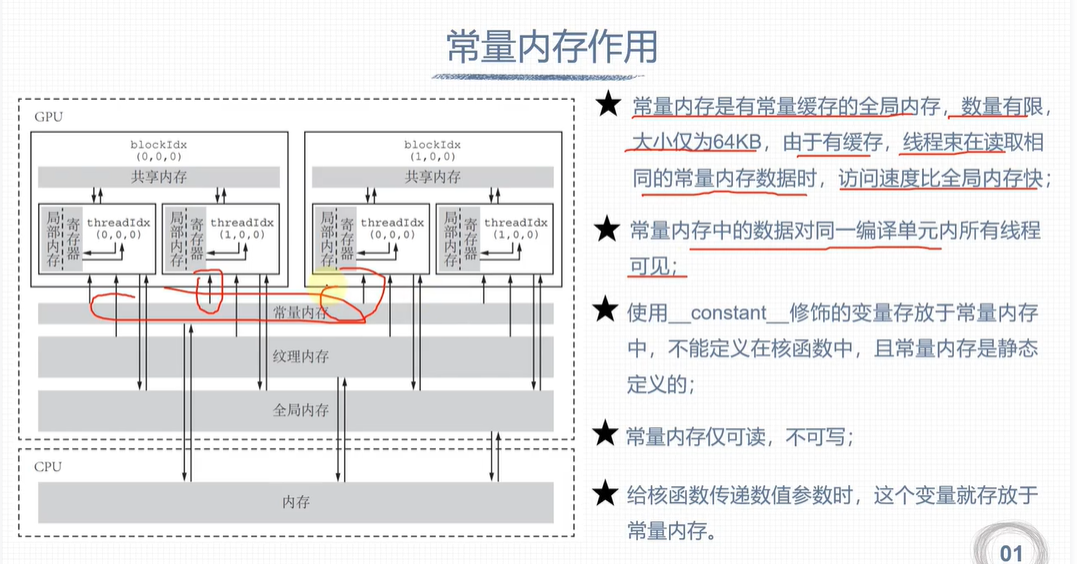
常量内存

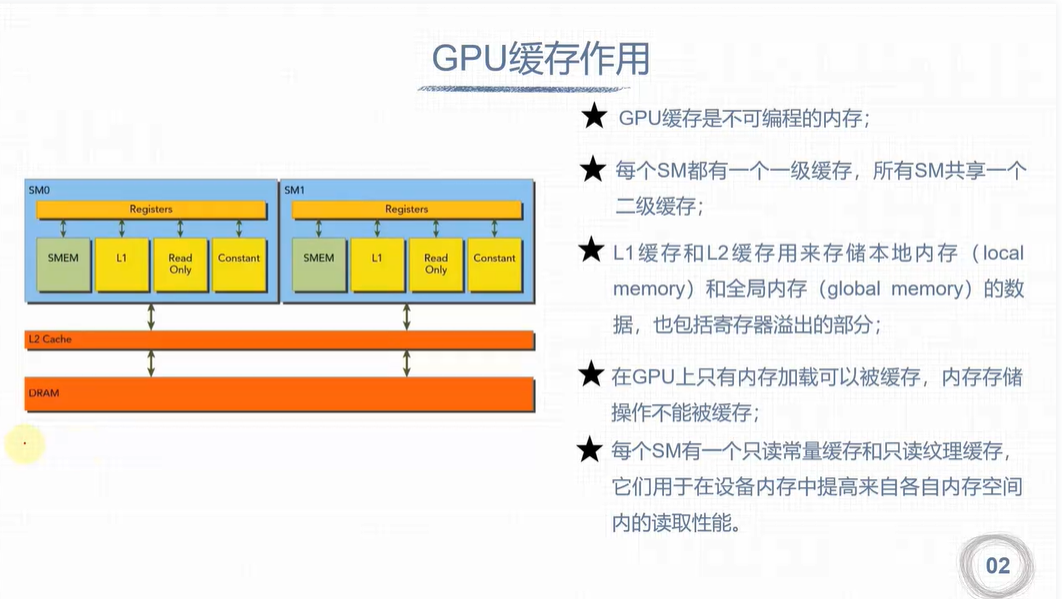
GPU缓存

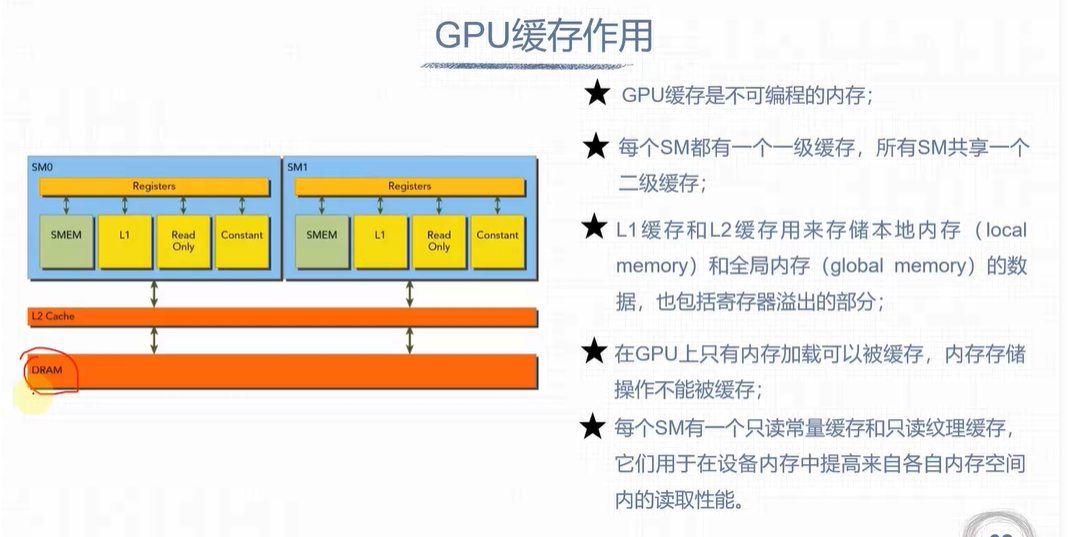



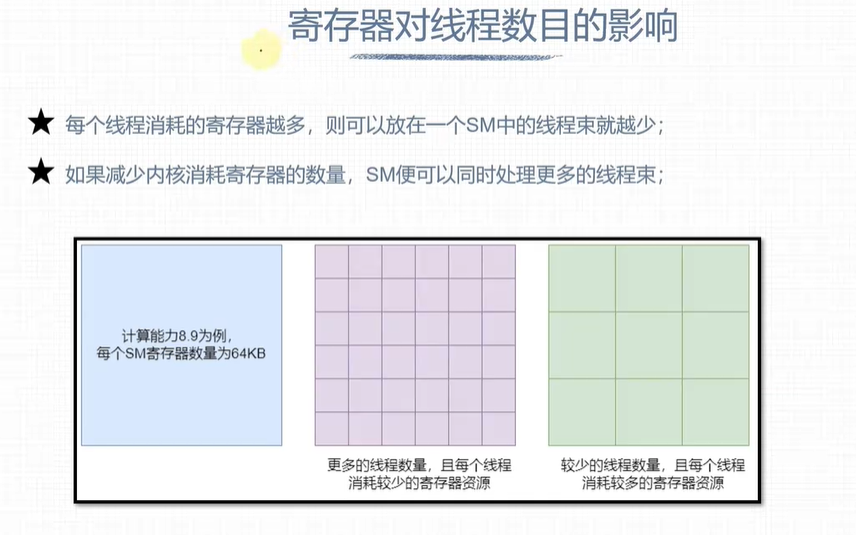
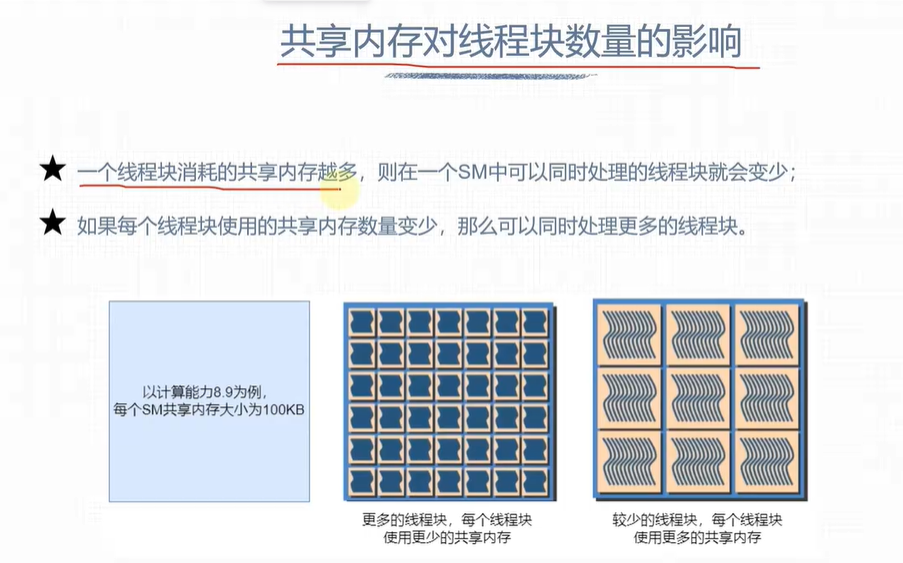
计算机资源分配




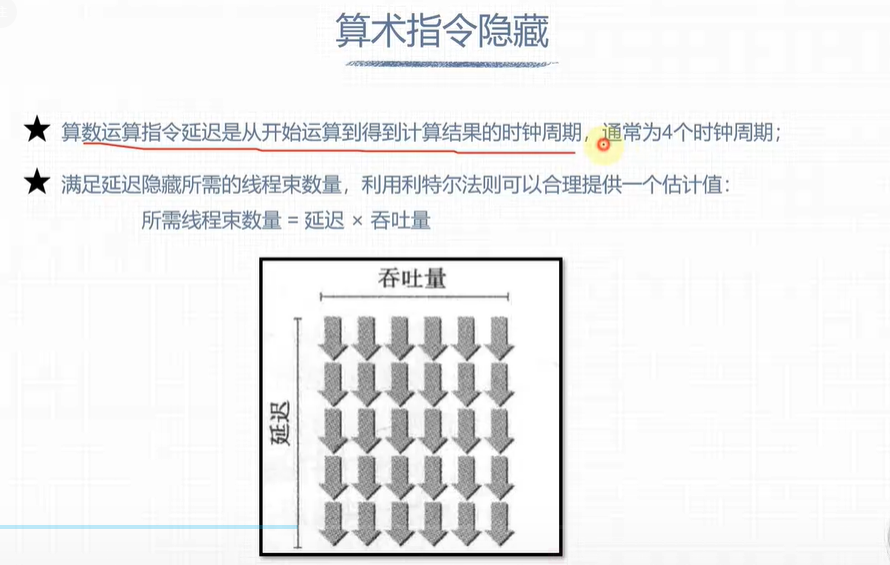
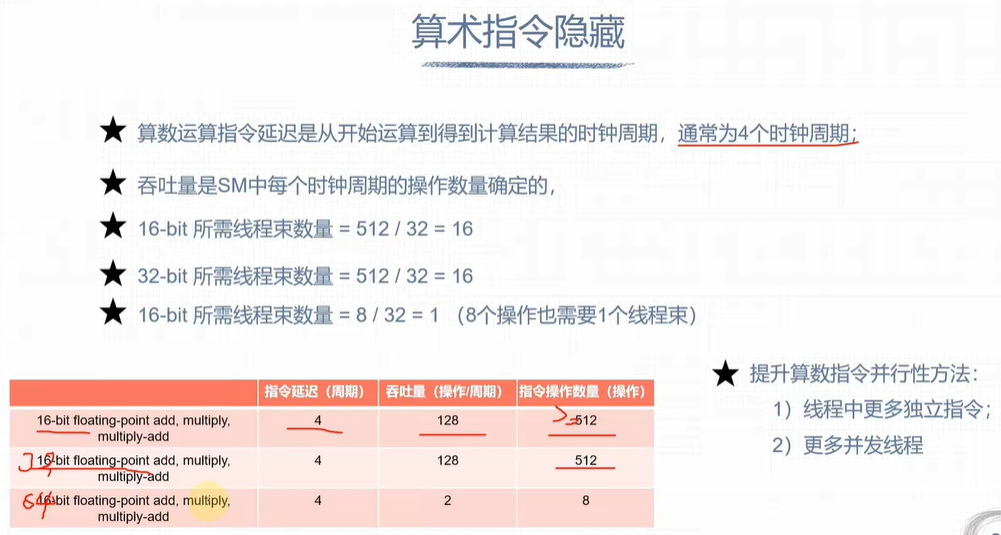
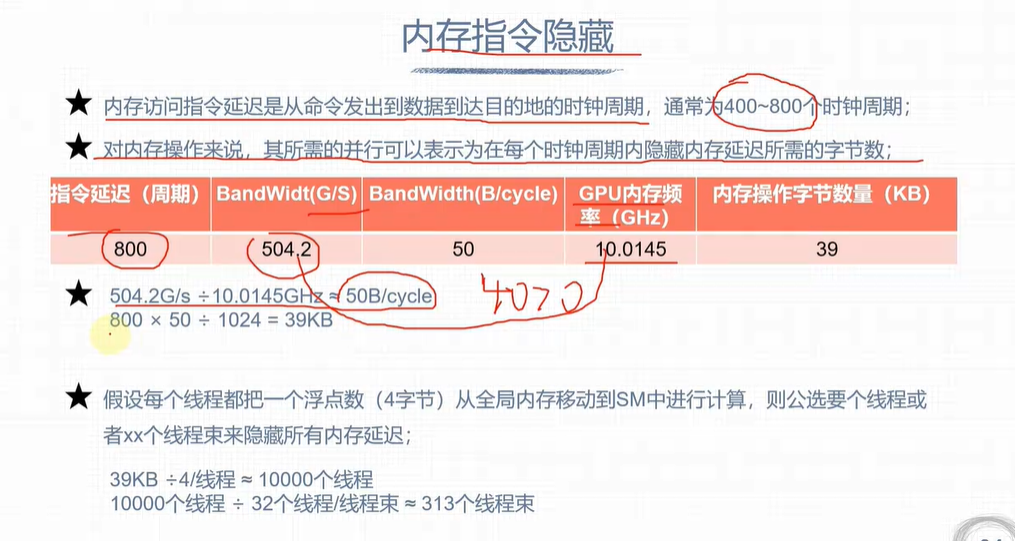
延迟隐藏

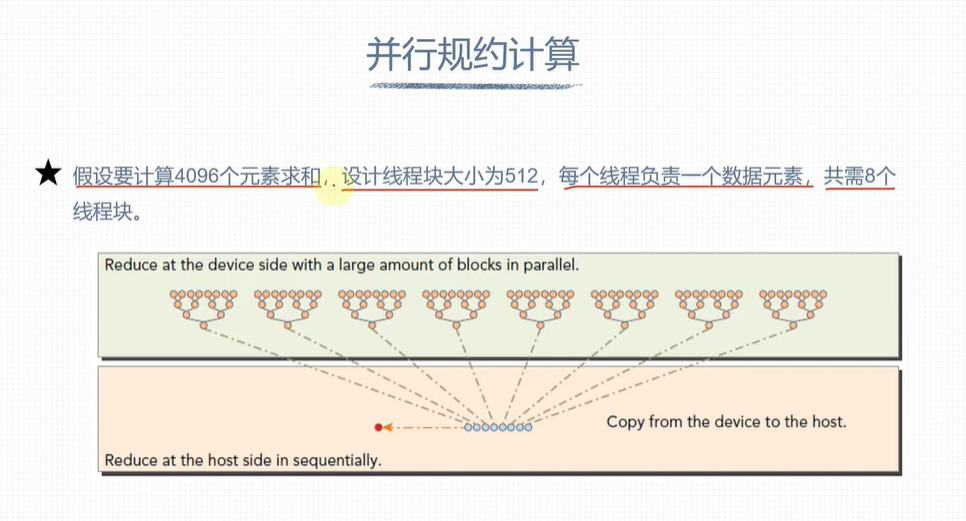
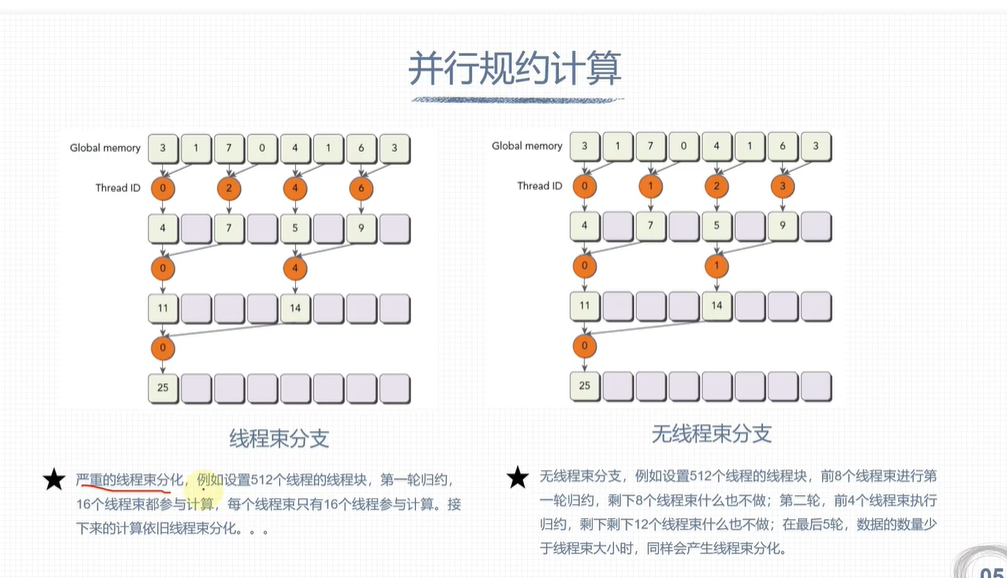
避免线程束分化





















 2193
2193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









