







- 图片和视频同时训练,latent code的方式、基础机构transformer,text条件的diffusion模型
- 支持不同的时长、分辨率、比例。分钟级别的生成
视觉数据转化为patchs
类似llm中的文字token
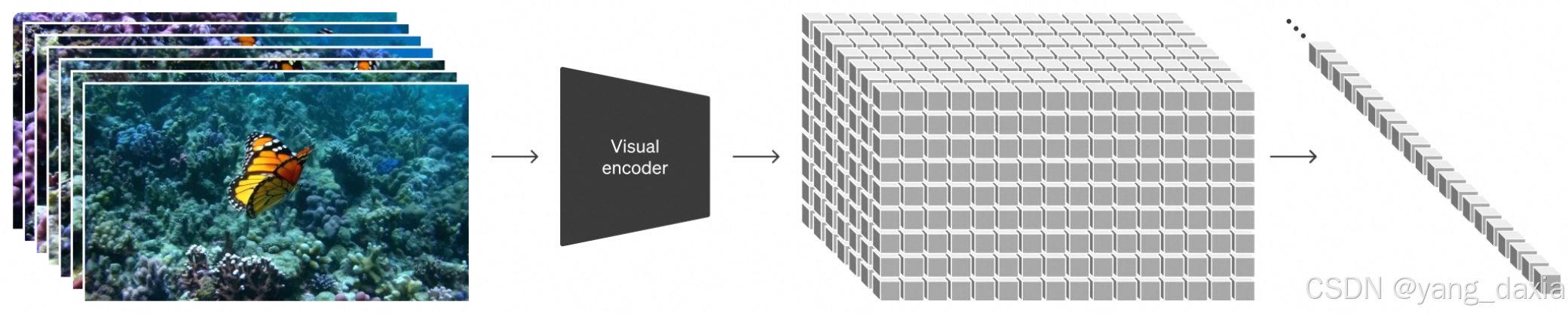
Video compression network
即encoder,将视频压缩为latent 维度
Spacetime latent patches
时空的隐patches,即视频压缩后的结果。图片可以看出单帧的视频
Scaling transformers for video generation
sora使用的是基于transformer的diffusion模型。transformer可以很好的scale,随着scale的增加,生成的效果越来越好

Improved framing and composition
使用视频的原始分辨率进行训练,有助于好看的构图生成。如果crop为正方形,效果下降。

Language understanding
sora参考了DALL*3对视频生成文本描述的方式。
专门训练了一个视频文本描述模型
使用GPT将用户的短prompt扩充为复杂的长prompt,提升生成效果
Prompting with images and videos
在文字prompt的基础上,还可以增加图片、视频的参考。适配多种生成任务
-
让图片动起来
-
扩展视频
-
sora结合Sdedit,可以对视频进行编辑,比如风格转换,环境转换
 - 连接两个视频,对两个视频的内容做插值
- 连接两个视频,对两个视频的内容做插值

-
仿真能力:3d场景一致性、时间一致性、和世界交互、仿真数字世界
讨论
交互生成比较差,如玻璃碎、吃东西
整个技术报告主要是功能介绍。技术细节几乎没有。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











