






 本文分享了在Spark项目中进行数据获取和转换的心得,包括从和鲸社区获取数据,将Excel和CSV文件转化为JSON,使用Notepad++和Navicat处理数据编码和格式问题,以及通过Spark统计地区最高销售额的例子。
本文分享了在Spark项目中进行数据获取和转换的心得,包括从和鲸社区获取数据,将Excel和CSV文件转化为JSON,使用Notepad++和Navicat处理数据编码和格式问题,以及通过Spark统计地区最高销售额的例子。
前言
本篇文章是小编在制spark项目时,在前期对数据进行获得,但在使用中时,却发现数据并不理想,在结合网上学习到的方法的得到的,主要是用各种软件将数据集转换后,得到自己理想的数据样式
目录
一,数据获得
在制作数据项目的过程中,数据是必不可少的,然而在很多小伙伴制作项目时,找一个适合做这个项目的数据尤为重要,也是第一个要遇到的问题,那要怎样解决这个问题呢?我们接下来往下看
1、和鲸社区
首先我们可以在一些数据集的网站上找一些Excel或者csv的数据
下面是我经常用到数据网站
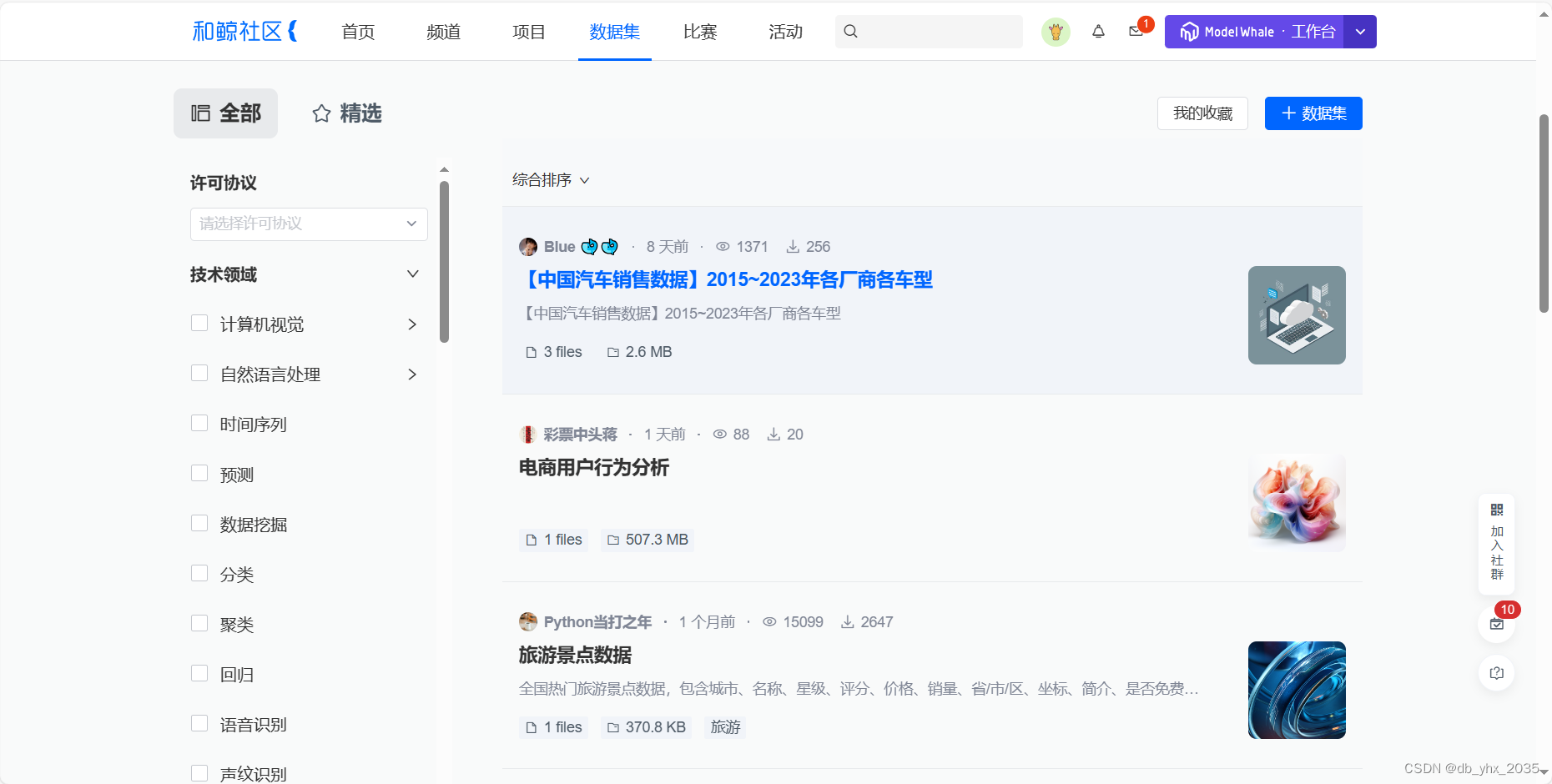
可以通过一下链接,进入和鲸社区的首页,然后点击上面的数据集,就可以每天白嫖三个数据集
二.数据转换
获得到数据集之后,会有一个让我们头疼的问题,有些项目在制作的过程中, Excel和csv文件并不适用于所有项目,在我制作spark项目中,就感觉用sql类型的数据比较方便一点,那我们应该怎么把Excel和csv文件转化为spl类型的数据呢?
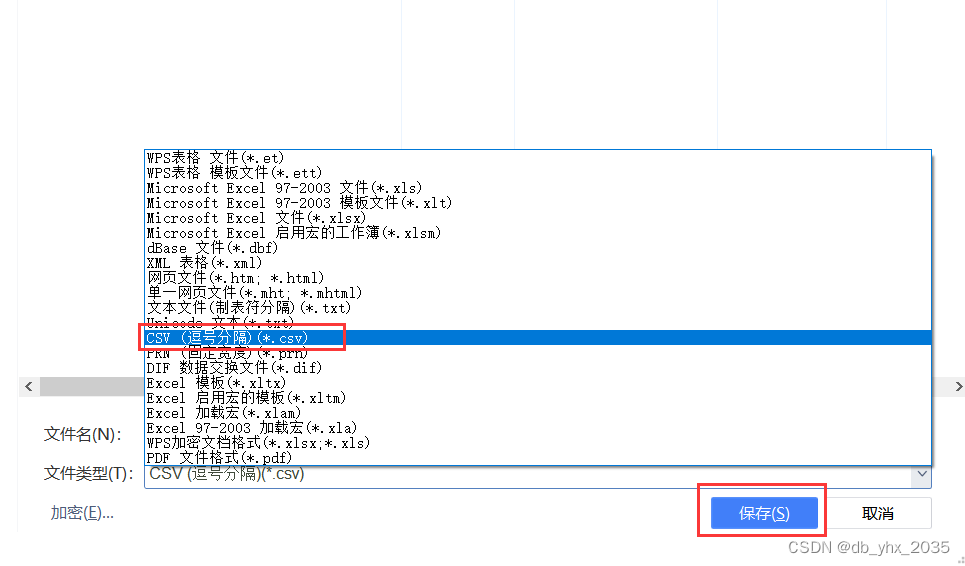
1、把文件转化为csv文件
我们可以用WPS将, Excel文件转化为csv文件
2、下载notepad++
然后我们要下载一个notepad++
这是官网,点进去下载即可
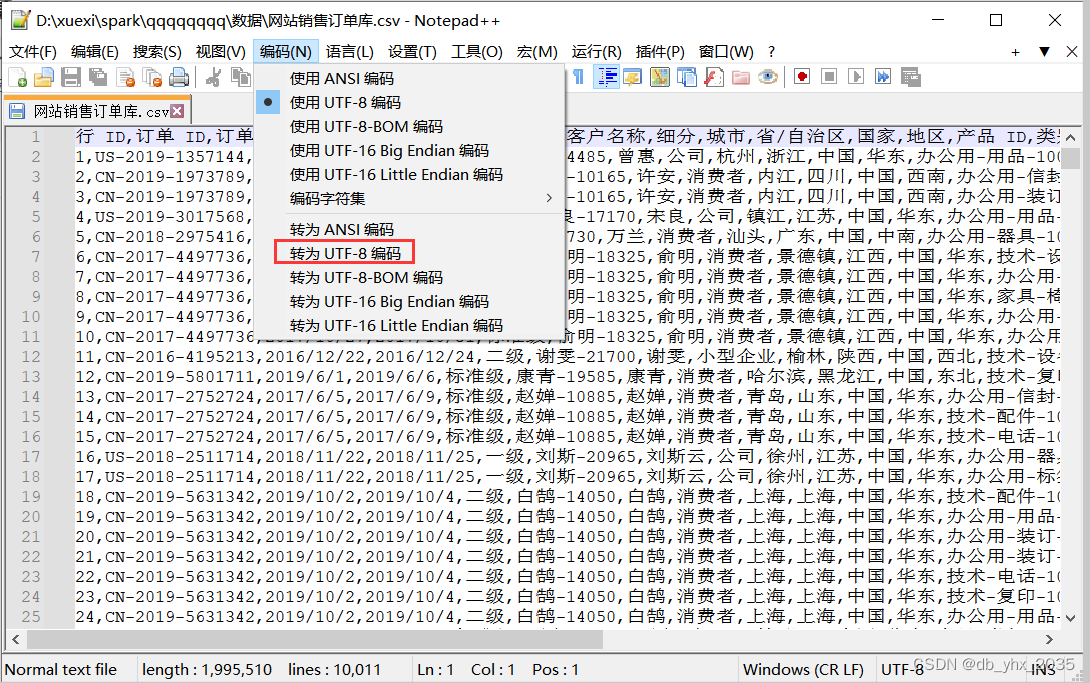
下载完成后我们打开要转化的csv文件
将数据类型转换为utf-8编码
用到navicat
然后我们要用到navicat

新建一个数据库,将转换好的csv文件导入进表中
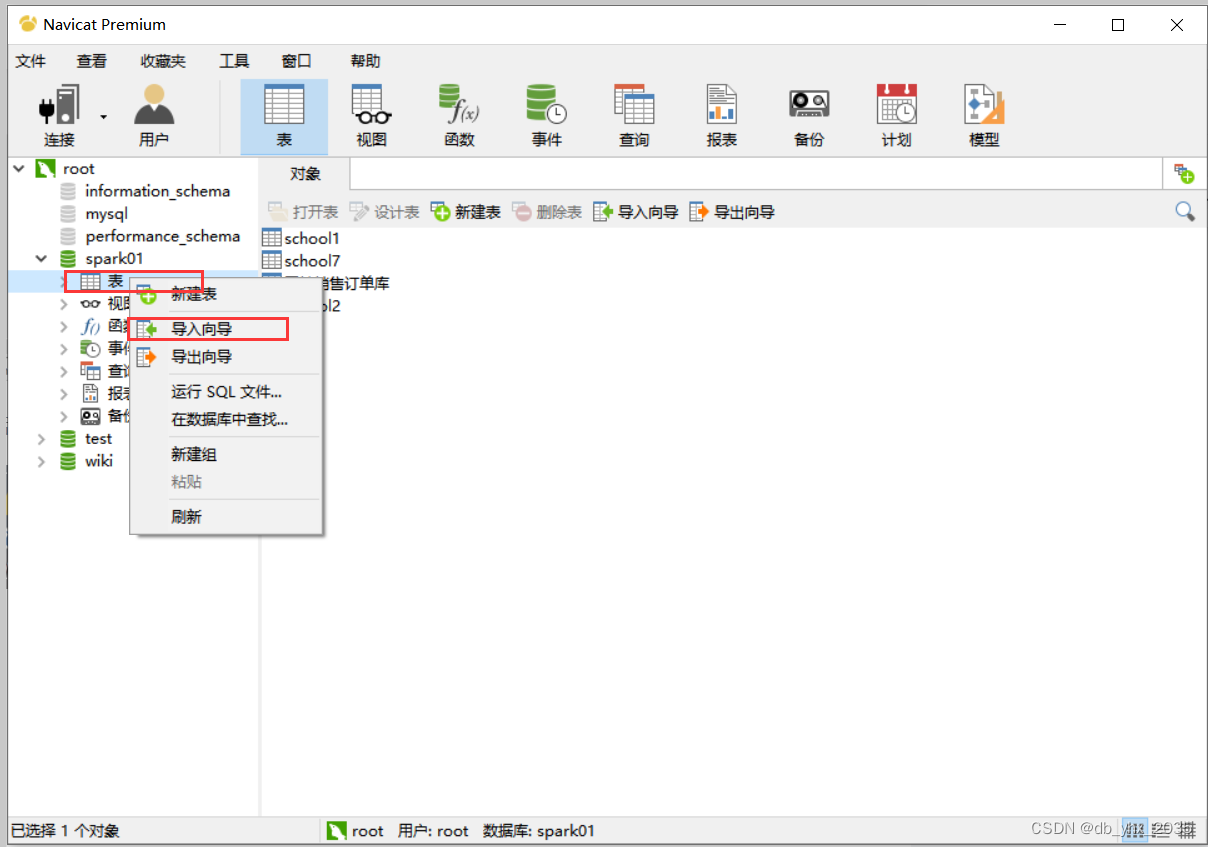
然后再将表导出
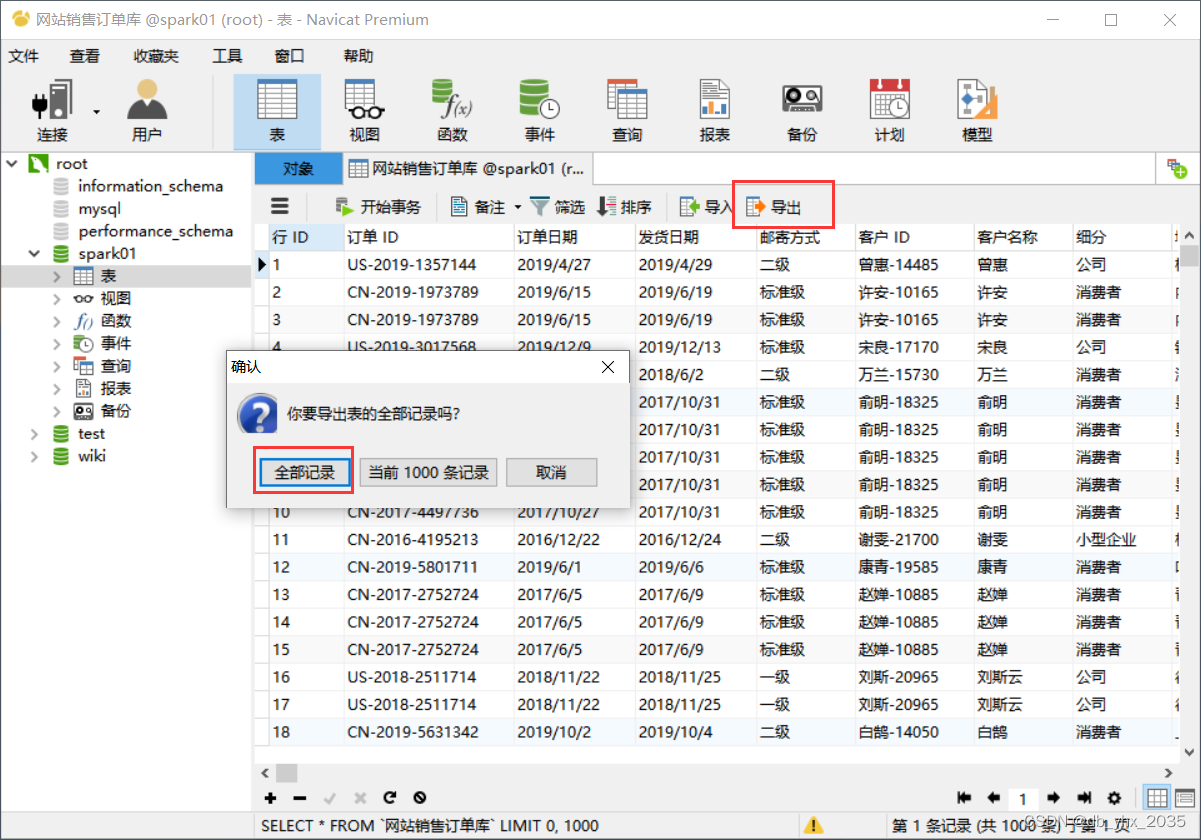
在这里我们就可以选择我们想要的数据类型了
我这里选择json文件
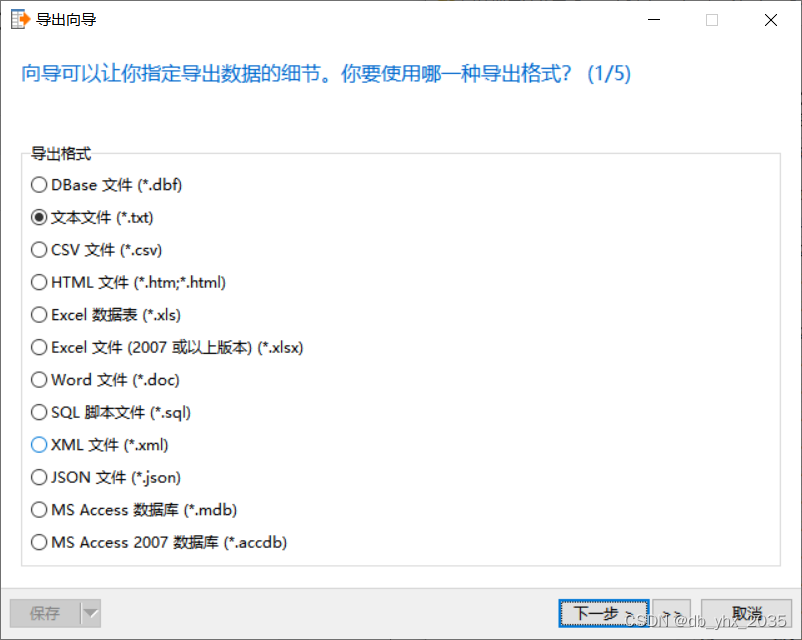
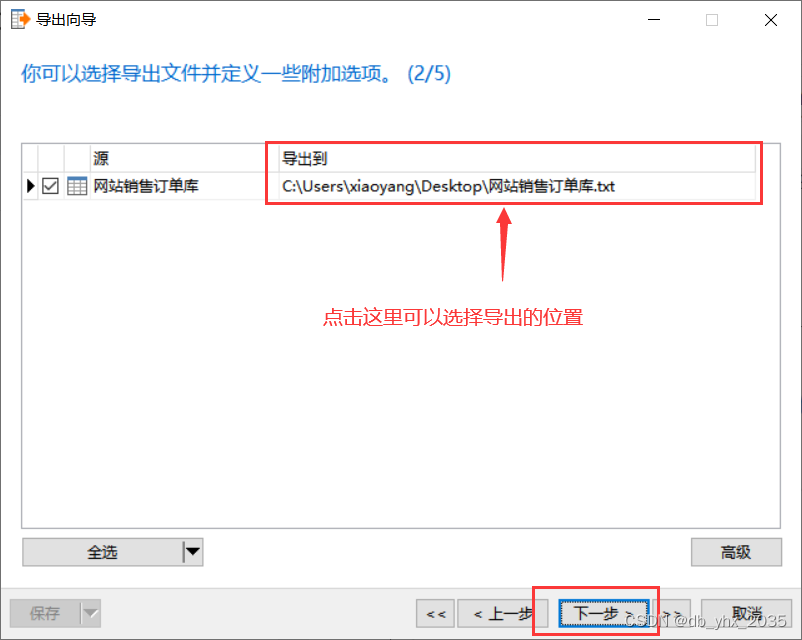
点击开始即可
发现问题
现在json类型的数据是转换出来了,但是在使用的过程中还是会出现问题
我在做项目时就报了以下的错
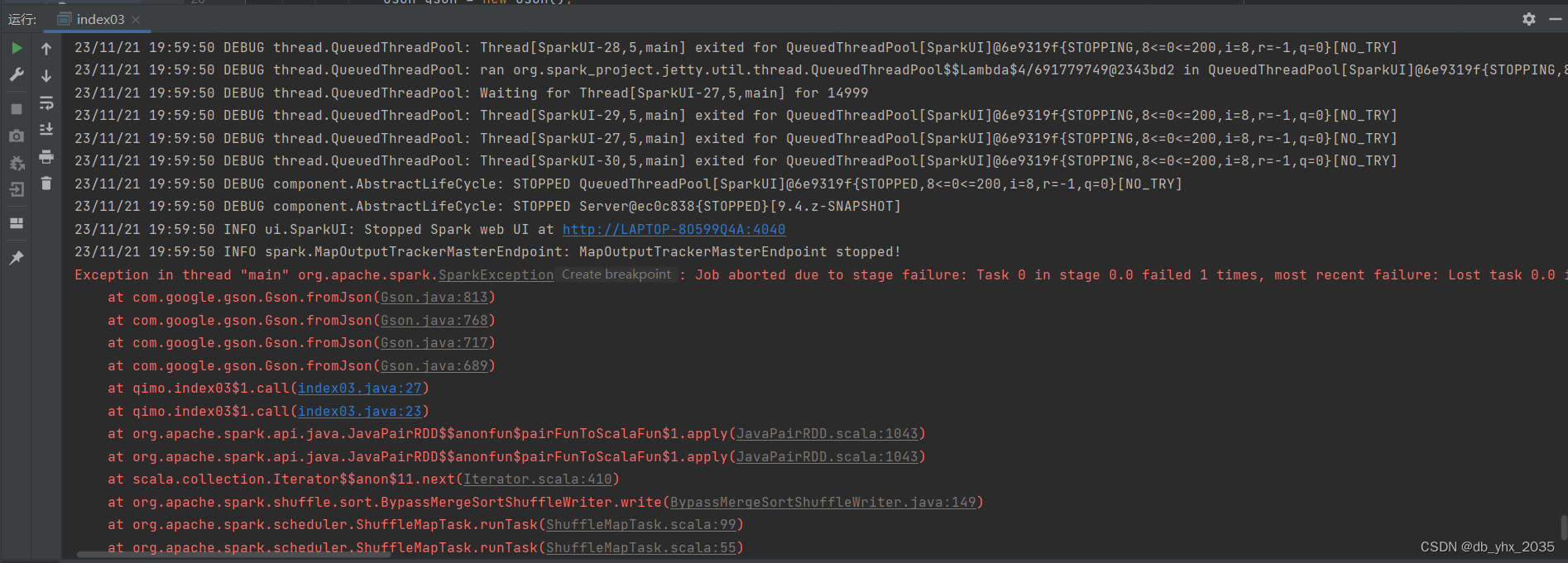
当我们仔细检查转换出来的数据之后,我们发现数据有很多的回车空行,并且每条数据他们都是用个逗号隔开,从而使我们无法使用数据
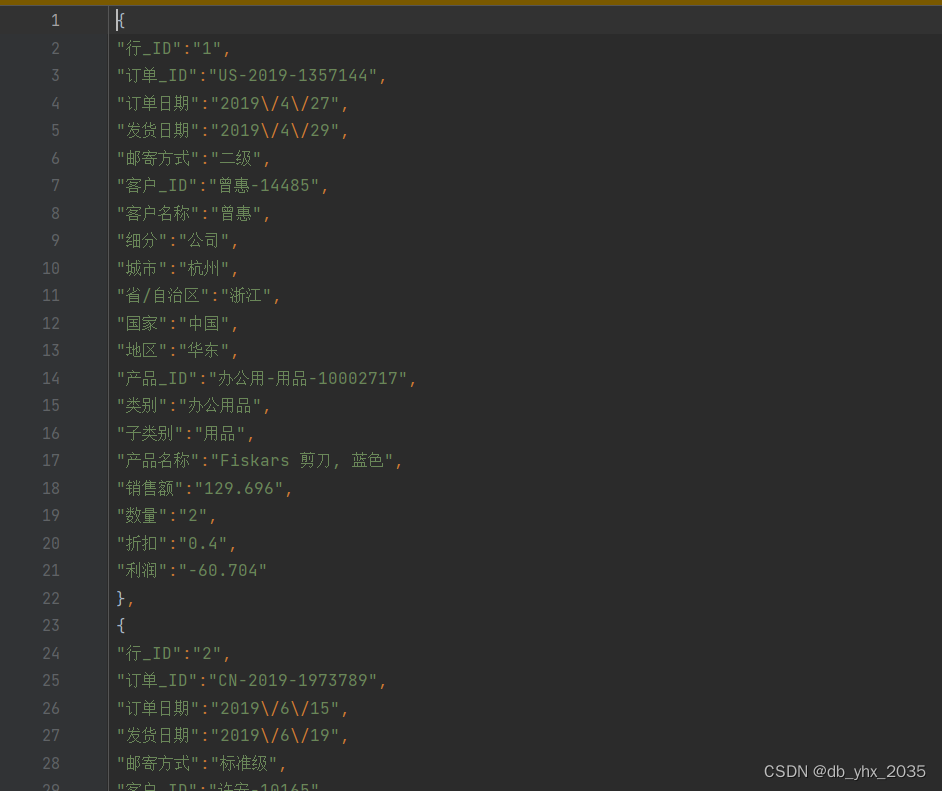
三、用word文档将数据进行整理
这时我们就可以用到 Word文档的替换功能了
我们可以将json数据集,复制粘贴到word文档中,ctrl+H
先将空格回车全部清理掉
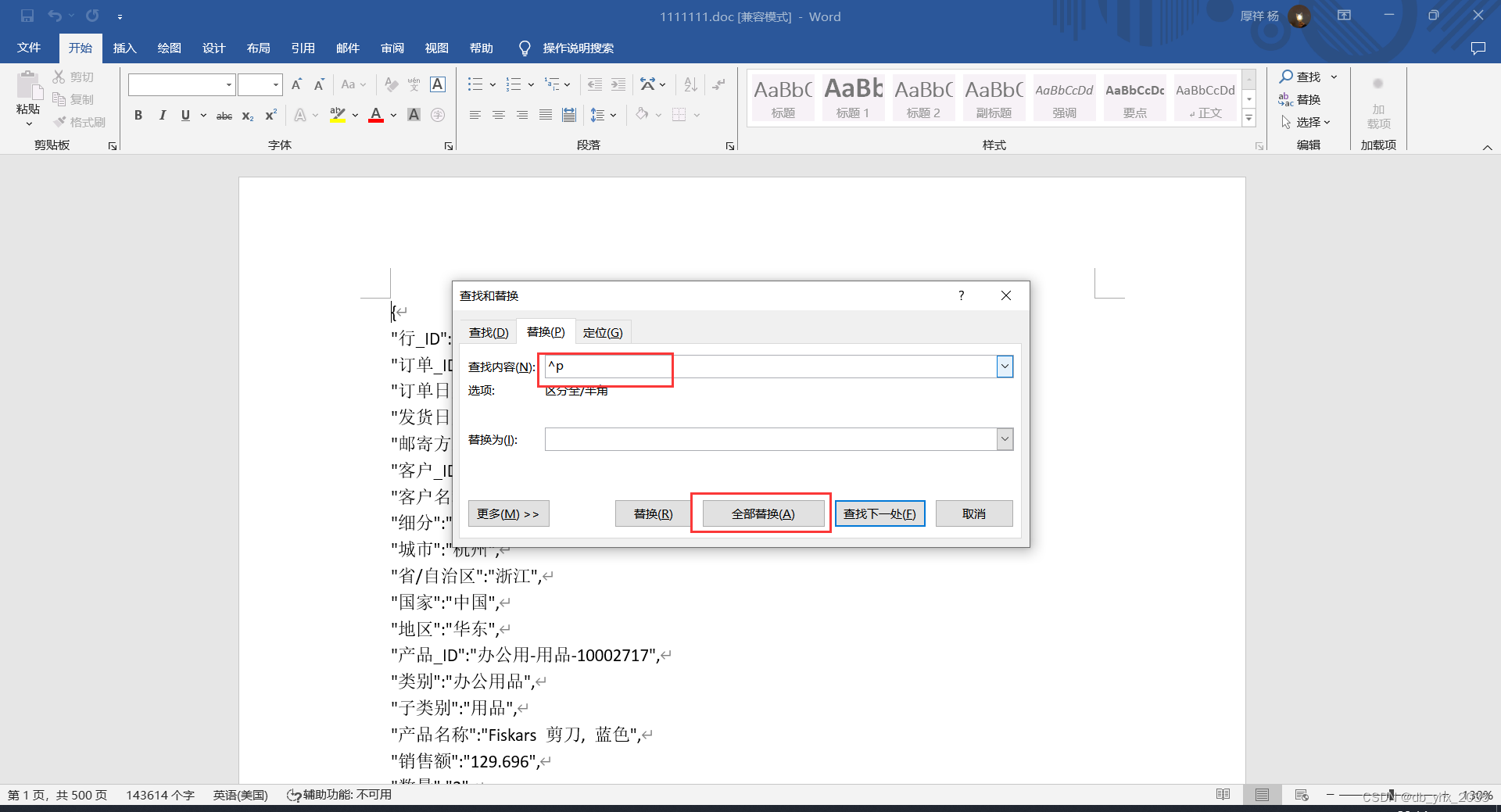
数据就变成了以下样子

这样我们的空格回车就全部清理掉了
接下来就将每一条数据后面的逗号转换为换行
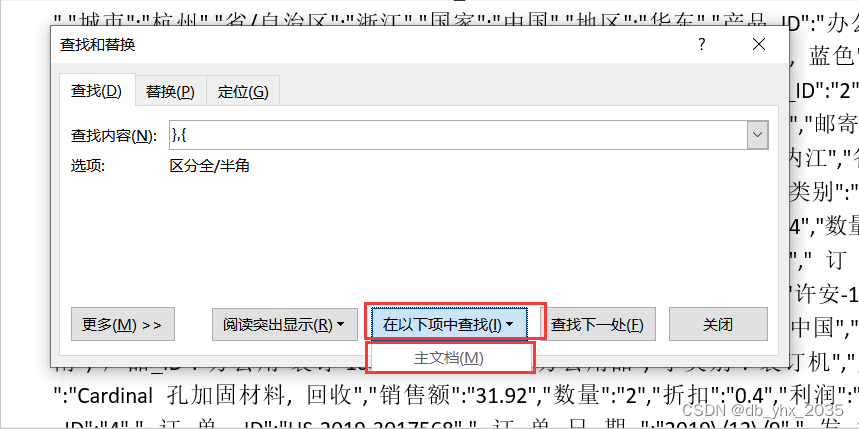
将两个括号删掉后,选择当前所选内容
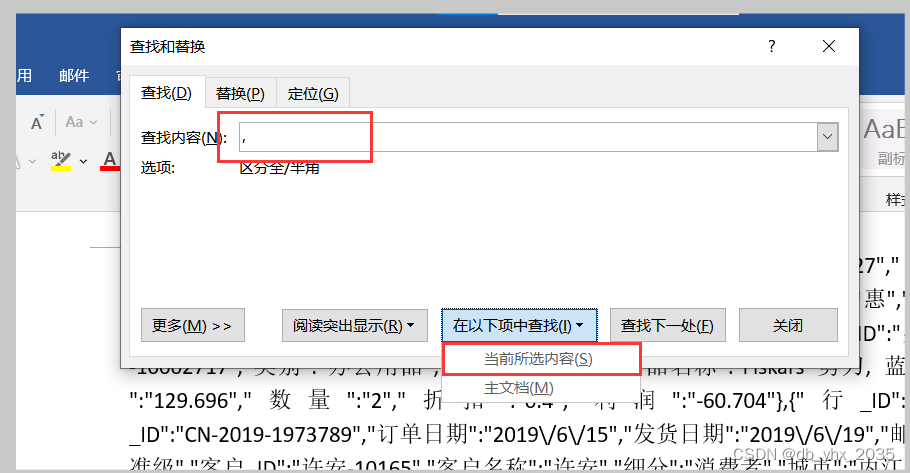
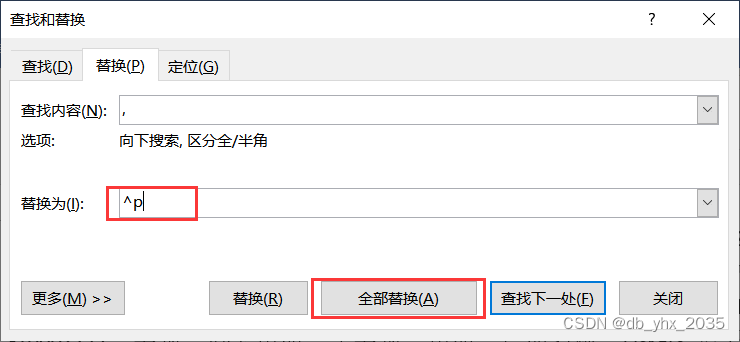
得到可使用的json文件
替换后我们的数据就变成以下内容
也是可以进行使用了
当然要将这些数据全选后,重新粘贴到json文件中

四、用例子进行演示
下面就让我们用一个例子,来验证这个数据是否可用
用spark实现统计每个地区的最高销售额
package qimo;
import com.google.gson.Gson;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.PairFunction;
import qimo.Data;
import scala.Tuple2;
import java.util.List;
import java.util.Objects;
public class index03 {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("a").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
sparkConf.set("spark.driver.host", "localhost");
// (1)读前一天的所有数据文件,得到一个RDD
JavaRDD<String> rdd = sc.textFile("D:\\xuexi\\spark\\idea\\spark02\\src\\网站销售订单库.json");
JavaPairRDD<String, Data> kvRdd = rdd.mapToPair(new PairFunction<String, String, Data>() {
@Override
public Tuple2<String, Data> call(String s) throws Exception {
Gson gson = new Gson();
Data data = gson.fromJson(s,Data.class);
return new Tuple2<>(data.get地区(),data);
}
});
JavaPairRDD<String,Iterable<Data>> g = kvRdd.groupByKey();
JavaRDD<Tuple2<String,Data>> resRdd = g.map(new Function<Tuple2<String, Iterable<Data>>, Tuple2<String, Data>>() {
@Override
public Tuple2<String, Data> call(Tuple2<String, Iterable<Data>> t) throws Exception {
Data max =null;
for (Data c : t._2){
if (Objects.isNull(max)){
max = c;
}else{
if (c.get销售额().intValue() > max.get销售额().intValue()){
max = c;
}
}
}
return new Tuple2<>(t._1,max);
}
});
List<Tuple2<String,Data>> list = resRdd.take(10);
for (Tuple2<String,Data> t : list){
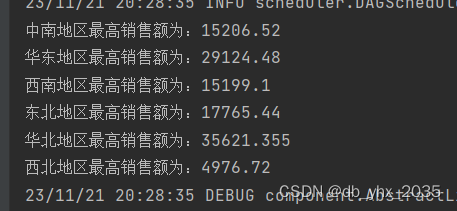
System.out.printf("%s地区最高销售额为:%s%n",t._1,t._2.get销售额());
}
sc.stop();
}
}
运行结果如下
总结
在学习编程和使用的过程中,我们总会遇到很多问题,在解决问题的过程中我们并不会感觉得到时间的流逝,在想一个问题,不知不觉时间就过去了,解决完一个问题后我们就有一种轻舟已过万重山的感觉,这就是学习编程语言的魅力,一起加油努力吧


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









