




-
研究背景:
人工智能(AI)在自动驾驶(AD)领域的感知和规划任务中展现出了超越传统方法的优越性能。然而,不透明的AI系统加剧了自动驾驶安全性保证的挑战。为了缓解这一挑战,可以利用可解释的AI(XAI)技术。本文是关于安全和可信自动驾驶中可解释方法的首次全面系统文献综述。

-
过去方案和缺点:
以往的研究主要集中在通过人类反馈的强化学习(RLHF)等方法对AI进行微调,以提高其安全性。然而,这些措施在确保足够安全性方面的有效性仍然是一个开放问题,这突显了需要进一步的方法。此外,目前没有明确的标准专门针对自动驾驶中基于数据驱动的AI的使用。现有的安全标准(如ISO 26262和ISO 21448)并未明确为数据驱动的AI系统及其独特特性制定。因此,这些标准在解决基于深度学习的系统安全要求方面面临挑战。
-
本文方案和步骤:
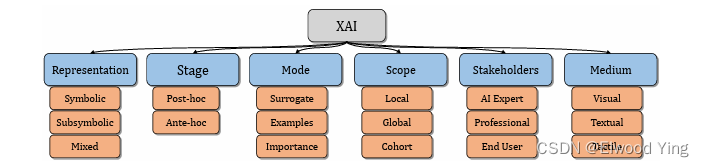
本文首先分析了自动驾驶中AI的需求,重点关注数据、模型和代理三个关键方面,并发现XAI对于满足这些需求至关重要。基于此,文章解释了AI中解释的来源,并描述了XAI的分类。然后,文章确定了XAI在安全和可信AI中的五个关键贡献,包括可解释设计、可解释替代模型、可解释监控、辅助解释和可解释验证。最后,提出了一个名为SafeX的模块化框架,以整合这些贡献,实现向用户交付解释的同时确保AI模型的安全性。 -
本文实验和性能:
本文通过系统文献综述的方法,对自动驾驶领域中的XAI技术进行了全面审视。研究者们提出了一个结构化、系统化且可复现的文献综述,重点关注环境感知、规划和预测以及控制。基于综述的方法,研究者们识别了五种应用于安全和可信自动驾驶的XAI技术范式,并讨论了每种范
阅读Explainable AI for Safe and Trustworthy Autonomous Driving: A Systematic Review
最新推荐文章于 2025-12-03 20:31:34 发布
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 372
372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









