




 本文探讨了一种针对外包训练和迁移学习的新型攻击方式——后门攻击,其中攻击者通过数据投毒在模型中植入后门,使模型在特定触发条件下产生预设错误预测。研究在MNIST手写数字识别和街道标志识别任务中进行了实验,证明后门即使在模型后续训练中也能保持有效。此外,文章还分析了模型供应链中的安全漏洞,指出预训练模型库可能成为攻击途径,并提出了安全建议,强调了模型验证和安全性的必要性。
本文探讨了一种针对外包训练和迁移学习的新型攻击方式——后门攻击,其中攻击者通过数据投毒在模型中植入后门,使模型在特定触发条件下产生预设错误预测。研究在MNIST手写数字识别和街道标志识别任务中进行了实验,证明后门即使在模型后续训练中也能保持有效。此外,文章还分析了模型供应链中的安全漏洞,指出预训练模型库可能成为攻击途径,并提出了安全建议,强调了模型验证和安全性的必要性。
摘要
在这篇文章中作者展示了外包训练过程可能会引入新风险:后门攻击。首先用手写数字集做了个toy example,然后针对街道标志识别器做了攻击,可以将stop标志识别为限速标志,并且即使在之后模型又被进一步训练,后门还能维持。
引言:
针对的场景是迁移学习和MLaaS
一种植入后门的攻击方法
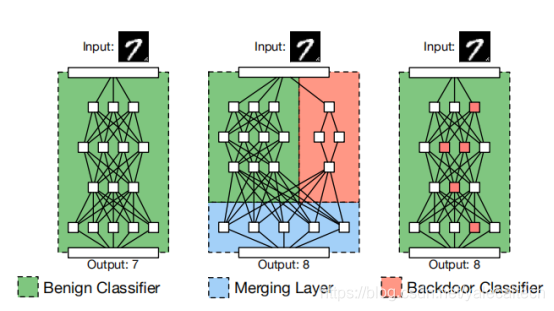
左边是正常的分类器。假设理想情况下,攻击者可以使用一个独立的网络来识别trigger,但是不会改变整个网络架构。将其与原网络结合在一起就得到了右边的植入后门后的分类器。
中间这幅图中,左边的网络用于进行分类,右边的网络用于检测是否输入中是否有trigger。将其结合merging在一起,就可以当有trigger时,触发后门使得预测可以被攻击者控制
但是不能简单直接将这种方式方法应用于外包训练的场景下,因为模型的架构通过是由用户指定的。
我们的方法是在给出训练集、trigger、和模型架构的情况下,通过训练集投毒来计算权重,通过适合的权重来实现后门效果。
背景和威胁模型:
针对外包训练和迁移学习
相关工作:
数据投毒
对抗样本
针对合作式深度学习的投毒攻击
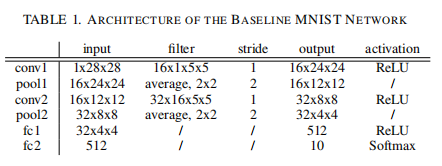
Case Study:MNST Digit Recognition Attack
使用一个CNN,架构如下
考虑两种不同的t
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1465
1465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









