 随机森林实战
随机森林实战





执行随机森林算法所涉及的基本步骤如下:
从数据集中选择N个随机记录。
根据这N条记录构建决策树。
在算法中选择所需的树数,然后重复步骤1和2。
在回归问题的情况下,对于新记录,林中的每个树都预测Y(输出)的值。 可以通过取森林中所有树木预测的所有值的平均值来计算最终值。或者,在分类问题的情况下,林中的每个树都预测新记录所属的类别。最后,新记录被分配到赢得多数投票的类别。
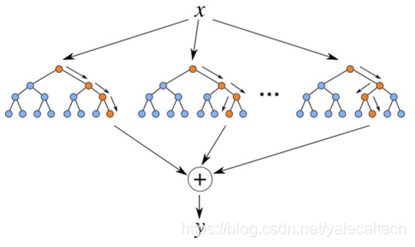
随机森林有很多优点:
随机森林的优点有:
对于很多种数据,它可以产生高准确度的分类器。
它可以处理大量的输入变量。
它可以在决定类别时,评估变量的重要性。
在建造森林时,它可以在内部对于一般化后的误差产生不偏差的估计。
它包含一个好方法可以估计丢失的数据,并且,如果有很大一部分的数据丢失,仍可以维持准确度。
它提供一个实验方法,可以去侦测variable interactions。
对于不平衡的分类数据集来说,它可以平衡误差。
它计算各例中的亲近度,对于数据挖掘、侦测离群点(outlier)和将数据可视化非常有用。
使用上述。它可被延伸应用在未标记的数据上,这类数据通常是使用非监督式聚类。也可侦测偏离者和观看数据。
学习进程是很快速的。
这次实验我们分为两部分,一部分是将随机是随机森林算法用于回归任务,一部分是将随机森林算法用于分类任务。
接下来开始我们的实验。
将随机森林算法用于回归
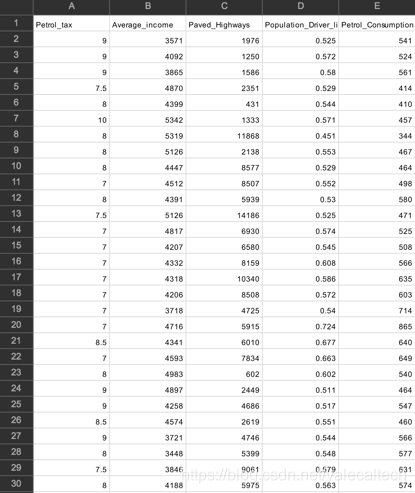
我们使用的数据集为petrol_consumption.csv,案例是:根据汽油税(以美分计),人均收入(美元),铺设公路(以英里为单位)和拥有驾照的人口比例来预测美国48个州的天然气消费量(以百万加仑计)。
数据集打开如下所示:
了解背景之后,我们开始编程吧。
第一步是导入需要用于到的库

加载数据集

准备训练用的数据,首先是将数据划分为属性集和标签集。

然后将得到的数据分成训练集和测试集。

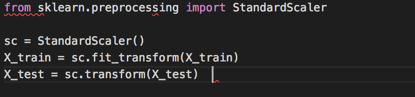
接下来我们需要缩放特征
我们在看csv数据那张图的时候,知道我们的数据集还不是缩放值例如,Average_Income字段的值范围为数千,而Petrol_tax的值范围为数十。因此我们需要缩放我们的数据。我们使用Scikit-Learn的StandardScaler类。
然后就该开始训练模型了

sklearn.ensemble库中的RandomForestRegressor类用于通过随机林解决回归问题。RandomForestRegressor类最重要的参数是n_estimators参数。此参数定义随机森林中的树的数量。我们上面的代码是设置n_estimator = 20。
最后一步是评估算法的性能。对于回归问题,用于评估算法的度量是平均绝对误差,均方误差和均方根误差。下面的代码用于给出这些值

将以上代码整合在一起(1.py)
运行后得到结果如下

在我们设置20棵树时,均方根误差为64.93。这一定范围内,通过增加树的数量,我们可以降低误差,误差设置为200颗树

结果如下

可以看到,相比于20颗树,误差确实下降了
第二个部分是将随机森林用于分类问题。数据集为bill_authentication.csv,给出了图像小波变换图像的方差、偏斜度、熵和图像的简略度,来预测纸币是否真实
同样我们还是先导入库

加载数据文件

然后准备训练用的数据
先将数据分别分为属性和标签

再将数据划分为训练集和测试集

然后缩放特征

接下来开始训练模型

在回归问题中,我们使用sklearn.ensemble库的RandomForestRegressor类。 二对于分类问题而言,我们将sklearn.ensemble库的RandomForestClassifier类。 RandomForestClassifier类也将n_estimators作为参数。与之前一样,此参数定义为随机森林中的树数。我们再次设置为20棵树。
训练之后就该评估了,对于分类问题,用于评估算法的度量是精确度,召回率和F1值等,我们打印出来即可

完整代码在2.py,结果如下所示
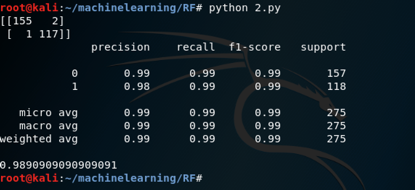
从上图可以看到,用20棵树的随机森林分类器得到的准确率为98.90%。
参考:
1.《机器学习》(西瓜书)
2.《机器学习导论》(Ethen Alpaydin)
3. https://stackabuse.com

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









