




- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
目标:
1.什么是随机森林(RF)
随机森林(Random Forest, RF)是一种由 决策树 构成的 集成算法 ,采用的是 Bagging 方法,他在很多情况下都能有不错的表现。其是由很多决策树构成的,不同决策树之间没有关联。当我们进行分类任务时,新的输入样本进入,就让森林中的每一棵决策树分别进行判断和分类,每个决策树会得到一个自己的分类结果,决策树的分类结果中哪一个分类最多,那么随机森林就会把这个结果当做最终的结果。个人理解:就是通过不维度去使用决策树去分类,每个决策树都有自己的分类结果 ,再把所有的结果进行统计,得出分类最多的那个分类就是预测的最终结果 。
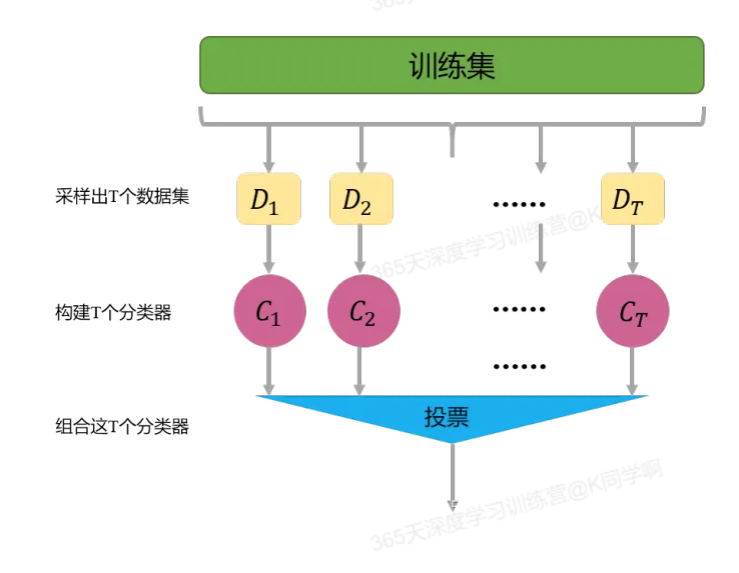
2. Bagging方法:Bagging的主要思想如下图所示,首先从数据集中采样出T个数据集,然后基于这T个数据集,每个训练出一个基分类器,再讲这些基分类器进行组合做出预测。Bagging在做预测时,对于分类任务,使用简单的投票法。对于回归任务使用简单平均法。若分类预测时出现两个类票数一样时,则随机选择一个。
3.目标:从一个天气数据集去推送天气情况
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









