




机器学习之PCA
- 关于降维算法的背景
在许多领域的研究与应用中,通常需要对含有多个变量的数据进行观测,收集大量数据后进行分析寻找规律。多变量大数据集无疑会为研究和应用提供丰富的信息,但是也在一定程度上增加了数据采集的工作量。更重要的是在很多情形下,许多变量之间可能存在相关性,从而增加了问题分析的复杂性。如果分别对每个指标进行分析,分析往往是孤立的,不能完全利用数据中的信息,因此盲目减少指标会损失很多有用的信息,从而产生错误的结论。
因此需要找到一种合理的方法,在减少需要分析的指标同时,尽量减少原指标包含信息的损失,以达到对所收集数据进行全面分析的目的。由于各变量之间存在一定的相关关系,因此可以考虑将关系紧密的变量变成尽可能少的新变量,使这些新变量是两两不相关的,那么就可以用较少的综合指标分别代表存在于各个变量中的各类信息。主成分分析与因子分析就属于这类降维算法。
。
什么是降维?
降维就是一种对高维度特征数据预处理方法。降维是将高维度的数据保留下最重要的一些特征,去除噪声和不重要的特征,从而实现提升数据处理速度的目的。在实际的生产和应用中,降维在一定的信息损失范围内,可以为我们节省大量的时间和成本。降维也成为应用非常广泛的数据预处理方法。
降维具有如下一些优点:
使得数据集更易使用。
降低算法的计算开销。
去除噪声。
使得结果容易理解。
降维的算法有很多,比如奇异值分解(SVD)、主成分分析(PCA)、因子分析(FA)、独立成分分析(ICA)。
这次我们就来学习主成分分析法PCA。
PCA(Principal Component Analysis),即主成分分析方法,是一种使用最广泛的数据降维算法。PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。PCA的工作就是从原始的空间中顺序地找一组相互正交的坐标轴,新的坐标轴的选择与数据本身是密切相关的。其中,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与第一个坐标轴正交的平面中使得方差最大的,第三个轴是与第1,2个轴正交的平面中方差最大的。依次类推,可以得到n个这样的坐标轴。通过这种方式获得的新的坐标轴,我们发现,大部分方差都包含在前面k个坐标轴中,后面的坐标轴所含的方差几乎为0。于是,我们可以忽略余下的坐标轴,只保留前面k个含有绝大部分方差的坐标轴。事实上,这相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,实现对数据特征的降维处理。
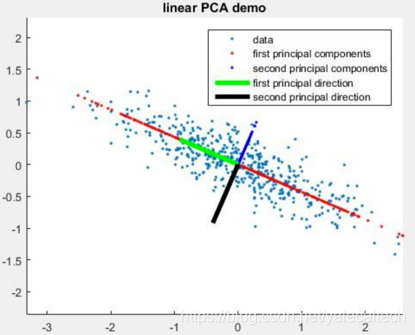
我们如何得到这些包含最大差异性的主成分方向呢?
事实上,通过计算数据矩阵的协方差矩阵,然后得到协方差矩阵的特征值特征向量,选择特征值最大(即方差最大)的k个特征所对应的特征向量组成的矩阵。这样就可以将数据矩阵转换到新的空间当中,实现数据特征的降维。
接下来我们简单地推导一下
首先的向量內积的概念,向量的内积我们在高中就已经学过,两个维数相同的向量的内积被定义为:
(a1,a2,…,an)·(b1,b2,…bn)T=a1b1+a2b2+…+anbn
这个定义很好理解,那么内积的几何意义是什么呢,我们看个图
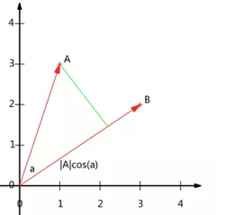
内积的另一种我们熟悉的表述方法为向量的模乘上向量之间的夹角的余弦值,即:
A·B=|A||B|cos(a)
如果我们假设B的模为1,即单位向量,那么:
A·B=|A|cos(a)
这里我们可以发现,内积其实就是A向量在B向量的方向上的投影的长度。
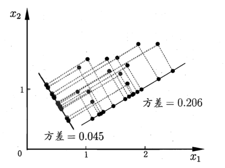
接下来我们考虑一个问题:对于空间中的所有样本点,如何找到一个超平面对所有的样本进行恰当的表达?举个例子,例如我们在二维空间内,想把数据降为一维,那么应该把样本点投影到x轴还是y轴呢?
对于这个问题,我们需要找到的超平面需满足最大可分性:样本点在这个超平面上的投影能尽可能分开,这个分开的程度我们称之为散度,散度可以采用方差或协方差来衡量(在机器学中,样本的方差较大时,对最终的结果影响会优于方差较小的样本)如图,对于方差0.2的超平面散度高于方差为0.045的超平面,因此0.2方差的超平面即为我们需要的。
这里我们再简单补充下协方差的知识:
方差是用来形容单个维度的样本的波动程度,协方差是指多个维度的样本数据的相关性,其计算公式为:
Cov(X,Y)=∑ni=1(Xi−X⎯⎯⎯⎯)(Yi−Y⎯⎯⎯⎯)(n−1)
其中Cov(X,Y)∈(−1,1)
,绝对值越大说明相关性越高。注意,协方差不等于相关系数,相关系数是协方差除标准差,相关系数的相除操作把样本的单位去除了,因此结果更加标准化一些,实际含义类似。
PCA的首要目标是让投影后的散度最大,因此我们要对所有的超平面的投影都做一次散度的计算,并找到最大散度的超平面。为了方便计算我们需要构建协方差矩阵。
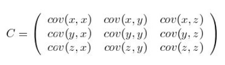
图中是一个三维的协方差矩阵,其中对角线是样本本身的协方差即方差,非对角线是不同样本之间的协方差。
注意,在PCA中,我们会对所有的数据进行中心化的操作,中心化后数据的均值为0,即:
xi=xi−1m∑i=1mxi
根据我们上文提到的协方差计算公式,我们可以得到数据样本的协方差矩阵为:
Cov(Xi)=1m∑i=1m(Xi−X⎯⎯⎯⎯i)2=1m∑i=1m(Xi)2=1m∑i=1mXi·XTi
我们设可投影的超平面为V,我们要求投影的协方差,是不是可以根据我们第一条提到的向量的内积呢?因此我们可以得到投影后的值为VT·Xi,我们把投影后的方差计算一下
S2=1m∑i=1m(VTXi−E(VTX))2
这里我们进一步的做中心化操作,因此期望值为0,所以有:
S2=1m∑i=1m(VTXi)2=1m∑i=1mVTXiXTiV=1m∑i=1mXiXTiVVT
仔细看,投影的方差即是原数据样本的协方差矩阵乘VVT。为了后续表述方便,我们设原数据样本的协方差矩阵为C,即:
S2=VTCV
到了这一步,我们获得了投影的散度的计算方法。我们再看下PCA的首要目标:让投影后的散度最大,既然是要最大化散度,那么就会涉及到我们熟悉的优化问题了,不过这里有一个限制条件,即超平面向量的模为1即:
argmax VTCVs.t.|V|=1
对于有限制条件的优化问题,我们采用拉格朗日乘子法来解决,即:
f(V,α)=VTCV−α(VVT−1)
对于求极值的问题,当然是求导啦,这里我们对V求导,即:
αfαv=2CV−2αV
我们令导数为0,即:
CV=αV
对于CV=αV
这个公式是不是很熟悉,没错就是特征值,特征向量的定义式,其中α即是特征值,V即是特征向量,这也就解释了开头提到的问题,为啥PCA是求特征值与特征向量即特征值分解。
最后我们把求出来的偏导带入到f(V,α)中,即:
f(V,α)=α
由公式可知散度的值只由α来决定,α的值越大,散度越大,也就是说我们需要找到最大的特征值与对应的特征向量。
通过上面的推导我们知道了为啥要求特征值与特征向量,那么特征向量和特征值到底有什么意义呢?
首先,我们要明确一个矩阵和一个向量相乘有什么意义?即等式左边CV的意义。矩阵和向量相乘实际上是把向量投影到矩阵的列空间,更通俗的理解就是对该向量做个旋转或伸缩变换,我们来看个例子。
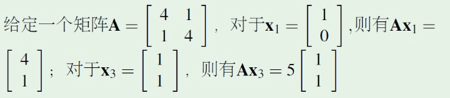
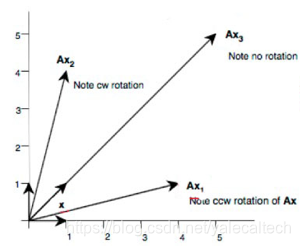
从图中我们可以发现(X3为特征向量,X1,X2为非特征向量):
一个矩阵和该矩阵的非特征向量相乘是对该向量的旋转变换,如AX1,AX2
一个矩阵和该矩阵的特征向量相乘是对该向量的伸缩变换,如AX3
再看下等式右边αV,一个标量和一个向量相乘,没错就是对一个向量的伸缩变换。
通过以上分析,我们发现,CV=αV的意思就是:特征向量在矩阵的伸缩变换下,那到底伸缩了多少倍呢?伸缩了“特征值”倍。
接下来就是我们的最后一步了,我们把所有的特征值按照降序排列,根据我们最终需要的维度d来选取前d大的特征向量,并组成一个矩阵W∗=(w1,w2,…,wd),把原始样本数据与投影矩阵做矩阵乘法,即可得到降维后的结果。对于超参数d的选择,可采用交叉验证来选择。
概括而言,PCA的流程图如下。

。
我们按照经典的机器学习流程,首先导入库和数据集,进行前期的数据分析和预处理,最后训练我们的模型,进行预测并评估准确性。 唯一额外的步骤是在我们训练模型之前执行PCA以找出k。
导入库

我们这次使用经典的iris数据集。
该数据集由150条鸢尾属记录组成,有四个特征:“萼片长度”、“萼片宽度”、“花瓣长度”和“花瓣宽度”。所有特征都是数字的。这些记录被分为三类,即“鸢尾属”、“鸢尾属”或“鸢尾属”。
导入数据集

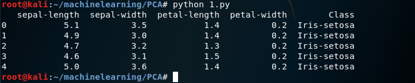
打印出一部分看看

结果如下:
接下来是预处理部分
预处理的第一步就是将数据集分成特征集及相应的标签

上面的脚本将特征集存储到X变量和将一系列相应标签存到到y变量中。
下一个步骤是将数据划分为训练和测试集

PCA在标准化后的特征集中表现最好,所以我们标准化特征集:

标准化后,我们可以应用PCA了
我们使用Python的Scikit-Learn库中的PCA类。
使用Scikit-Learn执行PCA分为两步:
通过将组件数传递给构造函数来初始化PCA类。
调用fit,然后通过transform将特征集传递给这些方法。
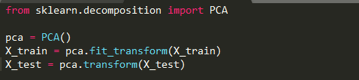
在上面的代码中,我们创建了一个名为pca的PCA对象。我们没有指定构造函数中的component的数量。因此将返回特征集中的四个特征。
PCA类包含explain_variance_ratio_,它返回由每个主成分引起的方差。
explain_variance变量是一个浮点型数组,它包含每个主成分的方差比。
加入如下代码进行打印,完整代码在2.py

结果如下
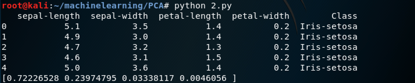
可以看出,第一主成分导致72.26%的方差。 类似地,第二主成分导致数据集中的方差为24.0%。总的来说,我们可以说特征集中包含的分类信息的(72.26 + 24.0)96.26%是由前两个主成分引起的。
我们首先尝试使用1个主成分来训练我们的算法。

接下来的过程和其他机器学习的步骤都是一样的。
先是训练和预测,我们这次使用随机森林来做预测。

评估效果
完整代码在3.py
输出如下:
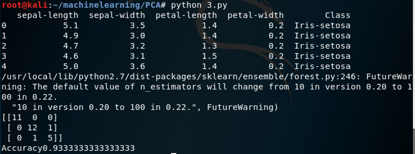
从输出中可以看出,使用一个特征的时候,随机森林算法能够正确预测30个实例中的28个,从而获得93.33%的准确率。
使用两个主成分时代码如下

上面pca的component被设置为2
修改这个参数即可,或者使用4.py
此时的归类结果如下
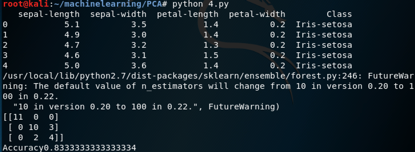
有两个主成分,分类准确度降至83.33%,而单一成分则为93.33%。
有三个主成分时,

结果如下所示:
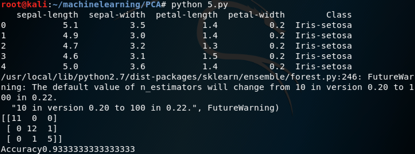
可以看到有三个主成分时,分类准确率再次提高到93.33%
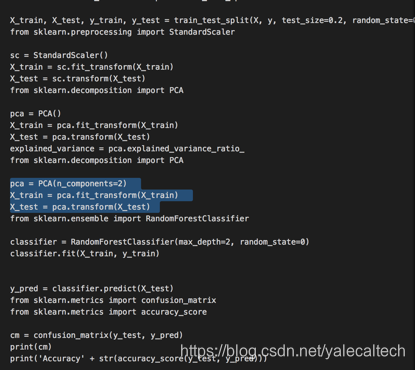
让我们尝试使用完整的特征集来看看结果如何。从我们上面编写的脚本中删除PCA部分即可,即删除下图阴影部分
具有完整特征集,而不应用PCA的结果如下所示:
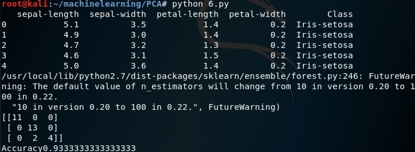
可以看到,完整特征集收到的精度是随机森林算法也是93.33%。
通过上述实验,我们在实现了最佳精度的同时显著减少了数据集中的特征数量,看到仅用1个主成分实现的精度与用全部特征集实现的精度相同,都是93.33%。 同时我们还能得出一个结论,分类器的准确性不一定随着主成分数量的增加而提高。从结果我们可以看出,一个主成分(93.33%)所达到的准确度大于两个主成分(83.33%)所达到的准确度。
参考:
- 《机器学习》(西瓜书)
- https://en.wikipedia.org/wiki/Principal_component_analysis
- https://medium.com/@chih.sheng.huang821/%E6%A9%9F%E5%99%A8-%E7%B5%B1%E8%A8%88%E5%AD%B8%E7%BF%92-%E4%B8%BB%E6%88%90%E5%88%86%E5%88%86%E6%9E%90-principle-component-analysis-pca-58229cd26e71
- https://blog.youkuaiyun.com/zhongkejingwang/article/details/42264479
- https://stackabuse.com/

















 1万+
1万+




 到【灌水乐园】发言
到【灌水乐园】发言







