






设想一下,你现在可以使用Kimi、智谱清言、Stable Diffusion、ChatGPT等大模型或者AI工具,甚至将大模型的API嵌入到你的项目中。
然而,预训练的大模型虽然强大,但不是万能的。
比如你问大模型你写的文章信息,因没有文章语料,它就无法回答。你想让大模型回答医学问题,它可能泛泛而谈。
大模型依赖于大量互联网数据进行训练,虽然覆盖面广,但在特定情境下往往无法提供精准的答案。
为此,你需要对大模型进行改造,让它更好地满足你的需求。
用于优化和增强大模型能力的方法有:提示工程、RAG、微调、更换大模型、使用多模态大模型。
简单来说,一种方法是不改变模型本身,那就优化提示词,使用外部知识库(技术是:RAG)。一种方法是改变大模型参数(技术是:微调)。
另一种方法是,换一个大模型,或者使用多模态大模型。
下面我们一一讲解。如果你想学习如何用搭建个人知识库,微调大模型,自动化工作流程等技能,可以关注我们的AI线下工作坊,扫描文末二维码,加入福利群,月中会在群里发福利券。
1. 优化提示词
当大模型的输出内容不满足你的期望时,你可以选择优化提示词,直到优化到不能优化。
 使用提示词生成答案(图来源:myscale)
使用提示词生成答案(图来源:myscale)
依据大模型的能力、特点和局限,选择合适的提示词,能够让大模型生成更符合你特定要求的输出。
例如,你想用AI批量生成小红书文案,你可以在提示词中,详细说明目标受众、语气、文章结构,引导大模型生成小红书风格的文案。
你可以设计一系列提示词模版,这样每次都可以调用。
如何优化提示词大更多内容,可以点击下面链接查看:
2. 使用外部知识库
通过检索增强生成(RAG),大模型会首先从外部知识库(比如你写的文章)中查找并收集相关信息,然后使用检索到的信息和预先存在的知识,更准确的回答问题。
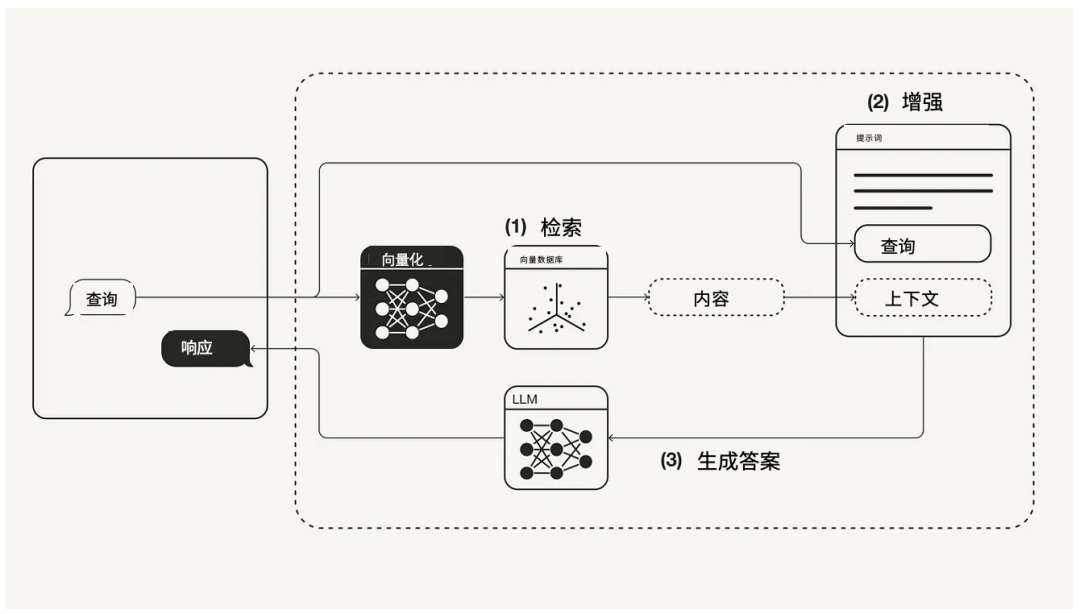
RAG工作流程(图来源:Monigatti)
RAG让模型具备特定领域的知识,从而表现得更好。
外部知识库可以是公司产品说明、教程或用户指南;客服回答的问题、聊天记录;公司政策文件、标准操作程序;你写过的文章等等。
使用何种外部知识库,取决于你的目标。
使用外部知识库,最直接的方式是在AI机器人聊天页面上传文档,开启对话。比如下图是我使用kimi解读一篇论文。(官网:kimi.moonshot.cn)。你也可以尝试扣子(官网:coze.cn)

上传某本书/文章 让kimi解读
但是这种做法也有局限。如果你不想文档泄漏,或者公司里面有成千上万个文档,你就需要借助新的工具或者运用,甚至开发专用的运用。
下图是一些常用的RAG工具,这些工具在Github上Star较多。

常见RAG工具/运用(整理:mscreate)
案例:某科技公司将RAG应用于其客户支持系统,大模型通过检索公司内部的技术文档和历史支持记录,能够在几秒钟内为客户提供精准的解决方案,大大提高了客户满意度和支持效率。
3. 微调大模型
微调是指在预训练大模型的基础上,进一步在较小的、特定领域的数据集上进行训练。
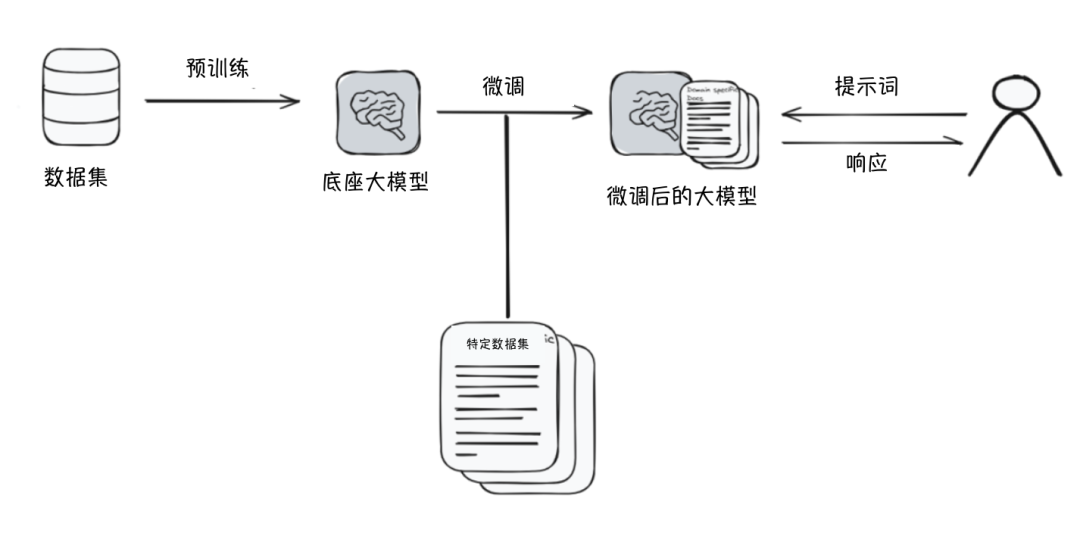
微调示意(图来源:myscale)
微调有助于让大模型更满足特定需求。
例如,你想让大模型翻译地方方言更准确,那可以使用地方方言数据集微调大模型。
与RAG不同,RAG是使用外部信息增强模型的知识,而微调则是更新模型的参数,使其更好地适应你的领域或任务。
当你拥有某个领域特定的数据时,微调特别有用。
案例:如果你想构建一个法律大模型,可以用法律文件、法律案例和合同等数据微调模型。使其在法律文件分析和合同审查中表现出色,能够快速识别潜在风险和异常条款,帮助律师更高效地完成工作。
4. 换一个大模型
除了上面的方法外,你还可以换一个模型,并非一定要拘泥于使用一个模型。
模型和模型之间能力有所差别。有些模型更擅长写出流畅的中文,有的则更擅长数据分析或者长文本处理、写代码。
不同大模型公司对大模型能力的描述
成本也有所差别。当然还有其他差别。
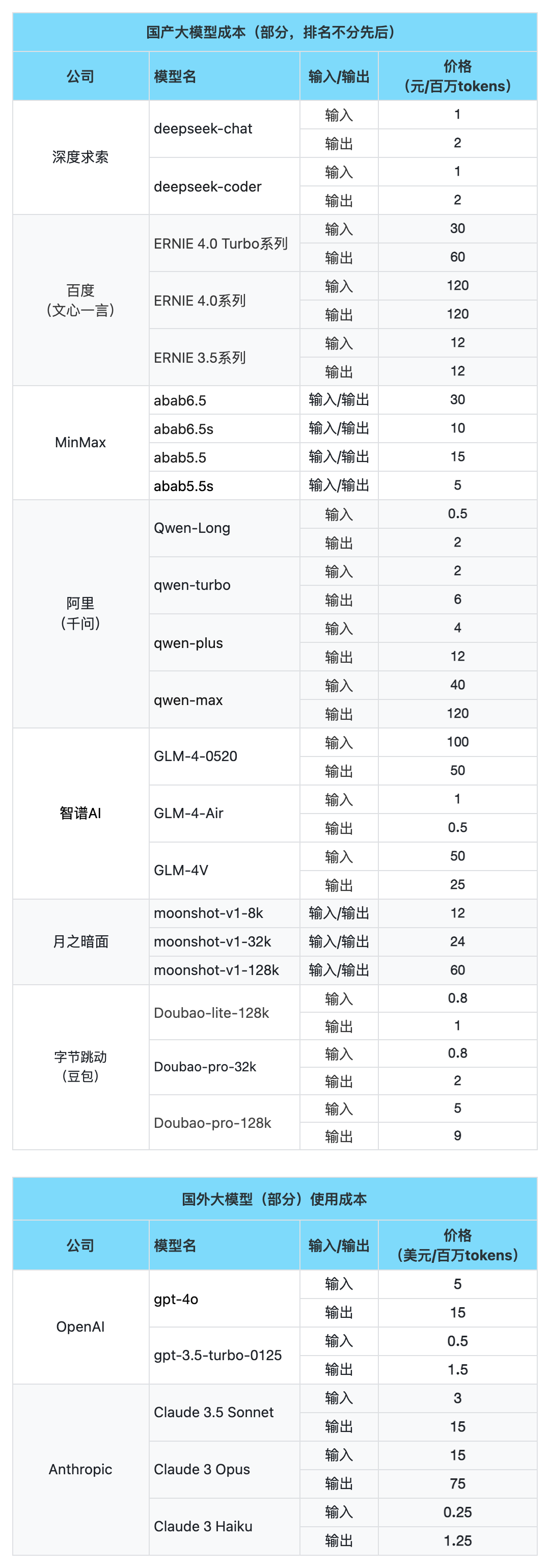
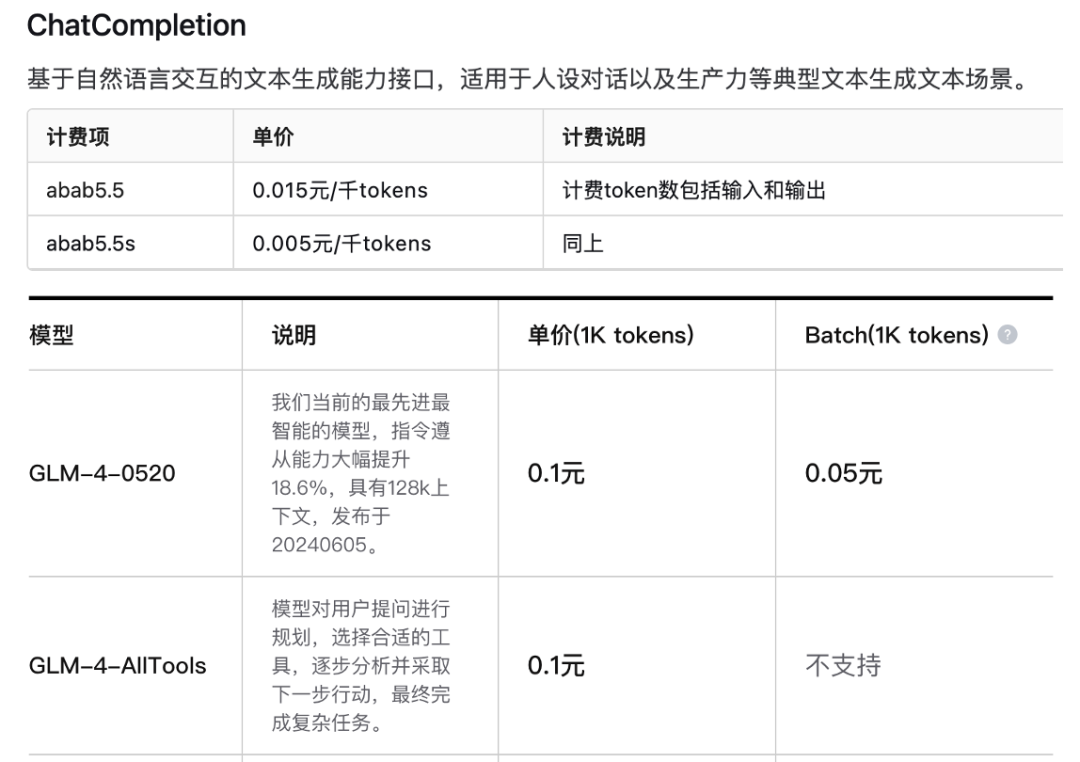
定价页面
深度求索:https://platform.deepseek.com/api-docs/zh-cn/pricing/
百度:https://cloud.baidu.com/doc/WENXINWORKSHOP/s/hlrk4akp7
MinMax:https://platform.minimaxi.com/document/price?id=6433f32294878d408fc8293e
阿里:https://help.aliyun.com/zh/model-studio/product-overview/billing-for-alibaba-cloud-model-studio?spm=5176.28515448.J_aHwmq4rbOGdcDUYyNQ3GJ.1.1ce338b1MNKJ19&scm=20140722.X_data-14ce560b9a2a78db69e3._.V_1
智谱AI:https://maas.aminer.cn/pricing
月之暗面:https://platform.moonshot.cn/docs/price/chat#%E4%BA%A7%E5%93%81%E5%AE%9A%E4%BB%B7
OpenAI:https://openai.com/api/pricing/
Anthropic:https://www.anthropic.com/pricing#anthropic-api
你可以尝试不同模型,综合效果和成本等,找到最适合的模型。
选择模型时,需要想清楚希望AI执行哪些任务?需要达到怎样的准确性、响应速度或者成本?
一旦你有了候选模型,就可以开始测试它们。
输入样本数据,评估输出结果,并将其与预设的指标进行比较。尽量尝试不同的设置、参数或微调技术,看看每个模型的反应。
例如,一家电商公司在构建推荐系统时,通过测试不同的大模型,最终选择了一个既能提供高精准推荐,又能实时响应的模型,极大地提升了用户购物体验和销售转化率。
5. 使用多模态大模型
模型不仅仅只能处理文本,还可以处理图像、音频、视频等。多模态大模型可以同时处理文本、图像等。
很多应用场景需要多模态技术支持才能实现。比如,借助多模态技术,让视力受损的人能轻松浏览网络,甚至在真实世界中充当导航。

GPT-4V展示的多模态使用例子
假设你在开发一个内容创作平台,帮助博主和营销人员制作引人入胜的文章。有了多模态大模型,用户输入提示词,AI会生成一篇精美、用吸引力的文章,还会附带相关的图片。
目前多模态大模型正在快速发展中。
最后,综合运用多种方法
真正的魔力在于结合这些方法:提示词、RAG、微调、切换模型和使用多模态大模型。
利用每种方法的优势,并将其应用于文本和图像数据,以此用大模型提升你的生产力。

















 973
973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









