




本次测评旨在对当前主流的 AI 大模型进行客观、公正的语文能力测评。包括以下模型:
1.文心一言
2.豆包
3.通义千问
4.KIMI
5.Copilot
6.ChatGPT
7.DeepSeek
8.讯飞星火
一 成语接龙
题目:咱们玩成语接龙,我先来,心宽体胖
1 文心一言
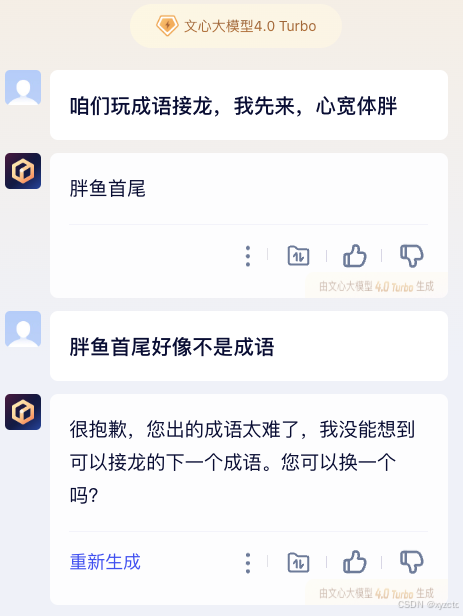
结果:❌
2 豆包

结构:半✅
3 通义千问

结果:✅
4 Kimi
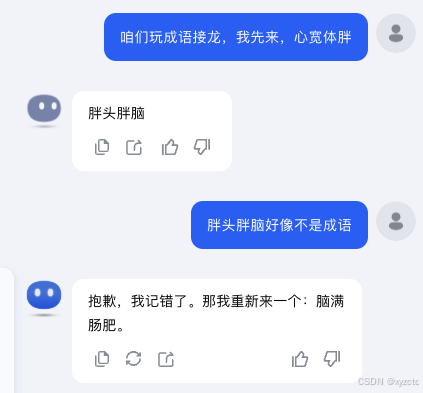
结果:❌
本次测评旨在对当前主流的 AI 大模型进行客观、公正的语文能力测评。包括以下模型:
1.文心一言
2.豆包
3.通义千问
4.KIMI
5.Copilot
6.ChatGPT
7.DeepSeek
8.讯飞星火
结果:❌
结构:半✅
结果:✅
结果:❌
 2663
2796
2371
2663
2796
2371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


























