场景文字检测和识别的关键技术
网络架构
全卷积网络 FCN
- Fully convolutional network FCN 全卷积网络,没有全连接层的网络
- FCN可以生成用于有效语义分割的特征层次结构

- 由于多尺寸学习和预测的优点,符合场景文字的本质,许多文字识别方法把FCN作为它们的骨干(backbone)网络。
- 一般来说,首先,使用 FCN 得到像素级文本/非文本 salient map(突出点映射),它产生像素级标签或包含文本的标记区域。然后,生成文本候选边框。
- 通过利用 skip architecture of FCN(全连接网络的跳跃连接结构),不同尺寸的感受野(receptive fields RF)能够同时编码文本的局部特征和文本的全局上下文信息。
ResNet
- 越深的神经网络越难训练,因为精度可能饱和并且迅速下降,参数跟新比较困难
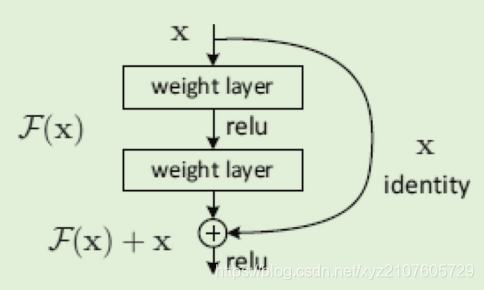
- 为了解决深层网络难训练的问题,提出了deep residual network(深度残差网络 ResNet),它的组成模块被定义为
y
=
F
(
X
,
W
i
)
+
x
y = F(X, {W_i}) + x
y=F(X,Wi)+x
- x,y分别代表输入和输出向量,
F
(
X
,
W
i
)
F(X,W_i)
F(X,Wi) 是要学习的残差映射,有些文字识别方法用ResNet做主干网络(backbone)来进行特征提取
Regions with CNN(R-CNN)
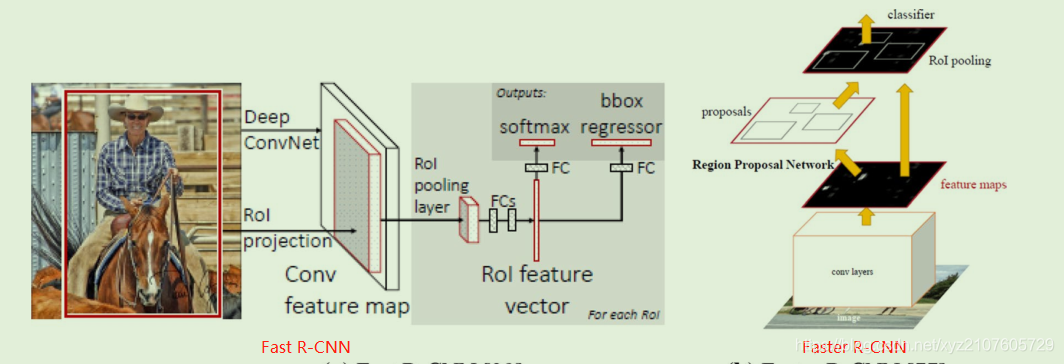
- Fast R-CNN中,输入图片和由 selective search 产生的ROI,喂给ConvNet,输出是 softmax probabilities and per-class bounding-box regression offsets
- Faster R-CNN通过共享整张图像的卷积特征的RPN(区域候选网络)产生ROI,减少了regions proposal 生成的时间,因此更 fast
- 把一些额外的组件整合到 R-CNN架构中,提出了一些计算高效额文本检测方法
You Only Look Once(Yolo)
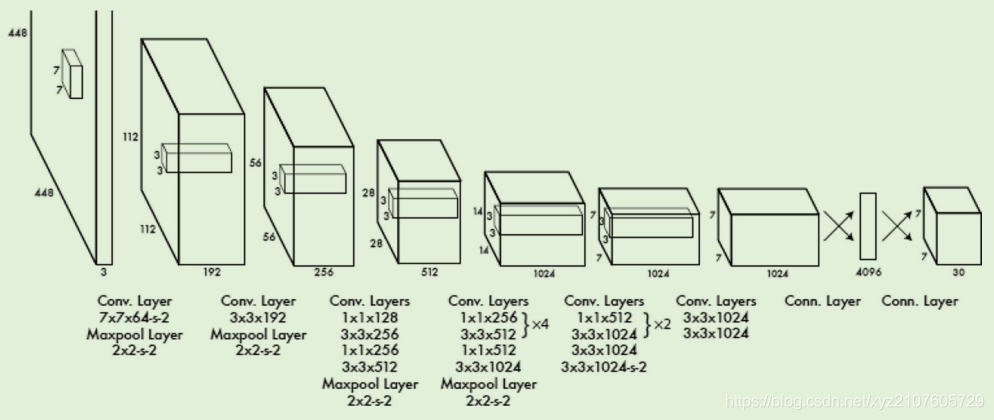
- yolo是一个单一的卷积网络,把目标检测看做回归问题,它同时预测多个边界框以及这些边界框的类别概率,准确度不高,速度很快。
- 受yolo启发,提出了FCRN用于场景文字检测。
Single shot detector(SSD)

- SSD为边界框的输出空间定义了一组默认边框,并且,它同时预测形状偏移量和对所有目标类别的置信度。
- SSD中,预测结合了不同分辨率下的多个 feature map,相对于yolo,SSD能有小弟处理多种尺寸的目标,除此之外,相比于基于R-CNN的网络,SSD消除了候选生成和特征重采样(proposal generation and feature resampling)
- 由于SSD结合了yolo和R-CNN的优点,基于SSD提出了许多文本检测的方法,如,设计有较大宽高比的默认框,多方向的默认框,采用inception-style 卷积滤波器
[1]
:https://www.researchgate.net/profile/Han_Lin11/publication/330331570_Review_of_Scene_Text_Detection_and_Recognition/links/5c39a53e458515a4c71ff2f2/Review-of-Scene-Text-Detection-and-Recognition.pdf







 本文概述了场景文字检测和识别的关键技术,包括全卷积网络FCN、ResNet、R-CNN系列以及YOLO和SSD。FCN因其多尺寸学习能力成为许多方法的骨干网络,ResNet解决了深层网络训练难题,R-CNN系列提高了目标检测效率,YOLO和SSD则提供了快速检测方案。这些技术在场景文字识别领域发挥重要作用。
本文概述了场景文字检测和识别的关键技术,包括全卷积网络FCN、ResNet、R-CNN系列以及YOLO和SSD。FCN因其多尺寸学习能力成为许多方法的骨干网络,ResNet解决了深层网络训练难题,R-CNN系列提高了目标检测效率,YOLO和SSD则提供了快速检测方案。这些技术在场景文字识别领域发挥重要作用。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









