






 文章详细介绍了GPUFermi架构,包括主机接口、GigaThreadEngine、StreamMultiprocessors(SM)和CudaCores。每个SM包含多个Core,执行SIMT模式的线程束,其中线程束由32个线程组成。CUDA编程与GPU硬件紧密相关,共享内存用于Block内的通信,线程调度策略优化了并行计算效率。
文章详细介绍了GPUFermi架构,包括主机接口、GigaThreadEngine、StreamMultiprocessors(SM)和CudaCores。每个SM包含多个Core,执行SIMT模式的线程束,其中线程束由32个线程组成。CUDA编程与GPU硬件紧密相关,共享内存用于Block内的通信,线程调度策略优化了并行计算效率。
一些参考文章:
CUDA C++ Programming Guide
NVIDIA’s Fermi the First Complete GPU Architecture
Performance Optimization: Programming Guidelines and GPU Architecture Reasons Behind Them
Nvidia GPU Architecture–Fermi架构笔记
计算机组成原理 — GPU 图形处理器
关于GPU一些笔记(SIMT方面)
NVIDIA GPU 架构梳理
CUDA编程学习笔记-02(GPU硬件架构)
查看GPU对应的计算能力
本人的配置在这:

1 GPU的硬件架构

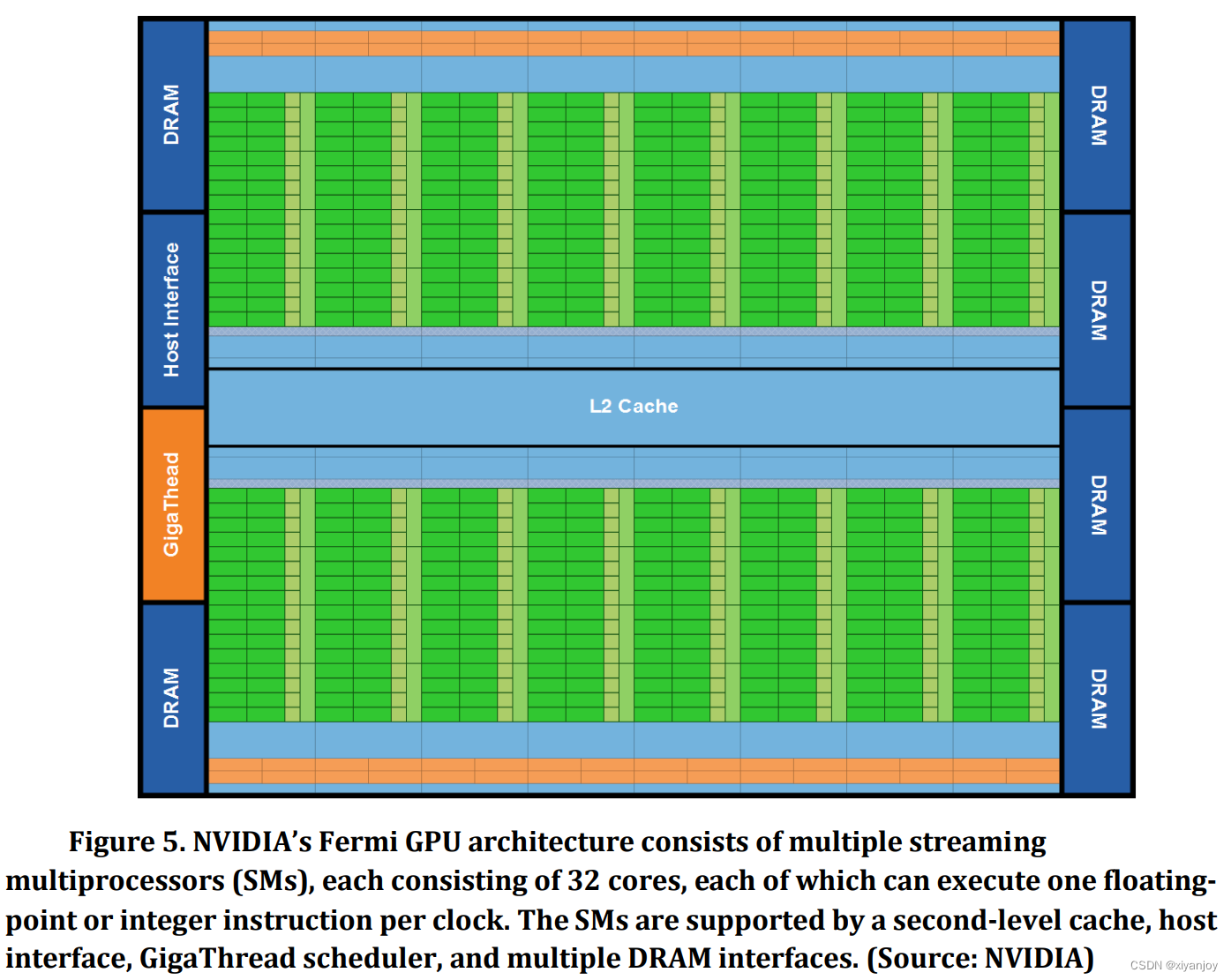

- 主机接口(host interface):通过 PCI-Express 将 GPU 连接到 CPU
- Giga Thread/Giga Thread Engine:全局调度器将线程块分发给 SM 线程调度器
This switching is managed by the chip-level GigaThread hardware thread scheduler, which manages 1,536 simultaneously active threads for each streaming multiprocessor across 16 kernels.
This centralized scheduler is another point of departure from conventional CPU design. In a multicore or multiprocessor server, no one CPU is “in charge”. All tasks, including the operating system’s kernel itself, may be run on any available CPU. This approach allows each operating system to follow a different philosophy in kernel design, from large monolithic kernels like Linux’s to the microkernel design of QNX and hybrid designs like Windows 7. But the generality of this approach is also its weakness, because it requires complex CPUs to spend time and energy performing functions that could also be handled by much simpler hardware.
With Fermi, the intended applications, principles of stream processing, and the kernel and thread model, were all known in advance so that a more efficient scheduling method could be implemented in the GigaThread engine
- SM(Stream Multiprocessor):如图中黑框以及右边的放大图所示,内有32个Core(Cuda Core)
- Core(Cuda Core):向量的运行单元,每个Core包含一个整数运算单元ALU(Integer Arithmetic Logic Unit)和一个浮点运算单元FPU(Floating Point Unit)
- Register File:寄存器文件
- SFU(Specil Function Units):特殊函数单元,超越函数和数学函数,如反平方根、正余弦等)
- Warp Scheduler:线程束调度器,将线程下方到具体的计算单元里
- Dispatch Unit:指令分发单元
- LD/ST(Load/Store):访问储存单元(负责数据处理),每周期为16个线程(因为有16个LD/ST)计算出源操作数地址和目的操作数地址。用于GMEM, SMEM, LMEM的访问
在Cuda Core前,还有一种SP(Stream Processor)流处理器的概念,其实就是Cuda Core,从Fermi架构开始,SP就改叫Cuda Core了
在后续新退出的架构中,还会有不同类型的Core并放在同一个SM中,像从Volta架构开始,就变成了INT32、FP32、Tensor Core,更好地支持并发执行。
Cuda Core的概念也慢慢淡化,取而代之的是更加细致的Core种类划分。
在后续新推出的架构中,每个SM还带有多个Tex,这是用来访问Texture和Read-only GMEM的
- Warp线程束:The warp is the fundamental unit of dispatch within a single SM(Warp是SM基本执行单元),一个Warp包含32个并行Thread(似乎目前所有GPU架构都是这个数,在内核函数中可以通过warpSize获取),这32个Thread执行于SIMT模式。也就是说所有Thread以锁步的方式执行同一条指令,但每个Thread会使用各自的Data执行指令分支。
如果在Warp中没有32个Thread需要工作,那么Warp虽然还是作为一个整体运行,但这部分Thread是处于非激活状态的。
在一个SM中,对一个Warp拆解成具体的指令,给计算单元去执行
个人理解:一个SM下面有多个Core,但一个Core并不代表一个可运行的线程,同一个SM下面的Core数量并不代表的数最多可以并行的线程数量,SM调度器只是会将下面的Core调度起来,让Core去执行指令,以便能够更加充分地利用所有Core去高效运行
一般一个线程块中的线程数量通常为线程束的整数倍,才能最大发挥硬件的性能(不绝对,存在特殊情况)
2 Cuda与GPU硬件架构的关系
图来自b站视频


这就很好解释了shared memory对应一个Block内的共享内存(通过定义一个修饰了 __shared__ 的变量来创建)
- 一个SM可以储存一个或多个Block,储存Block的数量取决于几个因素:(1)共享内存、寄存器的限制;(2)一个SM上thread、block数量的限制
- 储存在SM上的所有Block,其相关context都储存在固定的位置(注意与cpu的不同),如共享内存始终放置在共享缓存处,线程切换后也仍然放在共享内存处(因此切换线程的开销比cpu小)
- 虽然一个SM上可能会储存着多个Block,但若一个Block被调度到后,这个Block就会一直执行直到结束(而不会像cpu那样做时间片轮换)
- 一个SM一次只能调度一个(早些年的GPU)或少量(最近的GPU)的Warp(32个Thread),并基于SIMT的原理,一次同时执行一条指令
- 通过Warp的调度,隐藏延迟
关于Thread以及Block的调度能找到的相关说明确实很少,而且有些还互相冲突,因此以上内容多为自身总结,如有错误欢迎指正

















 4719
4719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









