







参见:零基础学机器学习 读书笔记。
第一章 AI与大模型时代对基础架构的需求
- 机器学习或深度学习中最常执行的运算都是基于乘加运算的向量卷积运算。
所以提高机器学习或深度学习的训练或推理效率,就是要加快向量卷积运算的速度。 - 能执行向量卷积运算的硬件设备:
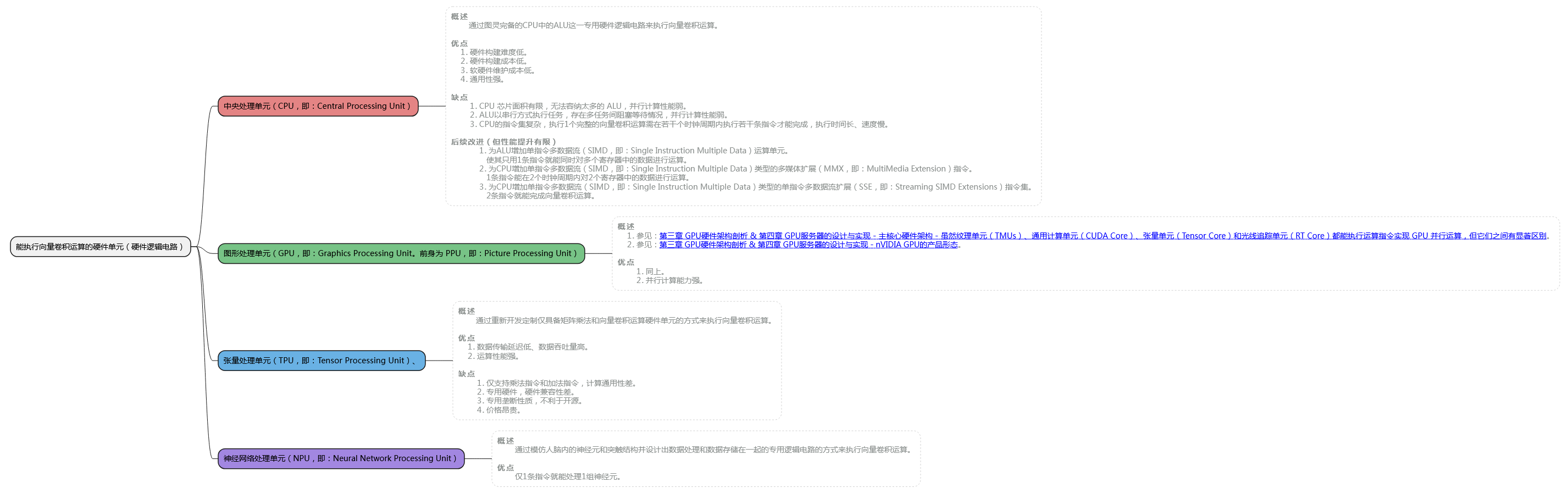
第二章 软件程序与专用硬件的结合
- 在GPU上执行运算的简要步骤:

- nVIDIA GPU的CUDA Core执行运算的简要步骤:

- 关于机器学习框架
- 产生原因:
- 提供综合、统一、便捷的框架给开发者使用。避免自己单独造各种机器学习算法的轮子。
- 单纯面向底层硬件编程,不但学习曲线陡峭、上手难度高,而且产出效率低。不利于 AI 产品的快速落地。
- 支持的训练方式:

- 产生原因:
第三章 GPU硬件架构剖析 & 第四章 GPU服务器的设计与实现 & 第五章 机器学习所依托的I/O框架体系
- nVIDIA GPU的产品形态:

- 主核心硬件架构:
以Ada Lovelace架构为例。

其中,缓存速度由快到慢依次为:- 位于流式多处理器(Stream Multiprocessor)单元每象限内的、被每象限内CUDA Core和Tensor Core共用的寄存器文件(Register File)。
- 位于流式多处理器(Stream Multiprocessor)单元每象限内的、被每象限内CUDA Core和Tensor Core共用的零级指令缓存(i-Cache,即:Instruction Cache)。
- 位于流式多处理器(Stream Multiprocessor)单元每象限内的、被所有CUDA Core和Tensor Core共用的一级数据缓存(L1 Data Cache,即:Level-1 Data Cache)。
- 位于整颗单裸片(Die)内的、被所有GPU处理集群(GPC,即:GPU Processing Cluster)共用的二级缓存(L2 Cache,即:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









