




一、概述
顶点着色器输入的主要来源是逐顶点变化的属性。属性通常用于存储位置、法线和纹理坐标等值。例如,一个顶点着色器可能会声明以下属性:
in vec3 position;
in vec3 normal;
in vec2 textureCoordinate;
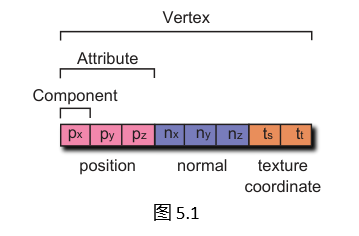
为了澄清一些术语,一个顶点由属性组成。在上面的例子中,一个顶点由位置、法线和纹理坐标属性组成。一个属性由组件组成。在上面的例子中,位置属性由三个浮点组件组成,而纹理坐标属性由两个组件组成(见图5.1)。
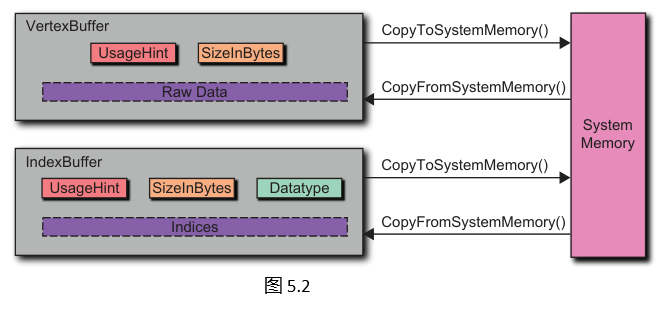
在我们的渲染器中,顶点缓冲区用于存储属性数据,而索引缓冲区用于存储用于选择顶点进行渲染的索引。这两种类型的缓冲区如图5.2所示。
二、顶点缓冲区
顶点缓冲区是原始的、无类型的缓冲区,它们将属性存储在驱动程序控制的内存中,这些内存可以是 GPU 内存、系统内存,或者两者兼具。客户端可以将数据从系统内存中的数组复制到顶点缓冲区的驱动程序控制内存中,反之亦然。在我们的示例中,最常见的操作是在 CPU 上计算位置,将其存储在数组中,然后复制到顶点缓冲区。
顶点缓冲区通过抽象类VertexBuffer 来表示,其 OpenGL 实现为 VertexBufferGL3x。创建顶点缓冲区需调用 Device::createVertexBuffer` 方法。客户端创建顶点缓冲区仅需提供两个参数:一个用于指示数据复制方式的使用提示(usage hint),以及缓冲区的字节大小。
namespace Device {
// ...
VertexBuffer* createVertexBuffer(BufferHint usageHint, size_t sizeInBytes) {
return new GL3x::VertexBufferGL3x( usageHint ,sizeInBytes ) ;
}
}
使用提示由BufferHint枚举定义,该枚举有三种值:
- StaticDraw:客户端向缓冲区复制数据一次,然后多次使用该缓冲区进行绘制。虚拟地球中的许多顶点缓冲区应使用此提示,这可能会使驱动程序将缓冲区存储在GPU内存中。例如,地形和静态矢量数据的顶点缓冲区通常会被多个帧使用,并且不会每帧都通过系统总线传输,从而显著受益。
- StreamDraw:客户端向缓冲区复制数据一次,然后最多使用该缓冲区进行几次绘制(例如,想想流式视频,其中每个视频帧只使用一次)。在虚拟地球中,此提示对于实时数据很有用。例如,可以渲染广告牌来显示美国每架商业航班的位置。如果位置更新足够频繁,则存储位置的顶点缓冲区应使用此提示。
- DynamicDraw:客户端会反复向缓冲区复制数据并使用该缓冲区进行绘制。这并不意味着整个顶点缓冲区会反复更改;客户端可能每帧只更新一部分。在前面的示例中,如果每次更新只有一部分飞机位置发生变化,则此提示很有用。
值得尝试不同的BufferHint,看看哪种最适合你的场景。请记住,这些只是传递给驱动程序的提示,尽管许多驱动程序会认真对待这些提示,因此它们会影响性能。在我们的GL渲染器实现中,BufferHint对应于传递给glBufferData的usage参数。有关如何适当设置它的更多信息,请参阅NVIDIA的白皮书[120]。
值得通过试验不同的BufferHint值,来确定哪种能在你的场景中带来最佳性能。请记住,这些只是传递给驱动程序的提示,尽管许多驱动程序会认真对待这些提示,因此它们会影响性能。在我们的GL渲染器实现中,BufferHint对应于传递给glBufferData的usage参数。有关如何适当设置它的更多信息,请参见NVIDIA的白皮书[120]。
顶点缓冲区接口(VertexBuffer):客户端代码可通过copyFromSystemMemory的模板重载方法,将标准容器(如std::vector<T>)或原始数组中的全部/部分数据复制到顶点缓冲区;通过copyToSystemMemory的模板重载方法,将顶点缓冲区中的数据复制到std::vector<T>中。
对于实现者(例如VertexBufferGL3x),只需实现纯虚接口copyFromSystemMemory(接收void*、偏移量和字节长度)和copyToSystemMemory(接收void*、偏移量和字节长度)即可。这是因为接口中的模板重载会自动将类型化数据(如std::vector<float>)转换为原始字节流,并委托给上述纯虚方法执行实际复制逻辑,无需实现者重复处理类型转换和容器适配。
这种设计通过模板实现了类型安全的接口封装,同时将平台相关的底层复制逻辑(如OpenGL的glBufferSubData调用)隔离在派生类中,既保留了C++的类型检查优势,又遵循了接口与实现分离的原则。
struct VertexBuffer {
virtual ~VertexBuffer() = default;
template <typename T>
void copyFromSystemMemory(const std::span<T>& buffer) {
copyFromSystemMemory(buffer.data(), 0, buffer.size() * sizeof(T));
}
template <typename T>
void copyFromSystemMemory(const T* buffer, size_t destinationOffsetInBytes) {
copyFromSystemMemory(buffer, destinationOffsetInBytes, ArraySizeInBytes<T>::value * buffer.size());
}
virtual void copyFromSystemMemory(const void* bufferInSystemMemory,
size_t destinationOffsetInBytes,
size_t lengthInBytes) = 0;
template <typename T>
std::vector<T> copyToSystemMemory() {
std::vector<T> result(sizeInBytes() / sizeof(T));
copyToSystemMemory(result.data(), 0, sizeInBytes());
return result;
}
template <typename T>
std::vector<T> copyToSystemMemory(size_t offsetBytes, size_t lengthBytes) {
std::vector<T> result(lengthBytes / sizeof(T));
copyToSystemMemory(result.data(), offsetBytes, lengthBytes);
return result;
}
virtual void copyToSystemMemory(void* destination, size_t offsetBytes, size_t lengthBytes) = 0;
virtual size_t sizeInBytes() const = 0;
virtual BufferHint usageHint() const = 0;
};
试试看:
添加一个包含sourceOffsetInBytes(源偏移量,以字节为单位)参数的CopyFromSystemMemory重载方法,这样复制操作就不必从数组的起始位置开始。这个重载方法在什么情况下有用呢?
顶点缓冲区可以只存储单一类型的属性(例如位置),也可以存储多种属性(例如位置和法向量)。存储多种属性时,既可以采用位置与法向量交错排列的方式,也可以先存储所有位置,再存储所有法向量。这些存储方式如图5.3所示,并将在接下来的三节中详细描述。
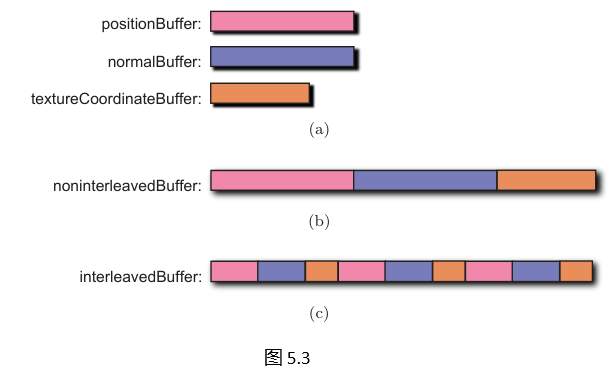
分离缓冲区
一种方法是为每种属性类型使用一个单独的顶点缓冲区,如图5.3(a)所示。例如,如果顶点着色器需要位置、法线和纹理坐标,则会创建三个不同的顶点缓冲区。位置顶点缓冲区的创建和填充代码如下:
std::vector<glm::vec3> positions = /* ... */;
size_t positionsSize = sizeof(glm::vec3) * positions.size();
VertexBuffer* positionBuffer = Device::createVertexBuffer(Device::StaticDraw, positionsSize);
positionBuffer->copyFromSystemMemory(positions.data(), positionsSize);
类似地,可以使用类似的代码将法线和纹理坐标数组复制到它们各自的顶点缓冲区。
这种方法的优点是灵活性。每个缓冲区都可以使用不同的BufferHint创建。例如,如果我们正在渲染位置经常变化的广告牌,我们可以使用StreamDraw为位置创建一个顶点缓冲区,而使用StaticDraw为不变化的纹理坐标创建一个顶点缓冲区。分离缓冲区的灵活性还允许我们在多个批次之间重用一个顶点缓冲区(例如,多个广告牌批次可以使用不同的位置顶点缓冲区,但使用相同的纹理坐标顶点缓冲区)。
非交错缓冲区
可以将所有属性存储在单个顶点缓冲区中,而非每个顶点缓冲区仅存储一种属性,如图5.3(b)所示。减少顶点缓冲区的数量有助于降低每个缓冲区的开销。
可以将顶点缓冲区视为一个原始字节数组,我们可以向其中复制任何数据。例如,位置和纹理坐标的数据类型可能不同。此时应使用带有字节偏移量参数的CopyFromSystemMemory重载方法,该偏移量用于指定在顶点缓冲区中开始复制数据的位置,从而将不同属性的数组在顶点缓冲区中拼接起来:
std::vector<glm::vec3> positions = /* ... */;
std::vector<glm::vec3> normals = /* ... */;
std::vector<glm::vec2> textureCoordinates = /* ... */;
size_t positionsSize = sizeof(glm::vec3) * positions.size();
size_t normalsSize = sizeof(glm::vec3) * normals.size();
size_t textureCoordinatesSize = sizeof(glm::vec2) * textureCoordinates.size();
size_t totalSize = positionsSize + normalsSize + textureCoordinatesSize;
std::shared_ptr<VertexBuffer> vertexBuffer = Device::createVertexBuffer(Device::StaticDraw, totalSize);
vertexBuffer->copyFromSystemMemory(positions.data(), positionsSize, 0);
vertexBuffer->copyFromSystemMemory(normals.data(), normalsSize, positionsSize);
vertexBuffer->copyFromSystemMemory(textureCoordinates.data(), textureCoordinatesSize, positionsSize + normalsSize);
尽管非交错属性只使用一个缓冲区,但由于单个顶点由多个属性组成,这些属性需要从内存的不同部分获取,因此内存一致性可能会受到影响。在实践中,我们没有使用这种方法,而是将属性交错存储在一个单独的缓冲区中。
交错缓冲区
如图5.3©所示,可以通过交错每个属性来在单个顶点缓冲区中存储多个属性。也就是说,如果缓冲区包含位置、法线和纹理坐标,则存储一个位置,然后是一个法线,接着是一个纹理坐标。这种交错模式对每个顶点重复进行。实现这一点的常见方法是将每个顶点的每个组件存储在一个结构体中,该结构体在内存中顺序排列:
struct InterleavedVertex {
glm::vec3 position;
glm::vec3 normal;
glm::vec2 textureCoordinate;
};
然后,创建这些结构体的数组:
std::vector<InterleavedVertex> vertices = {
{glm::vec3(1, 0, 0), glm::vec3(1, 0, 0), glm::vec2(0, 0)},
// ...
};
最后,创建一个与数组大小相同的顶点缓冲区(以字节为单位),并将整个数组复制到顶点缓冲区:
size_t totalSize = sizeof(InterleavedVertex) * vertices.size();
VertexBuffer* vertexBuffer = Device::createVertexBuffer(Device::StaticDraw, totalSize);
vertexBuffer->copyFromSystemMemory(vertices.data(), totalSize);
在渲染大型静态网格时,交错缓冲区的性能优于非交错缓冲区[2]。可以采用一种混合技术,既能获得交错缓冲区的性能优势,又能保留独立缓冲区的灵活性。由于在同一次绘制调用中可以读取多个顶点缓冲区,因此对于不常变化的属性,可以使用静态交错缓冲区;而对于频繁变化的属性,则可以使用动态或流式顶点缓冲区。
GL渲染器实现
我们的GL顶点缓冲区实现VertexBufferGL3x直接使用GL的缓冲区函数,目标是GL_ARRAY_BUFFER。构造函数使用glGenBuffers为缓冲区对象创建名称。当对象被销毁时,glDeleteBuffers删除缓冲区对象的名称。
构造函数还通过向 glBufferData 传递空指针为缓冲区分配内存。驱动程序的实现可能是这样的:首次调用 glBufferData 时开销不大,实际内存分配发生在第一次调用 glBufferSubData 时。或者,我们的实现也可以将 glBufferData 的调用延迟到第一次调用 copyFromSystemMemory 时,不过这需要额外的记录工作。
在调用 glBufferData 和 glBufferSubData 之前,总会先调用 glBindBuffer(以确保修改的是正确的 OpenGL 缓冲区对象)和 glBindVertexArray (0)(以确保不会意外修改 OpenGL 顶点数组)。
试试看:
不使用glBufferData和glBufferSubData更新OpenGL缓冲区对象,而是通过glMapBuffer或glMapBufferRange将缓冲区(或其一部分)映射到应用程序的地址空间。之后就可以像操作其他内存一样,通过指针修改该缓冲区。为渲染器添加这一功能。这种方法有什么优势?使用C#等托管语言会带来哪些挑战?
三、索引缓冲区
索引缓冲区由抽象类IndexBuffer表示,其GL实现为IndexBufferGL3x。接口和实现与顶点缓冲区几乎完全相同。客户端代码通常看起来类似,例如以下示例,它将一个三角形的索引复制到新创建的索引缓冲区中:
std::vector<uint16_t> indices = {0, 1, 2};
IndexBuffer* indexBuffer = Device::createIndexBuffer(Device::BufferHint::StaticDraw, indices.size() * sizeof(uint16_t));
indexBuffer->copyFromSystemMemory(indices.data());
与顶点缓冲区不同,索引缓冲区是完全类型的。索引可以是无符号短整型(unsigned short)或无符号整型(unsigned int),这由IndexBufferData类型枚举定义。客户端代码不需要显式声明索引缓冲区中索引的数据类型。相反,copyFromSystemMemory的泛型参数T用于确定数据类型。
客户端应尽量使用占用最少内存的数据类型,但同时仍能完整地索引到顶点缓冲区。如果使用64K或更少的顶点,unsigned short类型的索引就足够了,否则需要使用unsigned int类型的索引。在实践中,我们没有注意到unsigned short和unsigned int之间存在性能差异,尽管在许多情况下“尺寸就是速度”,并且使用较少的内存,尤其是GPU内存,总是一种良好的实践。
Q:
渲染器的一项实用功能是将索引精简为最小的够用数据类型。这样客户端代码可以始终使用无符号整数(unsigned int),而渲染器则尽可能只分配无符号短整数(unsigned shorts)。设计并实现这一功能。在哪些情况下这种做法并不可取?
A:
该做法在静态或半静态索引数据(如模型、UI 元素)中价值显著,能以微小的一次性分析成本换取内存和带宽优化;但在动态、高频更新或超大规模索引场景中,需权衡利弊,可能更适合直接使用unsigned int以避免额外开销。
我们索引缓冲区和顶点缓冲区之间唯一的值得注意的GL实现差异是,索引缓冲区使用GL_ELEMENT_ARRAY_BUFFER目标,而不是GL_ARRAY_BUFFER。
四、顶点数组
顶点缓冲区和索引缓冲区只是在驱动程序控制的内存中存储数据;它们仅仅是缓冲区。顶点数组定义了构成顶点的实际组件,这些组件从一个或多个顶点缓冲区中提取。顶点数组还引用了一个可选的索引缓冲区,该缓冲区对这些顶点缓冲区进行索引。顶点数组由抽象类VertexArray表示:
class VertexArray {
public:
virtual ~VertexArray() = default;
virtual VertexBufferAttributes* getAttributes() const {
return nullptr;
};
virtual void setAttribute(VertexBufferAttributes& va) = 0;
virtual IndexBuffer* getIndexBuffer() const {
return nullptr;
}
virtual void setIndexBuffer(IndexBuffer& indexBuffer) = 0;
// ...
};
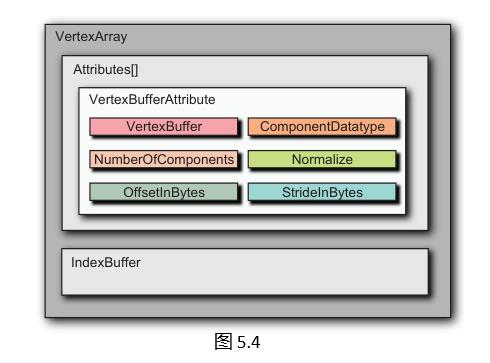
顶点数组中的每个属性由VertexBufferAttribute定义:
enum class ComponentDatatype {
Byte,
UnsignedByte,
Short,
UnsignedShort,
Int,
UnsignedInt,
Float,
HalfFloat
};
class VertexBufferAttribute {
public:
// 构造器 ......
VertexBuffer* getVertexBuffer();
ComponentDatatype getComponentDatatype();
int getNumberOfComponents();
bool getNormalize();
int getOffsetInBytes();
int getStrideInBytes();
// ...
};
属性通过一个基于零的索引访问,该索引对应于着色器的属性位置。每个顶点数组支持多达Device::MaximumNumberOfVertexAttributes个属性。
属性由包含数据的顶点缓冲区、其组件的数据类型(ComponentDatatype)以及组件的数量定义。与仅支持无符号短整型和无符号整型的索引不同,顶点组件支持这些有符号和无符号的整数类型,以及字节、浮点数和半浮点数。后者对于节省内存很有用,尤其是在与浮点数相比,用于范围在[0, 1]内的纹理坐标的内存。
如果每个属性类型都存储在单独的顶点缓冲区中,创建引用每个组件的顶点数组是直接的。为每个组件创建一个引用适当顶点缓冲区的VertexBufferAttribute,如下所示:
VertexArray* va = Context.createVertexArray();
va->attributes[0] = new VertexBufferAttribute(positionBuffer, ComponentDatatype::Float, 3);
va->attributes[1] = new VertexBufferAttribute(normalBuffer, ComponentDatatype::Float, 3);
va->attributes[2] = new VertexBufferAttribute(textureCoordinatesBuffer, ComponentDatatype::HalfFloat, 2);
位置和法线各由三个浮点组件组成(例如,x、y和z),而纹理坐标由两个浮点组件组成(例如,s和t)。如果一个单一的顶点缓冲区包含多种属性类型,可以使用VertexBufferAttribute的OffsetInBytes和StrideInBytes属性从顶点缓冲区的适当部分选择属性。例如,如果位置、法线和纹理坐标以非交错的方式存储在一个单一的顶点缓冲区中,可以使用OffsetInBytes属性选择从顶点缓冲区提取的起始点:
std::vector<glm::vec3> positions = /* ... */;
std::vector<glm::vec3> normals = /* ... */;
std::vector<glm::vec2> textureCoordinates = /* ... */;
size_t normalsOffset = ArraySizeInBytes::size(positions);
size_t textureCoordinatesOffset = normalsOffset + ArraySizeInBytes::size(normals);
// ...
va->attributes[0] = new VertexBufferAttribute(positionBuffer, ComponentDatatype::Float, 3);
va->attributes[1] = new VertexBufferAttribute(normalBuffer, ComponentDatatype::Float, 3, false, normalsOffset, 0);
va->attributes[2] = new VertexBufferAttribute(textureCoordinatesBuffer, ComponentDatatype::HalfFloat, 2, false, textureCoordinatesOffset, 0);
最后,如果属性在同一个顶点缓冲区中交错存储,还会使用StrideInBytes属性设置每个属性之间的步幅,因为属性不再彼此相邻:
size_t normalsOffset = SizeInBytes<glm::vec3>::Value;
size_t textureCoordinatesOffset = normalsOffset + SizeInBytes<glm::vec3>::Value;
va->attributes[0] = new VertexBufferAttribute(positionBuffer, ComponentDatatype::Float, 3, false, 0, SizeInBytes<InterleavedVertex>::Value);
va->attributes[1] = new VertexBufferAttribute(normalBuffer, ComponentDatatype::Float, 3, false, normalsOffset, SizeInBytes<InterleavedVertex>::Value);
va->attributes[2] = new VertexBufferAttribute(textureCoordinatesBuffer, ComponentDatatype::HalfFloat, 2, false, textureCoordinatesOffset, SizeInBytes<InterleavedVertex>::Value);
如前面的代码所示,DrawState有一个VertexArray成员,它为渲染提供顶点。渲染器的公共接口没有“当前绑定的顶点数组”的全局状态;相反,客户端代码为每次绘制调用提供一个顶点数组。
GL 渲染器实现
配置顶点数组的GL调用位于VertexArrayGL3x和VertexBufferAttributeGL3x中。使用glGenVertexArrays创建顶点数组的GL名称,当然,最终会使用glDeleteVertexArrays将其删除。将组件或索引缓冲区分配给顶点数组并不会立即导致任何GL调用。相反,这些调用被延迟到下一次使用该顶点数组的绘制调用,以简化状态管理[32]。当修改顶点数组时,它会被标记为脏。当进行绘制调用时,使用glBindVertexArray绑定GL顶点数组。如果它是脏的,其脏组件通过调用glDisableVertexAttribArray或调用glEnableVertexAttribArray、glBindBuffer和glVertexAttribPointer来实际修改GL顶点数组。同样,使用glBindBuffer与GL_ELEMENT_ARRAY_BUFFER的调用来清理顶点数组的索引缓冲区。
在ContextGL3x中,实际的绘制调用是通过glDrawRangeElements发出的(如果使用了索引缓冲区)或通过glDrawArrays发出的(如果没有索引缓冲区)。
五、网格
即使有了我们的渲染器抽象,创建顶点缓冲区、索引缓冲区和顶点数组仍然需要大量的工作。在许多情况下,特别是对于渲染静态网格的情况,客户端代码不应该关心要分配多少字节,如何将属性组织到一个或多个顶点缓冲区中,或者哪些顶点数组属性对应于哪些着色器属性位置。幸运的是,渲染器允许我们提高抽象层次并简化这个过程。低级的顶点和索引缓冲区对客户端是可用的,但客户端也可以在易用性比细粒度控制更重要时使用更高级别的类型。
设计一个 Mesh类,Mesh(网格)描述了几何形状。它可以表示虚拟地球的椭球面、地形瓦片、广告牌的几何形状、建筑物的模型等。Mesh类类似于VertexArray,因为它包含顶点属性和可选的索引。一个关键的区别是Mesh具有强类型的顶点属性,而渲染器的VertexBuffer需要一个VertexBufferAttribute来解释其属性。
Mesh类被定义在Scene中,因为它只是一个容器。它不直接用于渲染,它不依赖于任何渲染器类型,它在幕后不创建任何GL对象,因此它不属于Renderer。它只是包含数据。Context.createVertexArray的一个重载以网格作为输入,并根据网格创建包含顶点和索引缓冲区的顶点数组。这个createVertexArray重载只使用公开暴露的渲染器类型,因此不需要为每个支持的渲染API重写。
Mesh的另一个好处是计算几何的算法可以创建一个网格对象。这将几何计算与渲染解耦,这是有意义的;例如,计算椭球体三角形的算法不应该依赖于我们的渲染器类型。实际上,我们在项目中构建几何形状时始终使用Mesh类型。
class Mesh {
public:
Mesh();
VertexAttributeCollection& attributes();
const VertexAttributeCollection& attributes() const;
IndicesBase indices();
const IndicesBase indices() const;
void setIndices(IndicesBase& indices);
PrimitiveType primitiveType() const;
void setPrimitiveType(PrimitiveType type);
WindingOrder frontFaceWindingOrder() const;
void setFrontFaceWindingOrder(WindingOrder order);
private:
std::unique_ptr<VertexAttributeCollection> _attributes;
IndicesBase* _indices;
PrimitiveType _primitiveType;
WindingOrder _frontFaceWindingOrder;
}
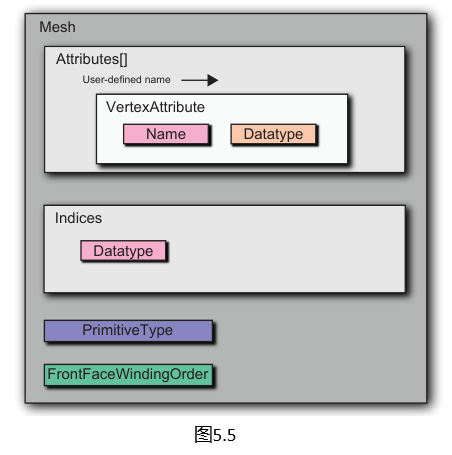
这允许客户端代码使用更高级别的网格类来描述几何形状,并让Context.createVertexArray完成顶点缓冲区布局和其他簿记工作。这个CreateVertexArray重载只使用公开暴露的渲染器类型,因此不需要为每个支持的渲染API重写。
Mesh的另一个好处是,计算几何的算法可以创建一个网格对象。这将几何计算与渲染解耦,这是有意义的;例如,计算椭球体三角形的算法不应该依赖于我们的渲染器类型。在第4章中,我们介绍了几种创建近似地球仪椭球面的网格对象的算法。实际上,我们在本书中构建几何形状时始终使用Mesh类型。
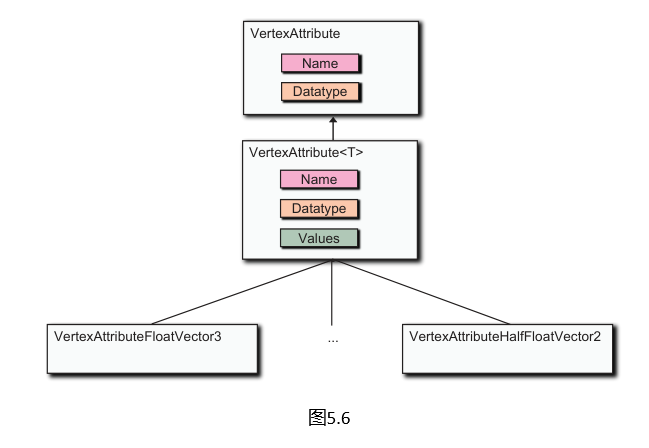
网格包含一个顶点属性集合,类似于顶点数组可以为每个属性有单独的顶点缓冲区。VertexAttributeType枚举列出了支持的数据类型。每个类型都有一个从VertexAttribute<T>和VertexAttribute继承的具体类。
enum class VertexAttributeType {
UnsignedByte,
HalfFloat,
HalfFloatVector2,
HalfFloatVector3,
HalfFloatVector4,
Float,
FloatVector2,
FloatVector3,
FloatVector4,
EmulatedDoubleVector3
}
class VertexAttribute {
public:
VertexAttribute(std::string name, VertexAttributeType type) : _name(std::move(name)), _type(type) {}
virtual ~VertexAttribute() = default;
const std::string& name() const { return _name; }
VertexAttributeType datatype() const { return _type; }
private:
std::string _name;
VertexAttributeType _type;
};
template <typename T>
class VertexAttributeT : public VertexAttribute {
public:
VertexAttributeT(std::string name, VertexAttributeType type)
: VertexAttribute(std::move(name), type), _values() {}
VertexAttributeT(std::string name, VertexAttributeType type, size_t capacity)
: VertexAttribute(std::move(name), type), _values(capacity) {}
std::vector<T>& values() { return _values; }
const std::vector<T>& values() const { return _values; }
private:
std::vector<T> _values;
};
每个属性都有一个用户定义的名称(例如,“position”、“normal”)及其数据类型。具体属性类有一个强类型的Values集合,其中包含实际的属性。这允许客户端代码创建一个强类型的集合(例如,VertexAttributeFloatVector3),填充它,然后将其添加到网格中。然后,Context.createVertexArray可以使用其datatype成员检查属性的类型,并将其强制转换为适当的具体类。这与前面章节中用于统一变量的类层次结构设计非常相似,如图 5.6。
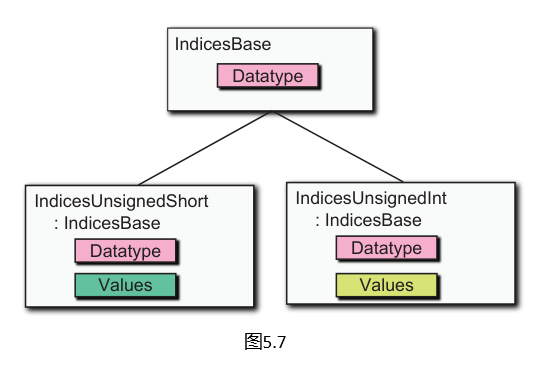
网格的索引处理方式与顶点属性类似,不同之处在于:一个网格仅包含一个索引集合,而非多个索引集合。如图5.7所示,支持两种不同的索引数据类型:无符号短整型和无符号整型。同样,客户端代码可以创建所需的特定类型的索引(例如,IndicesUnsignedShort),Context.createVertexArray将使用基类的datatype属性将其强制转换为正确类型并创建适当的索引缓冲区。
enum class IndicesType {
UnsignedShort,
UnsignedInt
};
class IndicesBase {
protected:
IndicesBase(IndicesType type) : _type(type) {}
public:
IndicesType dataType() const { return _type; }
virtual ~IndicesBase() = default;
private:
IndicesType _type;
};
template <typename T, IndicesType Type>
class Indices : public IndicesBase {
public:
Indices() : IndicesBase(Type), _values() {}
Indices(int capacity) : IndicesBase(Type), _values(capacity) {}
std::vector<T>& values() { return _values; }
const std::vector<T>& values() const { return _values; }
void addTriangle(const TriangleIndices<T>& triangle) {
_values.push_back(triangle.UI0());
_values.push_back(triangle.UI1());
_values.push_back(triangle.UI2());
}
void addTriangle(int ui0, int ui1, int ui2) {
_values.push_back(ui0);
_values.push_back(ui1);
_values.push_back(ui2);
}
private:
std::vector<T> _values;
};
using IndicesUnsignedShort = Indices<unsigned short, IndicesType::UnsignedShort>;
using IndicesUnsignedInt = Indices<unsigned int, IndicesType::UnsignedInt>;
使用Mesh和context.CreateVertexArray创建包含单个三角形的顶点数组的示例客户端代码如下:
// 创建网格并设置基本属性
Mesh mesh;
mesh.primitiveType = PrimitiveType::Triangles;
mesh.frontFaceWindingOrder = WindingOrder::Counterclockwise;
// 定义顶点位置属性 (3D坐标)
auto positionsAttribute = std::make_unique<VertexAttributeFloatVector3>("position", 3);
mesh.attributes().add(positionsAttribute.get());
// 定义三角形索引 (3个顶点)
auto indices = std::make_unique<IndicesUnsignedShort>(3);
mesh.Indices() = indices.get();
// 设置顶点数据
auto& positions = positionsAttribute->values();
positions.add(glm::vec3(0, 0, 0));
positions.add(glm::vec3(1, 0, 0));
positions.add(glm::vec3(0, 0, 1));
// 设置三角形索引(使用辅助类简化代码)
indices->addTriangle(TriangleIndicesUnsignedShort(0, 1, 2));
// 创建着色器程序和顶点数组对象
std::shared_ptr<ShaderProgram> shaderProgram = Device::createShaderProgram(vs, fs);
std::shared_ptr<VertexArray> vertexArray = context::createVertexArray(
&mesh,
shaderProgram->vertexAttributes(),
BufferHint::StaticDraw
);
首先,创建了一个Mesh对象,并将其图元类型和环绕顺序分别设置为三角形和逆时针。接下来,为三个单精度3D向量顶点属性分配内存,并将这些属性被添加到网格的属性集合中。类似地,为三个无符号短整型索引分配内存并添加到网格中。然后,分配实际的顶点属性和索引值。注意使用了一个辅助类TriangleIndicesUnsignedShort,只需一行代码即可添加一个三角形的索引,而无需调用 indices.values().add· 三次。
最后,从网格创建了一个顶点数组。将着色器的属性列表传递给createVertexArray,并将其与网格的属性名称与着色器的属性名称进行匹配。
将 Mesh 及其相关类型视为系统内存中供通用应用程序使用的几何数据,而将 VertexArray 及其相关类型视为驱动程序控制的内存中供渲染使用的几何数据,这种理解方式很有帮助。不过严格来说,顶点数组并不包含几何数据,而是引用并解释顶点缓冲区和索引缓冲区。
尽管我们通常更青睐 Mesh 和 Context.CreateVertexArray 带来的便捷性,但在某些情况下,顶点缓冲区和索引缓冲区的灵活性使其值得被直接创建。特别是当多个顶点数组需要共享一个顶点缓冲区或索引缓冲区时,应当直接使用渲染器类型。
想一想:
我们实现的Context.CreateVertexArray方法为每个顶点属性创建了单独的顶点缓冲区。请实现两种变体:一种将所有属性存储在单个非交错(noninterleaved)顶点缓冲区中,另一种将属性存储在单个交错(interleaved)缓冲区中。这两种方式在性能上有何差异?
提示:
若几何体静态且渲染性能敏感,优先使用交错缓冲区。 若需要动态更新部分属性,或数据生成逻辑复杂,考虑非交错缓冲区。
参考:
- Cozi, Patrick; Ring, Kevin. 3D Engine Design for Virtual Globes. CRC Press, 2011.
注释:
[1] 一个OpenGL驱动程序也可能在系统内存中保留一份副本,以便处理D3D所称的“丢失设备”情况,即需要恢复GPU资源。
[2] Louis Bavoil.“Efficient Multifragment Effects on Graphics Processing Units.” Master’s thesis, University of Utah, 2007. Available at http://www.sci.utah.edu/∼csilva/papers/thesis/louis-bavoil-ms-thesis.pdf.

















 749
749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









