




 本文探讨了Spark Streaming在不同并发设置下executor处理Kafka分区任务的分配现象。当并发度为1时,每个executor对应一个分区;而并发度为2时,由于任务堆积和局部性超时,部分executor执行少量额外任务。分析表明,这与Spark的任务调度策略和资源释放有关。
本文探讨了Spark Streaming在不同并发设置下executor处理Kafka分区任务的分配现象。当并发度为1时,每个executor对应一个分区;而并发度为2时,由于任务堆积和局部性超时,部分executor执行少量额外任务。分析表明,这与Spark的任务调度策略和资源释放有关。
1. 关于spark.streaming.concurrent.job参数的问题
1)当参数环境:6个executor,kafka topic 有3个partition,spark.streaming.concurrent.job=1 时
则:只有3个exevutor有task在跑,这个比较好理解,一个executor处理一个分区数据
2)当参数环境:6个executor,kafka topic 有3个partition,spark.streaming.concurrent.job=2 时
则:有3个exevutor有大量(五位数)task在执行,另3个executor会有少量(两位数)task执行
为什么job并发度为2的时候,会有其他executor执行少量task?
**分析:**因为topic只有3个partition,然后每个executor只有一个core,当并行度为1时,任务调度是process local的,所以只有3个executor会分配task,当并行度为2时,当job出现堆积,则会出现一个executor上的task未执行完,就尝试分配下一个task给他,此时等待executor计算资源释放,如果在等待时间内没有释放,则会将task的执行位置修改为node local或者rack local或者any,所以有少量的task被分配到其他executor上。
以图为证:
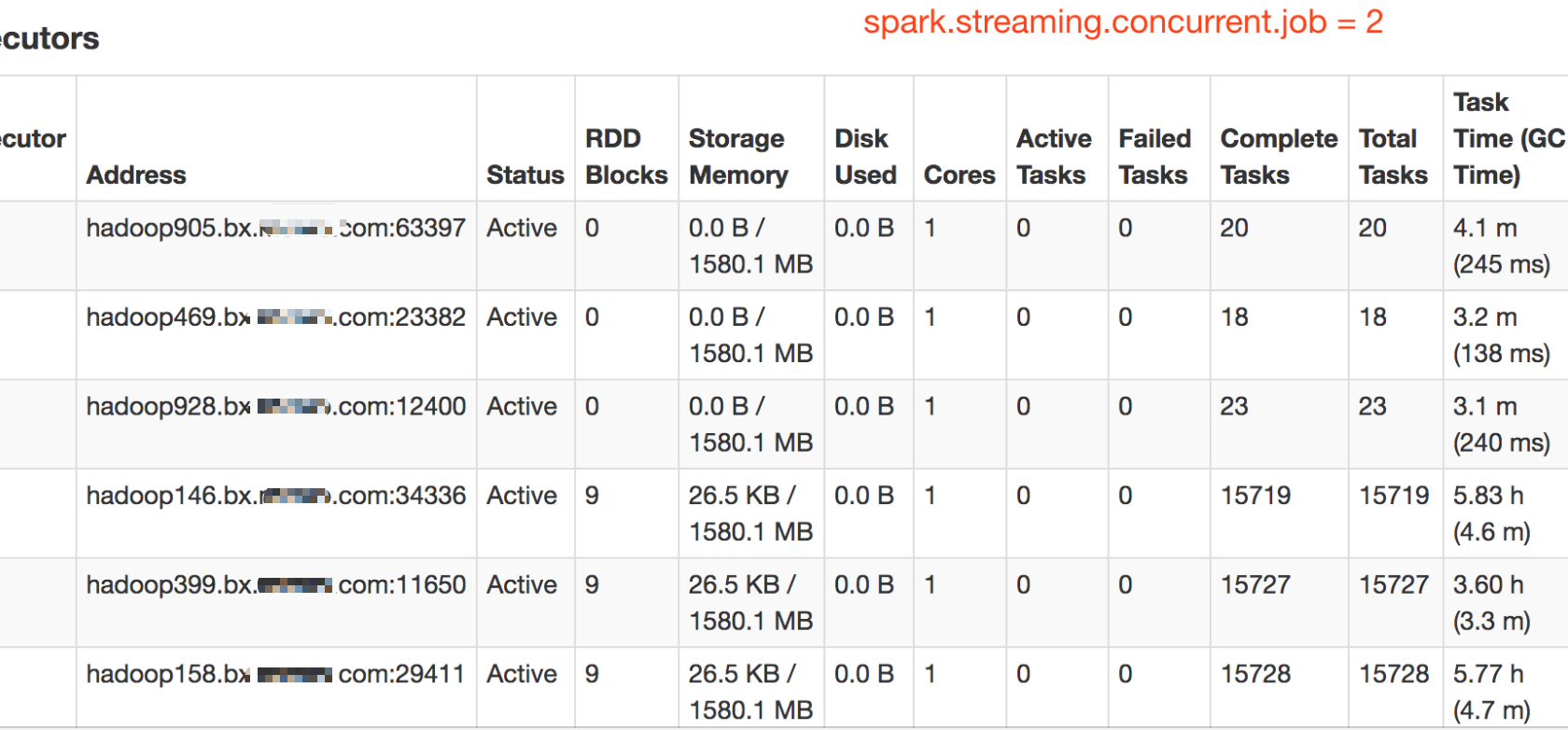
如图中所示,因为kafka topic是3个分区,有3个executor主要承担task任务,当spark.streaming.concurrent.job=2 时,机器905,469,928上会有少量task在执行。当spark.streaming.concurrent.job=1时,只有三个executor承担所有task任务。
下图为某一个数据量很大(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 761
761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









