



因为1位二进制数可以表示2种状态:0、1;而2位二进制数可以表示4种状态:00、01、10、11;依次类推,7位二进制数可以表示128种状态,每种状态都唯一地编为一个7位的二进制码,对应一个字符(或控制码),这些码可以排列成一个十进制序号0~127。所以,7位ASCII码是用七位二进制数进行编码的,可以表示128个字符,其最高位(b7)用作奇偶校验位。所谓奇偶校验,是指在代码传送过程中用来检验是否出现错误的一种方法,一般分奇校验和偶校验两种。奇校验规定:正确的代码一个字节中1的个数必须是奇数,若非奇数,则在最高位b7添1;偶校验规定:正确的代码一个字节中1的个数必须是偶数,若非偶数,则在最高位b7添1。
第0~32号及第127号(共34个)是控制字符或通讯专用字符,如控制符:LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BEL(振铃)等;
通讯专用字符:SOH(文头)、EOT(文尾)、ACK(确认)等;
第33~126号(共94个)是字符,其中第48~57号为0~9十个阿拉伯数字;65~90号为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等。

绝大多数计算机的一个字节是8位,取值范围是0~255,而ASCII码并没有规定编号为128~255的字符,为了能表示更多字符,各厂商制定了很多种ASCII码的扩展规范。注意,虽然通常把这些规范称为扩展ASCII码(Extended ASCII),但其实它们并不属于ASCII码标准。例如以下这种扩展ASCII码由IBM制定,在字符终端下被广泛采用,其中包含了很多表格边线字符用来画界面。
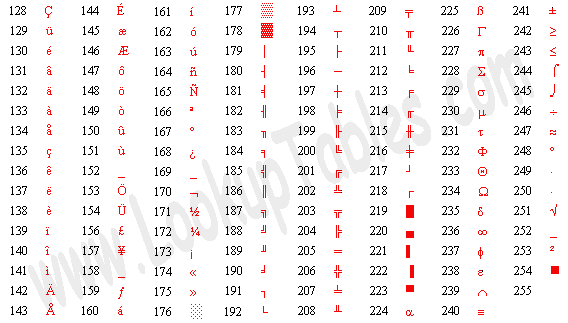
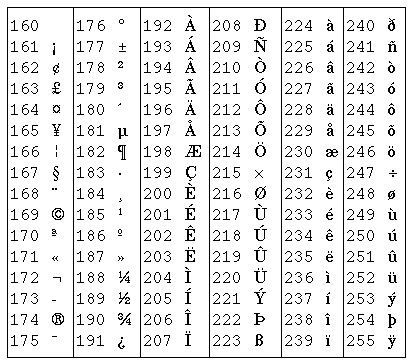
在图形界面中最广泛使用的扩展ASCII码是ISO-8859-1,也称为Latin-1,其中包含欧洲各国语言中最常用的非英文字母,但毕竟只有128个字符,某些语言中的某些字母没有包含。如下表所示(编号为128~159的是一些控制字符,表中没有列出):
在自己的DEV下调试下面这个程序:

















 1935
1935

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









