







机器学习模型通常需要数值型输入,因为大多数模型的数学基础(如矩阵运算、梯度下降等)依赖于数值计算。字符串或其他非数值型数据需要通过某种方式转换为数值型特征,以便模型能够处理。
常见预处理算法:几种常见的字符串转换为数值的方法的对比-优快云博客
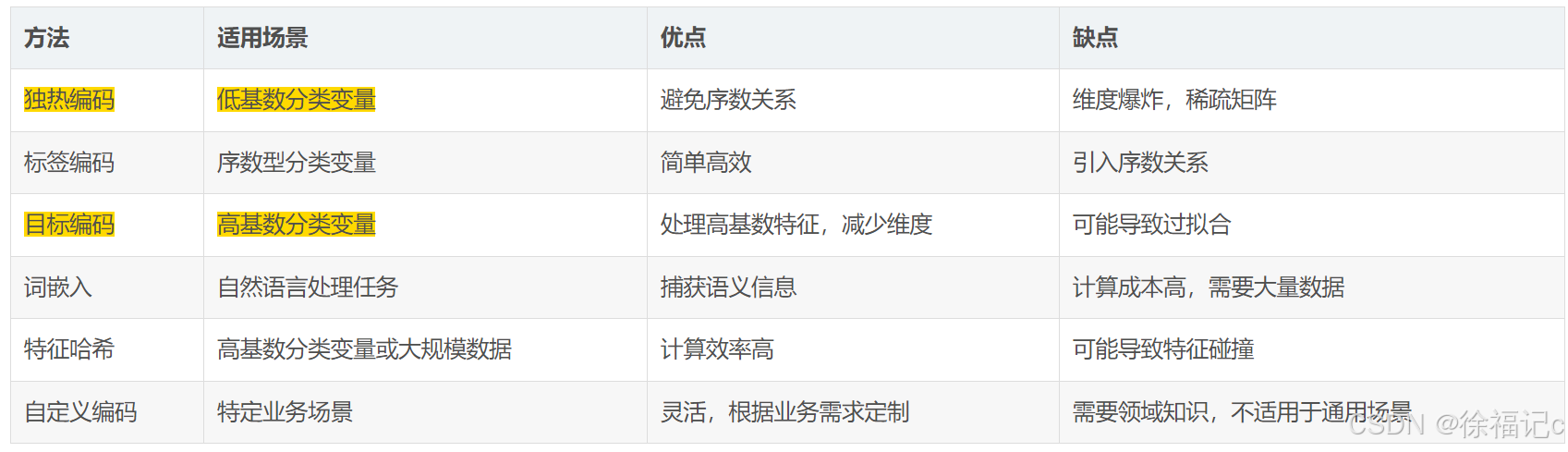
OneHotEncoder是一种常用的数据处理技术,用于将分类变量(categorical variables)转换为数值型特征(numerical features),以便机器学习模型能够处理这些数据。它通过将每个分类变量的类别(category)映射为一个二进制向量(binary vector)来实现这一点。
原理
-
分类变量:分类变量是离散的、非数值型的变量,例如颜色(红、绿、蓝)、性别(男、女)等。
- 独热编码:
OneHotEncoder将每个类别映射为一个二进制向量,其中只有一个元素为1,其余为0。例如:- 颜色类别“红”、“绿”、“蓝”会被编码为:
-
红 → [1, 0, 0]
-
绿 → [0, 1, 0]
-
蓝 → [0, 0, 1]
-
- 颜色类别“红”、“绿”、“蓝”会被编码为:
优点
-
模型兼容性:机器学习模型通常需要数值型输入,
OneHotEncoder使分类变量能够被模型处理。 -
避免序数关系:与
LabelEncoder不同,OneHotEncoder不会引入序数关系(即不会隐含地假设某个类别比其他类别“更大”或“更小”)。
缺点
-
维度爆炸:如果分类变量的类别数量很大,
OneHotEncoder会生成大量二进制特征,导致特征空间维度急剧增加。 -
稀疏性:生成的特征矩阵通常是稀疏的,可能需要额外的存储和计算资源。
应用场景
-
低基数分类变量:适用于类别数量较少的分类变量(如性别、颜色等)。
-
树模型:树模型(如决策树、随机森林)通常对独热编码的特征表现良好。
-
线性模型:线性模型(如逻辑回归、线性回归)需要数值型输入,
OneHotEncoder是常用的预处理步骤。
代码示例
以下是一个使用OneHotEncoder的代码示例:
import pandas as pd
from sklearn.preprocessing import OneHotEncoder
# 创建示例数据
data = {'颜色': ['红', '绿', '蓝', '红', '蓝'],
'尺寸': ['小', '中', '大', '中', '小']}
df = pd.DataFrame(data)
# 初始化OneHotEncoder
encoder = OneHotEncoder(sparse_output=False, handle_unknown='ignore')
# 对分类变量进行编码
encoded_data = encoder.fit_transform(df[['颜色', '尺寸']])
# 输出编码后的数据
print(encoded_data)
print(encoder.get_feature_names_out())
输出结果
[[1. 0. 0. 1. 0. 0.]
[0. 1. 0. 0. 1. 0.]
[0. 0. 1. 0. 0. 1.]
[1. 0. 0. 0. 1. 0.]
[0. 0. 1. 1. 0. 0.]]
['颜色_红', '颜色_绿', '颜色_蓝', '尺寸_小', '尺寸_中', '尺寸_大']
总结
OneHotEncoder是一种常用的数据预处理技术,用于将分类变量转换为数值型特征。它通过独热编码避免了序数关系的问题,但可能导致维度爆炸。在实际应用中,需要根据数据特性和模型需求选择合适的编码方式。

















 1157
1157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









