









 本文详细分析了Java中的Iterator接口,包括hasNext、next、remove和forEachRemaining方法。同时,介绍了Iterable接口,它是为集合类提供for-each循环支持的关键,其核心方法iterator返回一个迭代器。此外,还探讨了IteratorSpliterator,它是如何利用iterator进行操作并实现数据的分割和遍历。
本文详细分析了Java中的Iterator接口,包括hasNext、next、remove和forEachRemaining方法。同时,介绍了Iterable接口,它是为集合类提供for-each循环支持的关键,其核心方法iterator返回一个迭代器。此外,还探讨了IteratorSpliterator,它是如何利用iterator进行操作并实现数据的分割和遍历。
目录
Iterator
简介
Iterator模式腾空出世,它总是用同一种逻辑来遍历集合。使得客户端自身不需要来维护集合的内部结构,所有的内部状态都由Iterator来维护。客户端从不直接和集合类打交道,它总是控制Iterator,向它发送"向前","向后","取当前元素"的命令,就可以间接遍历整个集合。
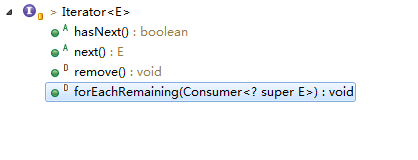
在Java中Iterator为一个接口,它只提供了迭代了基本规则,在JDK中他是这样定义的:对 collection 进行迭代的迭代器。迭代器取代了 Java Collections Framework 中的 Enumeration。
/**
* <p>一个迭代器覆盖一个集合,iterator取代了enumeration
* 它比enumeration好的地方是
* <p>允许在已经访问过的集合内,删除元素
* <p> 增强方法的名字
*
* @param <E> the type of elements returned by this iterator
* <p>E是迭代器返回的元素的类型
* @author Josh Bloch
* @see Collection
* @see ListIterator
* @see Iterable
* @since 1.2
*/
public interface Iterator<E>hasNext
是否有下个元素
/**
* <p>返回这次迭代是否还有更多的元素,换言而之,如果返回true,那么调用next方法会返回一个元素
* <p>如果返回false,next方法会报错
* @return {@code true} if the iteration has more elements
*/
boolean hasNext();next
返回下个元素
/**
* Returns the next element in the iteration.
* <p>返回这次迭代的下一个元素,如果没有了,会报NoSuchElementException
* @return the next element in the iteration
* @throws NoSuchElementException if the iteration has no more elements
*/
E next();remove
存在默认方法,删除
/**
* <p>在已经访问过的集合内,删除最后返回的元素
* <p>这个方法只能在调用next方法后,被调用一次,一一对应,(不能调用1次next,然后调用2次remove)
* <p>如果被访问的集合被修改了(当这个迭代处于其他的过程而不是通过调用这个方法),这个方法的结果没有被定义
* <p>例如在别的线程内,删除元素
* <p>默认实现是不实现方法,抛出异常UnsupportedOperationException(代表着实现iterator接口的类,可以选择不实现这个方法)
* @throws UnsupportedOperationException if the {@code remove}
* operation is not supported by this iterator
*
* @throws IllegalStateException if the {@code next} method has not
* yet been called, or the {@code remove} method has already
* been called after the last call to the {@code next}
* method
*/
default void remove() {
throw new UnsupportedOperationException("remove");
}forEachRemaining
jdk1.8新增的方法,是默认方法,action执行剩余所有元素
/**
* <p>对每个保留的元素执行给定的参数action的accept方法,直到所有的元素都被处理了或者action报错
* <p>注意:第一个被执行的元素是下一次next返回的元素,而不是这个迭代器被新建时,第一次next的元素
* <p>action以迭代的顺序被执行(如果顺序被设定了)
* <p>被抛出的异常会被转发给调用者
* <p>默认实现等价于
* <pre>{@code
* while (hasNext())
* action.accept(next());
* }</pre>
*
* @param action The action to be performed for each element
* @throws NullPointerException if the specified action is null
* @since 1.8
*/
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}Iterable
Iterable是迭代器的意思,作用是为集合类提供for-each循环的支持。由于使用for循环需要通过位置获取元素,而这种获取方式仅有数组支持,其他许多数据结构,比如链表,只能通过查询获取数据,这会大大的降低效率。Iterable就可以让不同的集合类自己提供遍历的最佳方式。
它的作用就是为Java对象提供foreach循环,其主要方法是返回一个Iterator对象:
也就是说,如果想让一个Java对象支持foreach,只要实现Iterable接口,然后就可以像集合那样,通过Iterator iterator = strings.iterator()方式,或者使用foreach,进行遍历
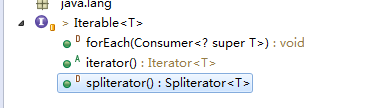
iterator
主要功能,通过iterator方法,返回一个iterator
/**
* <p>返回一个iterator(T类型的)
* @return an Iterator.
*/
Iterator<T> iterator();forEach
1.8新增的方法,默认方法,对iterable的所有元素作为参数执行下面的action.accept这个方法
/**
* <p>默认方法,对iterable的所有元素作为参数执行下面的action.accept这个方法,直到抛出异常
* <p>除非这个方法被覆盖的方法重写了,元素以iterator的顺序被执行
* <p>被抛出的异常会被转发给调用者
* <p>这个方法等价于下面的这个代码
* <pre>{@code
* for (T t : this)
* action.accept(t);
* }</pre>
*
* @param action iterable里的所有元素,都作为参数,一个个给action对象,然后调用它的accept方法
* @throws NullPointerException if the specified action is null
* @since 1.8
*/
default void forEach(Consumer<? super T> action) {
//先校验这个action是否为空,如果为空则报错NullPointerException
Objects.requireNonNull(action);
//对这个iterable对象进行foreach循环
for (T t : this) {
action.accept(t);
}
}spliterator
通过Spliterators工具类的spliteratorUnknownSize方法,返回一个默认的spliterator,这个应该要被覆盖
/**
* <p>创建一个spliterator覆盖这个iterable包含的元素。
*
* <p>默认的实现从iterable的iterator创建一个早期绑定的spliterator。
* 这个spliterator从iterable的iterator继承fail-fast属性。
*
* <p>默认的实现应该通常被覆盖。默认实现返回的spliterator有很差的分割能力,没有报告大小,不能报告任何特征。
* 实现的类应该接近总是提供一个更好的实现。
*
* @return a {@code Spliterator} over the elements described by this
* {@code Iterable}.
* @since 1.8
*/
default Spliterator<T> spliterator() {
//用iterable的iterator结果作为参数,特征直接设置为0,啥都没有
return Spliterators.spliteratorUnknownSize(iterator(), 0);
}可以看到是用给定的iterator作为元素的来源,没有最初的大小估计,创建一个spliterator,一个IteratorSpliterator
/**
* <p>使用给定的iterator作为元素的来源,没有最初的大小估计,创建一个spliterator。
*
* <p>这个spliterator不是迟绑定的,基础了iterator的fail-fast属性,
* 并且实现了trySplit,来允许有限的并发。
*
* <p>元素的遍历应该通过spliterator完成。
* 如果在返回spliterator后对iterator进行操作,分割和遍历的行为是未定义的。
*
*
* @param <T> Type of elements
* @param iterator The iterator for the source
* @param characteristics 这个spliterator的来源或元素的特征。(如果是sized和subsized,会被忽略,并且不报告)
* @return A spliterator from an iterator
* @throws NullPointerException if the given iterator is {@code null}
*/
public static <T> Spliterator<T> spliteratorUnknownSize(Iterator<? extends T> iterator,
int characteristics) {
return new IteratorSpliterator<>(Objects.requireNonNull(iterator), characteristics);
}IteratorSpliterator
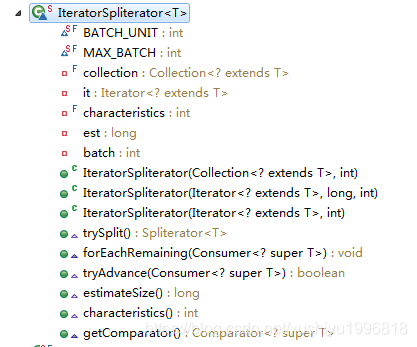
简介
一个spliterator使用给定的iterator作为元素的操作,它实现了trySplit来允许有限的并发。
/**
* 一个spliterator使用给定的iterator作为元素的操作,它实现了trySplit来允许有限的并发。
*/
static class IteratorSpliterator<T> implements Spliterator<T>数据结构
static final int BATCH_UNIT = 1 << 10; // batch array size increment
static final int MAX_BATCH = 1 << 25; // max batch array size;
/**<p>collection和iterator可以在构建时2选1设置,如果是collection,最后会从它生成iterator,赋值给it,最后是使用iterator
* <p>注意collection生成iterator,为了减少对元素来源的操作的影响,会在调用方法时(例如tryAdvance)生成,并设置est=collecion的size
* <p>collection是否为null都可以
*/
private final Collection<? extends T> collection;
private Iterator<? extends T> it; //最后使用的iterator
private final int characteristics;
private long est; // size estimate
private int batch; // batch size for splits构造方法
/**
* Creates a spliterator using the given iterator
* for traversal, and reporting the given initial size
* and characteristics.
*
*
* @param iterator the iterator for the source
* @param characteristics properties of this spliterator's
* source or elements.
*/
public IteratorSpliterator(Iterator<? extends T> iterator, int characteristics) {
this.collection = null;
this.it = iterator;
this.est = Long.MAX_VALUE; //这种情况估计大小为long的max
//特征值无视了sized和subsized(就是这两个位置都设置为0)
this.characteristics = characteristics & ~(Spliterator.SIZED | Spliterator.SUBSIZED);
}tryAdvance和forEachRemaining
基本都是利用iterator的next作为action的参数
@Override
public boolean tryAdvance(Consumer<? super T> action) {
if (action == null) throw new NullPointerException();
if (it == null) {
//初始化iterator
it = collection.iterator();
est = (long) collection.size();
}
//it调用next,iterator前进一步,action接受next的返回值。
if (it.hasNext()) {
action.accept(it.next());
return true;
}
return false;
}
@Override
public void forEachRemaining(Consumer<? super T> action) {
if (action == null) throw new NullPointerException();
Iterator<? extends T> i;
if ((i = it) == null) {
i = it = collection.iterator();
est = (long)collection.size();
}
//使用iterator自带的forEachRemaining方法,
i.forEachRemaining(action);
}trySplit
分割为等差数列,每次增加1024,next的元素放入数组,最后通过ArraySpliterator返回。
@Override
public Spliterator<T> trySplit() {
/*
*
* 分割成算数上递增的块大小。这将仅仅增加并发效果,如果将每个元素进行consumer操作比将它们变成数组花费更大。
* 分割大小递增提供了开销与并发之间的界限,这不是特别有利于或者不利于轻量级元素和重量级元素的操作,
* 它们跨越元素多少n和cpu核心数的组合,无论两者是否已知。我们产生O(sqrt(n))的分割,允许O(sqrt(cores))的潜在递增。
*
*/
Iterator<? extends T> i;
//s为预计大小
long s;
//初始化iterator
if ((i = it) == null) {
i = it = collection.iterator();
s = est = (long) collection.size();
}
else
s = est;
if (s > 1 && i.hasNext()) {
//如果预计大小>1并且iterator有next
//batch为上次分块的大小,最初为0,BATCH_UNIT为块每次递增的长度,=1024,n为本次分割的元素的长度
int n = batch + BATCH_UNIT;
if (n > s)
n = (int) s; //如果n>s,则n=s
if (n > MAX_BATCH)
n = MAX_BATCH;//如果n>max_batch,则n=max_batch= 33554432
Object[] a = new Object[n]; //建立大小为n的数组
int j = 0;
//将数组a中元素一个个放置为i.next,直到没有next或者填满为止
do { a[j] = i.next(); } while (++j < n && i.hasNext());
batch = j; //这次块的大小为j
if (est != Long.MAX_VALUE)
est -= j; //如果est存在,则减去j
//最后根据数组a,长度0到j,特征为characteristics,构建一个ArraySpliterator
return new ArraySpliterator<>(a, 0, j, characteristics);
}
return null;
}其他
@Override
public long estimateSize() {
if (it == null) {
//如果是collection作为构造函数,就先生成iterator
//返回collection的size
it = collection.iterator();
return est = (long)collection.size();
}
//如果是iterator作为参数,会返回long.max_value
//不然会返回上面赋给est的值
return est;
}
@Override
public int characteristics() { return characteristics; }
@Override
public Comparator<? super T> getComparator() {
if (hasCharacteristics(Spliterator.SORTED))
//如果是sorted,返回null,否则抛出IllegalStateException
return null;
throw new IllegalStateException();
}
}

















 1512
1512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









