



 引言
引言
生成式 AI 是当下最热门的术语之一。最近,涉及文本、图像、音频和视频生成的生成式 AI 应用呈现爆发式增长。
在图像创作领域,扩散模型已成为最先进的内容生成技术。虽然该技术最早于 2015 年提出,但经过重大改进后,现已成为 DALLE 和 Midjourney 等知名模型的核心机制。
本文旨在阐释扩散模型的核心原理。掌握这些基础知识将有助于理解复杂扩散变体中使用的进阶概念,并在训练自定义扩散模型时解读超参数的作用。
扩散
物理学类比
让我们想象一杯透明的水。如果我们加入少量另一种黄色液体会发生什么?黄色液体会逐渐均匀地扩散到整杯水中,最终混合物会呈现略微透明的淡黄色。
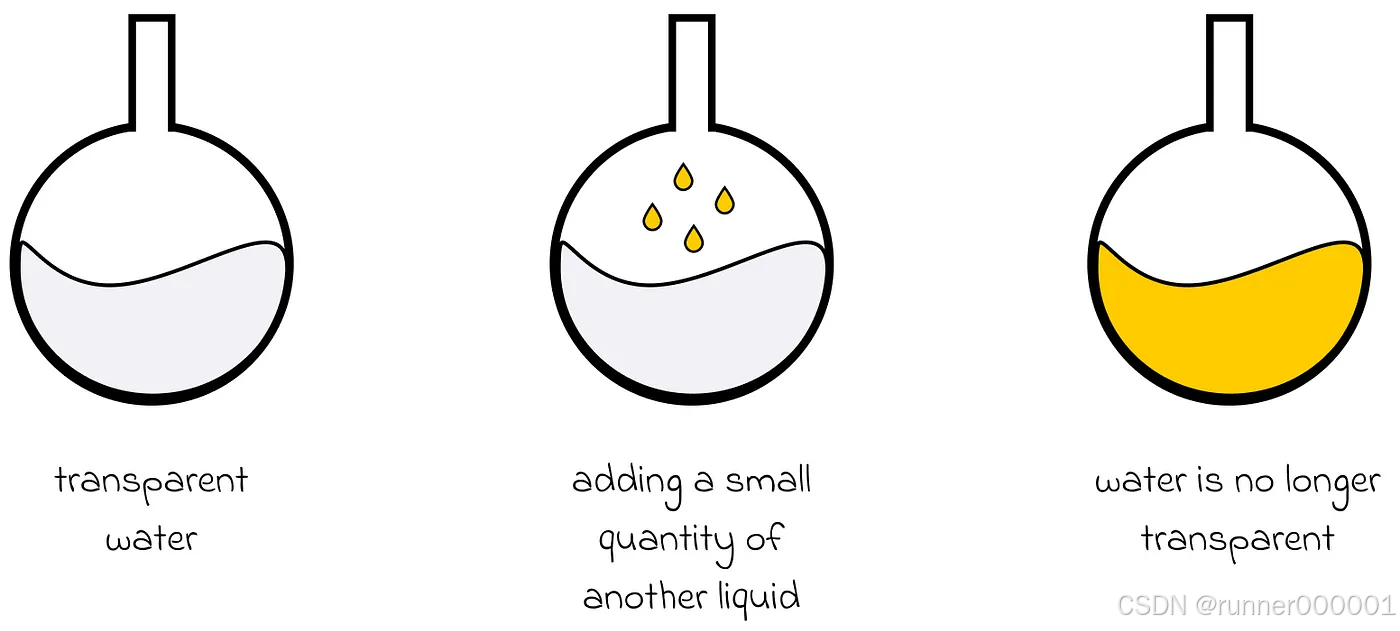
上述过程被称为正向扩散:我们通过添加少量其他液体改变了环境状态。但进行反向扩散——将混合物恢复到原始状态——会同样容易吗?事实证明并非如此。在最佳情况下,实现这一目标需要极其精密的装置。
将这个类比应用于机器学习
扩散过程同样适用于图像处理。想象一张高清的狗狗照片,我们可以通过逐步添加随机噪声来改变这张图片。随着噪声增加,像素值逐渐变化,最终照片里的狗狗会变得模糊难辨。这种转化过程被称为正向扩散。

我们也可以思考逆向操作:给定一张含噪图像,目标是要还原出原始图像。这项任务更具挑战性,因为在海量可能的噪声变体中,具有高度可识别性的图像状态极为稀少。沿用前文的物理学类比,这个过程被称为逆向扩散。
扩散模型架构
为了更好地理解扩散模型的结构,我们需要分别考察这两个扩散过程。
前向扩散
如前所述,前向扩散过程会逐步向图像添加噪声。但在实际操作中,这个过程要更精细一些。
最常用的方法是从均值为 0 的高斯分布中为每个像素采样一个随机值。这个采样值(可为正或负)随后会叠加到像素原始值上。对所有像素重复此操作后,原始图像就会变成带噪版本。
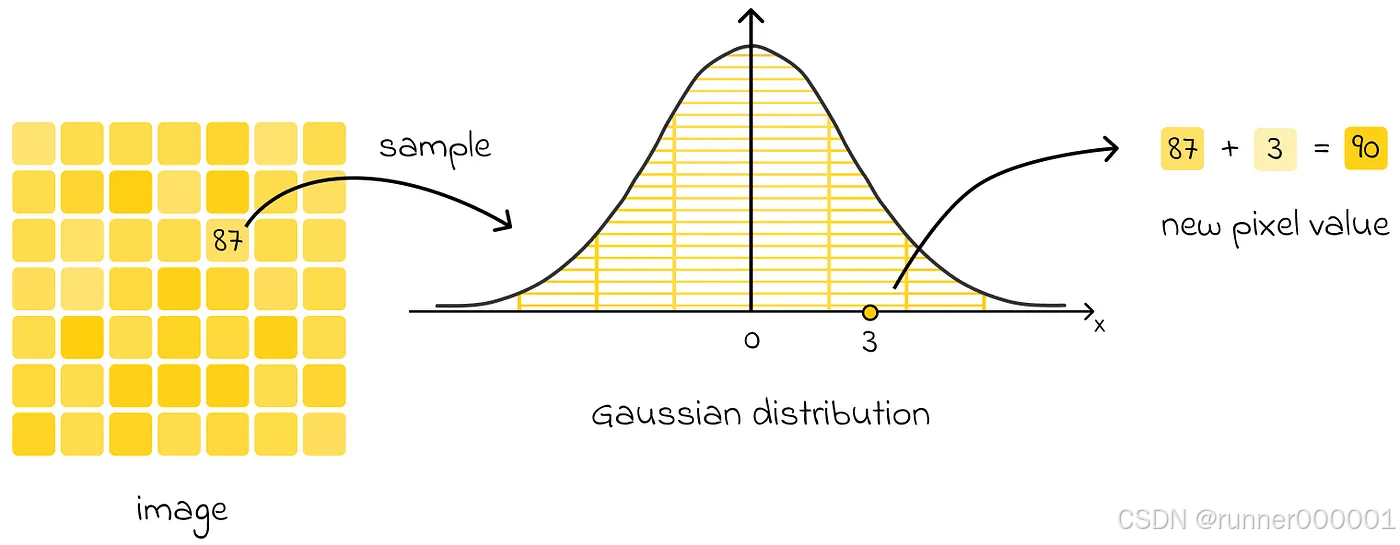
所选的高斯分布通常具有相对较小的方差,这意味着采样值通常较小。因此,每一步仅对图像引入微小的变化。
正向扩散是一个迭代过程,其中噪声会多次施加到图像上。随着每次迭代,生成的图像与原图的差异越来越大。经过数百次迭代(在实际扩散模型中很常见)后,图像最终会变得与纯噪声无异。
逆向扩散
你可能会问:进行所有这些前向扩散变换的目的是什么?答案在于每次迭代生成的图像都用于训练神经网络。
具体来说,假设我们在前向扩散过程中应用了 100 次连续的噪声变换。我们可以获取每一步的图像,并训练神经网络从当前步骤重建上一步骤的图像。预测图像与实际图像之间的差异通过损失函数(例如均方误差 MSE)计算,该函数衡量两幅图像之间像素级的平均差异。
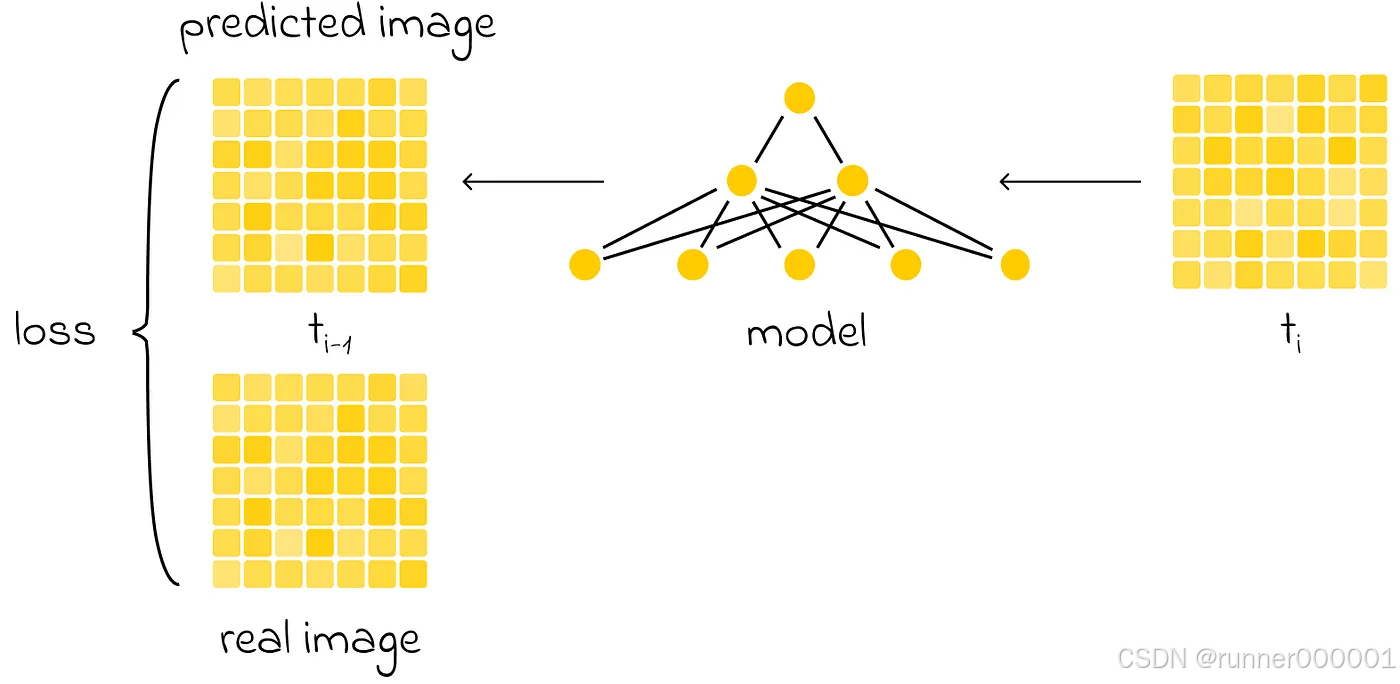
这个例子展示了扩散模型如何重建原始图像。与此同时,扩散模型也可以被训练用于预测图像中添加的噪声。在这种情况下,只需从上一迭代步骤的图像中减去预测噪声即可重建原始图像。
虽然这两项任务看似相似,但预测添加噪声相比图像重建要简单得多。
模型设计
在获得对扩散技术的基本直觉后,有必要探索几个更高级的概念以更好地理解扩散模型的设计。
迭代次数
迭代次数是扩散模型中的关键参数之一:
一方面,使用更多迭代次数意味着相邻步骤的图像对差异会更小,使模型的学习任务更容易。另一方面,更高的迭代次数会增加计算成本。
减少迭代次数可以加快训练速度,但模型可能无法学习步骤间的平滑过渡,导致性能不佳。
通常迭代次数选择在 50 到 1000 之间。
神经网络架构
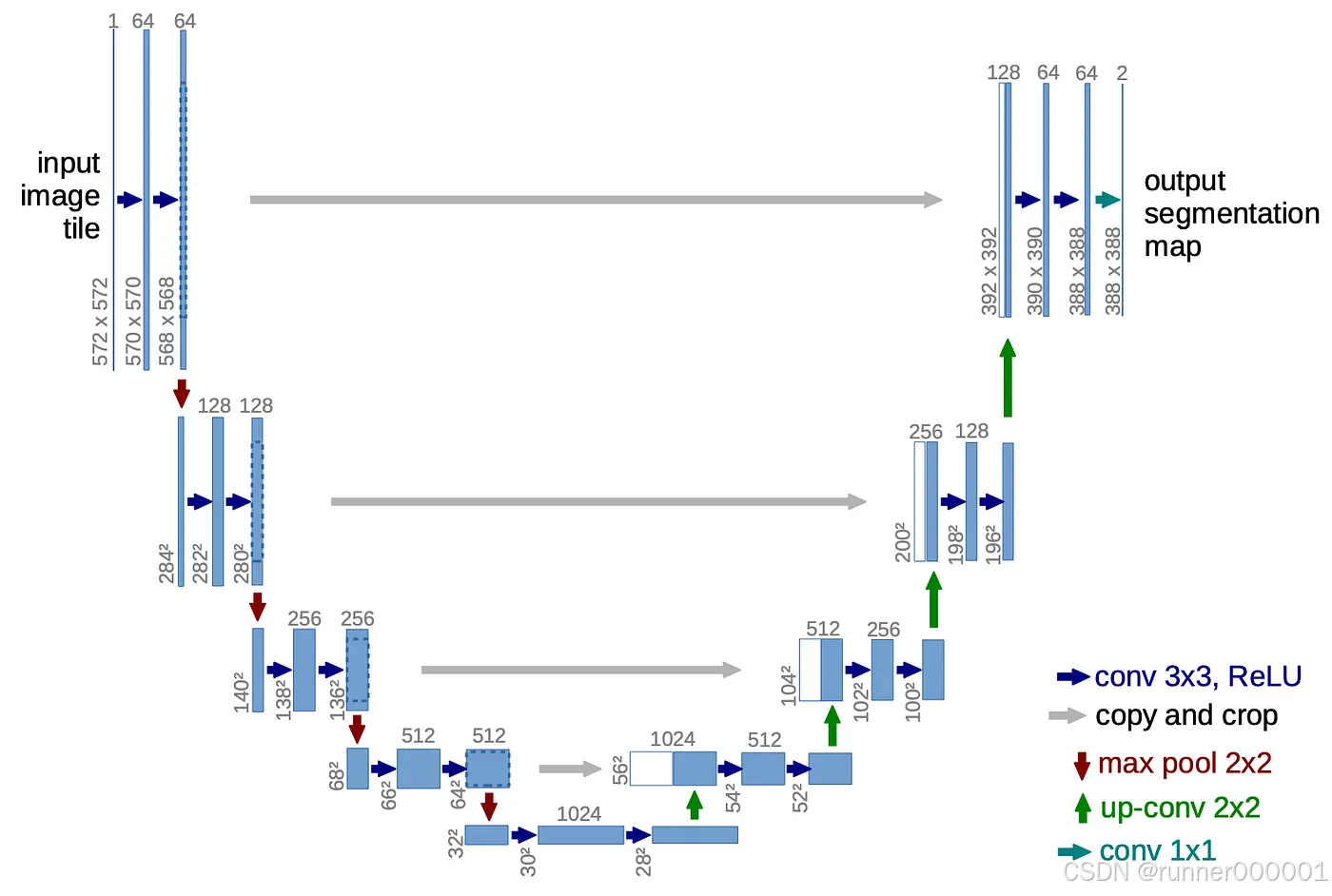
扩散模型最常采用 U-Net 架构作为主干网络,主要原因如下:
- U-Net 保持输入和输出图像的维度一致,确保在反向扩散过程中图像尺寸始终不变。
- 其瓶颈式架构能在图像压缩至潜空间后实现完整重建,同时通过跳跃连接保留关键图像特征。
- U-Net 最初为生物医学图像分割设计(该领域需要像素级精度),其优势恰好适用于需要精确预测单个像素值的扩散任务。
共享网络
乍看之下,似乎需要在扩散过程的每次迭代中训练单独的神经网络。虽然这种方法可行并能产生高质量的推断结果,但从计算角度来看效率极低。例如,若扩散过程包含一千个步骤,我们就需要训练一千个 U-Net 模型——这是极其耗时且消耗资源的任务。
但我们可以发现,不同迭代间的任务配置本质相同:每种情况下,我们都需要重建相同尺寸的图像,这些图像仅被相似强度的噪声所改变。这一关键洞见催生了在所有迭代中使用单一共享神经网络的想法。
实践中,这意味着我们使用具有共享权重的单一 U-Net 模型,该模型在不同扩散步骤的图像对上训练。在推断阶段,含噪图像会多次通过同一个训练好的 U-Net,逐步精炼直至生成高质量图像。

虽然仅使用单一模型可能导致生成质量略有下降,但训练速度的提升变得极为显著。
结论
本文探讨了扩散模型的核心概念,这些模型在图像生成中起着关键作用。这类模型有许多变体——其中稳定扩散模型尤为流行。虽然基于相同的基本原理,稳定扩散还能整合文本或其他类型的输入来引导和约束生成的图像。



















 3070
3070

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











