





《我的世界》对强化学习而言是个不可思议的挑战。
这款游戏体量庞大,包含众多机制和复杂的动作序列。仅是为人类玩家编写的维基指南就超过 8000 页。那么机器学习能表现得多出色呢?
这正是本文要解答的问题。我们将设计一个机器人程序,尝试完成《我的世界》中最艰巨的挑战之一:从零开始寻找钻石。更困难的是,我们将在随机生成的世界中接受这项挑战,因此无法依赖特定种子进行学习。

我们要讨论的内容不仅限于《我的世界》。它可以应用于类似的复杂环境。更具体地说,我们将实现两种不同的技术,这些技术将成为我们智能代理的核心基础。
但在训练代理之前,我们需要了解如何与环境交互。让我们从一个脚本化的机器人开始,熟悉相关语法。我们将使用 MineRL 这个出色的库来构建《我的世界》中的人工智能应用。
本文使用的代码可在 Google Colab上获取。这是基于 2021 年 MineRL 竞赛组织者(MIT 许可)制作的优秀笔记本简化调整后的版本。
📜 一、脚本机器人
MineRL 允许我们在 Python 中启动《我的世界》并与游戏交互。这是通过流行的 gym 库实现的。
env = gym.make('MineRLObtainDiamond-v0')
env.seed(21)

我们正对着一棵树。如你所见,分辨率相当低。低分辨率意味着像素更少,这能加快处理速度。幸运的是,神经网络不需要 4K 分辨率也能理解屏幕上的内容。
现在,我们需要与游戏进行交互。我们的智能体能执行哪些操作?以下是可能的动作列表:

寻找钻石的第一步是获取木材来制作工作台和木镐。
让我们试着靠近那棵树。这意味着我们需要按住"前进"键不到一秒。在 MineRL 中,每秒会处理 20 个动作:我们不需要完整的一秒,所以处理 5 次动作,然后等待 40 个游戏刻。
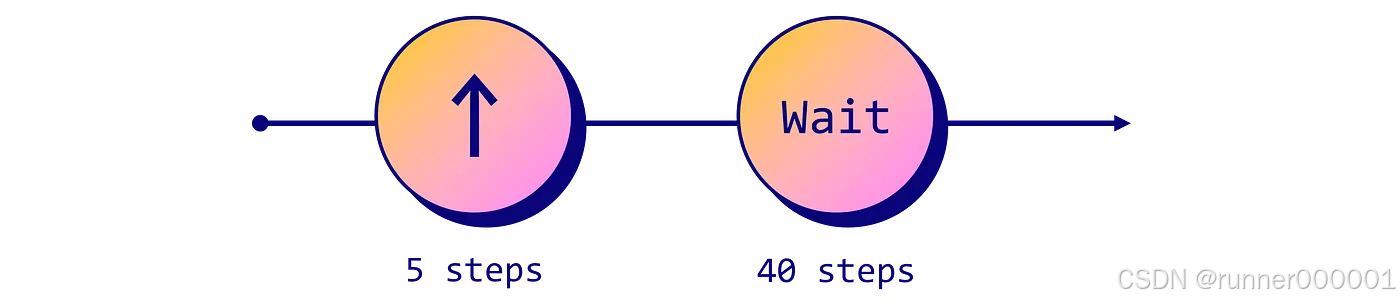
# Define the sequence of actions
script = ['forward'] * 5 + [''] * 40
env = gym.make('MineRLObtainDiamond-v0')
env = Recorder(env, './video', fps=60)
env.seed(21)
obs = env.reset()
for action in script:
# Get the action space (dict of possible actions)
action_space = env.action_space.noop()
# Activate the selected action in the script
action_space[action] = 1
# Update the environment with the new action space
obs, reward, done, _ = env.step(action_space)
env.release()
env.play()很好,现在来砍这棵树。我们总共需要四个动作:
- 前进以走到树前;
- 攻击来砍树;
- 调整镜头视角向上或向下;
- 跳跃以获取最后一块木材。
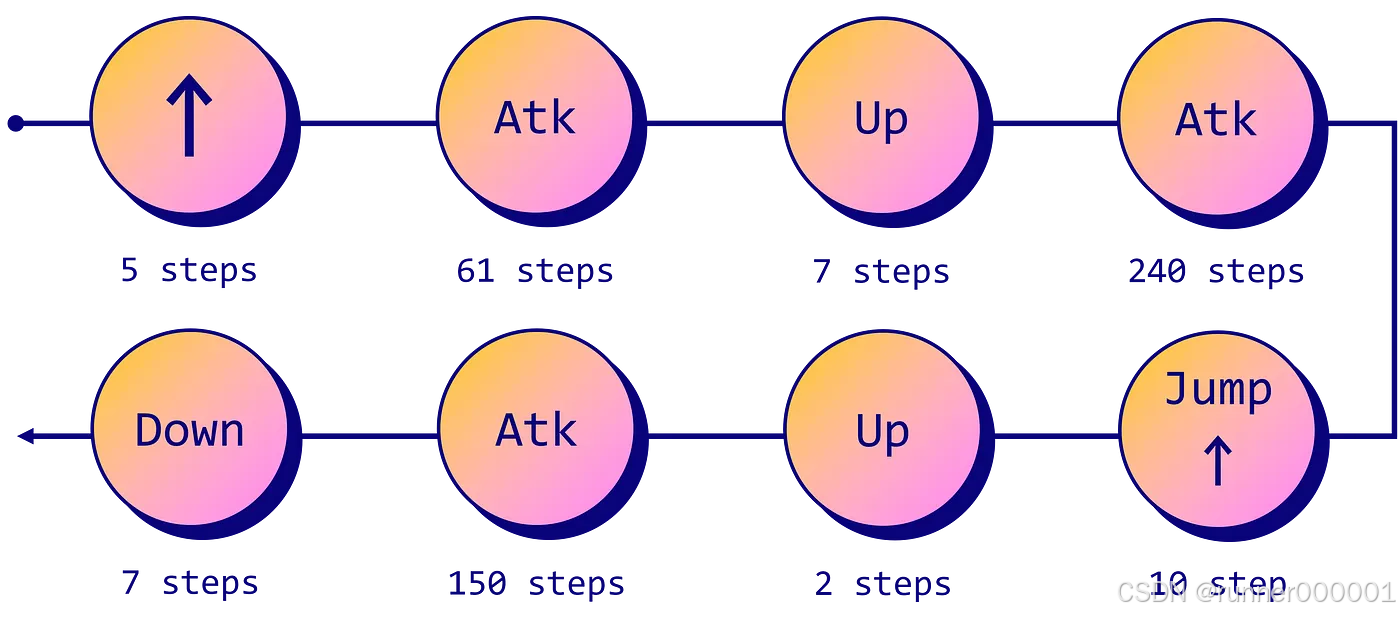
手动操控镜头可能相当麻烦。为了简化语法,我们将采用这个GitHub仓库(MIT 许可证)中的 str_to_act 函数。修改后的脚本如下:
script = []
script += [''] * 20
script += ['forward'] * 5
script += ['attack'] * 61
script += ['camera:[-10,0]'] * 7 # Look up
script += ['attack'] * 240
script += ['jump']
script += ['forward'] * 10 # Jump forward
script += ['camera:[-10,0]'] * 2 # Look up
script += ['attack'] * 150
script += ['camera:[10,0]'] * 7 # Look down
script += [''] * 40
for action in tqdm(script):
obs, reward, done, _ = env.step(str_to_act(env, action))
env.release()
env.play()智能体高效地砍伐了整棵树。这是个良好的开端,但我们希望能以更自动化的方式实现……
🧠 二、深度学习
我们的机器人在固定环境中表现良好,但如果改变种子或起始点会发生什么?
由于所有行为都是预设脚本,这个智能体很可能会试图砍伐不存在的树木。
这种静态方法无法满足我们的需求:我们需要能适应新环境的方案。比起编写预设指令,我们更希望 AI 能真正掌握砍树技能。自然,强化学习是训练此类智能体的合适框架。更具体地说,由于我们通过图像处理来选择最佳动作,深度强化学习似乎是理想的解决方案。
具体实现有两种途径:
- 纯深度强化学习:智能体通过与环境的交互从零开始训练,每次砍伐树木都会获得奖励。
- 模仿学习:智能体通过数据集学习如何砍伐树木。在本案例中,学习内容是人类演示的砍树动作序列。
两种方法能达到相同效果,但效率不同。根据 MineRL 2021 竞赛作者的数据,纯强化学习方案需要 8 小时才能达到的熟练度,模仿学习智能体仅需 15 分钟即可达成。
我们没有那么多时间可以消耗,因此选择模仿学习方案。该技术也被称为行为克隆,是最简单的模仿形式。
需要注意的是,模仿学习并不总是比强化学习更高效。若想深入了解这个话题,Kumar 等人曾就此撰写过一篇精彩的博客文章。
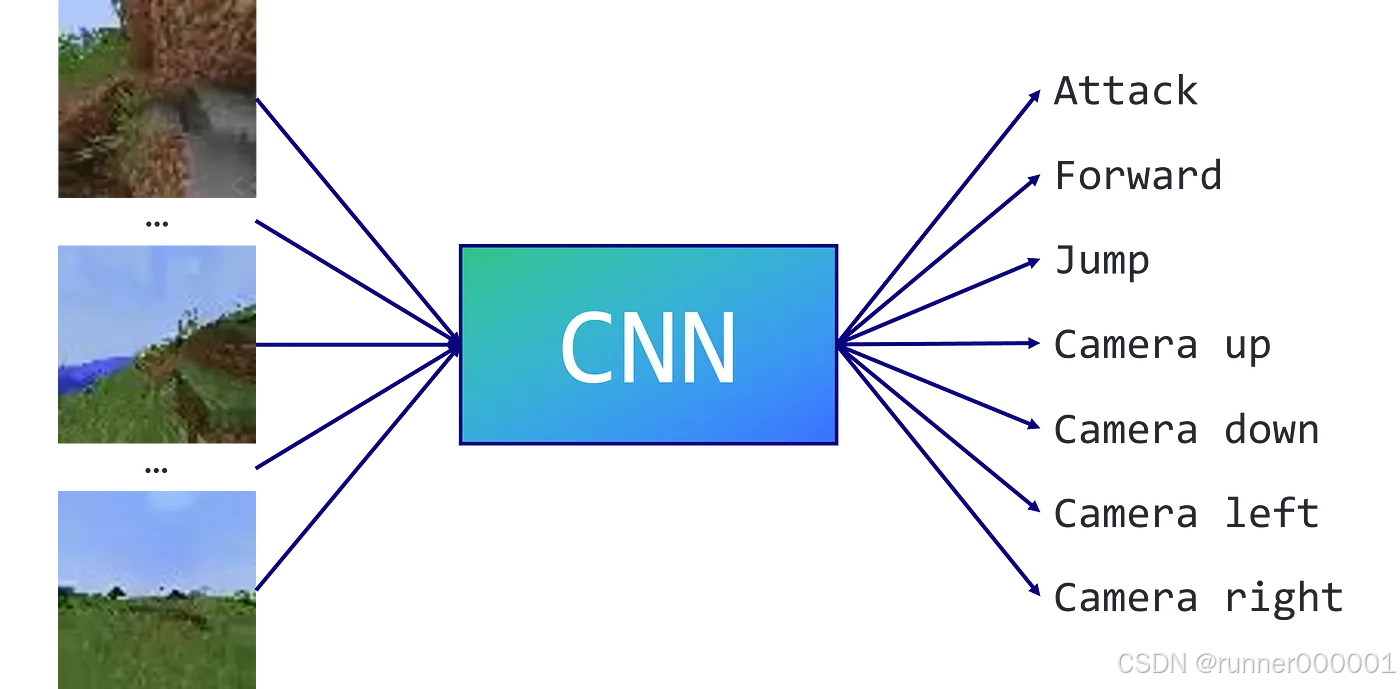
该问题可简化为多类别分类任务。我们的数据集由 mp4 视频构成,因此将使用卷积神经网络(CNN)将这些图像转换为相应动作。同时我们也要限制可执行动作(类别)的数量,这样 CNN 的选择会更少,意味着训练效率会更高。
class CNN(nn.Module):
def __init__(self, input_shape, output_dim):
super().__init__()
n_input_channels = input_shape[0]
self.cnn = nn.Sequential(
nn.Conv2d(n_input_channels, 32, kernel_size=8, stride=4),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=4, stride=2),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, stride=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Flatten(),
nn.Linear(1024, 512),
nn.ReLU(),
nn.Linear(512, output_dim)
)
def forward(self, observations):
return self.cnn(observations)
def dataset_action_batch_to_actions(dataset_actions, camera_margin=5):
...
class ActionShaping(gym.ActionWrapper):
...本示例中,我们手动定义了 7 个相关动作:攻击、前进、跳跃以及镜头移动(左、右、上、下)。另一种常见方法是应用 K 均值算法来自动提取人类执行的最相关动作。无论采用哪种方式,目标都是剔除对完成任务最无用的动作——比如本例中的物品合成。
现在让我们在 MineRLTreechop-v0 数据集上训练 CNN。其他数据集可通过此链接获取。我们选择了 0.0001 的学习率,32 的批次大小,并进行 6 个训练周期。
# Get data
minerl.data.download(directory='data', environment='MineRLTreechop-v0')
data = minerl.data.make("MineRLTreechop-v0", data_dir='data', num_workers=2)
# Model
model = CNN((3, 64, 64), 7).cuda()
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)
criterion = nn.CrossEntropyLoss()
# Training loop
step = 0
losses = []
for state, action, _, _, _ \
in tqdm(data.batch_iter(num_epochs=6, batch_size=32, seq_len=1)):
# Get pov observations
obs = state['pov'].squeeze().astype(np.float32)
# Transpose and normalize
obs = obs.transpose(0, 3, 1, 2) / 255.0
# Translate batch of actions for the ActionShaping wrapper
actions = dataset_action_batch_to_actions(action)
# Remove samples with no corresponding action
mask = actions != -1
obs = obs[mask]
actions = actions[mask]
# Update weights with backprop
logits = model(torch.from_numpy(obs).float().cuda())
loss = criterion(logits, torch.from_numpy(actions).long().cuda())
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Print loss
step += 1
losses.append(loss.item())
if (step % 2000) == 0:
mean_loss = sum(losses) / len(losses)
tqdm.write(f'Step {step:>5} | Training loss = {mean_loss:.3f}')
losses.clear()Step 4000 | Training loss = 0.878
Step 8000 | Training loss = 0.826
Step 12000 | Training loss = 0.805
Step 16000 | Training loss = 0.773
Step 20000 | Training loss = 0.789
Step 24000 | Training loss = 0.816
Step 28000 | Training loss = 0.769
Step 32000 | Training loss = 0.777
Step 36000 | Training loss = 0.738
Step 40000 | Training loss = 0.751
Step 44000 | Training loss = 0.764
Step 48000 | Training loss = 0.732
Step 52000 | Training loss = 0.748
Step 56000 | Training loss = 0.765
Step 60000 | Training loss = 0.735
Step 64000 | Training loss = 0.716
Step 68000 | Training loss = 0.710
Step 72000 | Training loss = 0.693
Step 76000 | Training loss = 0.695我们的智能体虽然行为相当混乱,但在这个全新的未知环境中仍能成功砍伐树木。那么,如何寻找钻石呢?
⛏️ 三、脚本+模仿学习
一个简单而有效的方法是将脚本化动作与人工智能相结合。先学习基础操作,再用脚本固化这些知识。
按照这个模式,我们将使用卷积神经网络(CNN)采集足量木材(3000 步)。接着通过预设脚本依次制作木板、木棍、工作台、木镐,并开始挖掘脚下的石头。这些石头可用于制作石镐,进而开采铁矿。
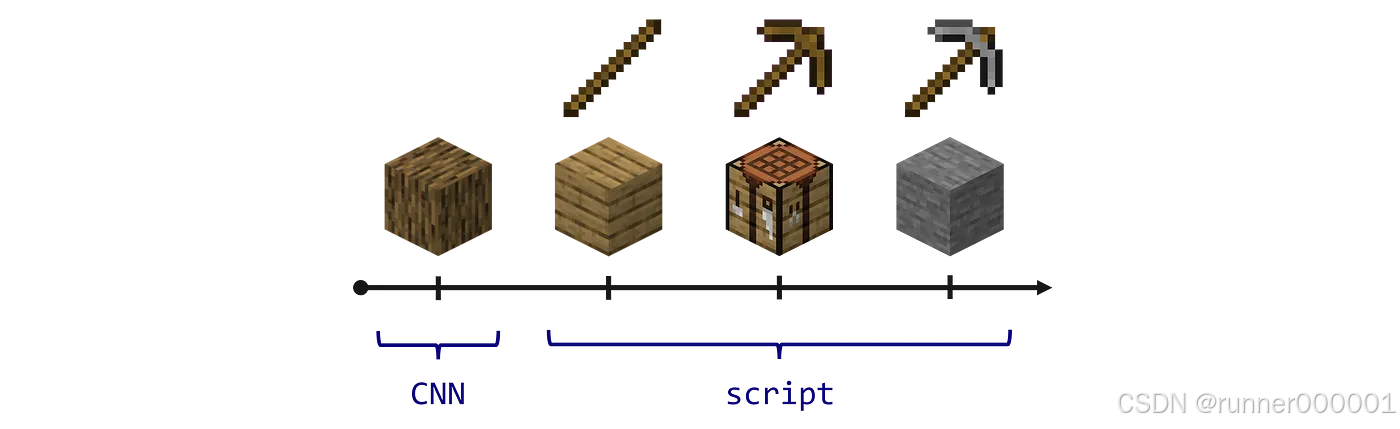
这时情况就变得复杂了:铁矿相当稀少,我们需要运行游戏一段时间才能找到矿脉。然后还得制作熔炉冶炼,才能得到铁镐。最后必须向更深处挖掘,并且足够幸运才能在不掉进岩浆的情况下获得钻石。
如你所见,虽然可行但结果相当随机。我们可以训练另一个智能体来寻找钻石,甚至再训练第三个来制作铁镐。如果你对更复杂的方法感兴趣,可以阅读 Kanervisto 等人撰写的《2021 年 MineRL 钻石挑战赛成果报告》。该报告描述了多种运用不同智能技术的解决方案,包括端到端的深度学习架构。不过这个问题确实非常复杂,即使有团队成功,也没有人能稳定地找到钻石。
因此接下来的示例中我们将仅限于获取石镐,但你可以修改代码来实现更深入的目标。
obs = env_script.reset()
done = False
# 1. Get wood with the CNN
for i in tqdm(range(3000)):
obs = torch.from_numpy(obs['pov'].transpose(2, 0, 1)[None].astype(np.float32) / 255).cuda()
probabilities = torch.softmax(model(obs), dim=1)[0].detach().cpu().numpy()
action = np.random.choice(action_list, p=probabilities)
obs, reward, done, _ = env_script.step(action)
if done:
break
# 2. Craft stone pickaxe with scripted actions
if not done:
for action in tqdm(script):
obs, reward, done, _ = env_cnn.step(str_to_act(env_cnn, action))
if done:
break
print(obs["inventory"])
env_cnn.release()
env_cnn.play()我们可以看到代理在前 3000 步像疯了一样砍树,随后我们的脚本接管并完成了任务。虽然不太明显,但命令 print(obs.inventory) 显示的是一把石镐。请注意这是个精选案例:大多数运行结果都没这么理想。
代理失败的原因有多种:可能生成在敌对环境(水、岩浆等)、没有木材的区域,甚至可能坠落死亡。尝试不同种子能让你充分理解这个问题的复杂性,或许还能启发你打造更优秀的事件处理代理。
结论
希望你喜欢这篇《我的世界》强化学习入门指南。除了显而易见的流行度,这款游戏还是测试强化学习代理的绝佳沙盒。与《NetHack》类似,它要求玩家精通游戏机制,才能在程序生成的世界中规划精确行动序列。本文中,
- 我们学习了如何使用 MineRL 工具;
- 我们探讨了两种方法(脚本和行为克隆)及其结合方式;
- 我们通过短视频直观展示了智能体的行为。
该环境的主要缺点是处理速度较慢。《我的世界》并非像《NetHack》或《Pong》那样的轻量级游戏,因此智能体需要较长时间进行训练。若存在效率问题,建议改用 Gym Retro 等更轻量的训练环境。



















 1503
1503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











