





 超级会员免费看
超级会员免费看

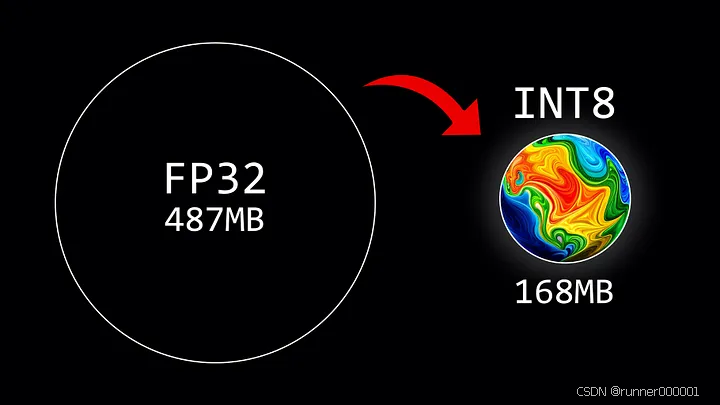
大型语言模型(LLMs)因其庞大的计算需求而闻名。通常,模型大小通过参数数量(规模)与数值精度(数据类型)相乘计算得出。但为了节省内存,可通过称为量化的过程,使用更低精度的数据类型存储权重。
本文我们区分出两大权重量化技术体系:
训练后量化(PTQ)是一种直接的技术,它无需重新训练即可将已训练模型的权重转换为更低精度。虽然易于实现,但 PTQ 可能导致性能下降。
量化感知训练(QAT)在预训练或微调阶段就融入了权重转换过程,从而提升模型性能。然而 QAT 计算成本高昂,且需要具有代表性的训练数据。
本文我们将重点使用 PTQ 方法来降低参数精度。为了获得直观理解,我们将对 GPT-2 模型示例同时应用基础版和更复杂的量化技术。
📚 浮点数表示法背景
数据类型的选择决定了所需计算资源的数量,影响模型的速度和效率。在深度学习应用中,平衡精度与计算性能成为关键考量,因为更高的精度通常意味着更大的计算需求。
在各种数据类型中,浮点数因其能够高精度表示大范围数值的特点,成为深度学习领域的主流选择。通常,一个浮点数会使用 n 位来存

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1068
1068

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











