







论文框架
这篇论文是关于**视觉问答问题(VQA,visual question answering)**的,北京交通大学的团队发表在CVPR 2020上的一篇。
摘要
由于现实生活中充满了 top-down 的注意力机制(任务驱动),而现有很多模型还是基于 bottom-up 的注意力机制(显著程度),所以本文从数据和模型两方面提供了一些解决。
首先提住了一个沉浸式场景的 top-down注意力的数据集 IQVA,由975个问题和问题的答案组成。IQVA可以表现视觉注意力的相应任务的表现(答案正确性),问题是参与者在头戴式显示器中观看360度视频时提出的。
数据分析表明,参与者的任务表现和他们的眼球运动之间存在明显联系,这也表明top-down任务注意力在任务表现中的作用。
在此基础上,本文提出了一个注意力模型,共同预测正确和不正确的注意力固定图。模型考虑到了预测答案的正确性,并且其输出结果将重要区域与其他区域分开。
这项研究可能会促进新的任务,激发新的研究。
背景介绍
问题:
- top-down研究较少
- 受限的矩形视觉场景,可能会使眼动追踪数据无法模拟人类真是的注意力;
改进:
- 沉浸式场景(头戴式显示器,360度的视频)
- 提出更有挑战性的问题,同时验证真实值(ground-truth)答案的正确性;
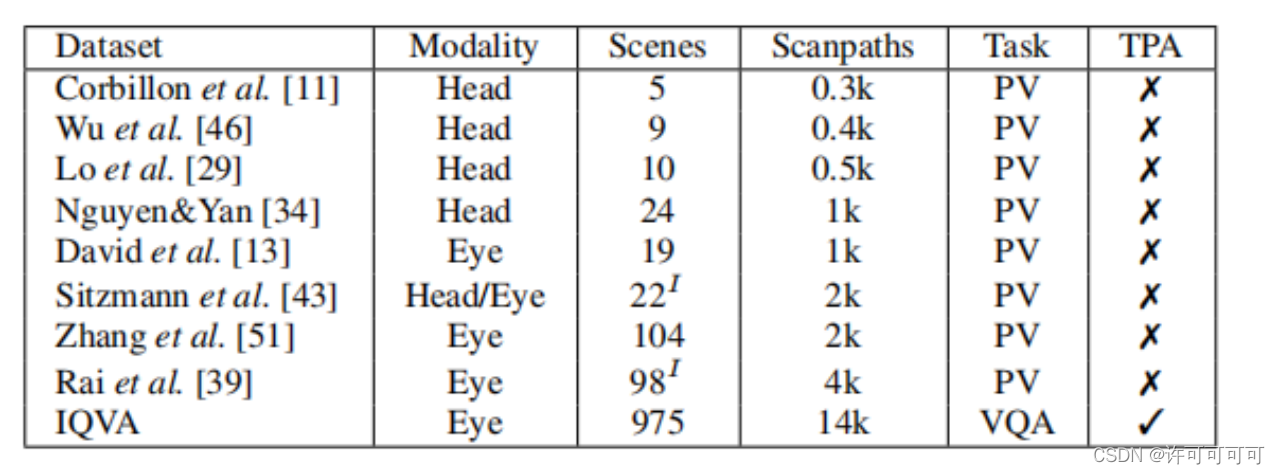
数据集
数据收集过程
视频来自YouTube,包括大多数人类活动和自然场景。一共有975个视频片段和14个参与者的眼球追踪数据。
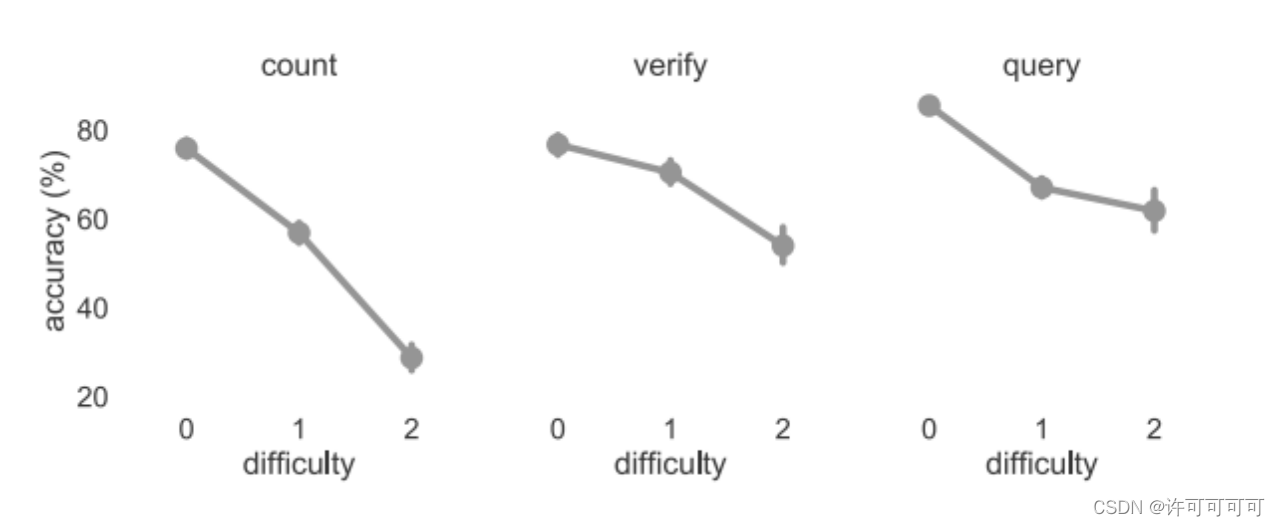
确保问题没有歧义,并且具有一定难度(分为0-2级)。
问题可以分成三类:查询、计数和验证。
最后统计的眼球追踪数据是一个固定图(一组从初始注视点位置开始的一组视觉扫描路径)。
数据分析
-
人类的视线偏向赤道:存在一定视觉偏差,不影响最终任务表现。
-
人类的答案具有广泛的准确性:参与者答案的总体准确性为68.45%。15.78%的问题回答全部正确,50.51%的问题的回答准确率在20%-80%。
-
正确的关注是一样的: 将答案分为正确、不正确、介于正确和不正确之间,测量每对视觉扫描路径之间的时空距离,分别得出EDR打分(分数越低表明扫描路径越相似)。回答正确的人的注意模式较相似,而不正确或模糊的答案的人的注意模式不同。同时注意到计数问题的注意模式是不同的。

- ** 不正确的关注以不同的模式失败**:不正确的注意力可能会缺少重要的线索,没有足够的视觉停留或者足够的注意力,或者在变化的场景中错过了时机,看到了错误的画面。
总而言之,分析表明注意力和任务表现之间具有很强的相关性,在正确和不正确的注意力之间也有一些差别。
预测模型
模型-语义工作记忆
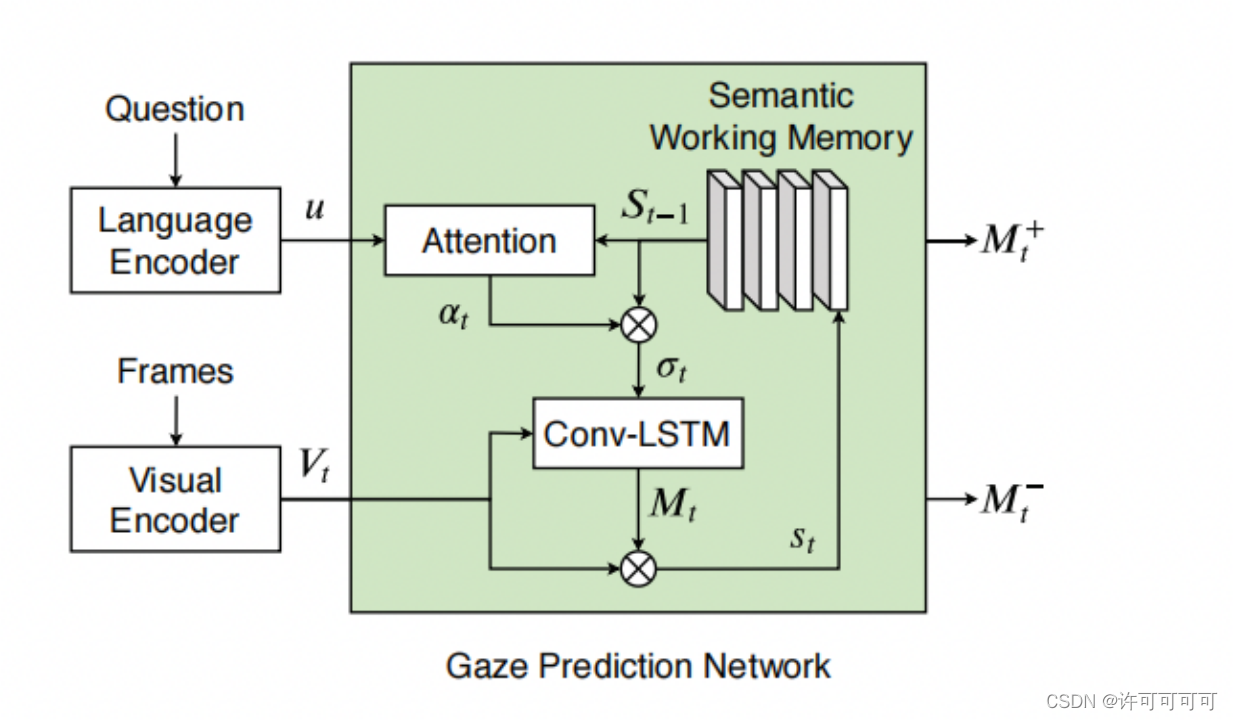
模型能够将任务信息与视觉输入联系起来,并随着时间的推移适应性地汇总重要语句,一利于视频帧地注意力预测。
精细化差异损失
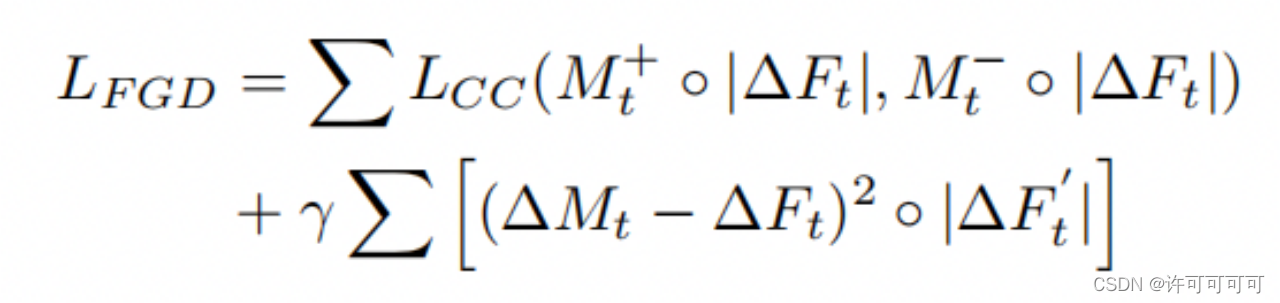
前项对注意力进行归一化,最小化他们的相关性使模型进行不同的预判,第二项最小化是见效预测和真实值的差异。
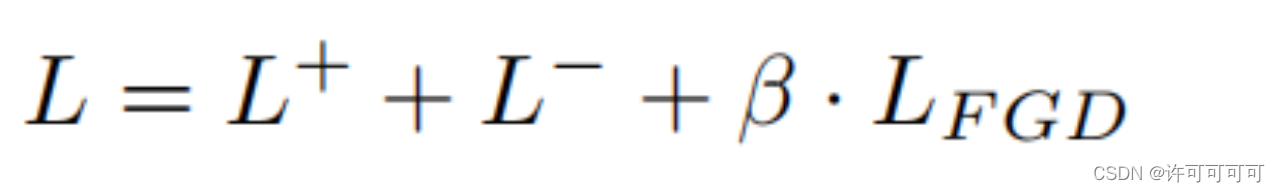
实验和结果
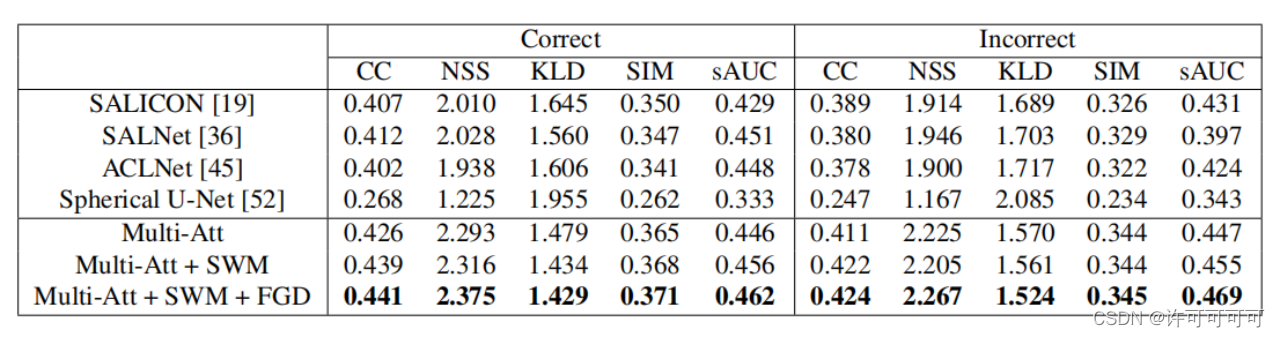
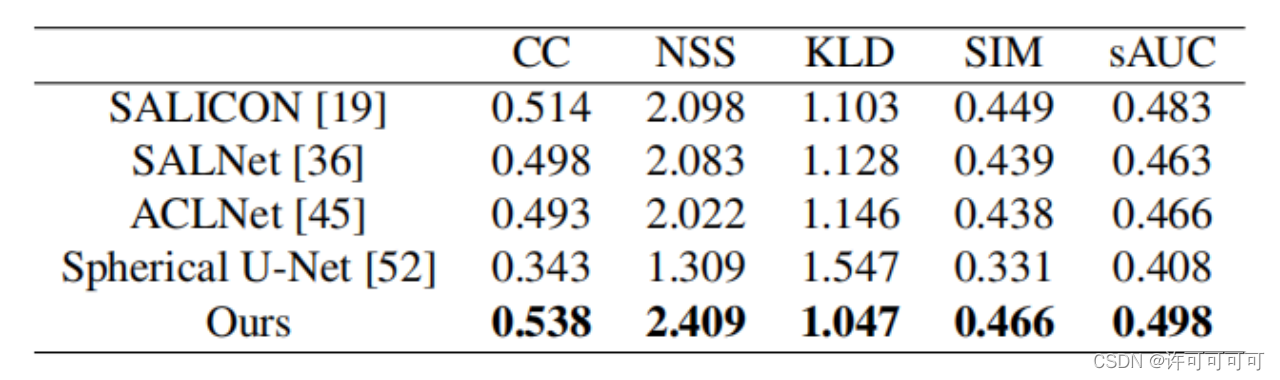
将数据集分为658个训练样本,96个验证样本和221个测试样本,训练和评估模型,执行正确性意识的注意力预测和不考虑正确性的注意力预测两个任务。
给定视频和问题,前者的目标是预测每个视频帧正确和不正确的注意力,后者是预测一个聚合的变化图。
总结
这篇文章主要的贡献在于:
- 提出了IQVA数据集,是沉浸式的,并且是top-down注意力;
- 为了评估数据集提出了一个改进之后的注意力预测模型,主要的创新点在两方面(语义工作记忆和精细化差异损失),模型通过联合信息有很好的表现。
通过进行研究,能够分析得出注意力和任务表现之间有很强的相关性。
后续的模型改进主要在对个人注意力模式的理解和预测,以及提高神经网络的性能和可解释性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









