







1.序列化
1.什么是序列化&反序列化?
序列化:内存中的数据类型--->序列化----->特定格式(json格式或pickle格式)
反序列化:内存中的数据类型<---序列化<-----特定格式(json格式或pickle格式)
土办法:
{'a':1,'b':2}--->序列化str({'a':1,'b':2})---->"{'a':1,'b':2}"
{'a':1,'b':2}--->反序列化eval({'a':1,'b':2})---->"{'a':1,'b':2}"
2.为何要序列化?
序列化是指 将内存的数据类型----->特定格式内容
1.可用于储存===>用于存档 推荐用pickle,并不常用
2.传输给其他平台使用===>跨平台数据交互 需要用json
3.如何序列化与反序列化
示例1:
import json
#序列化 列表转json格式的字符串
json_res=json.dumps([1,'aaa',True,False])
print(json_res,type(json_res))#[1, "aaa", true, false] <class 'str'>
#反序列化 json格式的字符串转列表
l=json.loads(json_res)
print(l,type(l))#[1, 'aaa', True, False] <class 'list'>示例2:
序列化,并将序列化结果写入文件的简便方法
import json
#序列化,并将序列化结果写入文件的简便方法
with open('test.json',mode='wt',encoding='utf-8') as f:
json.dump([1,'aaa',True,False],f)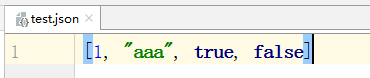
反序列化,从文件读取json格式字符串,并进行反序列化的简单方法
with open('test.json',mode='rt',encoding='utf-8') as f:
l=json.load(f)
print(l, type(l))#[1, 'aaa', True, False] <class 'list'>json格式兼容的是所有语言通用的数据类型,不能识别某一语言独有的数据类型
比如python独有的集合set类型,需要用pickle模块,用法跟json一致
import pickle
pickle_res=pickle.dumps([1,2,3,4,5,6])
print(pickle_res,type(pickle_res))
#b'\x80\x03]q\x00(K\x01K\x02K\x03K\x04K\x05K\x06e.' <class 'bytes'>
s=pickle.loads(pickle_res)
print(s,type(s))#[1, 2, 3, 4, 5, 6] <class 'list'>json强调:一定要搞清楚json格式与python的差别,不要混淆了
补充:古时候没有json时用XML,现在很少用了。shelve模块与pickle类似,了解即可。
configparser模块:
python项目的配置文件多写成settings.py ,将配置项写到py文件里 其实也可以写在.ini或者.conf文件中,写成分组的形式,而其他语言项目多是采用这种模式存放配置文件 configparser模块中有许多方法来操作这类的配置文件,遇到需要的时候,了解即可。
2.hash(哈希)介绍
1.什么是哈希?
hash是一类算法,该算法接收传入的内容,经过运算得到一串hash值
hash值的特点:
1.只要传入的内容一样,得到的hash值必然一样 2.不能由hash值返解传入内容 3.只要hash算法不变,不论传入内容长度如何,得到的hash值长度不变
2.hash的用途
用途1:密码密文的传输与验证 用途2:文件完整性校验
3.如何用?
import hashlib
m=hashlib.md5()
m.update('hello'.encode('utf-8'))#第一部分转成b投入算法
m.update('world'.encode('utf-8'))#第二部分转成b投入算法
res=m.hexdigest()#helloworld
print(res)#fc5e038d38a57032085441e7fe7010b0合在一起传入
import hashlib
m.update('helloworld'.encode('utf-8'))
res=m.hexdigest()#helloworld
print(res)#fc5e038d38a57032085441e7fe7010b0第一种: m.update(文件所有的内容) m1=m.hexdigest() 第二种 m.update(第一行内容) m.update(第一行内容) m.update(第一行内容) m.update(第一行内容) …… m2=m.hexdigest() 第一种和第二种等价,推荐使用第二种。 m1==m2
更常用的
hashlib.sha256()
用法与md5一样。
4.密码加盐
撞库:密码被试出来
提升撞库成本===》密码加盐
import hashlib
m=hashlib.md5()
m.update('天王'.encode('utf-8'))
m.update('密码明文'.encode('utf-8'))
m.update('盖地虎'.encode('utf-8'))
print(m.hexdigest())#606ab56ded2c33b3dce5332ce35aa099
















 2212
2212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









