







之前的文章集合:
一些可以参考文章集合1_xuejianxinokok的博客-优快云博客
一些可以参考文章集合2_xuejianxinokok的博客-优快云博客
一些可以参考的文档集合3_xuejianxinokok的博客-优快云博客
一些可以参考的文档集合4_xuejianxinokok的博客-优快云博客
一些可以参考的文档集合5_xuejianxinokok的博客-优快云博客
一些可以参考的文档集合6_xuejianxinokok的博客-优快云博客
一些可以参考的文档集合7_xuejianxinokok的博客-优快云博客
一些可以参考的文档集合8_xuejianxinokok的博客-优快云博客
一些可以参考的文档集合9_xuejianxinokok的博客-优快云博客
一些可以参考的文档集合10_xuejianxinokok的博客-优快云博客
一些可以参考的文档集合11_xuejianxinokok的博客-优快云博客
一些可以参考的文档集合12_xuejianxinokok的博客-优快云博客
一些可以参考的文档集合13_xuejianxinokok的博客-优快云博客
一些可以参考的文档集合14_xuejianxinokok的博客-优快云博客
20250611
作业帮基础观测能力之二全链路追踪实践_架构_InfoQ精选文章作业帮基础观测能力之二全链路追踪实践![]() https://www.infoq.cn/article/UccFkN9RIqvoOOkUQxLQ
https://www.infoq.cn/article/UccFkN9RIqvoOOkUQxLQ


https://www.51cto.com/article/817857.html![]() https://www.51cto.com/article/817857.html
https://www.51cto.com/article/817857.html
20250610

https://www.51cto.com/article/817742.html![]() https://www.51cto.com/article/817742.html
https://www.51cto.com/article/817742.html
20250609
setup 参数
使用setup 时,它将接收两个参数:props 和 context 。
3.1、props
第一个参数是 props ,表示父组件给子组件传值,props 是响应式的,当传入新的 props 时,自动更新。
export default{
props: {
msg: String,
ans: String,
},
setup(props,context){
console.log(props);//Proxy {msg: "着急找对象", ans: "你有对象吗?"}
},
} 因为 props 是响应式的,不能使用 ES6 解构,直接使用使用 ES6 解构会消除prop的响应特性,此时需要借用 toRefs 解构。示例8:
import { toRefs } from "vue";
export default{
props: {
msg: String,
ans: String,
},
setup(props,context){
console.log(props);
const { msg,ans } = toRefs(props)
console.log(msg.value); //着急找对象
console.log(ans.value); //你有对象吗?
},
} 使用组件时,经常会遇到可选参时,有些地方需要传递某个值,有些时候不需要,该如何处理呢?
如果 ans 是一个可选参数,则传入 props 中可能没有 ans 。在这种情况下 toRefs 将不会为 ans 创建一个 ref ,需要使用 toRef 代替它。
import { toRef } from "vue";
setup(props,context){
let ans = toRef(props ,'ans')// 不存在时,创建一个ans
console.log(ans.value);
} context
context 上下文环境,其中包含了 属性、插槽、自定义事件三部分。
复制
setup(props,context){
const { attrs,slots,emit } = context
// attrs 获取组件传递过来的属性值,
// slots 组件内的插槽
// emit 自定义事件 子组件
}
attrs 是一个非响应式对象,主要接收 no-props 属性,经常用来传递一些样式属性。
slots 是一个 proxy 对象,其中 slots.default() 获取到的是一个数组,数组长度由组件的插槽决定,数组内是插槽内容。
setup 内不存在this,所以 emit 用来替换 之前 this.$emit 的,用于子传父时,自定义事件触发。
示例9:
<template>
<div :style="attrs.style">
<slot></slot>
<slot name="hh"></slot>
<button @click="emit('getVal','传递值')">子向父传值</button>
</div>
</template>
<script>
import { toRefs,toRef } from "vue";
export default{
setup(props,context){
const { attrs,slots,emit } = context
// attrs 获取组件传递过来 style 属性
console.log('slots',slots.default());//插槽数组
console.log('插槽属性',slots.default()[1].props); //获取插槽的属性
return{
attrs,
emit
}
},
}
</script> https://www.51cto.com/article/693215.html![]() https://www.51cto.com/article/693215.html
https://www.51cto.com/article/693215.html
计算属性需要传入一个参数怎么写呢?
复制
<template>
<div>
<div v-for="(item,index) in arr" :key="index" @click="sltEle(index)">
{{item}}
</div>
</div>
</template>
<script>
import { ref, computed,reactive } from "vue"
export default{
setup(){
const arr = reactive([
'哈哈','嘿嘿'
])
const sltEle = computed( (index)=>{
console.log('index',index);
})
return{
arr,sltEle
}
}
}
</script>
直接这样写,运行的时候,出现错误:Uncaught TypeError: $setup.sltEle is not a function。
原因:
computed 计算属性并没有给定返回值,我们调用的是一个函数,而 computed 内部返回的并不是一个函数,所以就会报错:sltEle is not a function。
解决办法:
需要在计算属性 内部返回一个函数。修改代码如下:
const sltEle = computed( ()=>{
return function(index){
console.log('index',index);
}
}) https://www.51cto.com/article/694187.html https://www.51cto.com/article/694187.html
https://www.51cto.com/article/694187.html
20250605
Java 中 JSON 字段不固定怎么搞序列化?
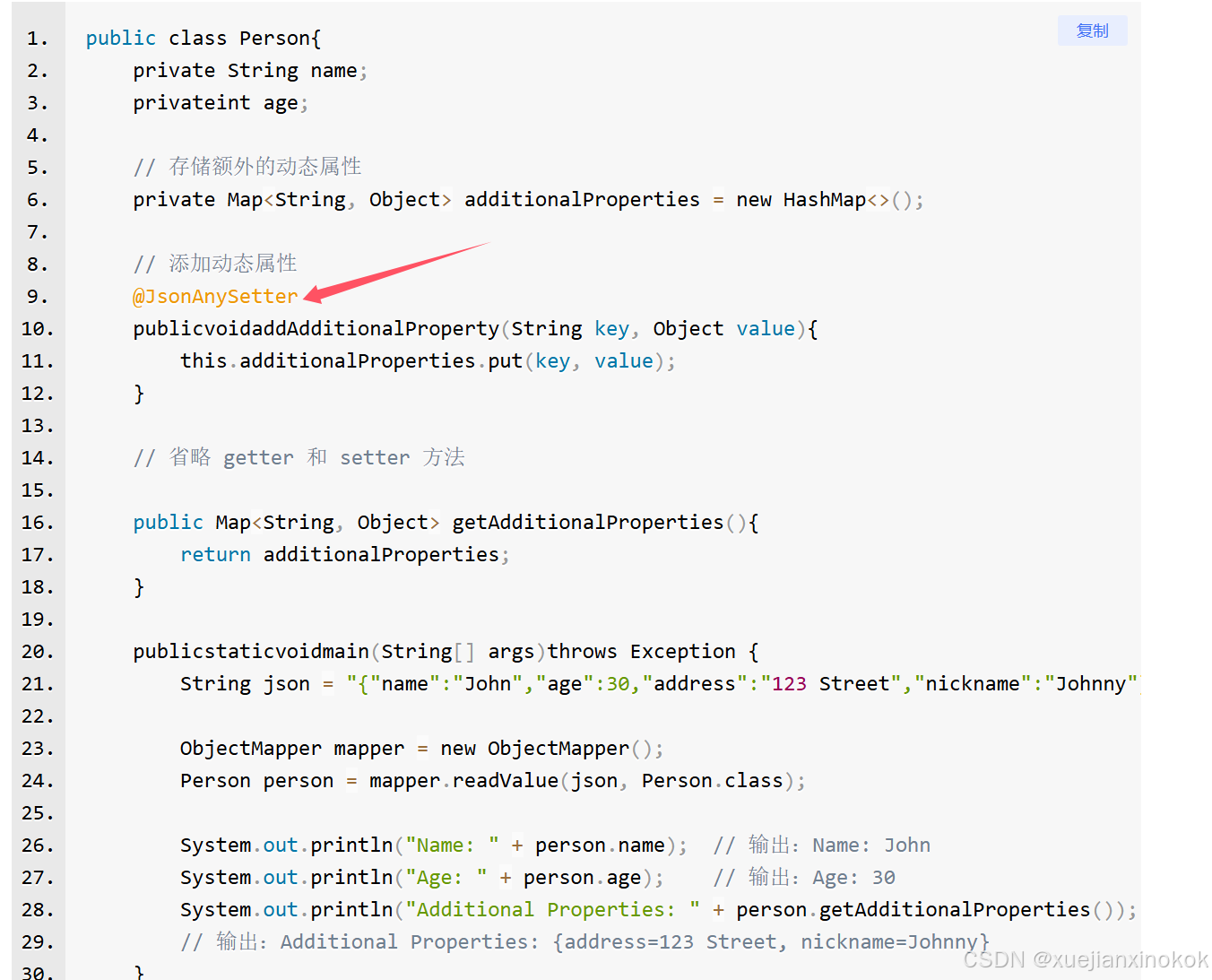
初我以为只能通过 Map 手动解析,但后来发现 Jackson 提供了 @JsonAnyGetter 和 @JsonAnySetter 这两个注解,专门用来处理这种“动态属性”。它们能让我优雅地把未知字段收集起来或者序列化出去,不影响已知字段的正常处理。
@JsonAnySetter 用于标注一个方法,该方法可以接收 JSON 中没有预定义的属性。当 Jackson 反序列化 JSON 时,如果遇到未在 Java 类中显式定义的字段,它会调用这个方法并将字段名和字段值作为参数传递给它。
当你在反序列化 JSON 时,不希望显式定义所有的字段,或者 JSON 中包含了动态的属性时,使用 @JsonAnySetter 可以自动将这些字段添加到一个 Map 或类似的结构中。
@JsonAnyGetter 用于标注一个方法,该方法返回一个 Map 或类似结构,它将包含对象的 动态属性(即对象中没有显式定义的字段)。当 Jackson 序列化对象时,它会将这个 Map 中的键值对当作额外的 JSON 属性来序列化。
当你有一个类,但是它可能会接受动态的字段,或者一些额外的键值对时,使用 @JsonAnyGetter 允许你将这些额外的字段序列化为 JSON。
https://www.51cto.com/article/817072.html![]() https://www.51cto.com/article/817072.html
https://www.51cto.com/article/817072.html
20250521
20250516
微服务只有在面临真正的扩展瓶颈、庞大的团队或独立演进的领域时才有价值。
微服务是一种扩展工具,而不是起始模板。
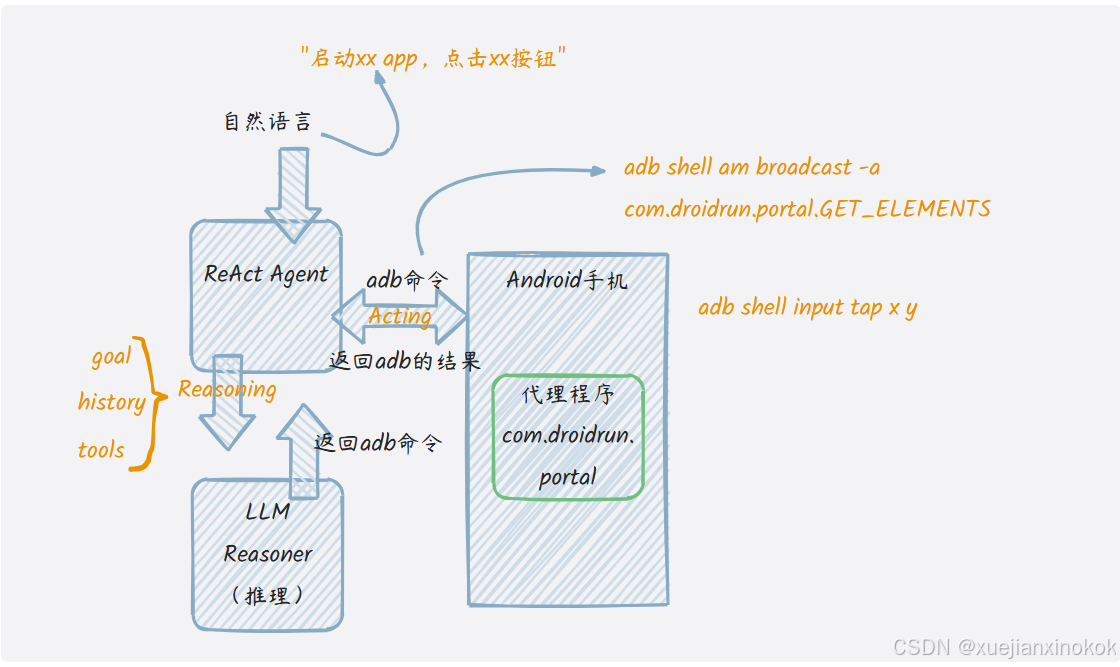
完成任务的过程是Reasoning(推理)和Acting(行动)的循环
step1.用户把自己的目标以自然语言告诉ReAct Agent(ReAct是Reasoning and Acting的缩写)
Step2.ReAct Agent把目标、历史和可用的工具告诉大模型,让大模型进行推理如何才能完成目标。
Step3.大模型经过推理,告诉ReAct Agent要实现A目标必须先采取B动作
Step4.ReAct Agent执行B动作,并把上一轮的推理过程,以及执行B动作的结果保存到历史当中
Step5.ReAct Agent把目标(没变)、历史(更新了)和可用的工具(没变)再次传给大模型,大模型据此作出下一步的指示。
为什么大模型(LLM)可以控制手机 – 韩师傅就是我![]() http://hanzilu.com/wordpress/?p=376
http://hanzilu.com/wordpress/?p=376
20250506
CAP理论
CAP理论是分布式架构中重要理论:
- 一致性(Consistency):所有节点在同一时间具有相同的数据;
- 可用性(Availability) :保证每个请求不管成功或者失败都有响应;
- 分隔容忍(Partition tolerance) :系统中任意信息的丢失或失败不会影响系统的继续运作。
关于 P 的理解,我觉得是在整个系统中某个部分,挂掉了,或者宕机了,并不影响整个系统的运作或者说使用,而可用性是,某个系统的某个节点挂了,但是并不影响系统的接受或者发出请求。
CAP 不可能都取,只能取其中2个的原因如下:
- 如果C是第一需求的话,那么会影响A的性能,因为要数据同步,不然请求结果会有差异,但是数据同步会消耗时间,期间可用性就会降低。
- 如果A是第一需求,那么只要有一个服务在,就能正常接受请求,但是对于返回结果变不能保证,原因是,在分布式部署的时候,数据一致的过程不可能想切线路那么快。
- 再如果,同时满足一致性和可用性,那么分区容错就很难保证了,也就是单点,也是分布式的基本核心。
- CAP 理论的取舍:
-
- Eureka 是典型的 AP,Nacos可以配置为 AP,作为分布式场景下的服务发现的产品较为合适,服务发现场景的可用性优先级较高,一致性并不是特别致命。
- 而Zookeeper、Etcd、Consul则是 CP 类型牺牲可用性,在服务发现场景并没太大优势;
用CAP理论来解释各个注册中心的区别-腾讯云开发者社区-腾讯云注册中心在分布式应用中是经常用到的,也是必不可少的,那注册中心,又分为以下几种:eureka(springcloud推荐的),zookeeper(与dubbo无缝结合),consul(HashiCorp开源),nacos(阿里开源的);https://cloud.tencent.com/developer/article/1616347
20200430
Kafka生产环境实战经验深度总结
https://www.51cto.com/article/814456.htmlhttps://www.51cto.com/article/814456.html
20250423
C 语言没有类也没有继承的特性,是通过结构体里的内存是连续的这一特点来实现“继承”的效果。将要继承的“父类”,放到结构体的第一位,然后通过结构体名的长度来强行截取内存,这样就能转换结构体,从而实现类似“继承”的效果。

深入 Linux 内核理解 socket 的本质
https://www.51cto.com/article/813803.html![]() https://www.51cto.com/article/813803.html
https://www.51cto.com/article/813803.html
easy-captcha 验证码
SpringBoot 3 接口防刷的八种高效解决方案
https://www.51cto.com/article/813130.html
RabbitMQ的架构设计
https://www.51cto.com/article/813176.html
Spring Boot 3 新特性全解析
https://www.51cto.com/article/813401.html
Spring Boot 3 对配置文件进行了改进,引入了新的配置属性和更灵活的配置方式。例如,现在可以使用 application.yaml 文件中的 spring.config.import 属性来导入其他配置文件,从而实现配置的模块化管理。
复制
# application.yaml
spring:
config:
import: "optional:classpath:modules/module1.yaml"
这种模块化的配置方式使得我们的配置文件更加清晰和易于管理。我们可以将不同的配置项分开到不同的文件中,然后在主配置文件中导入它们。
Apache Calcite 是一个开源的动态数据管理框架,它本身并不是数据库,而是一个提供 SQL 查询解析、验证、优化和执行的中间层框架,支持对多种数据源进行统一访问。其核心特性包括:
多数据源支持支持关系型数据库、CSV、JSON、MongoDB、Elasticsearch 等多种数据源。
SQL 引擎具备完整的 SQL 解析、校验、优化和执行能力。
虚拟化查询可将非结构化或半结构化数据通过 schema 建模为结构化视图。
可插拔架构支持自定义函数、自定义规则、插件式架构。
https://www.51cto.com/article/813381.html
在 MySQL 8.2 中,主库默认使用 InnoDB 存储引擎,这是 MySQL 中最常用的存储引擎,支持事务、行级锁、外键等特性,适合处理写操作频繁的业务。而从库则可以使用 MyRocks 存储引擎,MyRocks 是基于 RocksDB 开发的存储引擎,在读取性能和压缩比方面表现出色,适合处理读操作频繁的业务。
https://www.51cto.com/article/813831.html![]() https://www.51cto.com/article/813831.html
https://www.51cto.com/article/813831.html
20250402
使用PyTorch和Hugging Face构建一个自动语音识别系统
https://www.51cto.com/article/812162.html![]() https://www.51cto.com/article/812162.html
https://www.51cto.com/article/812162.html
20250327
Hugging Face 模型格式大揭秘:从 PyTorch 到 GGUF,一文搞懂!
在 Hugging Face 上,模型主要有以下几种格式:
- PyTorch 格式
- TensorFlow 格式
- Flax(JAX)格式
- SafeTensors 格式
- ONNX 格式
- GGUF 格式
https://www.51cto.com/article/811648.html![]() https://www.51cto.com/article/811648.html
https://www.51cto.com/article/811648.html
20250324
这篇 GPU 学习笔记,详细整理了其工作原理、编程模型和架构设计
https://www.51cto.com/article/811345.html![]() https://www.51cto.com/article/811345.html
https://www.51cto.com/article/811345.html
20250306
数学家弗朗西斯·高尔顿通过分析 1078 对父亲与儿子的身高数据,发现了一个有趣的现象,儿子的身高倾向于“回归”到父亲身高的平均值,而不是完全继承父亲的极端身高。他将这种现象称为回归效应(Regression to the Mean),并基于此建立了线性关系模型 y=33.73+0.516x,用于预测子女的身高。其中,x表示父亲的身高,y表示儿子的身高。回归问题很多模型都已做,比如如线性回归、svm、树模型。
20250228
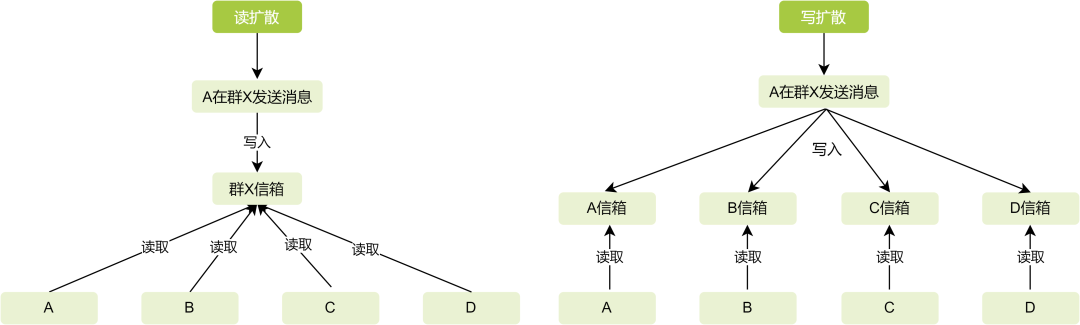
群聊消息的保存方式,主流有2种方式:读扩散、写扩散。图1展示了它们的区别,区别就在于消息是写一次还是写N次,以及如何读取。
读扩散就是所有群成员共用一个群信箱,当一个群产生一条消息时,只需要写入这个群的信箱即可,所有群成员从这一个信箱里读取群消息。
优点是写入逻辑简单,存储成本低,写入效率高。缺点是读取逻辑相对复杂,要通过消息表与其他业务表数据聚合;消息定制化处理复杂,需要额外的业务表;可能还有IO热点问题。
举个例子:
很常见的场景,展示用户对消息的已读未读状态,这个时候公共群信箱就无法满足要求,必须增加消息已读未读表来记录相关状态。还有用户对某条消息的删除状态,用户可以选择删除一条消息,但是其他人仍然可以看到它,此时也不适合在公共群信箱里拓展,也需要用到另一张关系表,总而言之针对消息做用户特定功能时就会比写扩散复杂。
写扩散就是每个群成员拥有独立的信箱,每产生一条消息,需要写入所有群成员信箱,群成员各自从自己的信箱内读取群消息。优点是读取逻辑简单,适合消息定制化处理,不存在IO热点问题。缺点是写入效率低,且随着群成员数增加,效率降低;存储成本大。
所以当单群成员在万级以上时,用写扩散就明显不太合适了,写入效率太低,而且可能存在很多无效写入,不活跃的群成员也必须得有信箱,存储成本是非常大的,因此采用读扩散是比较合适的。
据了解,微信是采用写扩散模式,微信群设定是500人上限,写扩散的缺点影响就比较小。
20250221
ES2025 爆款新特性,让开发效率翻倍
Pattern Matching(模式匹配)
类似 Rust 的强大模式匹配特性终于来到 JavaScript。
复制
const response = await fetch('/api/data');
const result = match (response) {
case { status: 200, data } => handleSuccess(data),
case { status: 404 } => handleNotFound(),
case { status } if status >= 500 => handleServerError(),
default => handleUnknownError()
};Type Annotations(类型注解)
原生支持类型注解,无需 TypeScript。

优势:
- 无需额外编译步骤
- 与 TypeScript 完全兼容
- 运行时类型检查
- 更好的 IDE 支持
4. Smart Pipeline Operator(智能管道操作符)
支持更复杂的管道操作。

使用场景:
- 数据转换
- 函数组合
- 流处理
- 链式操作
5. Exception Groups(异常组)
更强大的错误处理机制。

优势:
- 更精细的错误处理
- 支持多异常捕获
- 更好的异步错误处理
6. Record & Tuple(记录和元组)
不可变数据结构的原生支持。

应用:
- 状态管理
- 不可变数据处理
- 高性能比较操作
- 函数式编程
7. Block Params(块参数)
更灵活的代码块组织。
复制
array.forEach do |item, index| {
console.log(`${index}: ${item}`);
}
function process() do |cleanup| {
// 主要逻辑
cleanup(() => {
// 清理代码
});
}责任编辑:赵宁宁来源: JavaS
https://www.51cto.com/article/808643.html![]() https://www.51cto.com/article/808643.html
https://www.51cto.com/article/808643.html
20250213
@Conditional注解通常与@Configuration和@Bean注解一起使用,以标记那些需要条件化创建的Bean。在Spring Boot中,@Conditional注解更是被广泛应用,衍生出了如@ConditionalOnProperty、@ConditionalOnBean、@ConditionalOnClass等多个便捷的条件注解,进一步简化了条件配置的过程。
https://www.51cto.com/article/807920.html
20250211
分布式缓存技术
为什么选择Hazelcast
大家在平常写代码用缓存的时候是不是要么是内存缓存,要么是redis的缓存?像内存缓存那种,最大的好处是不用去搭建什么缓存中间件,引入个jar包就能直接用了,缺点也很明显,分布式环境下内存只是单机的不能多个实例共享。redis那种好处就是解决了内存的不共享的问题,缺点也很明显,配置复杂还需要服务器啥的比较复杂。
有没有一个中间件能既可以用于分布式缓存,又不用搭建服务器就可以使用的呢?当然有,最近小编接触到了一个分布式缓存工具,结合了上面说的两大特性,感觉很牛逼,接下来给大家介绍一下:
Redis和Hazelcast进行了效率的对比,红色是Redis,蓝色是Hazelcast,根据结果。Redis在低数据负载的时候响应比 Hazelcast 表现更好,而在数据负载和并发请求增加时则表现相反。
1.5.1传统的数据一致性方案
数据是软件系统的核心,在传统的架构中,通常使用关系型数据库存储并提供数据访问服务。应用程序直接和数据交互,数据库在另外的机器上通常存在一个备份。为了提高性能,需要对数据库调优或购买更高性能的服务器,这需要大量的投资和努力。
架构通常的做法是在更加靠近数据库的地方保存一份数据的备份,通常采用外部K-V存储技术或二级缓存来降低数据库访问压力。然而,当数据的性能达到极限或应用程序更多的请求是写请求时,这种方案对降低数据库的访问压力无能为力,因为不管是K-V存储还是二级多级缓存方案都只能降低数据库读压力。即便应用程序大多数是读请求,上述方案也有很多问题:当数据变化后,对缓存的影响是什么,缓存如何处理数据变化(目前公司的项目也在考虑方案解决整个问题),在这种条件下缓存存活时间(TTL)和直写缓存(Write-through )的概念诞生了。
考虑TTL的情况,如果访问的频率比TTL更低(TTL=30s,每次请求间隔35S),则每次访问的数据都不在缓存中,都需要从数据库读取数据,缓存每次都被穿透。另一方面,考虑直写缓存场景,如果集群中缓存的数据有多份,同样会面临数据一致性问题。数据一致问题可以通过节点间的互相通信解决,当一个数据不可用时,该消息可以在集群内的节点之间传播。
基于TTL和直写缓存可以设计一个理想的缓存模型,在该领域已经有缓存服务器和内存数据库等。然而,这些解决方案都是具有由其他技术提供的分布式机制的独立的单机实例(本质不是分布式集群,只是通过其他技术附加了集群特性)。回到问题的起点,如果产品是单节点,或者发行版没有提供一致性,总有一天会遇到容量问题。
1.5.2Hazelcast的一致性解决方案
围绕分布式思想设计的Hazelcast提供一种全新访问处理数据的方法。为了提高灵活性和性能,Hazelcast在集群周围共享数据。Hazelcast基于内存的数据网格为分布式数据提供集群和高可扩展性。
集群无主节点是Hazelcast的一个主要特性,从功能上来讲,集群内每个节点都被配置为对等。第一个加入集群的节点负责管理集群内其他所有节点,例如数据自动平衡、分区表更新广播。如果第一个节点下线,第二个加入集群的节点负责管理集群其他节点。
Hazelcast原理及使用-阿里云开发者社区Hazelcast原理及使用![]() https://developer.aliyun.com/article/1321536
https://developer.aliyun.com/article/1321536
20250210
大白话说清楚DeepSeek的蒸馏技术到底是什么?
LLM蒸馏是一项使大型语言模型更实用、更高效的关键技术。通过将复杂教师模型的关键知识转移到较小的学生模型,蒸馏在减少尺寸和计算需求的同时保留了性能。
这一过程使得在各个行业(从实时NLP任务到医疗保健和金融等专业用例)中实现更快、更易于访问的人工智能应用成为可能。实现LLM蒸馏需要精心规划和合适的工具,但好处——例如降低成本和更广泛的部署——是巨大的。
20250206
利用数据库 LOAD DATA 特性实现数据批量写入
例如,在 MySQL 中,LOAD DATA的基本语法如下:
复制
LOAD DATA [LOCAL] INFILE 'file_name'
INTO TABLE table_name
[FIELDS TERMINATED BY 'field_separator' [OPTIONALLY] ENCLOSED BY 'enclosure_character']
[LINES TERMINATED BY 'line_separator']
[IGNORE number LINES]
[(column_list)]其中,file_name是包含要导入数据的文本文件路径;table_name是目标数据库表;FIELDS TERMINATED BY指定字段之间的分隔符;LINES TERMINATED BY指定行之间的分隔符;IGNORE number LINES表示忽略文件开头的指定行数;(column_list)指定要导入数据对应的表列。
实现
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.demo.mapper.UserMapper">
<insert id="batchInsertByLoadData">
LOAD DATA LOCAL INFILE '/path/to/your/data/file.txt'
INTO TABLE user
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
(id, name, age)
</insert>
</mapper>20250205
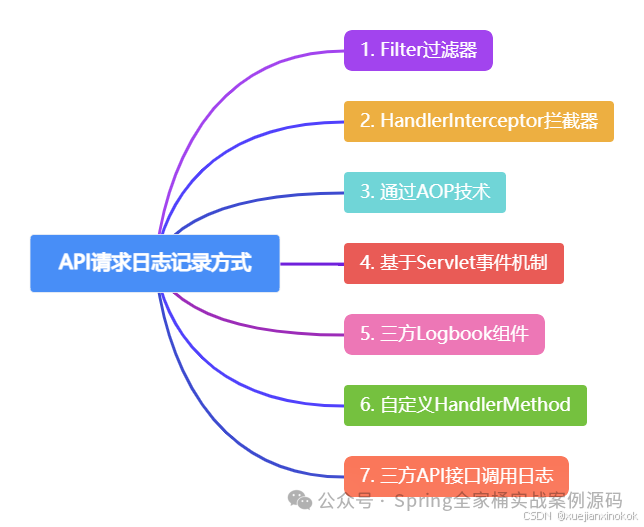
Spring Boot 记录Controller接口请求日志七种方式
注意
CommonsRequestLoggingFilter
默认情况下,当一个请求到达后,Spring MVC底层会发布一个事件ServletRequestHandledEvent,我们只需要监听该事件也是可以获取到详细的请求/响应信息。https://www.51cto.com/article/807227.htmlhttps://www.51cto.com/article/807227.htmlhttps://www.51cto.com/article/807227.html
20250109
限制分割次数
split 方法的第二个参数 limit 可以限制返回数组的长度。在处理一些日志或长文本时,我们可能只想要前几段内容,后续内容可以忽略。这时 limit 就派上用场了。
'section1ABsection2CDsection3'.split(/(AB|CD)/, 3);
// 结果:['section1', 'AB', 'section2']在这个例子中,我们用 limit 限制了数组长度为 3,因此 split 从第一个匹配位置分割,并在达到限制长度后停止,剩下的部分被忽略。这种用法对于需要提取特定部分内容时很实用,比如只保留标题和前两段描述。
JavaScript 里的??(空值合并运算符)看起来和我们之前聊过的||有点像,但它其实更“挑剔”!如果说||是遇到假值就找备胎,那么??只会在 null 和 undefined 出现时才出手救场。
?? 操作符的工作方式是:当左边的值是 null 或 undefined 时,才返回右边的备用值。像 0、false、"" 这些“假值”,在??眼里都是 有效值,它们不会触发备用计划。
20250106
短轮询就像一列严格按照时刻表发车的火车——无论是否有乘客,都会以固定的时间间隔离开车站。另一方面,WebSockets 就像有一条随时准备运送乘客的专用火车线路。
长轮询 像一列火车在车站等待,直到至少一名乘客上车后才出发。如果在一定时间(TTL)内没有乘客出现,那么它才会空着。这种方法可以让您两全其美 - 有数据(乘客)时立即出发,无数据时有效利用资源。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









