






Understanding LLMs: A Simple Guide to Large Language Models
理解LLMs:大型语言模型的简单指南
Osman Recai Ödemis 奥斯曼·雷卡伊·奥德米斯
19 min read
Hello, passionate learners from around the world ✌️
嗨,来自世界各地的热情学习者✌️
In 2023 ChatGPT from OpenAI reached 100 million users faster than other solutions in Web 2.0 era.
2023 年,OpenAI 的 ChatGPT 比 Web 2.0 时代的其他解决方案更快地达到 1 亿用户。
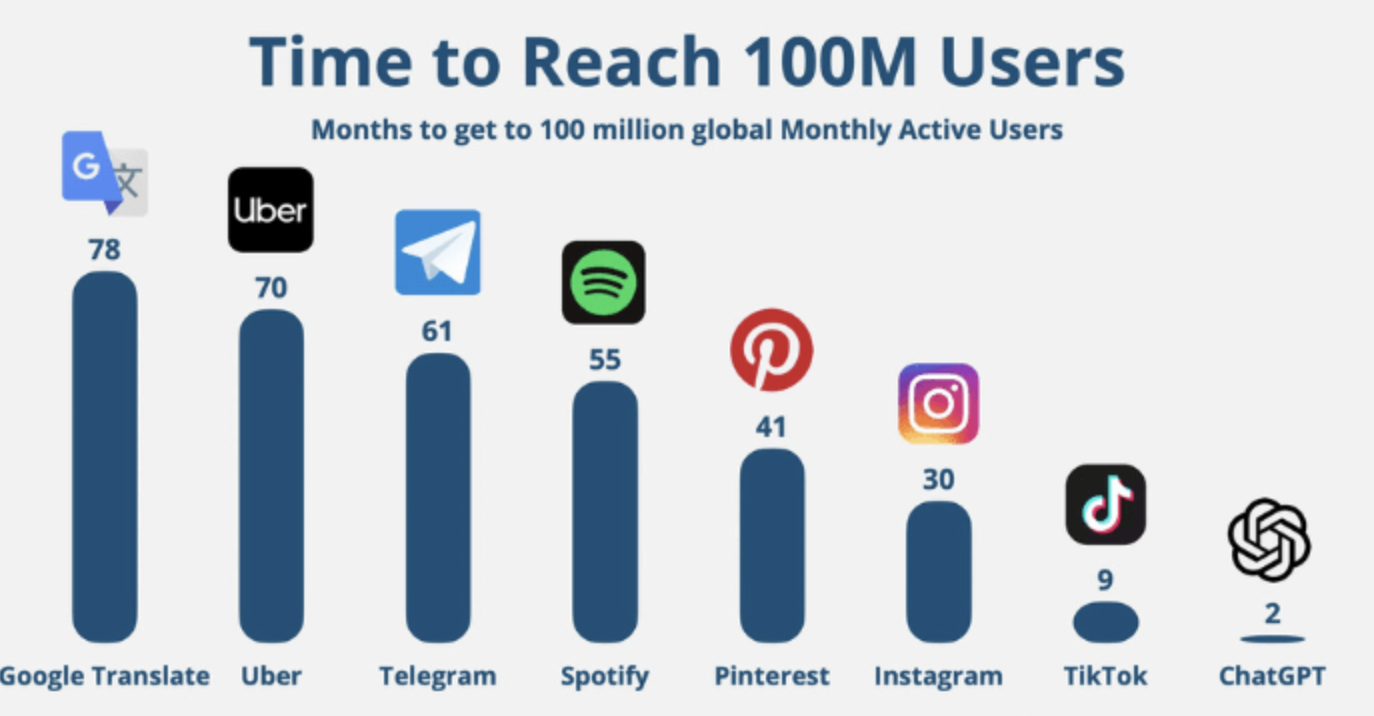
Source: Yahoo Finance
And since then many intelligent models from Anthropic, Cohere, IBM, Goole, Amazon, Meta AI, DeepSeek, HuggingFace come up and also many startups entering the arena. It’s interesting times to invest in our skillset.
从那时起,Anthropic、Cohere、IBM、Goole、Amazon、Meta AI、DeepSeek、HuggingFace等许多智能模型应运而生,许多初创公司也纷纷进入该领域。现在是投资学习这些技能的好时机。
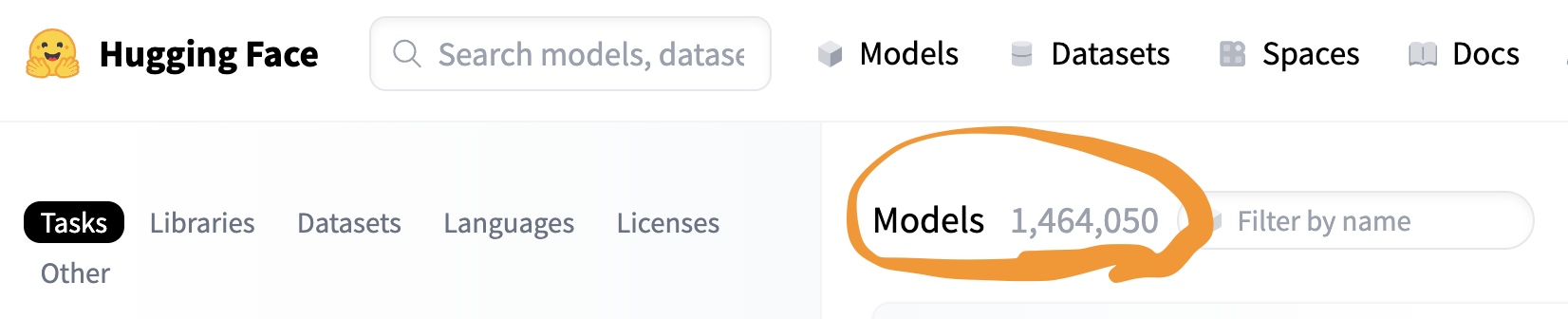
Platforms like HuggingFace—the GitHub of AI—serving as open hubs where an entire ecosystem of researchers and developers collaborate to share, fine-tune, and deploy AI models across the spectrum from natural language processing to computer vision. The scale is here 1.4 million models already deployed, with new breakthroughs arriving weekly.
HuggingFace等平台(AI 的 GitHub)充当开放中心,整个生态系统的研究人员和开发人员在此协作,共享、微调和部署从自然语言处理到计算机视觉等各个领域的 AI 模型。目前已部署的模型规模达到 140 万个,每周都有新的突破出现。
In this blog post, I will try to give a overview of the key components of Large Language Models (LLMs) at a high level, focusing on basic concepts, minimal math, and visual explanations to make complex ideas easy to understand.
在这篇博文中,我将尝试从高层次概述 大型语言模型 (LLMs) 的关键组件,重点介绍基本概念、最少的数学知识和视觉解释,以使复杂的想法变得易于理解。
Why This Actually Matters
为什么这很重要
Understanding model architecture isn’t just academic. Fine-tuning models, interpreting model cards, and selecting the right model for specific tasks like todays popular agentic architectures can imply the difference between breakthrough performance, costly failures and maybe also security vulnerabilities.
理解模型架构不仅仅是学术上的。微调模型、读取模型说明和为特定任务选择正确的模型(如当今流行的代理架构)可能意味着突破性性能、代价高昂的故障以及可能的安全漏洞之间的差异。
These models are reshaping how we work, learn, and create—right now. Whether you’re an educator designing curriculum, a researcher, or simply curious about the technology transforming your daily life, invest in these fundamentals (I also put many resources at the end of the blog).
这些模型正在重塑我们的工作、学习和创造方式——就在此刻。无论您是设计课程的教育者、研究人员,还是只是对改变您日常生活的技术感到好奇,请投资这些基础知识(我在博客末尾也放了许多资源)。
The technology feels like magic, let’s explore together! 🤗
这项技术就像魔法一样,让我们一起探索吧!🤗
The Road to Generative AI: Key Milestones
生成式人工智能之路:关键里程碑
But first, lets start with a quick history of Artificial Intelligence. AI is a discipline with a vast history and many applications in the real world. Very inspiring development phase with amazing research and development breakthroughs. While AI encompasses many approaches, this guide focuses specifically on the architecture that’s changing everything: Transformers. The true inflection point came in 2017 with the publication of a paper titled: “Attention is all you need.” The work by Vaswani and his friends would fundamentally transform AI capabilities and set the stage for today’s generative revolution.
但首先,让我们先来简要回顾一下人工智能的历史。人工智能是一门历史悠久、在现实世界中应用广泛的学科。人工智能的发展阶段令人振奋,研究和开发取得了惊人的突破。虽然人工智能涵盖了许多方法,但本指南特别关注改变一切的架构: Transformers 。真正的转折点出现在 2017 年,当时发表了一篇题为“Attention is all you need.和他的朋友们的工作将从根本上改变人工智能的能力,并为今天的生成革命奠定基础。

AI Language Modeling 人工智能语言建模
Language models are fundamentally about understanding deep connections between words, concepts, and context—similar to how our own brains process language.
语言模型从根本上讲是关于理解词语、概念和上下文之间的深层联系——类似于我们大脑处理语言的方式。
Imagine two friends chatting:
想象一下两个朋友聊天:
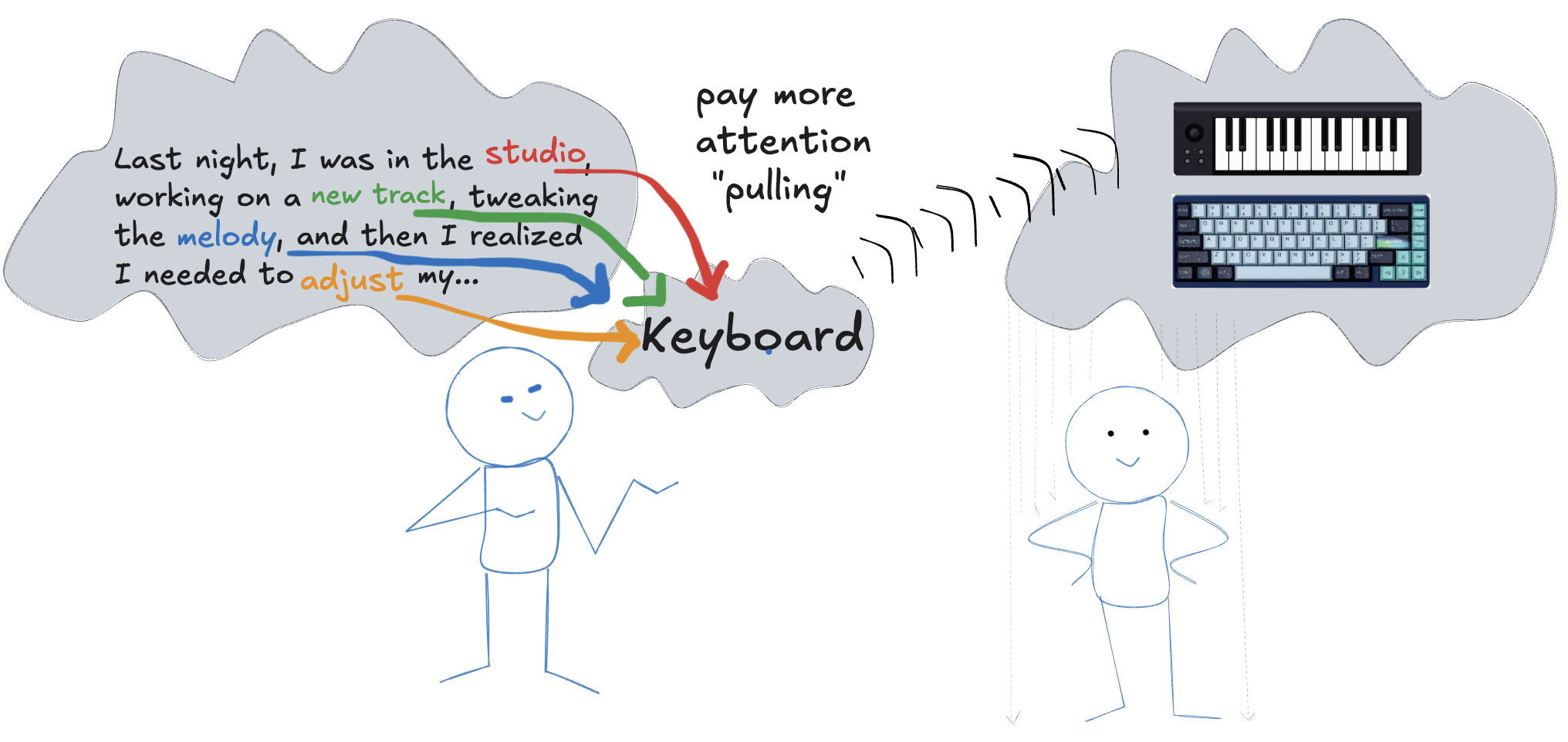
Person 1 (speaking): 第一个人(讲话者):
"Last night, I was in the studio*, working on a* new track*, tweaking the* melody*, and then I realized I needed to* adjust my…"
“昨晚,我在录音室,创作新曲目,调整旋律,然后我意识到我需要调整我的……”
At this moment, Person 1 own thought process is already being pulled toward a specific word before they even say it. Their mind is influenced by the words they just used—“studio,” “track,” “melody,” and “adjust”—making **“keyboard 🎹 **” feel like the most natural next word.
此时,第 1 个人的思维过程在说出某个特定词语之前就已被拉向该词语。他们的思维受到他们刚刚使用的词语的影响*——“工作室”、“曲目”、“旋律”和“调整”* ——使得“键盘🎹” 感觉是最自然的下一个词语。
Person 2 (listening): 第二个人(聆听者):
As Person 1 speaks, Person 2 is in thinking/listening mode, but what Person 2 expects depends on both Person 1’s words and their own mental associations. Person 2’s interpretation is influenced by Person 1’s context 🎹.
当第 1 个人说话时,第 2 个人处于思考/聆听模式,但第 2 个人的期望取决于第 1 个人的话语和他们自己的心理联想。第 2 个人的解释受到第 1 个人所处环境的影响🎹。
Just like in LLM’s, similarity helps pull related concepts together—such as how “melody” and “track” reinforce the idea of music—while attention helps focus on the most relevant words, filtering out less important information to determine meaning.
就像在 LLM 中一样,
相似性有助于将 相关概念联系在一起(例如“旋律”和“曲目”如何强化音乐的概念),
而注意力则有助于将注意力集中在最相关的单词上,过滤掉不太重要的信息以确定含义。
The Secret Sauce of LLMs: Similarity + Attention
LLMs 的秘诀:相似性 + 注意力
This human conversation mirrors how LLMs work:
这种人类对话反映了工作方式:
-
Similarity creates connections between related concepts—just as “melody” and “track” naturally point toward music-related completions.
相似性在相关概念之间建立了联系——就像“旋律”和“曲目”自然地指向与音乐相关的完成。 -
Attention helps filter out noise and focus on what matters most—determining which earlier words are most important for predicting what comes next.
注意力有助于过滤噪音,集中注意力于最重要的事情——确定哪些先前的单词对于预测接下来的内容最重要。
Next-Word Prediction: The Core Task
预测下一个token:核心任务
Like the example with above, at its heart, a Large Language Model has one fundamental job: “next token prediction.”
与上面的例子一样,大型语言模型的核心是一项基本任务: “预测下一个token”。
These sophisticated systems learn patterns from massive datasets to predict the next token in a sequence. When you type “Which move in AlphaGo was surprising?” the model:
这些复杂的系统从海量数据集中学习模式,以预测序列中的下一个标记。当您输入“AlphaGo 中的哪一步令人惊讶?”时,模型:
-
Processes your prompt 处理你的提示
-
Calculates probabilities for every possible next token
计算每个可能的下一个token的概率 -
Selects the most likely continuation (or samples from high-probability options)
选择最有可能的延续(或从高概率选项中抽样) -
Repeats until it reaches a natural stopping point
重复,直到到达自然停止点
The process continues word by word until the model decides to end the sequence, producing something like: “The most surprising move was 37”
该过程逐字逐句地继续进行,直到模型决定结束该序列,产生类似这样的结果: “最令人惊讶的动作是 37”
This simple mechanism—predicting one token at a time based on everything that came before—is the foundation for Large Language models, that can now write essays, code, stories, and even simulate conversations.
这种简单的机制——根据之前出现的所有内容一次预测一个token——是大型语言模型的基础,现在可以编写文章、代码、故事,甚至模拟对话。
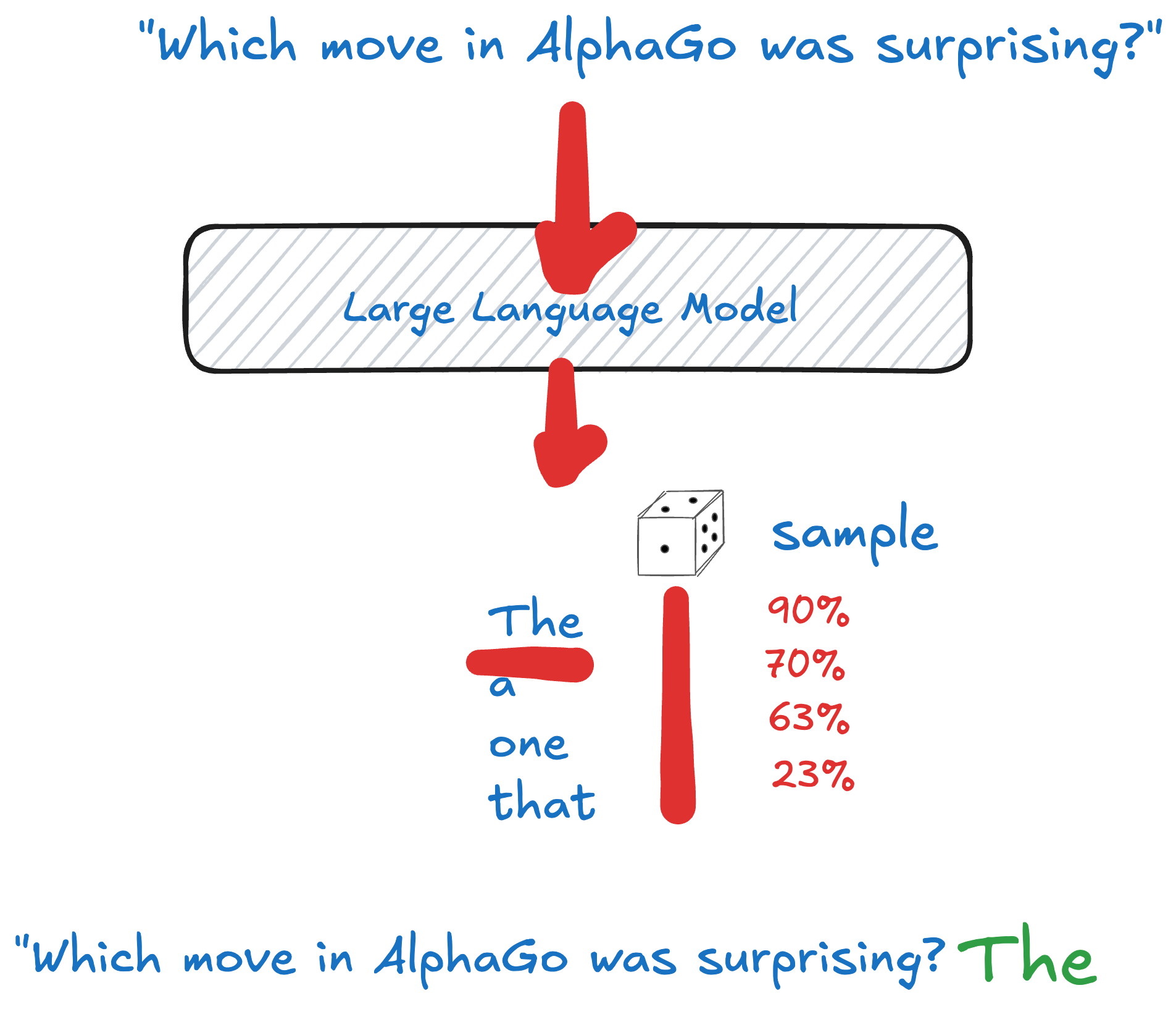
The complete sequence goes on, until the LLM decides, to bring a special token like |EOS| “End of Sequence” and the answer ends with “The most surprising move was 37” like.
完整的序列继续进行,直到 LLM 决定输出一个特殊标记,如|EOS| "序列结束” ,答案是“最令人惊讶的步骤是 37”。
*The complete flow illustrated:
完整流程如下:*
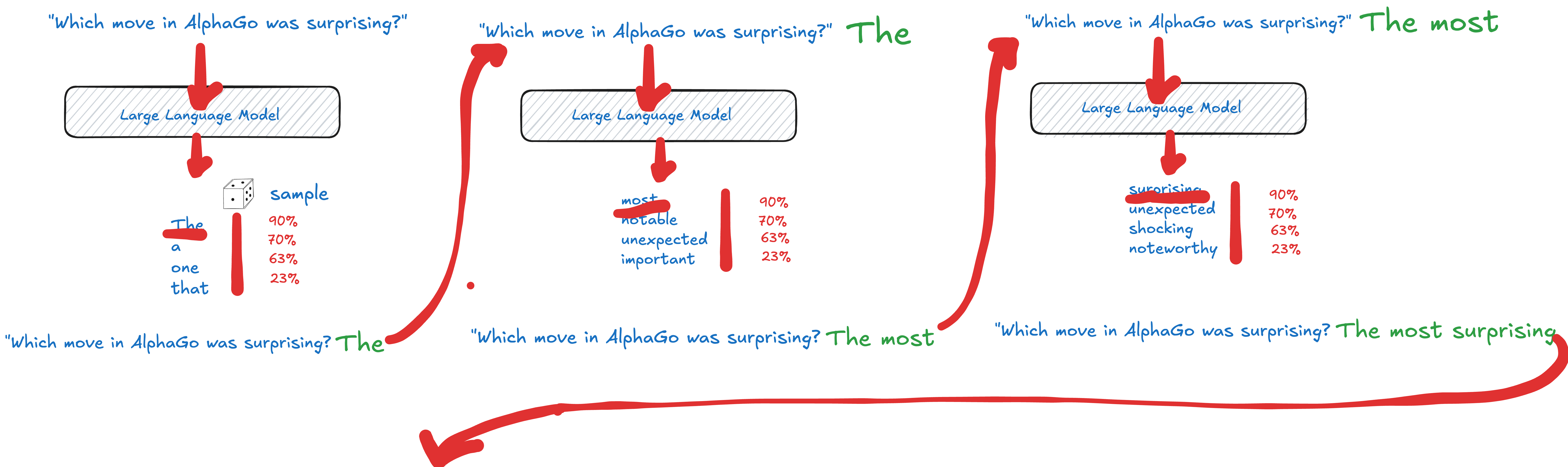

The Journey to an LLM artifact
训练LLM的过程
We can imagine these models as a compressed ZIP file of internet data. It contains the so-called million or billion parameter weights (floating-point numbers), which during training are adjusted and learned.
我们可以把这些模型想象成互联网数据的压缩 ZIP 文件。它包含所谓的数百万或数十亿个参数权重(浮点数),这些权重在训练过程中会进行调整和学习。

To achieve such behavior, we require high-quality data, substantial computational power, memory, and extensive GPU clusters. Training these models is costly and time-consuming, often taking months. Not many companies can afford the millions of dollars needed to train a model from scratch.
为了实现这种行为,我们需要高质量的数据、强大的计算能力、内存和广泛的 GPU 集群。训练这些模型既昂贵又耗时,通常需要数月时间。没有多少公司能负担得起从头开始训练模型所需的数百万美元。
For example, Llama 3 from Meta AI was trained on 24,576 GPU clusters for months, and Meta’s Llama 4 is currently being trained on a cluster exceeding 100,000 NVIDIA H100 GPUs. DeepSeek R1 model is trained on a smaller set of GPUs but uses advanced architecture training, which I want to explain in further blog posts, called Reinforcement Learning. This huge computational requirement also raises sustainability concerns, one of the most important topics in training models. A very good session about GPU power consumption is available at the CCC.
例如,Meta AI 的Llama 3在 24,576 个 GPU 集群上训练了数月,而 Meta 的Llama 4目前正在超过100,000 个 NVIDIA H100 GPU 的集群上进行训练。DeepSeek R1 模型在一组较小的 GPU 上进行训练,但使用高级架构训练,我将在后续的博客文章中解释它,称为强化学习。这种巨大的计算需求也引发了可持续性问题,这是训练模型中最重要的主题之一。CCC 上有一个关于 GPU 功耗的非常好的会议。

Let’s take a quick journey through these training steps.
让我们快速了解一下这些训练步骤。
Data preparation 准备数据
Large Language Models are trained on a massive scale of internet data. I mean by large scale, trillions and billions of tokens. In the upcoming sections I’ll explain more about tokens. At the same time, we want large diversity and high-quality documents. One popular dataset is CommonCrawl. Common Crawl, a non-profit organization, has been crawling the web since 2007, and actually contains 2.7 billion web pages. If you are interested in a large scale data pipeline and a cleaned up dataset, look at the FineWeb project from HuggingFace.
大型语言模型是在海量互联网数据上进行训练的。我指的是大规模,数万亿甚至数十亿个 token。在接下来的部分中,我将更多地解释 token。同时,我们想要大量多样性和高质量的文档。一个流行的数据集是 CommonCrawl。Common Crawl 是一个非营利组织,自 2007 年以来一直在抓取网络,实际上包含 27 亿个网页。如果您对大规模数据管道和清理后的数据集感兴趣,请查看 HuggingFace 的FineWeb项目。
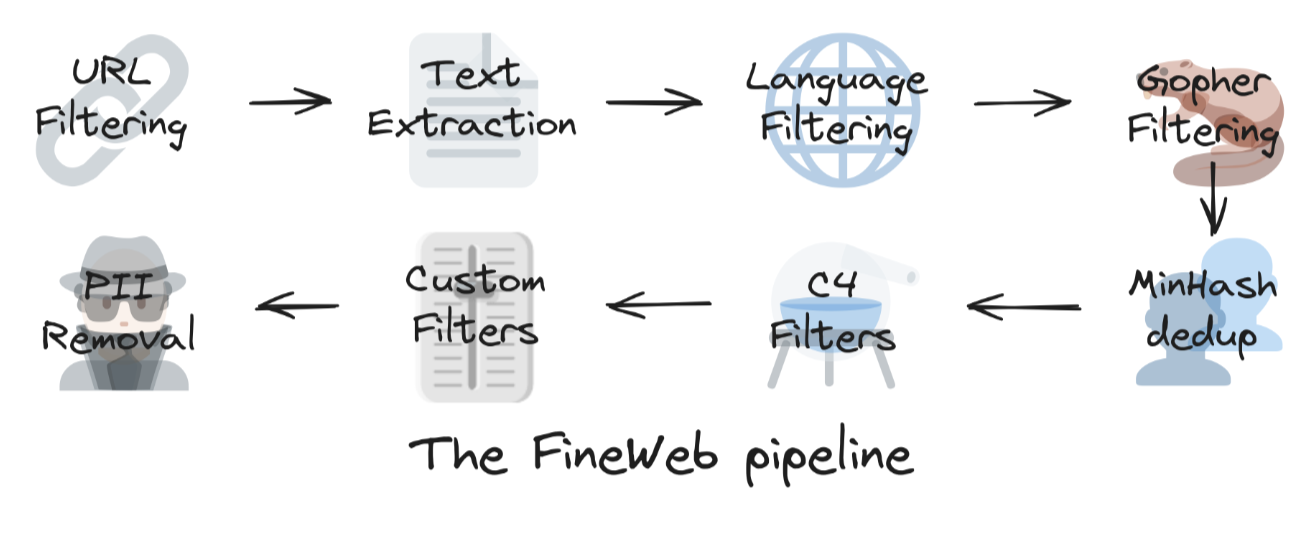
steps taken to produce FineWeb dataset for LLM training
生成 FineWeb 训练数据集所采取的步骤
I don’t want to go into the details of data engineering in this post, as it is about LLM concepts, but remember it’s trained on large diversity and high quality of data. To see the full pipeline visit FineWeb. Also worth mentioning you can explore some public datasets on atlas.nomic.ai and the diversity of the topics covered in the domains. Also HuggingFace Dataset is a good source to discover more datasets.
我不想在这篇文章中详细介绍数据工程,因为它涉及的是概念,但请记住,它是在大量多样性和高质量数据上进行训练的。要查看完整流程,请访问 FineWeb。另外值得一提的是,您可以在atlas.nomic.ai上探索一些公共数据集以及领域中涵盖的主题的多样性。此外, HuggingFace 数据集也是发现更多数据集的良好来源。

From Base Models to Chat Assistants
从基础模型到聊天助手
Next, we train a model for next token prediction. These models are also called base models, and their names typically end with “Base”, like Llama-3.1-405B-Base.
接下来,我们训练一个模型来预测下一个 token。这些模型也称为基础模型,其名称通常以“Base”结尾,例如Llama-3.1-405B-Base 。
However, these base models do not behave like ChatGPT or instruction-tuned models (e.g., Llama-3.1-405B-Instruct) that we experience through web interfaces.
然而,这些基础模型的行为并不像我们通过 Web 界面体验到的 ChatGPT 或指令调整模型(例如Llama-3.1-405B-Instruct )。
The base models are just the foundation - they can predict token incredibly well but lack the refined conversational abilities of the instruction-tuned versions that power consumer-facing AI assistants.
基础模型只是基础——它们可以非常好地预测token,但缺乏面向消费者的人工智能助手所具有的指令调整版本的精细对话能力。
For example if we prompt Llama-3.1-405B-Base with:
例如如果我们使用以下命令提示Llama-3.1-405B-Base :
**Prompt: "Which move in AlphaGo was surprising? **
提示:“AlphaGo 的哪一步棋令人惊讶?
we get following response sequence:
我们得到以下响应序列:
“Is it possible to explain it?" The following is a question I posed to the AlphaGo team, as part of an academic project: Which move in AlphaGo was surprising? Is it possible to explain it? AlphaGo’s moves are often surprising to human players, as they are based on a deep understanding of the game that is difficult for humans to replicate. One example of a surprising move made by AlphaGo……”
The base model artifacts are produced during the most costly phase: pre-training.
基础模型是在最昂贵的阶段生成的:预训练。
BUT: This is not what we want from an model. Most of the time we’re summarizing papers, translating sections, or generating content based on user questions or prompts.
但是:这不是我们想要的模型。大多数时候,我们都在总结论文、翻译部分内容或根据用户的问题或提示生成内容。
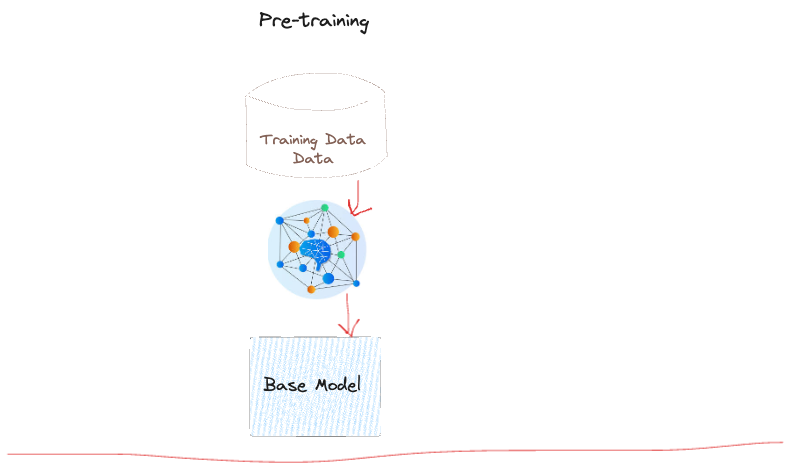
Instruction Tuning 指令调优
In order to get an assistant model like GPT, we need to align our model for our downstream task, which is awesome. For example, we can align to question answering, classification, translation, different persona roles that the model can take, topic modeling, clustering etc. The list goes on throughout the NLP journey.
为了获得像 GPT 这样的辅助模型,我们需要将模型与下游任务进行协调,这很棒。例如,我们可以将模型与问答、分类、翻译、模型可以承担的不同角色、主题建模、聚类等进行协调。在整个 NLP 旅程中,这个列表还在继续。
Think of it as following: you are giving a task for factual label checking, and we need to create thousands of instruction pairs. Then taking thousands of this possible pairs we can further fine-tune our base model and get an instruction tuned model. Andrej Karpathy explanations is very good.
想象一下:你正在给出一个事实标签检查任务,我们需要创建数千个指令对。然后利用数千个可能的指令对,我们可以进一步微调我们的基础模型,并得到一个指令调整模型。Andrej Karpathy 的解释非常好。
These instruction pairs look like this: Factual Explanation
这些指令对如下所示:事实解释
Instruction: Explain how photosynthesis works in simple terms.
Response labeled: Photosynthesis is how plants make their food. They take sunlight, water, and carbon dioxide from the air and convert it into oxygen and glucose (sugar). This happens in tiny structures called chloroplasts, which contain chlorophyll—the green pigment that captures sunlight energy. Plants use the glucose for energy and to build structures like stems and leaves. The oxygen is released into the air for us to breathe.
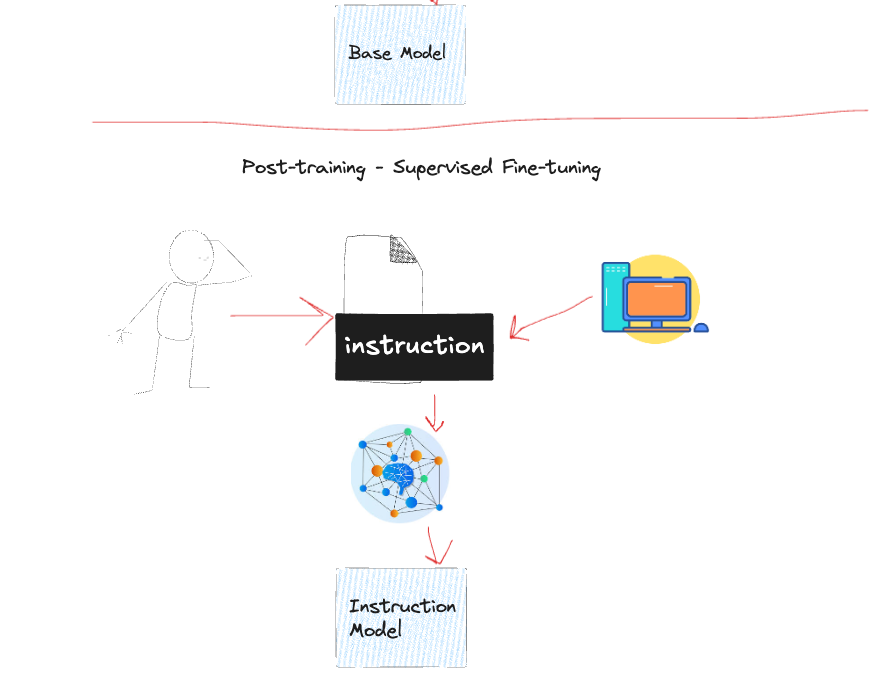
Beyond Instruction Tuning
超越指令调优
These data can be created from humans or synthetic data generation. But the story doesn’t end here—we need further improvements. Reinforcement Learning or Reinforcement Learning from Human Feedback like OpenAI approaches makes the alignment better.
这些数据可以由人类或合成数据生成。但故事并没有就此结束——我们需要进一步改进。强化学习或从人类反馈中进行强化学习(如 OpenAI 方法)可以使对齐效果更好。
Reinforcement Learning 强化学习
Reinforcement learning is an amazing field of artificial intelligence. We’ve heard in the news about breakthroughs from DeepSeek’s pure RL approach. Let’s illustrate RLHF or so-called Reinforcement Learning from Human Feedback simply.
强化学习是人工智能中一个令人惊奇的领域。我们在新闻中听说了 DeepSeek 的纯 RL 方法的突破。让我们简单说明一下 RLHF 或所谓的从人类反馈中进行的强化学习。
Initially, an instruction-tuned model is trained to follow prompts, but it undergoes further fine-tuning through reinforcement learning. During this phase, models interact with prompts, learn from trial and error, and receive human feedback to align responses with user expectations. This iterative process helps LLMs improve accuracy, relevance, and coherence, making them more effective in real-world applications.
最初,经过指令调整的模型会接受训练以遵循提示,但会通过强化学习进行进一步微调。在此阶段,模型会与提示进行交互,从反复试验中学习,并接收人工反馈以使响应与用户期望保持一致。这个迭代过程有助于提高准确性、相关性和连贯性,从而使模型在实际应用中更加有效。
The Reward Model in RLHF
RLHF 中的奖励模型
The reward model’s job is surprisingly simple: it just assigns a numerical score to any response. For example, when the LLM generates multiple answers to “Explain climate change” the reward model might give a score of 8.7 to a clear, accurate explanation and 3.2 to a confusing or inaccurate one. These scores then guide the learning process—the LLM is adjusted to maximize these reward scores, essentially learning to produce responses that humans would rate highly.
奖励模型的工作非常简单:它只是为任何响应分配一个数字分数。例如,当 LLM 生成多个**“解释气候变化”答案时,奖励模型可能会为清晰准确的解释给出 8.7分,为令人困惑或不准确的解释给出 3.2 分。然后,这些分数指导学习过程 — LLM 会进行调整以最大化这些奖励分数,本质上是学习如何产生人类会高度评价的响应。
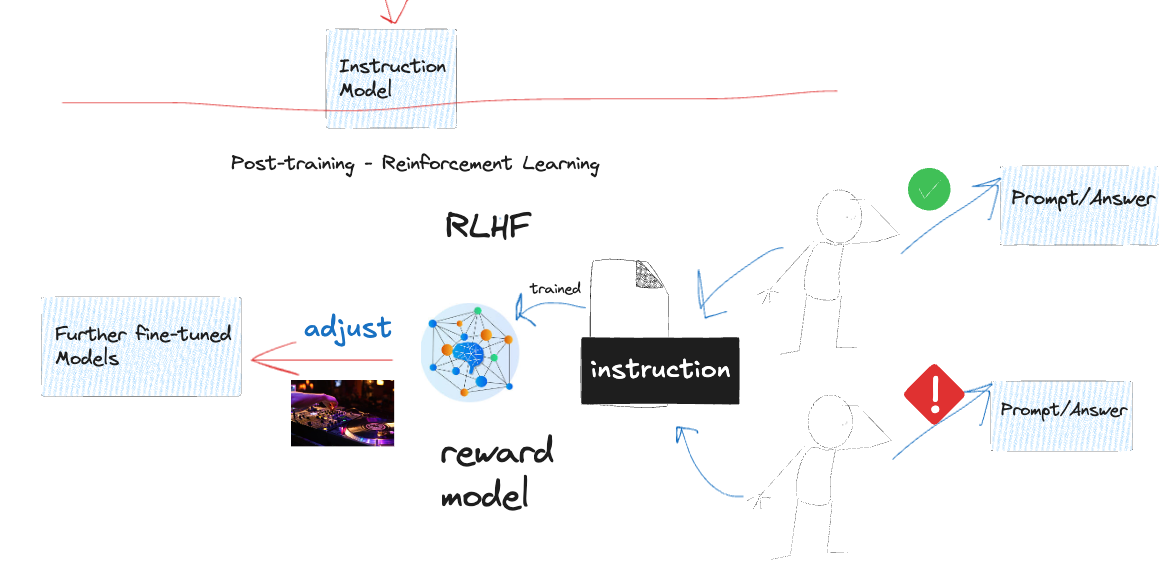
Ok lets go further, until now we understand at a very high level, what is AI Language modeling, what’s the task of an training (next token prediction), how different models created. But let’s see the revolutionized Idea of Attention.
好吧,让我们更进一步,到目前为止,我们已经在非常高的层次上理解了什么是人工智能语言建模,什么是训练的任务(下一个 token 预测),不同的模型是如何创建的。但让我们看看革命性的注意力理念。
Attention is all you need
你只需要注意力
In order to decode and process language in computers, we need a notion of:
为了在计算机中解码和处理语言,我们需要以下概念:
-
Numbers - converting language to numbers also called embedding space
数字 - 将语言转换为数字,也称为嵌入空间
-
Similarity 相似度
-
Attention 注意力
Tokenizer: The First Gateway to LLMs
Tokenizer:分词
This is the first step whenever we interact with an LLM like ChatGPT, Claude or any LLM API. Imagine this as the LLM’s Vocabulary. Every time we send a model a prompt, it first gets tokenized.
这是我们与 ChatGPT、Claude 或任何 API 交互时的第一步。可以将其想象为词汇表。每次我们向模型发送提示时,它都会首先被 token化。
Why? Because we need a mapping from text to numerical representations that computers can process and tokenization is the first part on the way 🛣️ 🛣️ Almost all of the model providers also have a pricing model based on consumed and output tokens.
为什么?因为我们需要从文本到计算机可以处理的数字表示的映射,而token化是第一步🛣️🛣️几乎所有的模型提供商都具有基于消耗和输出token来定价模型。
Lets say you send ChatGPT the prompt “What is tokenization why we need this”. The prompt gets broken into colored tokens as shown in the image. Importantly, tokens don’t always align with complete words—“token” & “ization” are separated into different tokens.
假设您向 ChatGPT 发送提示***“什么是token化?为什么我们需要它”。*提示会分解为彩色token,如图所示。重要的是,token并不总是与完整的单词对齐——“token”和“ization”**被分成不同的token。

You can visually explore tokenization processes using tools like thetiktokenizer.vercel.app.
您可以使用tiktokenizer.vercel.app**之类的工具直观地探索标记化过程。
Why use subword and not word by word?
为什么要使用子词而不是逐词?
Language is indeed complex and diverse, with new words constantly emerging across various languages. Many languages allows for the creation of new words from existing ones (e.g. sunflower), and some languages have even no spaces like Japanese (e.g. 今日はサーフィンに行きます). So our language models need to be generative and capable of capturing many patterns. Building a vocabulary with millions of words is not effective and even not possible.
语言确实复杂多样,各种语言中不断涌现新词。许多语言允许从现有单词中创建新单词(例如向日葵),有些语言甚至没有空格,例如日语(例如今日はサーフィンに行きます)。因此,我们的语言模型需要具有生成性,并且能够捕捉许多模式。构建包含数百万个单词的词汇表并不有效,甚至是不可能的。
Tokenizers are algorithms that capture statistical properties of large text corpora on which LLMs are pre-trained. There are different techniques for tokenization, like BPE (Byte Pair Encoding), WordPiece, SentencePiece. In this post I don’t go inside, but assume with tokenizers we get an intelligent vocabulary with subword tokens from our corpus of data.
分词器是一种算法,用于捕获预先训练过的大型文本语料库的统计特性。标记器有不同的技术,例如BPE(字节对编码)、WordPiece、SentencePiece。在这篇文章中,我不会深入探讨,但假设使用标记器,我们可以从数据语料库中获得包含子词标记的智能词汇表。

First numbers: Position IDs to token embedding vectors
第一个数字:位置 ID 到 token 嵌入向量
Remember tokenizer creates our vocabulary and helps us mapping from text to numerical representations.
记住,分词器创建了我们的词汇表并帮助我们从文本映射到数字表示。
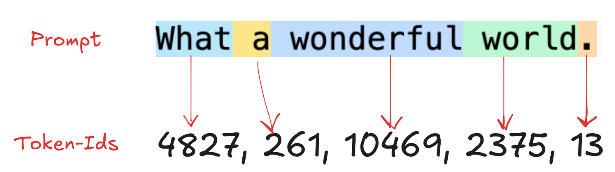
In general tokens can be anything from words, image patches, speech segments which has an ordered sequence in the nature. In the above example “What a wonderful world.” is mapped to the numbers 4827, 261, 10469, 2375, 13 and so on called the Position IDs. These IDs are encoded in the model’s inner architecture (Embedding-Matrix) and maps our tokens to a fixed token embedding vector.
一般来说,token可以是任何具有有序序列的单词、图像块、语音片段。在上面的例子中***,“多么美妙的世界。”被映射到数字4827、261、10469、2375、13等,称为位置 ID。这些 ID 被编码在模型的内部架构(嵌入矩阵)中,并将我们的标记映射到固定的*标记嵌入向量。
But why Positons IDs are so important?, because language is ordered and we should keep track of order for each token later in processing, for example most phenomena in the nature are ordered most not. Imagine machine translation, words can take another position in a sequence.
但是为什么位置 ID如此重要?因为语言是有序的,我们应该在后续处理中跟踪每个标记的顺序,例如,自然界中的大多数现象都是有序的,大多数则不是。想象一下机器翻译,单词可以在序列中占据另一个位置。
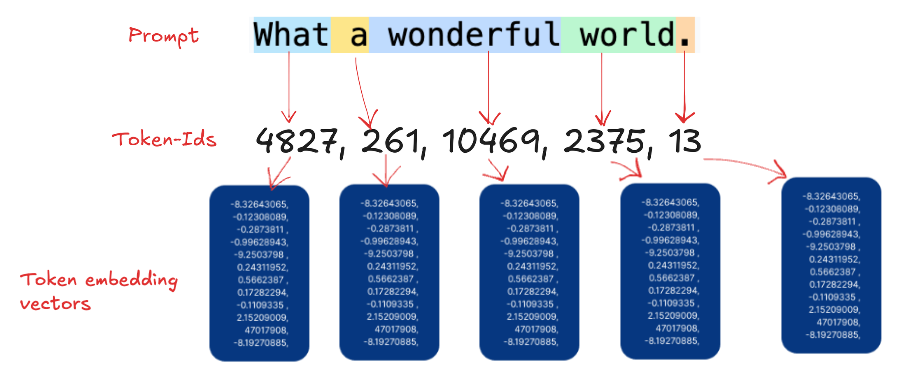
From these ID’s we get fixed vectors, so called token embedding vectors. These embedding vectors has huge dimension for example in ibm-granite/granite-3.1-8b-instruct LLM has 4096 dimension size.
从这些 ID 中,我们得到固定向量,即所谓的标记嵌入向量。这些嵌入向量具有巨大的维度,例如在ibm-granite/granite-3.1-8b-instruct LLM 中,维度大小为4096 。
It’s all about similarity?
都是关于相似性吗?
Ok tokenizer, position ids, and what are these token embedding vectors?
好的,标记器、位置 ID,以及这些标记嵌入向量是什么?
We need this because, with the power of linear algebra we can apply mathematical operations. Let’s explore these concepts in two dimensions for visualization 😃
我们之所以需要这个,是因为借助线性代数的力量,我们可以应用数学运算。让我们从二维角度探索这些概念,以便进行可视化 😃
Notion of similarity 相似性的概念
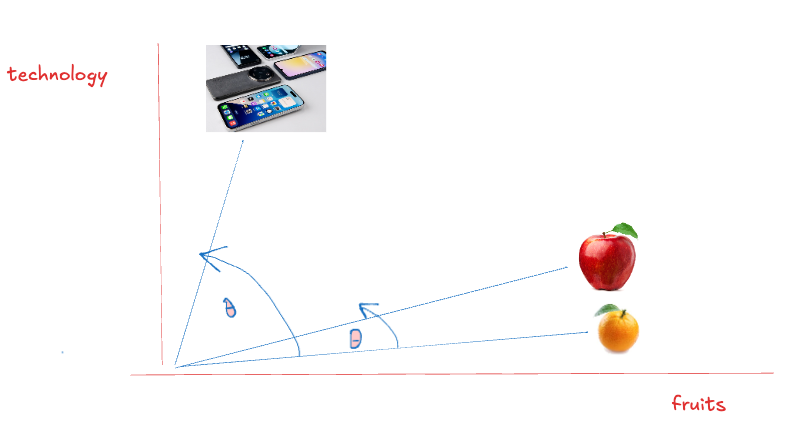
In this embedding space, we can see how words or concepts are arranged based on their meaning. The angle between vectors tells us how similar they are - smaller angles mean greater similarity. This is measured using cosine similarity, which ranges from -1 (completely opposite) to 1 (identical). For example, the apple and orange vectors have a small angle between them, indicating high similarity, while the phone and fruits have a much larger angle, showing they’re less related.
在这个嵌入空间中,我们可以看到单词或概念如何根据其含义排列。向量之间的角度告诉我们它们有多相似 - 角度越小,相似度越高。这是使用余弦相似度来衡量的,范围从**-1(完全相反)到 1(相同)。**例如,苹果和橙子向量之间的角度很小,表示相似度高,而手机和水果之间的角度要大得多,表明它们之间的相关性较低。
Now we have our embeddings and calculate similarity between the embeddings, are we done?
现在我们有了嵌入并计算了嵌入之间的相似度,完成了吗?
Unfortunately not. These token embedding vectors are not perfect, and should be learned and adjusted during training, because language is all about context.
不幸的是,不是。这些 token 嵌入向量并不完美,应该在训练过程中进行学习和调整,因为语言都是关于上下文的。
The Context Challenge: When “Apple” Isn’t Just a Fruit
语境挑战:“苹果”不再只是一种水果
Imagine these situations, how the token embedding for “apple” should be calculated?
想象一下这些情况, “apple”的 token embedding 应该如何计算?
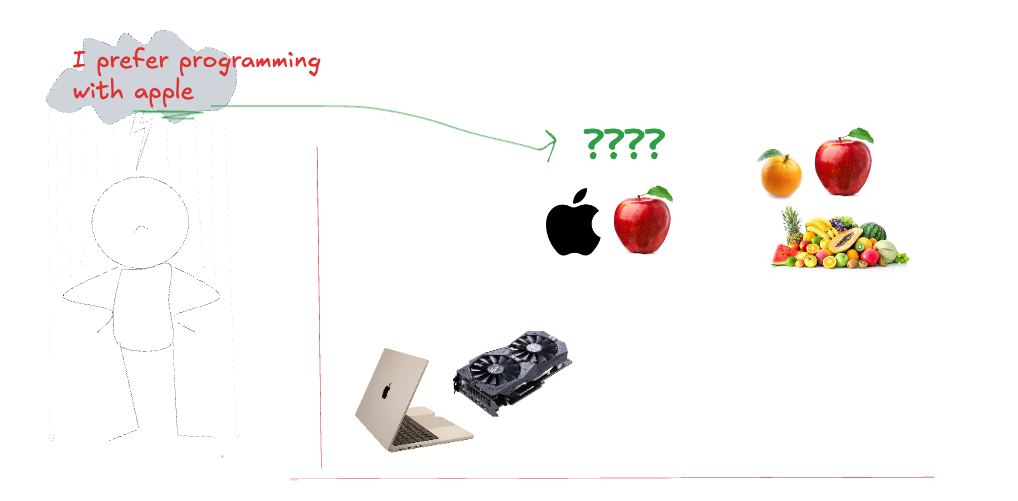
The Problem: Finding the Right Embedding
问题:找到正确的嵌入
The challenge is that we cannot assign a perfect place for every token in the latent space. Raw embeddings might capture some relationships, but they are often not well-aligned with real-world structures. To fix this, we apply linear transformations, which allow us to adjust the embedding space to better reflect similarities and relationships.
挑战在于我们无法为潜在空间中的每个token分配一个完美的位置。原始嵌入可能会捕获一些关系,但它们通常与现实世界的结构不一致。为了解决这个问题,我们应用线性变换,这使我们能够调整嵌入空间以更好地反映相似性和关系。
Linear Transformations 线性变换
So, what are linear transformations? Think of them as matrix operations applied to vectors. These operations can:
那么,什么是线性变换? 可以将它们视为应用于向量的矩阵运算。 这些运算可以:
-
Stretch the space to emphasize certain dimensions 📏
拉伸空间以强调某些维度📏 -
Rotate vectors to better align with meaningful directions 🔄
旋转矢量以更好地与有意义的方向对齐🔄 -
Shear data to adjust relationships between points 📐
剪切调整数据点之间的关系📐 -
Combine all these effects to create a better-structured space
组合所有这些效果,创造一个结构更好的空间
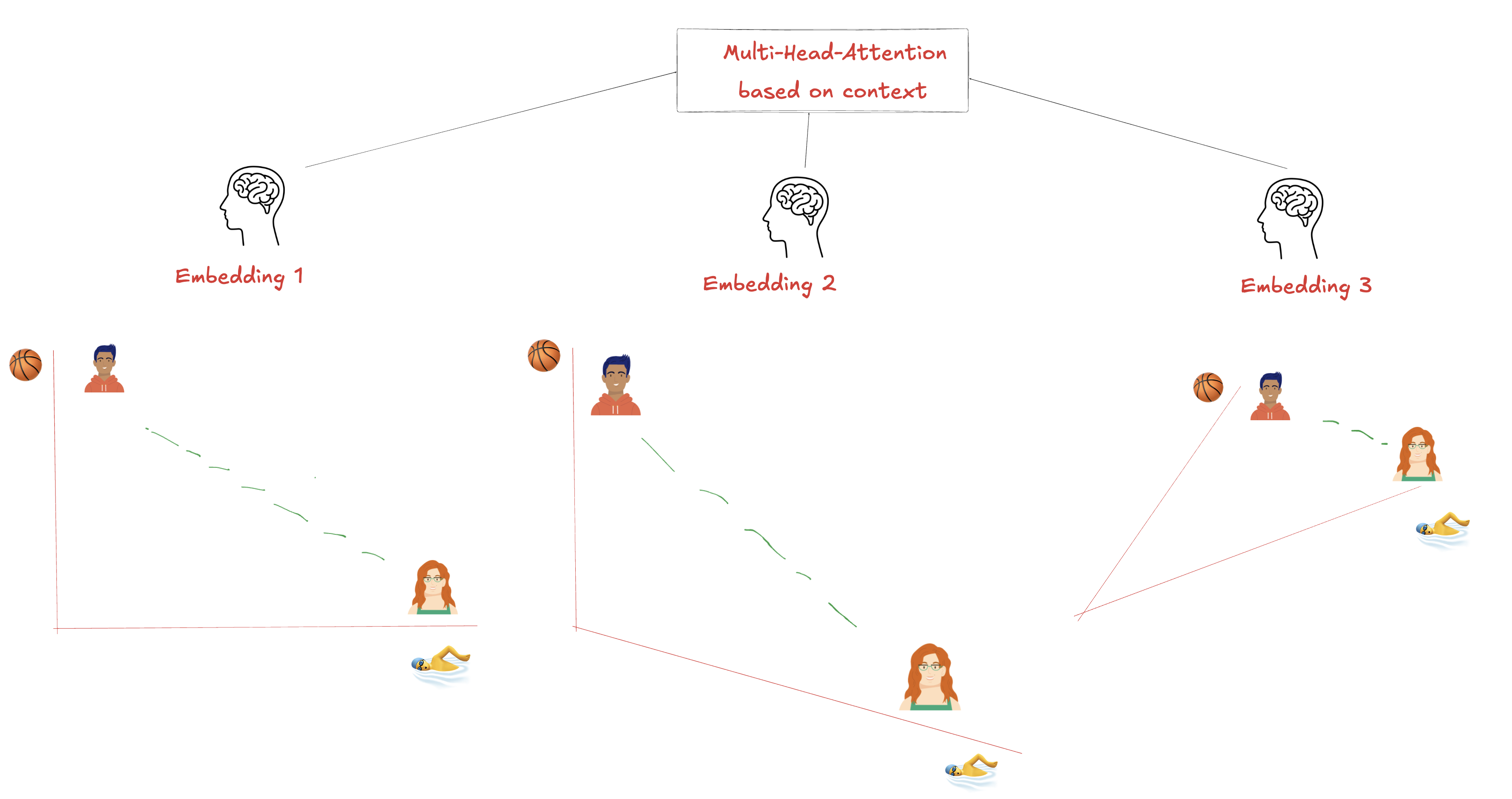
Adjusting Embeddings and Choosing the Best Embedding?
调整嵌入并选择最佳嵌入?
Imagine we want to discover the optimal embedding space that captures the true relationships in our data. Let’s explore this with a simple example:
假设我们想要找到能够捕捉数据中真实关系的最佳嵌入空间。让我们通过一个简单的例子来探索一下:
-
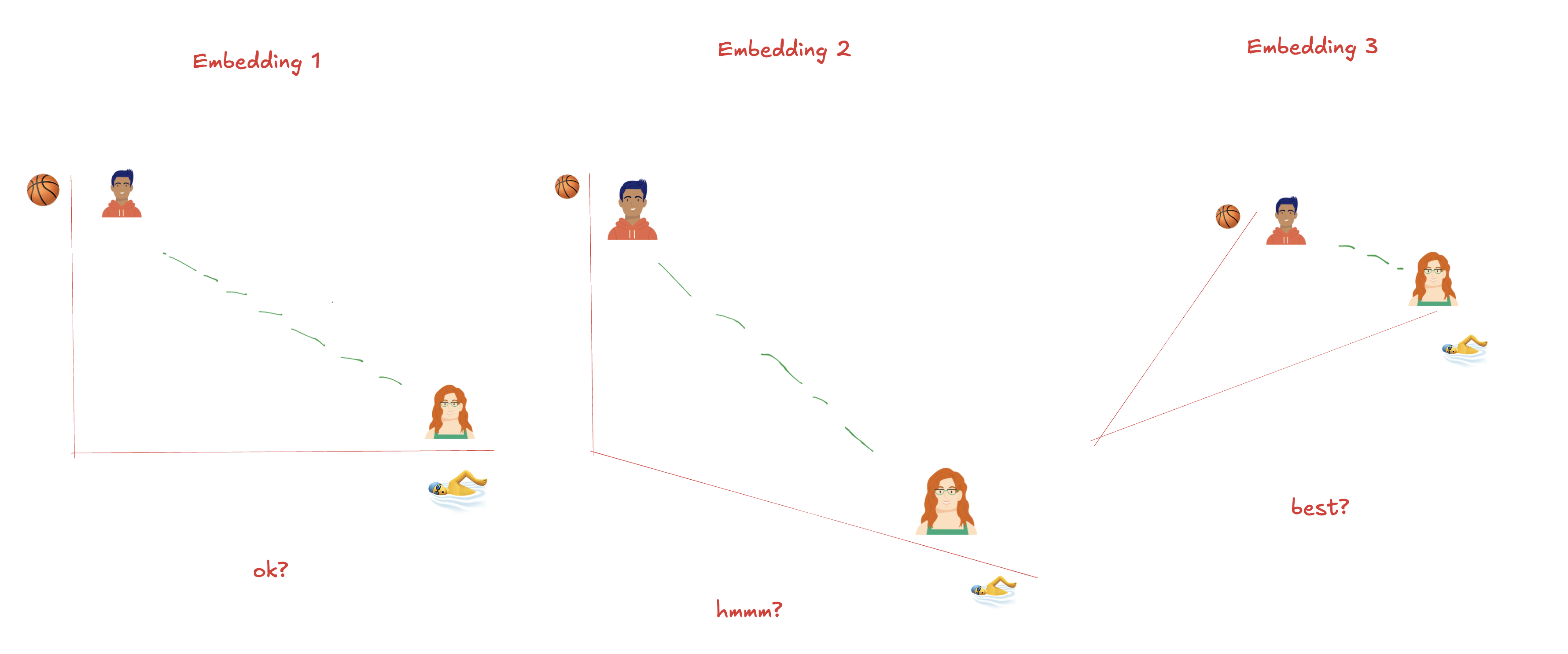
Ahmet is an excellent basketball player 🏀—he is great at jumping, agility, and teamwork.
艾哈迈德是一名出色的篮球运动员🏀——他擅长跳跃、敏捷和团队合作。 -
Sofia is a strong swimmer 🏊♂️—she excels in endurance and breathing control.
索菲亚是一名优秀的游泳运动员🏊♂️——她的耐力和呼吸控制能力非常出色。
Looking at the three embedding spaces below, we can immediately see why Embedding 3 is better. It organizes both athletes in relation to their sports while capturing their shared identity as athletes. During the training the so called the Multi-Head Attention Layer decides which Embedding is the best or combines them.
看看下面的三个嵌入空间,我们就能立即明白为什么Embedding 3 更好。它根据运动员的运动项目组织运动员,同时捕捉他们作为运动员的共同身份。在训练过程中,所谓的多头注意力层决定哪个嵌入是最好的或将它们结合起来。
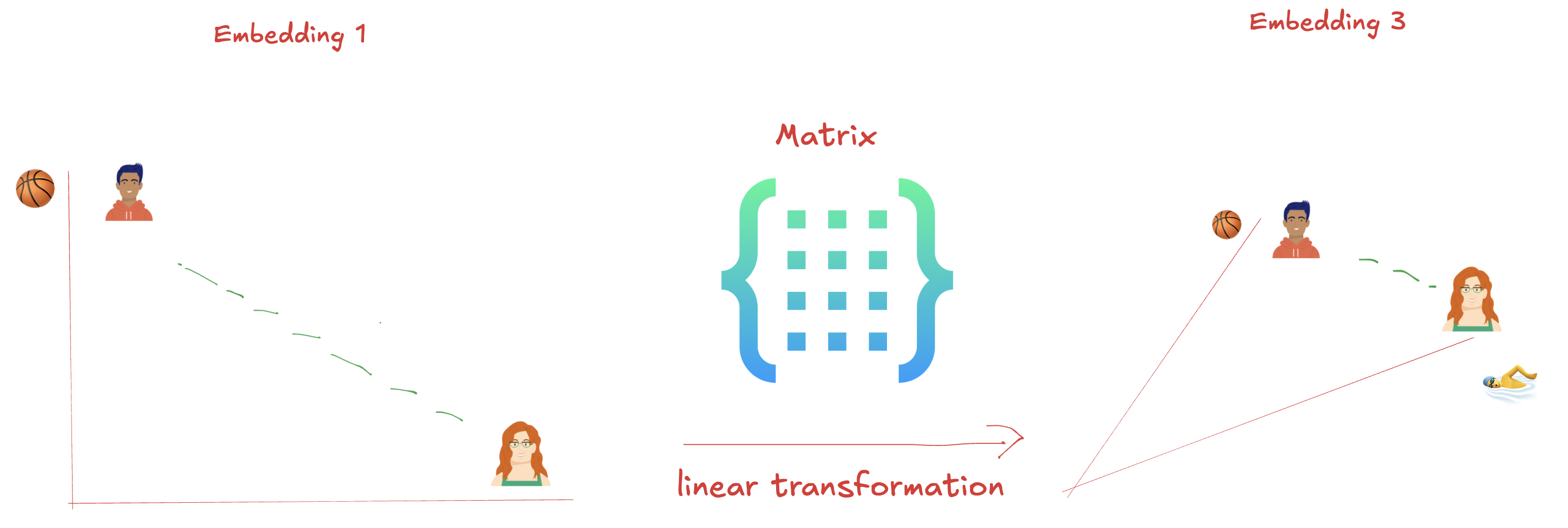
Transformation Magic 变换的魔法
If we decide Embedding 3 should be used then we apply a linear transformation with matrix. The values of the matrix is the learnable parameters. We’re performing matrix-vector multiplication, which is calculated using multiple dot products.
如果我们决定使用Embedding 3,那么我们将应用矩阵的线性变换。矩阵的值是可学习的参数。我们正在执行矩阵向量乘法,它是使用多个点积来计算的。
This process mirrors how our own brains might reorganize concepts—shifting from thinking about “sports equipment” to thinking about “athletes and their specialties” when the context requires it. The difference is that our AI models must learn these transformations through millions of examples rather than through lived experience.
这一过程反映了我们大脑重新组织概念的方式——在情境需要时,从思考“运动器材”转变为思考“运动员及其专长”。不同之处在于,我们的人工智能模型必须通过数百万个示例而不是生活经验来学习这些转变。
The beauty of this approach is that as the model encounters more data, these transformation matrices continuously refine, creating increasingly nuanced understanding of the relationships between concepts.
这种方法的优点在于,随着模型遇到更多数据,这些 转换矩阵 不断完善,对概念之间的关系形成越来越细致入微的理解。
The Magic of Attention: Why Context Changes Everything
注意力的魔力:为何上下文会改变一切
Until now we’ve explored similarity (cosine, dot-product) and how linear transformations can create better embeddings. But we’re missing something crucial - Attention, the breakthrough that revolutionized AI language understanding.
到目前为止,我们已经探索了相似性(余弦、点积)以及线性变换如何创建更好的嵌入。但我们缺少了至关重要的东西——注意力,这是彻底改变人工智能语言理解的突破。
Let’s take a example—journalist and microphone.
让我们举一个例子——记者和麦克风。
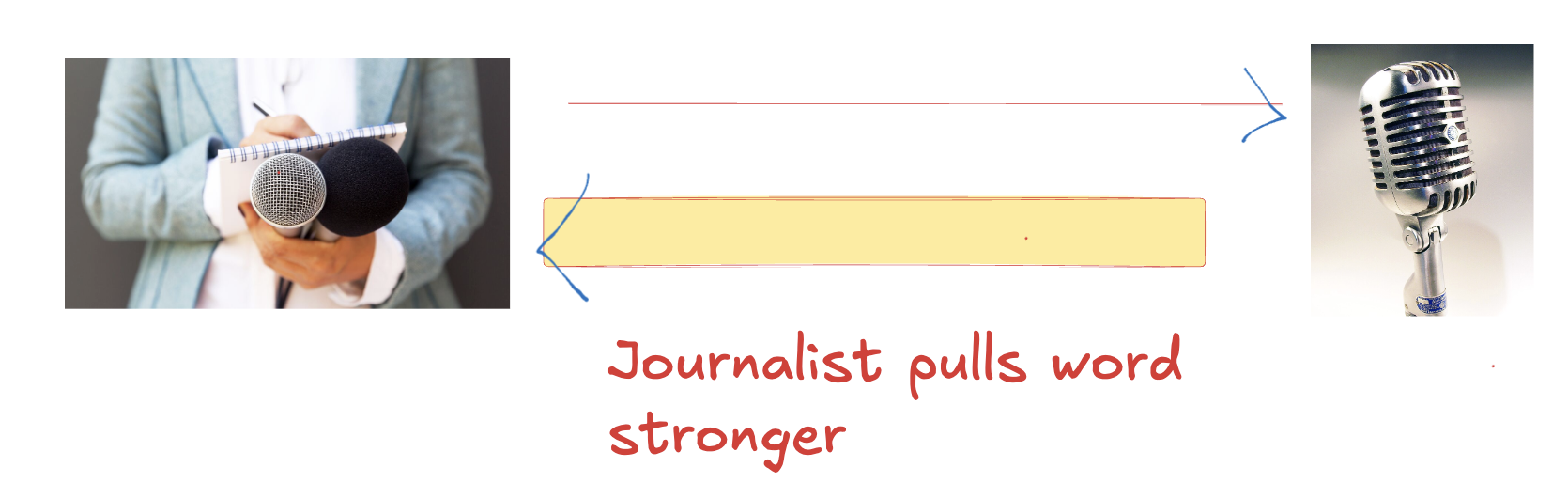
In an ideal world, these two should have a balanced connection in the embedding space, but in real-world training data, that’s not the case. A journalist strongly pulls “microphone”, but “microphone” does not strongly pull “journalist”.
在理想世界中,这两者应该在嵌入空间中具有平衡连接,但在现实世界的训练数据中,情况并非如此。记者强烈 拉拽(吸引) “麦克风” ,但“麦克风” 不会拉拽(吸引) “记者” 。
Why This Asymmetry Exists?
为什么存在这种不对称现象?
Because in real-world data, “journalist” often appears with words like interview, report, article, media, and yes, microphone. But “microphone” has a much broader range—it appears with singers, podcasters, radio hosts, studio equipment, speakers, and many other unrelated concepts. So, when we ask:
因为在现实世界的数据中,“记者”经常与采访、报道、文章、媒体以及麦克风等词语一起出现。但“麦克风”的范围要广得多——它与歌手、播客、电台主持人、演播室设备、扬声器以及许多其他不相关的概念一起出现。所以,当我们问:
-
“What does journalist relate to?” → Microphone is a strong association because journalists frequently use microphones.
“记者与什么相关?” →麦克风是一个很强的关联,因为记者经常使用麦克风。 -
“What does microphone relate to?” → Journalist is a weak association because a microphone is used by many professions, not just journalists.
“麦克风与什么相关?” →记者是一个弱关联,因为麦克风不仅被记者使用,还被许多职业所使用。
Why a Single Linear Transformation Doesn’t Work
为什么单一线性变换不起作用
If we apply only one transformation, we still get a symmetric pull, meaning the model would think that:
如果我们只应用一个变换,我们仍然会得到对称关联,这意味着模型会认为:
-
“Microphone” should influence “journalist” just as much as “journalist” influences “microphone.”
“麦克风”应该影响“记者”,就如同“记者”影响“麦克风”一样。 -
This is incorrect because a microphone is just a tool, and many people use it beyond journalists.
这是不正确的,因为麦克风只是一种工具,除了记者之外,还有许多人使用它。
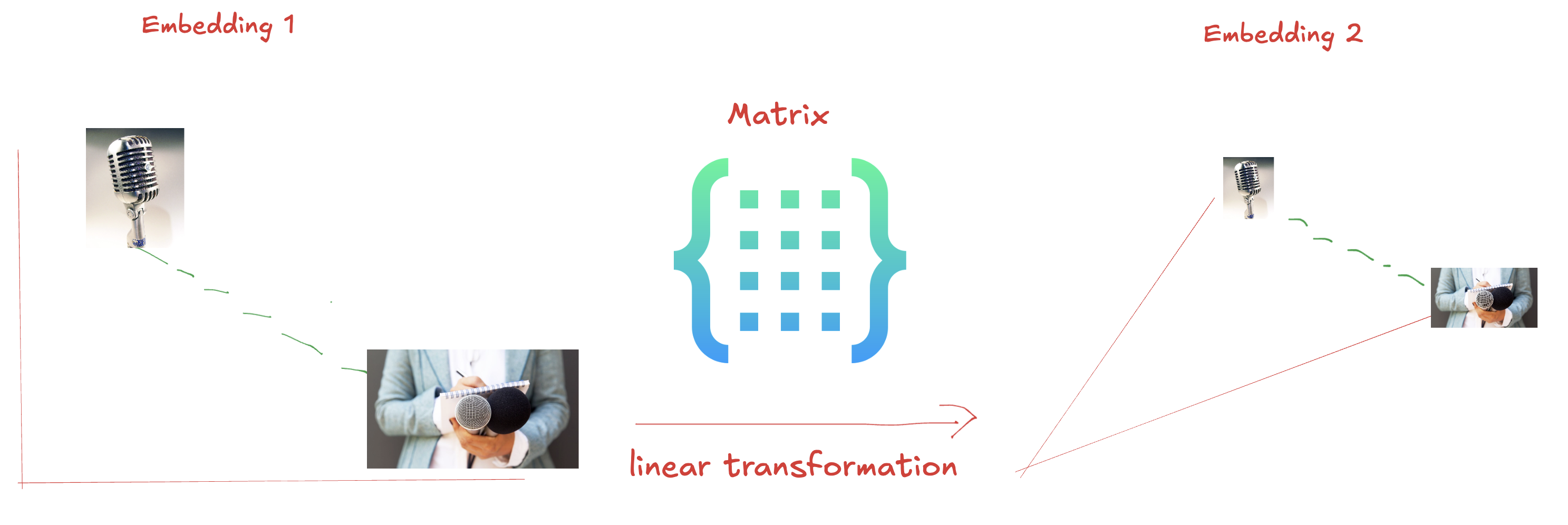
The Fix: Two Linear Transformations
解决方法:两个线性变换**
To properly capture this, we need two different transformations. Lets introduce Key and Query. Key is which pulls the other token, and Query is which is pulled. We apply different perspectives depending on whether “journalist” or “microphone” is acting as the key or the query.
为了正确捕捉这一点,我们需要两种不同的转换。让我们介绍一下Key和 Query。Key 拉拽别的 token , Query是被拉拽的。我们根据“记者”或“麦克风”是充当key还是查询来应用**不同的视角****。
-
Journalist (Key) – It strongly pulls “microphone” (Query) because it’s an important tool for their work.
记者(key) ——它强烈拉拽“麦克风”(query),因为这是他们工作的重要工具。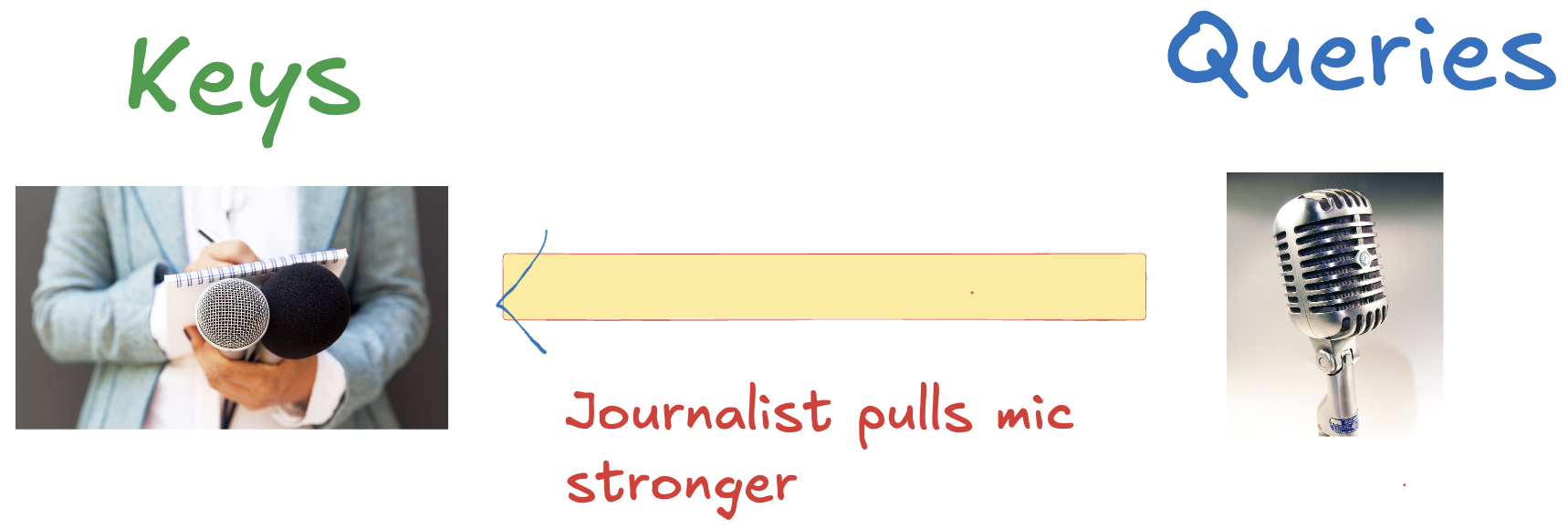
-
Microphone (Key) – It weakly pulls “journalist” because its use is much broader.
麦克风(key) ——它弱弱地拉拽“记者”,因为它的用途更为广泛。
The Formula 公式
Applying two linear transformations on Keys and Queries and then we take the angle between keys and queries. After that we can calculate the similarity via dot-product (the Attention matrix).
对 Keys 和 Queries 应用两个线性变换,然后我们取 key 和 query 之间的角度。之后我们可以通过点积(注意力矩阵)计算相似度。
Journalist (Key) – Microphone (Query) we want large cosine in similarity (strong pull).
记者(key) ——麦克风(query)我们希望相似度有 较大的余弦(强拉力)。
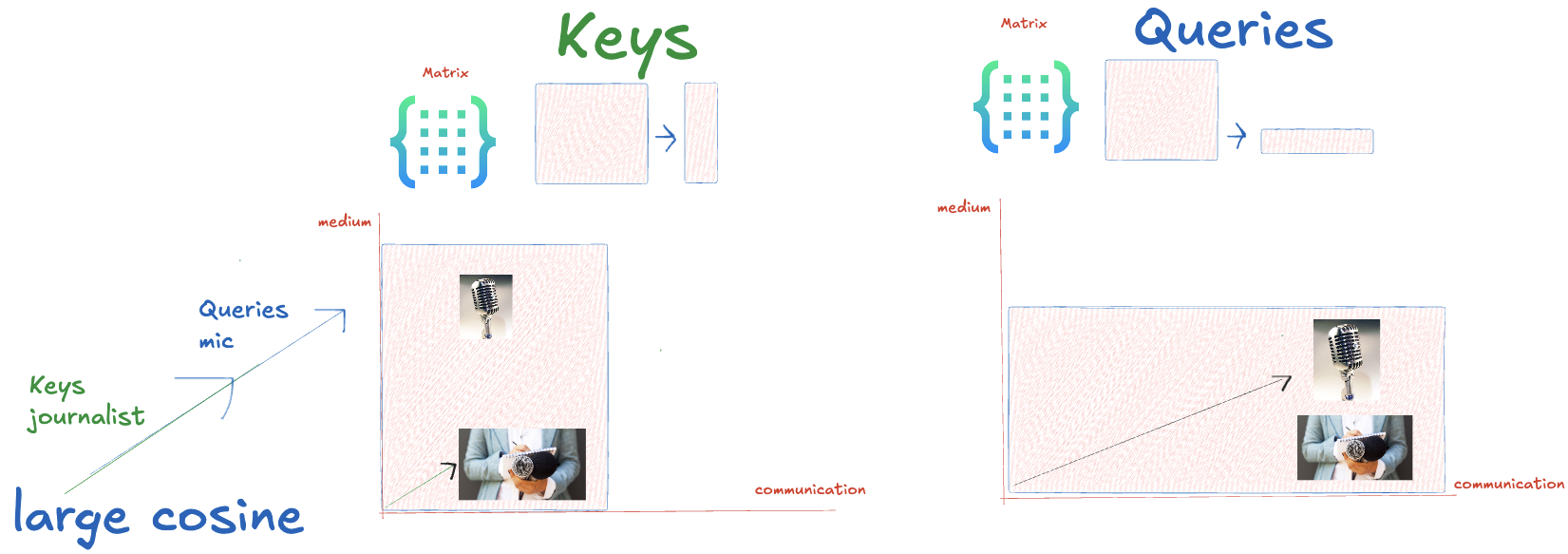
Microphone (Key) – Journalist (Query) we want small cosine in similarity (weak pull).
麦克风(key) ——记者(query)我们希望 相似度(弱拉力)的余弦较小。
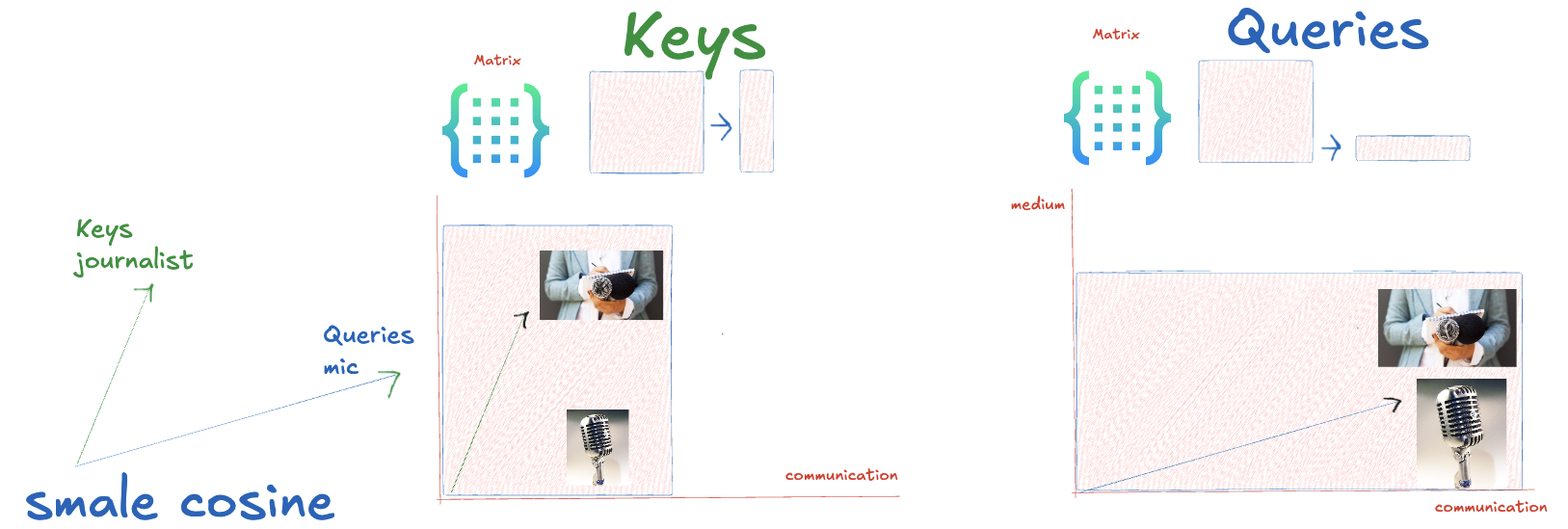
Every value of this matrices is adjusted during training time, so we get a clearer embedding.
该矩阵的每个值都会在训练时进行调整,因此我们得到更清晰的嵌入。
Understanding the Dot Product in Attention
理解注意力机制中的点积
The dot product is the mathematical operation that powers attention. In simple terms:
点积是增强注意力的数学运算。简而言之:
-
What it does: Measures how aligned two vectors are with each other.
作用:测量两个向量之间的对齐程度。 -
How it works: Multiplies corresponding elements of two vectors and sums the results.
工作原理:将两个向量的相应元素相乘并对结果求和。
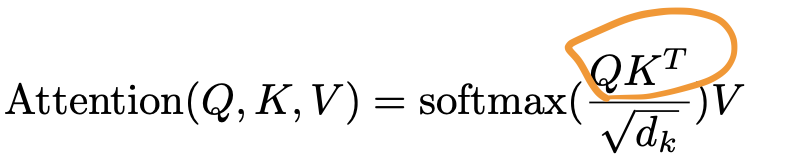
The Value 值
But last, there is another component called Value. Think like this, the actual audio content captured by the microphone—it carries the real meaning the journalist wants to process. After computing the similarity between queries and keys (dot product of Q and K), these attention scores are used to weight the Values (V). This means that:
最后,还有另一个组件称为值。这样想,麦克风捕获的实际音频内容——它承载着记者想要处理的真正含义。在计算查询和键之间的相似度( Q 和 K 的点积)后,这些注意力分数用于加权值( V ) 。这意味着:
-
If a key strongly matches a query, its corresponding value is given more importance.
如果某个键与查询高度匹配,则其对应的值将变得更加重要。 -
If a key weakly matches a query, its value contributes less to the final output.
如果某个键与查询的匹配程度较弱,则其值对最终输出的贡献较小。
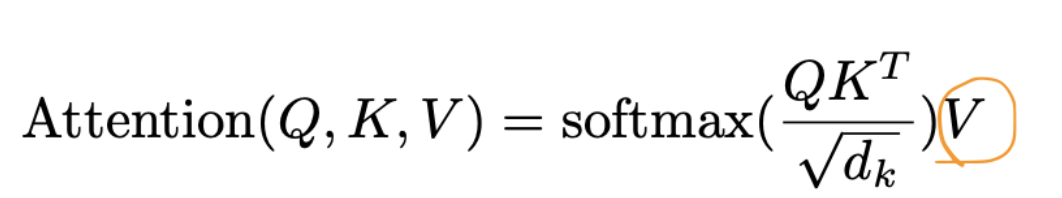
Recap: We are extracting from an token embedding the Query, Key and Values based on this trained matrices, and producing a more contextualized token embedding with same dimension
**回顾:**我们根据这个经过训练的矩阵,从嵌入查询、键和值的 token 中提取数据,并生成具有相同维度的更具语境化的 token 嵌入
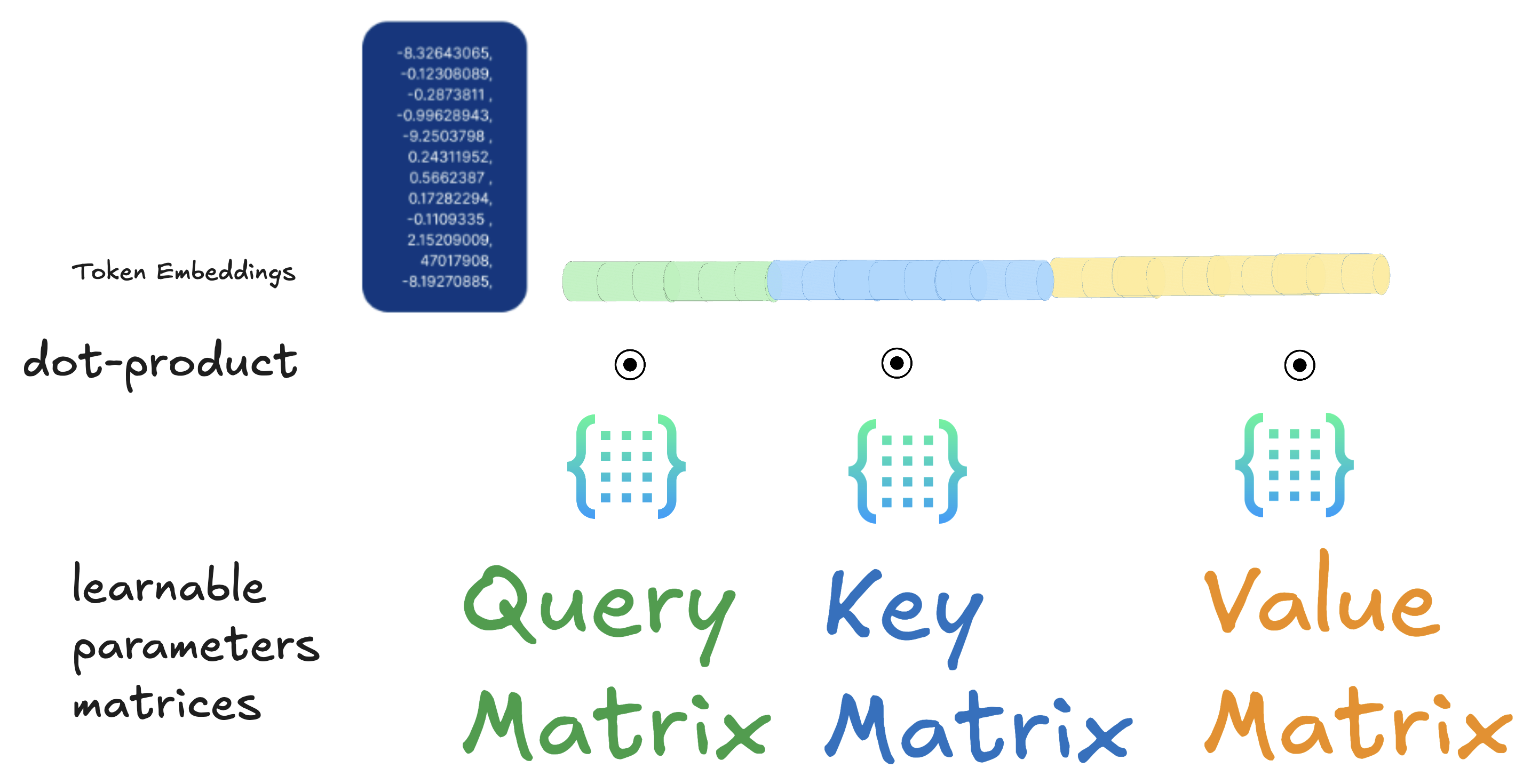
-

Token embeddings transform words into number vectors, creating a mathematical language.
token嵌入将单词转换为数字向量,从而创建一种数学语言。 -
Linear transformations are the key mathematical operations that create the three different perspectives:
线性变换是创建三个不同视角的关键数学运算:-
Each embedding is multiplied by three different matrices to create Query, Key, and Value representations of the same token
每个嵌入乘以三个不同的矩阵,以创建同一 token 的查询、键和值表示 -
This is how one word can have multiple “views” or “roles” in the attention process
这就是一个词在注意力过程中可以有多个“视图”或“角色”的原因
-
-
Query perspective (Q matrix transformation): “What am I looking for in other words?”
Query视角(Q矩阵变换):“换句话说,我在寻找什么?” -
Key perspective (K matrix transformation): “What aspect of me might others find relevant?”
Key视角(K矩阵变换):“别人可能会认为我的哪些方面与我相关?” -
Value perspective (V matrix transformation): “What information should I contribute if matched?”
Value视角(V矩阵变换):“如果匹配成功我应该贡献什么信息?” -
Same input, three views: The word “apple” starts as one embedding but is transformed into:
相同的输入,三个视图:“apple”这个词开始是一个嵌入,但被转换成:-
A Query vector (searching for relevant information)
query向量(搜索相关信息) -
A Key vector (advertising what it contains)
key向量(宣传其内容) -
A Value vector (the actual information to be used)
value向量(实际要使用的信息)
-
-
Dot products between queries and keys measure relationship strength, creating the attention map.
查询和键之间的点积测量关系强度,从而创建注意力图。 -
Context-sensitive understanding: These transformations allow the model to interpret “apple” differently when it appears near “iPhone” versus “orchard.”
上下文敏感的理解:这些转换允许模型在“apple”出现在“iPhone”和“orchard”附近时对其进行不同的解释。 -
Asymmetric relationships are naturally modeled because each token has these three distinct roles.
由于每个标记都有这三个不同的角色,因此可以自然地建模不对称关系。 -
Multi-head attention applies multiple sets of these transformations in parallel, capturing different relationship types simultaneously.
多头注意力机制并行应用多组此类转换,同时捕获不同的关系类型。
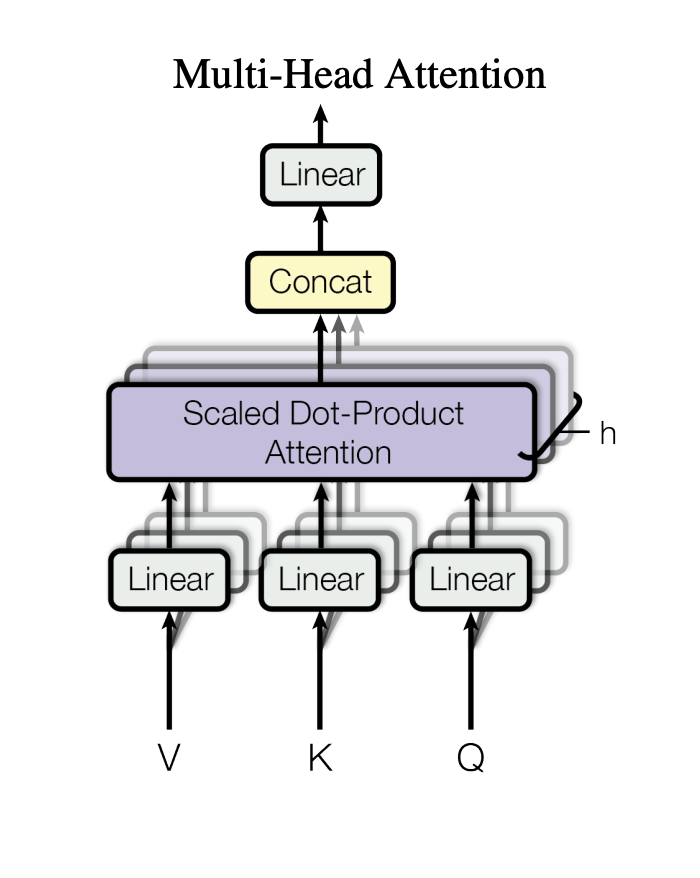
Multi-Head-Attention (Linear)
多头注意力(线性)
One point, as we saw we need to combine between best embeddings, this is done via Multi-Head-Attention (Linear). Below, from the original paper. Imagine these as an intelligent brain which combines the best token embedding based on context. Suppose many brains which are calculating embeddings and choose or combine and weight them based on context.
有一点,正如我们所见,我们需要 结合最佳嵌入,这是通过多头注意力(线性实现的。下面是原始论文。想象一下,它们是一个智能大脑,它根据上下文结合最佳的 token 嵌入。假设许多大脑正在计算嵌入,并根据上下文选择或组合并加权它们。
Multiple attention mechanisms in parallel: Each “head” learns to focus on different aspects of language.
多种注意力机制并行:每个“头脑”学会关注语言的不同方面。
The Linear transformations:
线性变换:
-
- Lower Linear layers: Project input embeddings into different “perspective spaces” - one might focus on syntax, another on semantics, another on entity relationships.
下线性层:将输入嵌入投影到不同的“透视空间”中——一个可能关注语法,另一个可能关注语义,还有一个可能关注实体关系。
- Lower Linear layers: Project input embeddings into different “perspective spaces” - one might focus on syntax, another on semantics, another on entity relationships.
-
- Upper Linear layer: Combines these multiple perspectives into a unified representation.
上线性层:将这些多种视角组合成一个统一的表示。
- Upper Linear layer: Combines these multiple perspectives into a unified representation.
Scaled Dot-Product Attention: Each head calculates its own attention pattern based on its specialized Query, Key, Value projections.
缩放点积注意力:每个头部根据其专门的查询、键、值投影计算自己的注意力模式。
Are we done with predicting the next token?
我们预测完下一个token了吗?
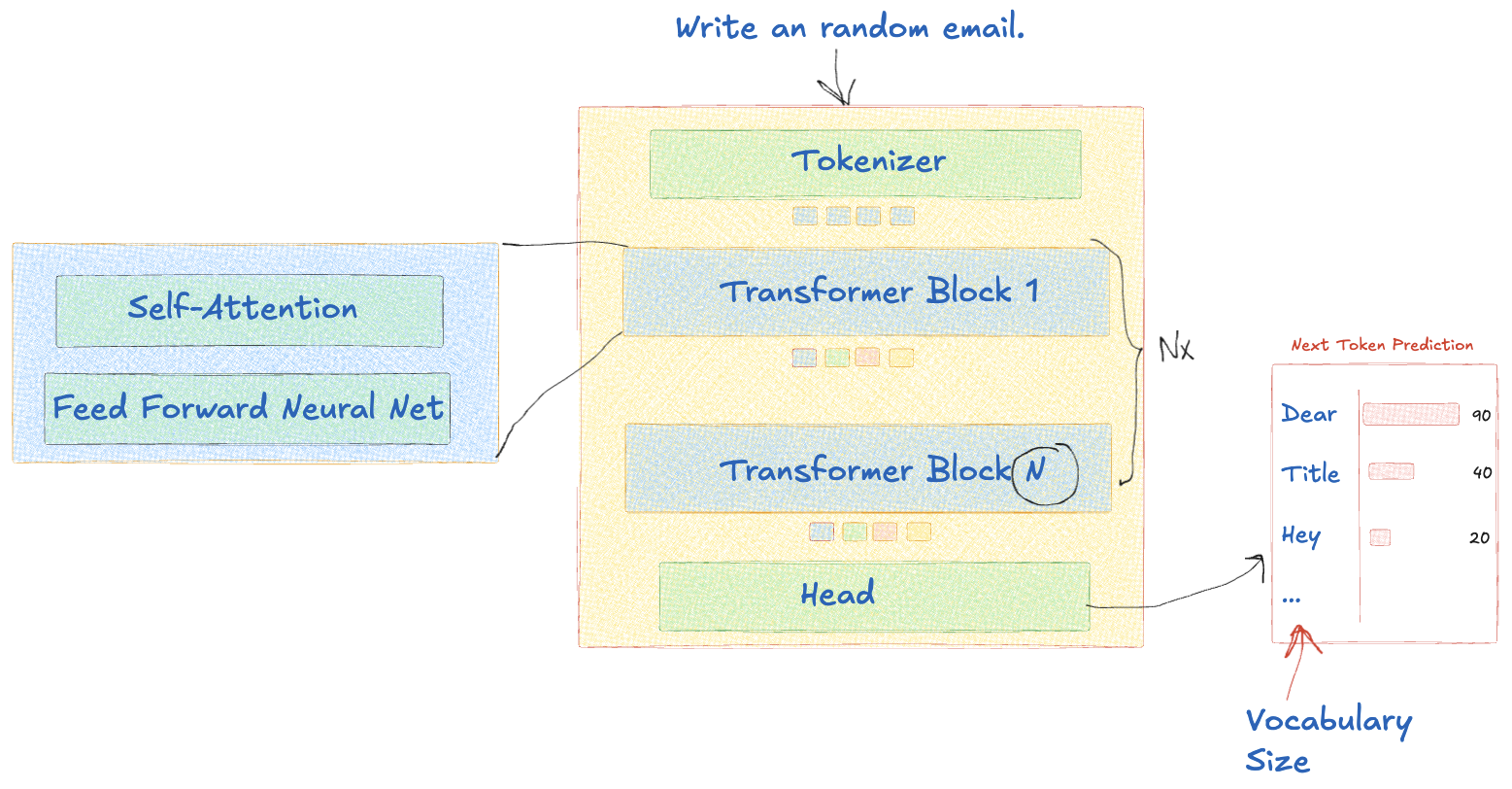
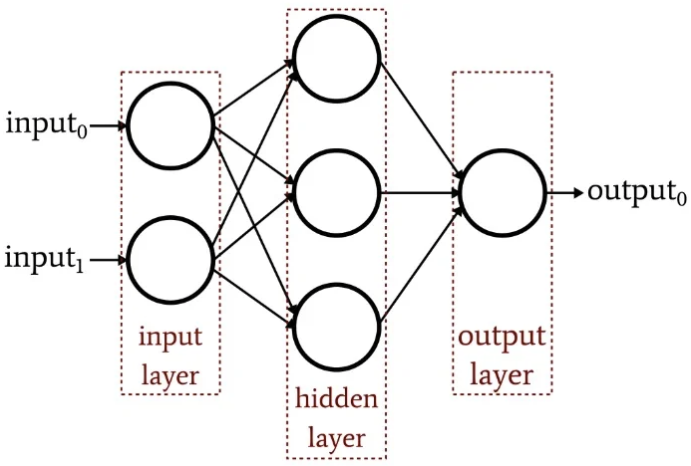
Until now, we have explored the attention mechanism. To predict the next token, the contextualized token embeddings pass through a multi-layer perceptron neural network (MLP) or a feedforward neural network (FFNN).
到目前为止,我们已经探索了注意力机制。为了预测下一个 token,上下文化的 token 嵌入会经过多层感知器神经网络 (MLP) 或前馈神经网络 (FFNN)。
Unlike self-attention, which connects and applies attention to tokens, this process handles each token position separately. As the information flows through this sequence, the model refines its understanding of the relationships and meanings within the text. At this layer, the model generalizes the learned concepts. This is also where most of the model’s parameters reside.
与将注意力连接到 token 并对其施加注意力的自注意力不同,此过程分别处理每个 token 位置。随着信息流经此序列,模型会完善对文本中的关系和含义的理解。在此层,模型会概括所学习的概念。这也是模型的大部分参数所在的地方。
Reading a model card 读取模型说明
Some model parameters from ibm-granite/granite-3.1-8b-instruct
一些模型参数来自ibm-granite/granite-3.1-8b-instruct
| Model | 8b Dense 8b 密集 | Explanation 解释 |
|---|---|---|
| Embedding Size 嵌入大小 | 4096 | each token embedding dimension, which flows through the network 每个 token 嵌入维度,流经网络 |
| Number of layers 层数 | 40 | 40 Transformer blocks 40 变压器块 |
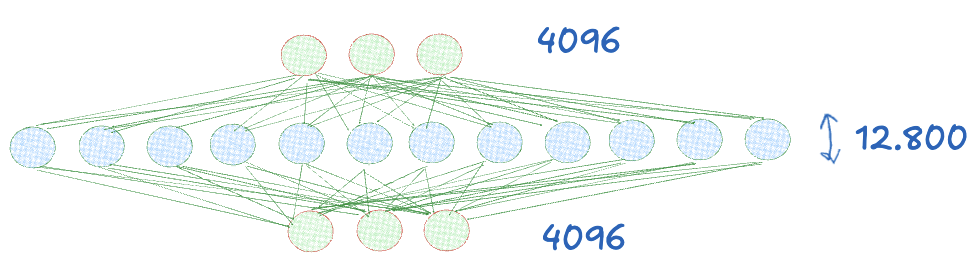
| Attention head size 注意头部尺寸 | 128 | each attention head is 128 dimensions, 4096 = 32×128 每个注意力头为 128 维,4096 = 32×128 |
| Number of attention heads 注意力头数量 | 32 | 32 heads in Attention 32 个注意力 |
| Number of KV heads KV头数量 | 8 | Key-Value projection pairs that are shared across multiple attention heads 多个注意力头共享的键值投影对 |
| MLP hidden size MLP 隐藏大小 | 12800 | hidden layer in MLP or FNN MLP 或 FNN 中的隐藏层 |
| Sequence length (context window) 序列长度(上下文窗口) | 128k 128千 | Maximum process token embeddings at a time 一次处理 token 嵌入的最大数量 |
| # Parameters # 参数 | 8.1B | total params 总参数 |
| # Training tokens # 训练token | 12T | 12 trillion training tokens 12万亿个训练token |
Embedding Size of 4096 and Number of Layers 40
嵌入大小为 4096,层数为 40
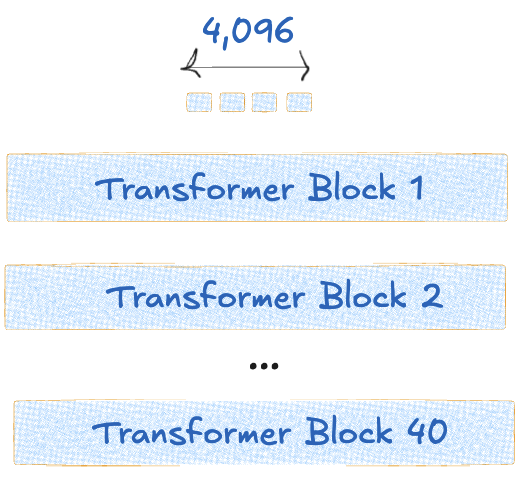
Number of attention heads 32 and Number of Key/Value heads 8
注意力头数量为 32,键/值头数量为 8

Feedforward Neural Network
前馈神经网络
Conclusion 结论
We’ve journeyed through the inner workings of Large Language Models, uncovering the elegant concepts that enables machines to understand and generate human language. Through our exploration, we learned
我们探索了大型语言模型的内部工作原理,揭示了使机器能够理解和生成人类语言的优雅概念。通过我们的探索,我们了解到
-
The core training objective is surprisingly simple: predict the next token
核心训练目标出奇的简单:预测下一个 token -
Embeddings 嵌入
-
Attention mechanism 注意力机制
-
Multi-head attention 多头注意力机制
-
Transformer architecture core components
Transformer 架构核心组件
Resources 资源
There is a lot to cover for more advanced deep dive I can suggest following resources.
对于更高级的深度探索,还有很多内容需要介绍,我可以推荐以下资源。
https://www.youtube.com/watch?v=RFdb2rKAqFw
AI Academy which provides very good insights
Hands-On Large Language Models: Language Understanding and Generation
实践大型语言模型:语言理解与生成
原文连接:Understanding LLMs: A Simple Guide to Large Language Models


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









