









 本文讨论了在MongoDB中,count()函数在大数据量下效率低下的问题,推荐使用聚合框架和索引来提高查询速度。作者提到,对于2000万数据,通过find()命中索引可实现0.2秒查询,对比count()的7秒差距明显。
本文讨论了在MongoDB中,count()函数在大数据量下效率低下的问题,推荐使用聚合框架和索引来提高查询速度。作者提到,对于2000万数据,通过find()命中索引可实现0.2秒查询,对比count()的7秒差距明显。
在MongoDB中,count()函数用于统计文档的数量。但是count()函数通常不会使用索引来计算文档数量,而是扫描集合中的文档来计数。当数据量较大的时候,就不适合使用了。
解决方案:
1、使用聚合框架(aggregation framework)。虽然count()方法方便快捷,但在某些复杂场景中,使用聚合框架可能会更灵活和强大。
2、使用索引,直接find()查询文档,只要命中索引,查询速度比count()效率高很多。如果还需要分页之类的操作,可以在程序中对查询出来的文档集合直接分页。
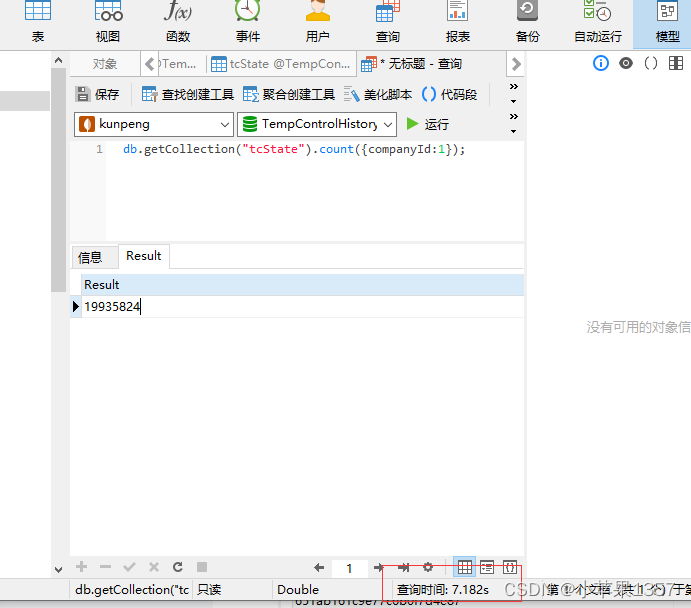
我的数据库大约有2000万数据,我是用的是索引的方式:
count统计没有命中索引,需要7秒钟
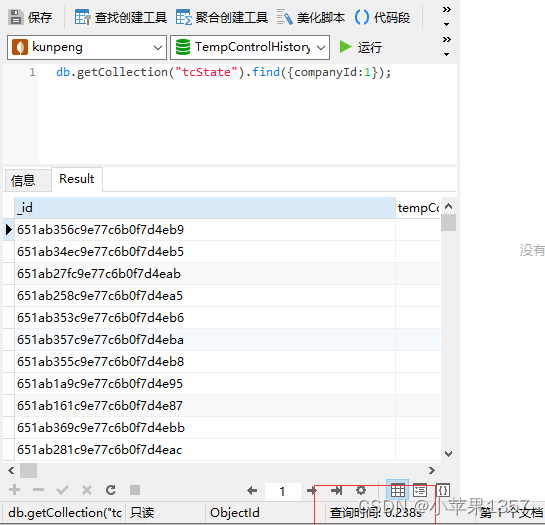
只有find根据条件查询,命中索引,只需要0.2秒

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









