 CornerNet目标检测算法详解
CornerNet目标检测算法详解





 本文介绍了CornerNet目标检测算法,它是一种无需引入anchors的one stage检测器,预测目标的左上和右下两个角点。文中还提出corner-pooling方式。详细阐述了其网络结构、Heatmaps、Offsets、Embeddings等模块,以及训练和测试过程,该算法在COCO数据集上AP达42.2%。
本文介绍了CornerNet目标检测算法,它是一种无需引入anchors的one stage检测器,预测目标的左上和右下两个角点。文中还提出corner-pooling方式。详细阐述了其网络结构、Heatmaps、Offsets、Embeddings等模块,以及训练和测试过程,该算法在COCO数据集上AP达42.2%。
1.摘要:
作者提出了一种新的检测方式,不需要引入anchors。
CornerNet是one stage检测器,它预测的是目标的左上和右下两个角点。
文中还提出了一种对应于corner预测的pooling方式,作者称之为corner-pooling。
CornerNet在COCO数据集上的AP达到了42.2%
2. CornerNet
2.1 网络结构
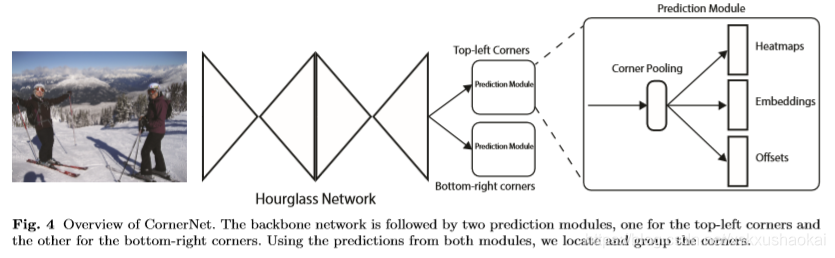
CornerNet网络有两个分支组成,一个分支用来预测top-lert角点,另一个分支用来预测bottom-right角点。其中每个分支又分为三个任务,分别是Heatmaps、Embeddings、Offsets。Heatmaps输出热点图,即每个点是一个目标顶点的概率;Embeddings用来判断该顶点属于哪个目标,即用于将 top-left 角点和 bottom-right 角点进行匹配;Offsets用来微调顶点位置,主要是为了提高小目标的检测精度,在本文中作者用来回归由于取整而损失掉的小数部分。
CornerNet的主干网络为Hourglass Network(沙漏网络),是一个全卷积网络。一个沙漏模块形如沙漏,前面使用卷积和maxpooling 进行downsample,用于提取特征缩小feature map大小,后面接upsample层,用来将feature map恢复到输入大小。沙漏模块中也含有跳过连接(skip layer),类似于yolov3中的shortcut层——前后的feature map concat。作者认为将多个沙漏模块进行串联可以重新处理前一个模块中的特征以提取更高级别的feature 信息。
作者在CornerNet中使用两个沙漏模块进行串联,并且没有使用maxpooling层进行downsample,而是使用stride为2的convoluation层进行downsample。每个沙漏模块降低了5倍的特征分辨率,并增加了沿途特征通道的数量(256;384;384;384;512)。当对特征进行上采样时,我们应用了两个残差模块。在每个跳过连接中还用了两个残差模块,所以在沙漏模块中共有四个残差模块。作者在沙漏模块之前使用7*7conv将feature map大小降低4倍,然后接步长2通道为256的残差块(同resnet)。
2.2 Heatmaps
top-left 和 bottom-right 的 Heatmaps 任务分别有C个channel,C为Object类别数(不包含背景),每个channel大小为H*W,表示对应类别的目标角点的heatmap。每个角点只有一个位置为正样本位置,其余位置均为负样本位置。

作者以每个groudtruth corner点为圆心找了一个圆,圆的半径是根据将圆内的点作为预测corner点所组成的目标框和gt目标框的IOU大于某个阈值来设定的。训练的时候对圆内的某点通过高斯公式计算进行惩罚,如下
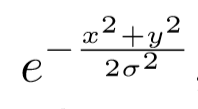
其中 σ = r/3,x,y为圆内某点相对于圆心的位置,计算的结果就代表该点的groundtruth值。
heatmap的loss按如下公式进行计算——改进的focal loss:
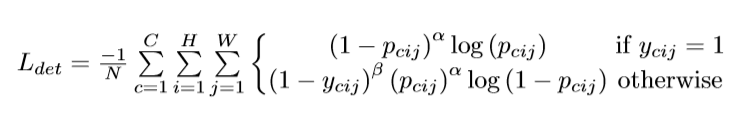
其中(c∈1,2,...C, i∈1,2...W, j∈1,2,...H)为预测值,
(c∈1,2,...C, i∈1,2...W, j∈1,2,...H)为groundtruth值。
2.3 Offsets
在原图中的坐标(x,y)在对应到1/n 的下采样网络的输出后其坐标为,因此会损失小数部分的精度,对小目标位置的精度会产生较大影响。所以,为了使输出feature map上的坐标反推原图上的坐标时更准确,作者对Offsets进行预测,加在预测的location坐标上,再反推目标在原图上的坐标。
有一点要注意:对于top-left角点分支,所有的类别共享一组offset值,即输出的feature maps 的 channel数为2,大小为W*H,一个channel为x的offset值,一个channel为y的offset值;bottom-right角点同上。
groundtruth:
![]()
Loss:

2.4 Embeddings
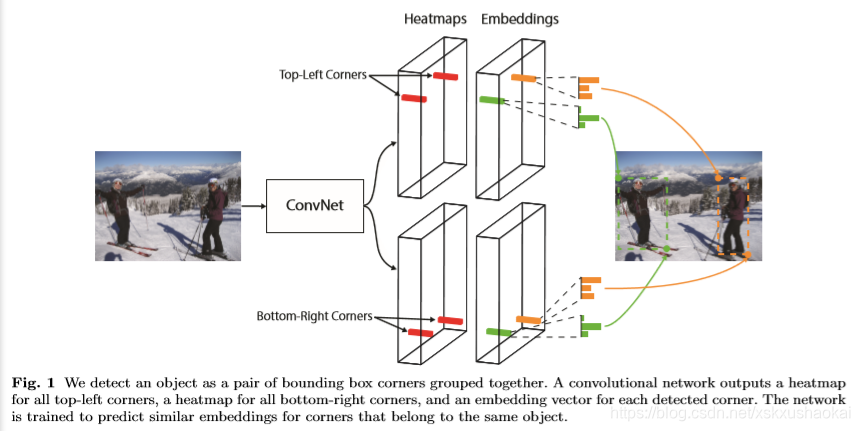
从Embeddings模块中提取出每个ground-truth corner点的值,记作 和
,分别代表top-left 和 bottom-right corner。求所有同一对角点的embedding值方差和,最小化该值,作为“pull” loss,同一对角点的均值记作
= (
+
) / 2,同时最大化非同对角点的均值差,作为“push” loss。最小化这两个loss。
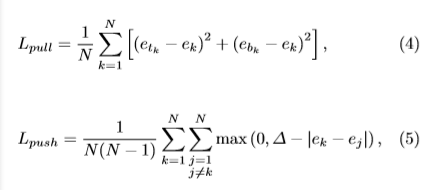
注意:这两个loss只对ground-truth目标的corner点计算
2.5 Corner Pooling

引入corner pooling的原因:
corner点附近的区域其实大多时候使不包含目标的,但是从corner点往横向和纵向看过去可以看到目标的边界,基于这个特性,作者引入了corner pooling,其目的就是找corner点的两条邻边,两条邻边找到了就能确定一个corner点了。
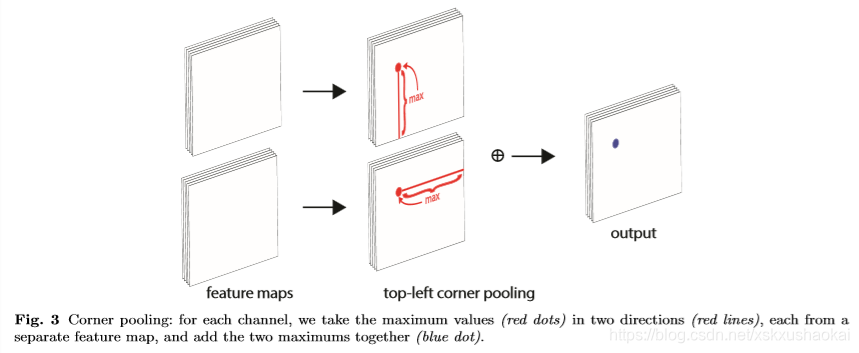
如上图所示,以 top-left corner pooling为例,corner pooling操作在两组feature map上分别进行,计算点(x, y) 处的corner pooling值时,一组feature map沿着 (x, y) 点向右计算,取该点右侧所有点的最大值作为该点的pooling值,另一组feature map沿着(x, y) 点向下计算,取该点下方所有点的最大值作为该点的pooling值,最后将两组feature map对应相加得到最终的corner pooling值。
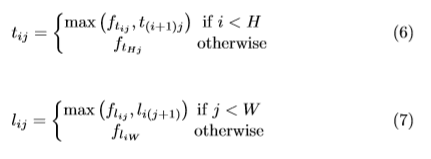
其中,W*H为feature map 宽、高,为向右pooling时(i, j)点的pooling值,
为向下pooling时(i, j)点的pooling值,
为pooling计算前点 (i, j) 处的值。从上式能看出,实际代码中计算top-left corner pooling时是从点 (i, j) 的最右侧点和最下方点开始计算的,为了减小计算复杂度。如下:
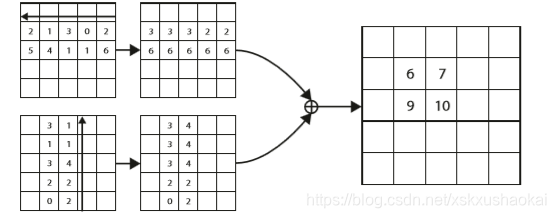
bottom-right 分支的corner pooling 计算方式与 top-left 相反。
基于以上内容,就可以看明白作者的预测模块的网络结构了:
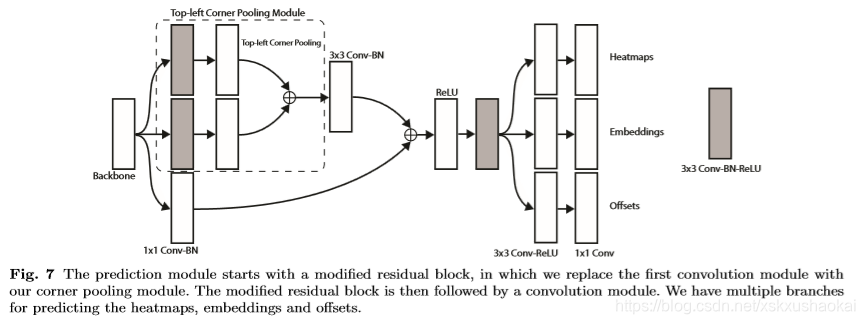
3. train
训练时,网络输入大小为511*511,输出大小为128*128。采用标准数据增强技术,包括随机水平翻转,随机缩放,随机裁剪和随机颜色抖动:包括调整图像的亮度,饱和度和对比度。此外,作者还用PCA算法处理了输入图像。训练损失为四项子损失加权和:。α 和 β 值设为0.1,γ值设为1,训练过程中作者发现α 和 β 的值设的过大模型学习效果较差。
4. test
在预测阶段,作者在heatmaps上使用3*3 maxpooling层来进行NMS操作。然后取前100个top-left点和前100个bottom-right点,用offset值微调corner点的位置。然后计算top-left点和bottom-right点的L1距离,距离大于0.5的或者top-left与bottom-right点类别不同的corner对将被丢弃,其余满足条件的corner对将作为预测的目标,top-left和bottom-right的平均分数作为检测结果的得分。
同时使用原图与翻转后的图预测目标,将两者结合得到最终结果。最后用soft-nms滤掉多余的框。

















 805
805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









