







vector是stl中正式的一员,与string比起来,vector实现的就更简洁,更规范。
vector翻译过来是向量的意思,而实际上,vector就是一个顺序表,其大小是可以改变的。
vector是一个标准的类模板,它可以存储各种类型。T就是vector内部存储的数据类型,而allocator是stl的六大组件之一的空间配置器,也就是内存池,现在先不需要了解,只需要vector是从这里申请和释放空间的。
一.vector的使用
1.构造
vector的构造和string比起来就简单很多了:
第一个是用空间配置器初始化,也可以理解为默认构造。
第二个是用n个value值来初始化,value_type是vector中typedef出来的,实际上就是模板参数T。
第三个是用一段迭代器区间来初始化。
第四个是拷贝构造
vector<int> iv1;
vector<int> iv2(10, 1);
vector<int> iv3(++iv2.begin(), --iv2.end());
vector<int>iv4(iv2);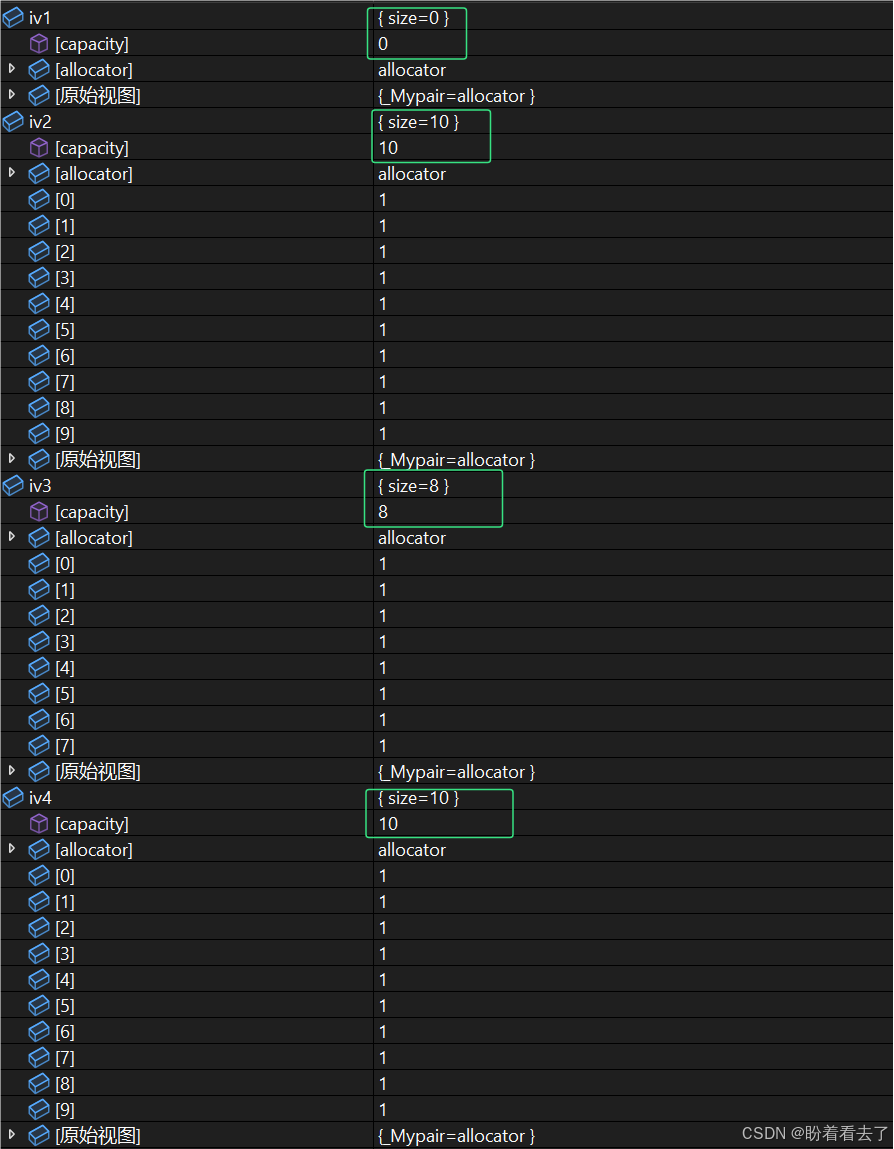
2.iterator和operator[]
vector的迭代器和string的迭代器相同,都是四种,使用方法也相同。
vector是顺序表,底层就是数组,所以也可以用数组的下标方式来访问,因此也重载了operator[]。
我们可以借助operator[]和迭代器来实现遍历vector。
其支持迭代器当然也支持范围for。
vector<int> iv2(10, 1);
size_t i = 0;
for (; i < iv2.size(); i++)
{
cout << iv2[i] << " ";
}
cout << endl;
vector<int>::iterator vi = iv2.begin();
while (vi != iv2.end())
{
cout << *vi << " ";
++vi;
}
cout << endl;
for (auto e : iv2)
{
cout << e << " ";
}
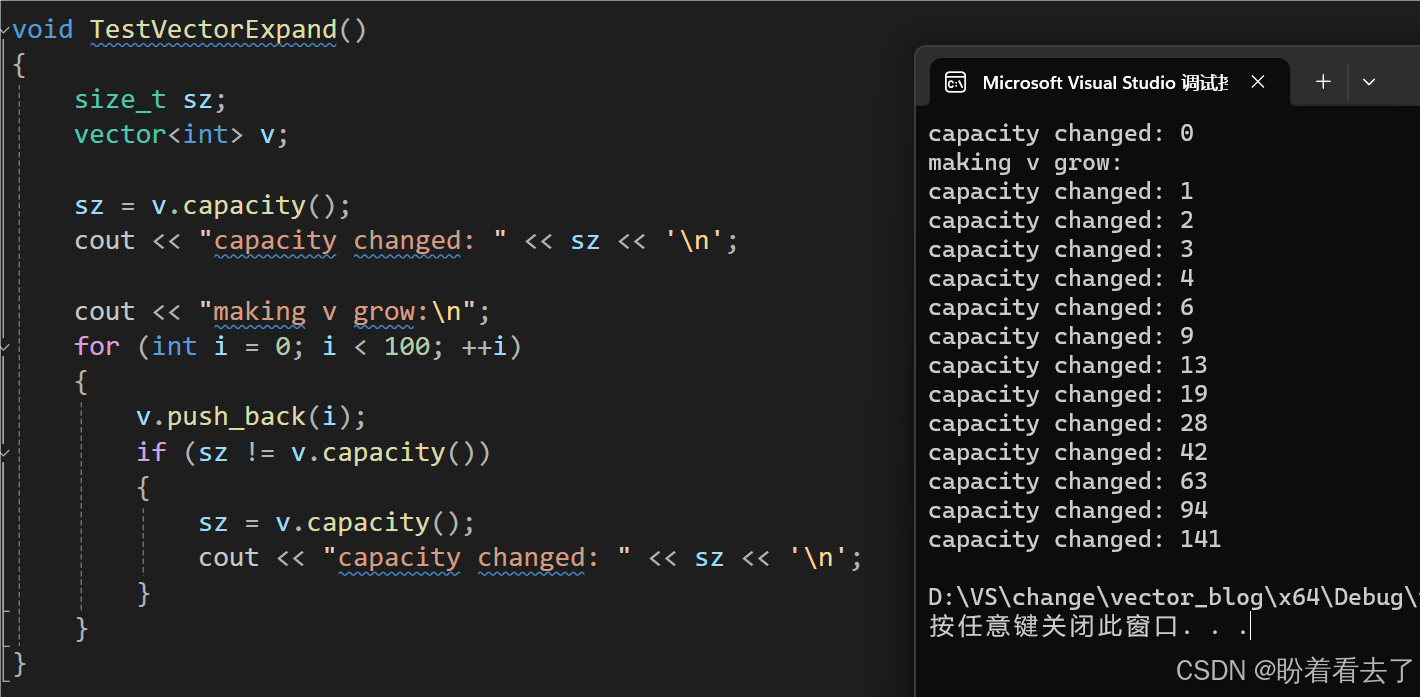
cout << endl;3.vector的扩容机制
VS2022下:
可以看到是标准的1.5倍扩容。
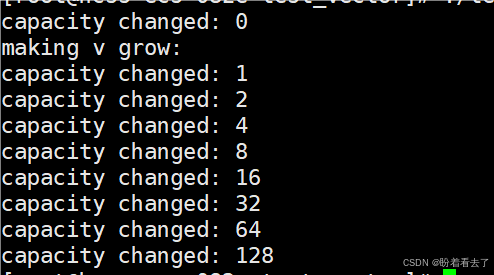
g++下:
在该环境下是标准的2倍扩容。
void TestVectorExpand()
{
size_t sz;
vector<int> v;
sz = v.capacity();
cout << "capacity changed: " << sz << '\n';
cout << "making v grow:\n";
for (int i = 0; i < 100; ++i)
{
v.push_back(i);
if (sz != v.capacity())
{
sz = v.capacity();
cout << "capacity changed: " << sz << '\n';
}
}
}4.reserve
在string中,reserve对n大于size小于capacity时,是否缩容是不确定的,在VS下不缩容,g++下缩容。而在vector中,reserve给出了明确的声明:在n<=capacity的情况下,是不会重新分配空间,不会对顺序表造成影响。
VS下:
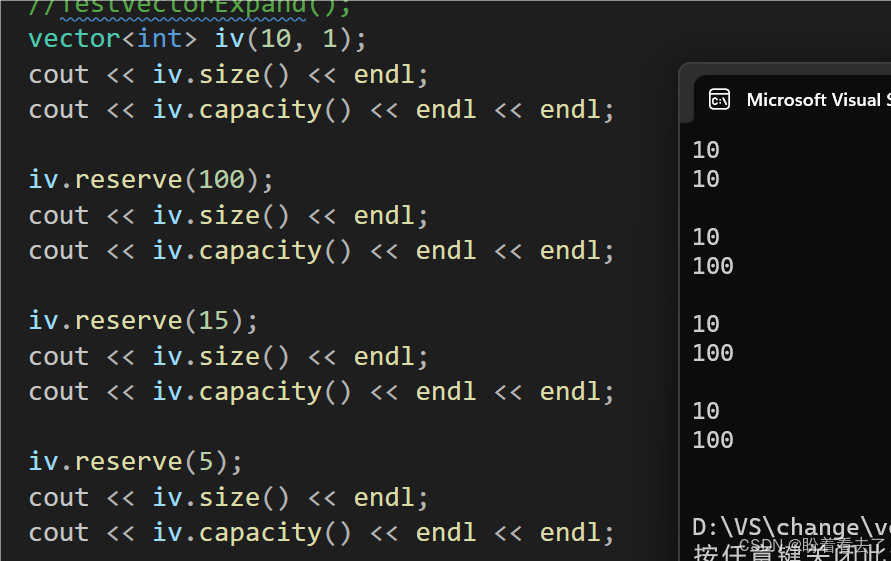 g++下:
g++下:

不论是哪种环境,其reserve都不会改变容量。
5.insert/erase
对于insert和erase来说,不在支持以下标的形式去插入,都是用迭代器来插入。这也是为了和后面的容器保持一致,毕竟不是所有的容器都可以用下标来访问数据。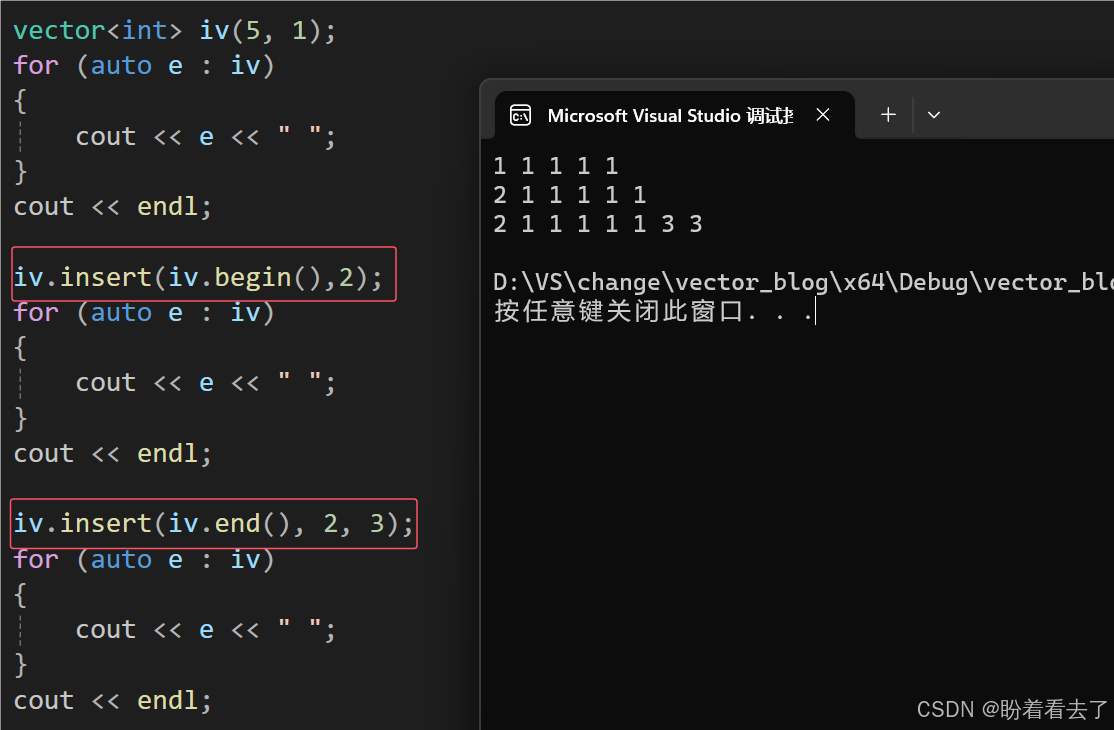
6.流插入与流提取
vector并没有重载流插入和流提取,但对于顺序表来说,实现这两个接口非常简单,需要用时自己实现即可。
vector<int> iv(5,0);
size_t i = 0;
for (; i < iv.size(); ++i)
{
cin >> iv[i];
}
for (auto e : iv)
{
cout << e << " ";
}
cout << endl;7.vector<char>
vector作为模板,既可以存储int,也可以存储char,那么是否可以用vector<char>来代替string?
答案是不行!
因为在string对象中,每一个字符串结尾都一个\0,且string实现的各种接口vector<char>并不能替代:string的比较方式和vector的比较方式不同、string可以获取字串vector不能;
而且就算给vector后面也放一个\0,此时符合了string的格式,但是vector又不仅仅存char,存了int这个\0又算是个啥。
8.vector<vector<int>>
vector的模板参数不仅仅可以是内置类型,也可以是自定义类:string、vector<int>等等。
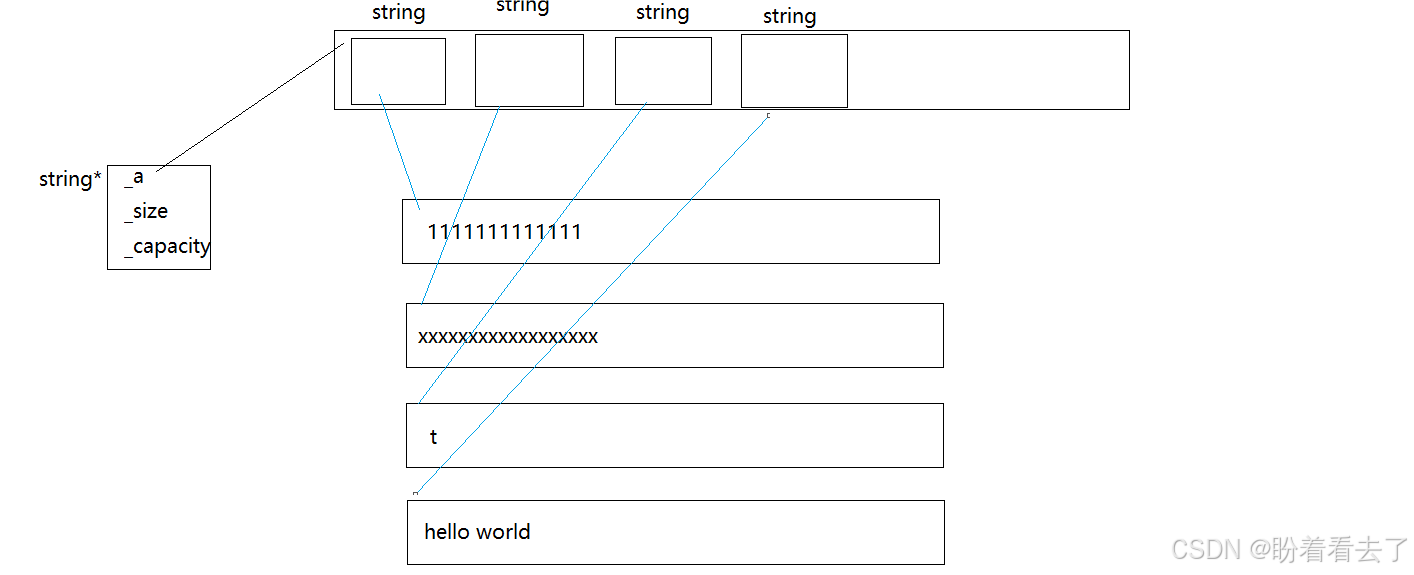
可以借助vector来模拟实现二维数组:
vector<int> v(5, 1);
vector<vector<int>> vv(10,v);这样就可以实现一个10行5列的二维数组。
对于vector<int>来说,他又三个成员变量_a(指向堆上的那块数组),_size(元素个数),_capacity(容量)。它存储的数据类型是int,那么_a的类型就是int*。
对于vector<vector<int>>来说,_a的类型时vector<int>*,指向的空间中每一个对象都是一个vector<int>,而vector<int>又指向另一块空间,空间上存储的是int。
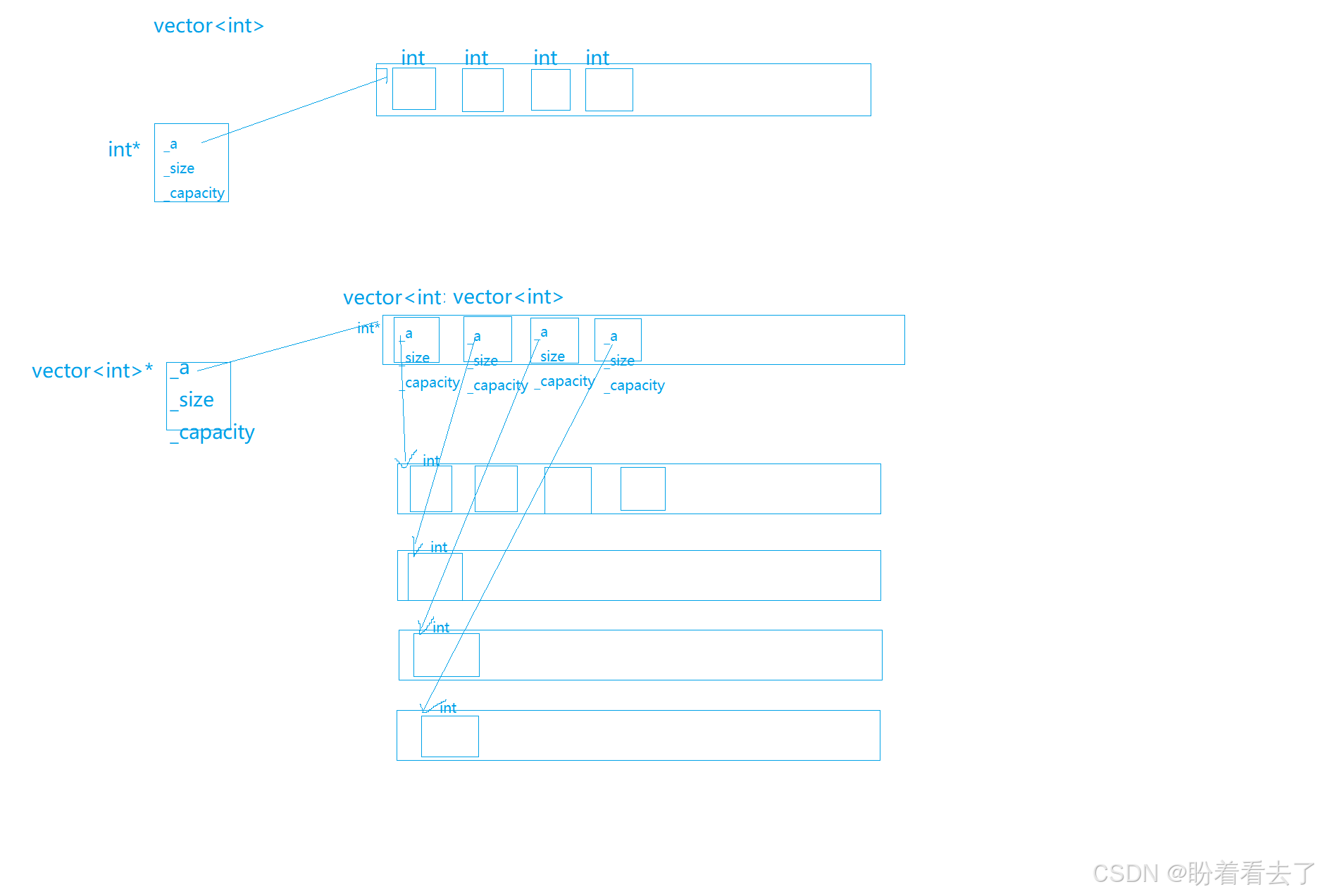
vector重载了[],使得vector可以像数组那样利用下标来访问,所以对于vector<vector<int>>来说,它也可以向二维数组那样借助vv.[i][j]来访问第i行第j列的数据。
vector<int> v(5, 1);
vector<vector<int>> vv(10,v);
for (size_t i = 0; i < vv.size(); ++i)
{
for (size_t j = 0; j < vv[i].size(); ++j)
{
cout << vv[i][j] << " ";
}
cout << endl;
}
cout << endl;
vv[2][1] = 2;这里的vv[i][j]其实调用了 两个不同类的operator[]。vv先和第一个[]结合,调用的是vector<vector<int>>这个类的operator[],其返回值是vector<int>的引用;然后与第二个[]结合,调用的是vector<int>这个类的operator[],返回值是int的引用。
借助一个题来理解借助vector实现二维数组:

杨辉三角其实就是一个二维数组,只不过其行数是不确定的,且每一行的长度是不同的,所以用一个定长的二维数组是解决不了的。如果没有vector的话,我们就需要借助malloc来动态开辟一个二维数组
int** aa = (int**)malloc(sizeof(int*) * numRows);
//检查
//...
for (int i = 0; i < numRows; ++i)
{
aa[i] = (int*)malloc(sizeof(int) * (i + 1));
//检查
//...
}利用malloc申请动态的二维数组非常麻烦,而且还需要进行检查等等操作,而且malloc的数组还需要返回数组的长度。
而利用vector实现的二维数组,可以像二维数组那样使用。
class Solution {
public:
vector<vector<int>> generate(int numRows)
{
vector<vector<int>> vv(numRows);
for(int i = 0; i<numRows; ++i)
{
vv[i].resize(i+1,1);
}
for(int i = 2; i<numRows; ++i)
{
for(int j = 1; j<vv[i].size()-1; ++j)
{
vv[i][j] = vv[i-1][j] + vv[i-1][j-1];
}
}
return vv;
}
};二.vector的模拟实现
1.vector的结构
vector和string都是顺序表,所以我们可以认为其内部和string是类似的,一个指向堆空间的指针,一个size,一个capacity。但是为了确认我们可以借助stl源码来观察:
在stl源码中,vector的结构是由三个迭代器实现的,我们可以猜测,start是指向空间开始的位置,finish是指向元素结束的下一个位置,end_of_storage是可用空间的结尾。 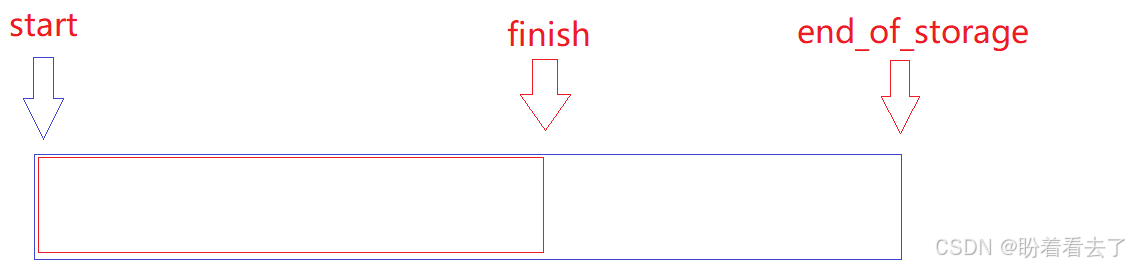
那么iterator到底是什么?
我们之前提到了所有的容器都实现了iterator,而iterator其实是typedef出来的,它的底层可能是原生指针,也可能是其他复杂的类型。而对于vector来说,iterator其实就是T*,也就是原生指针。
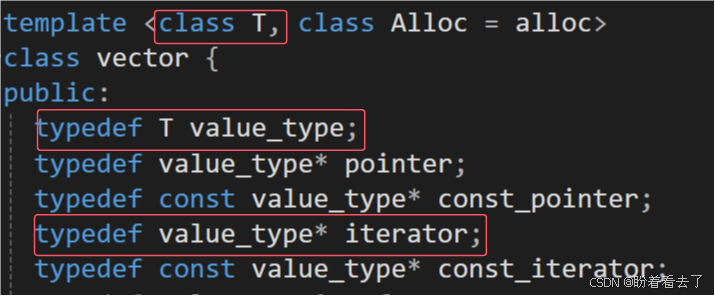
2.size()、capacity()、begin()、end()
对于指向数组不同位置的两个指针来说,指针相减就是中间的数据个数
size_t size() const
{
return _finish - _start;
}
size_t capacity() const
{
return _end_of_storage - _start;
}
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}
const_iterator begin() const
{
return _start;
}
const_iterator end() const
{
return _finish;
}3.push_back()、reserve()
尾插之前要先判断是否还有空间,如果空间满了就需要扩容。
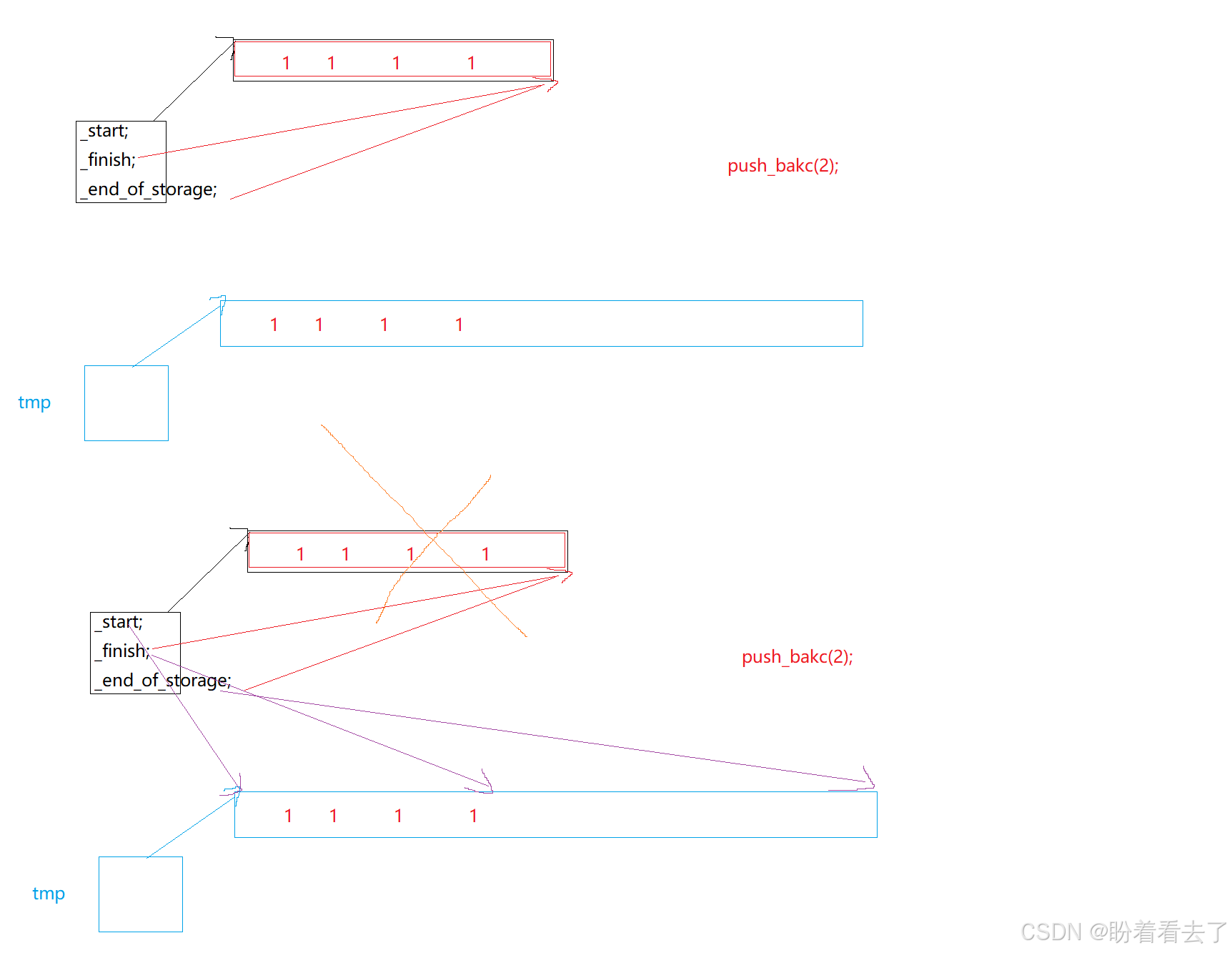
而扩容的逻辑交给reserve来实现:C++标准库里规定,当n小于等于capacity时,是不会引起容量的变化的,所以这里只需要处理n>capacity的情况,开n个空间,拷贝数据到新空间,释放旧空间,然后让_start指向新空间,同时更新_finsih以及_end_of_storage。
void reserve(size_t n)
{
if (n > capacity())
{
T* tmp = new T[n];
memcpy(tmp, _start,size()*sizeof(T));
delete[] _start;
_start = tmp;
_finish = tmp + size();
_end_of_storage = tmp + n;
}
}
void push_back(cosnt T& x)
{
if (_finish == _end_of_storage)
{
reserve(capacity() == 0 ? 1 : 2 * capacity);
}
*_finish = x;
++finish;
}测试尾插:
测试尾插失败了,这是为啥呢?
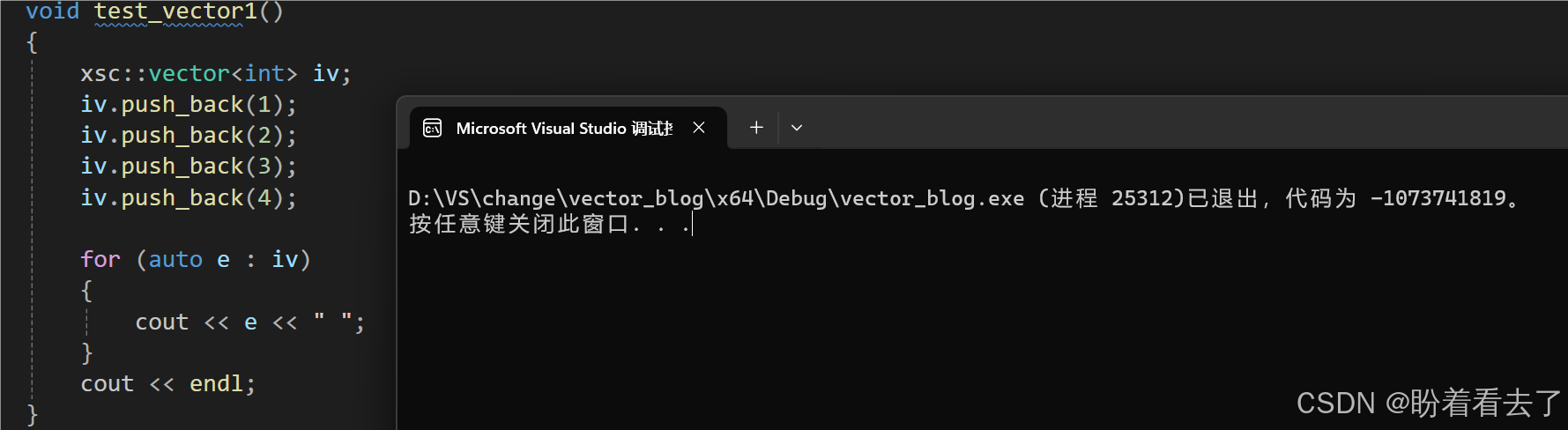
调试发现,是_finish出错了,_finish是空指针。可是我们在reserve时不是已经更新了_finish嘛?为什么还是nullptr呢?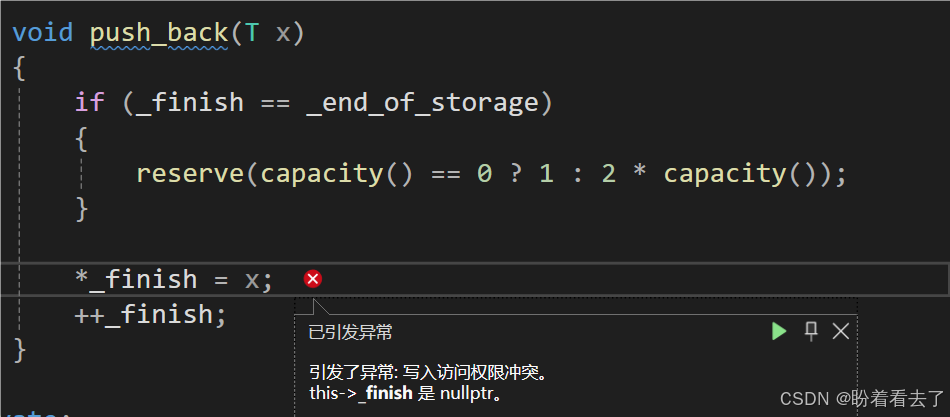
借助图示来分析,因为我们给了成员变量缺省值,而且没有显示写构造函数,所以其会使用默认生成的构造函数,走初始化列表时会被初始化成nullptr。当我们准备插入第一个时,此时capacity和size都是0,需要扩容n=1.到底reserve里面后,tmp开好一个空间后,移动数据,删除原空间,指向新空间。然后更新finish时,此时的size()已经改变了,当我们将该表达式展开发现,_start和tmp抵消掉了,_finish还是nullptr没有改变。所以回到push_back中就会发生对空指针的解引用。
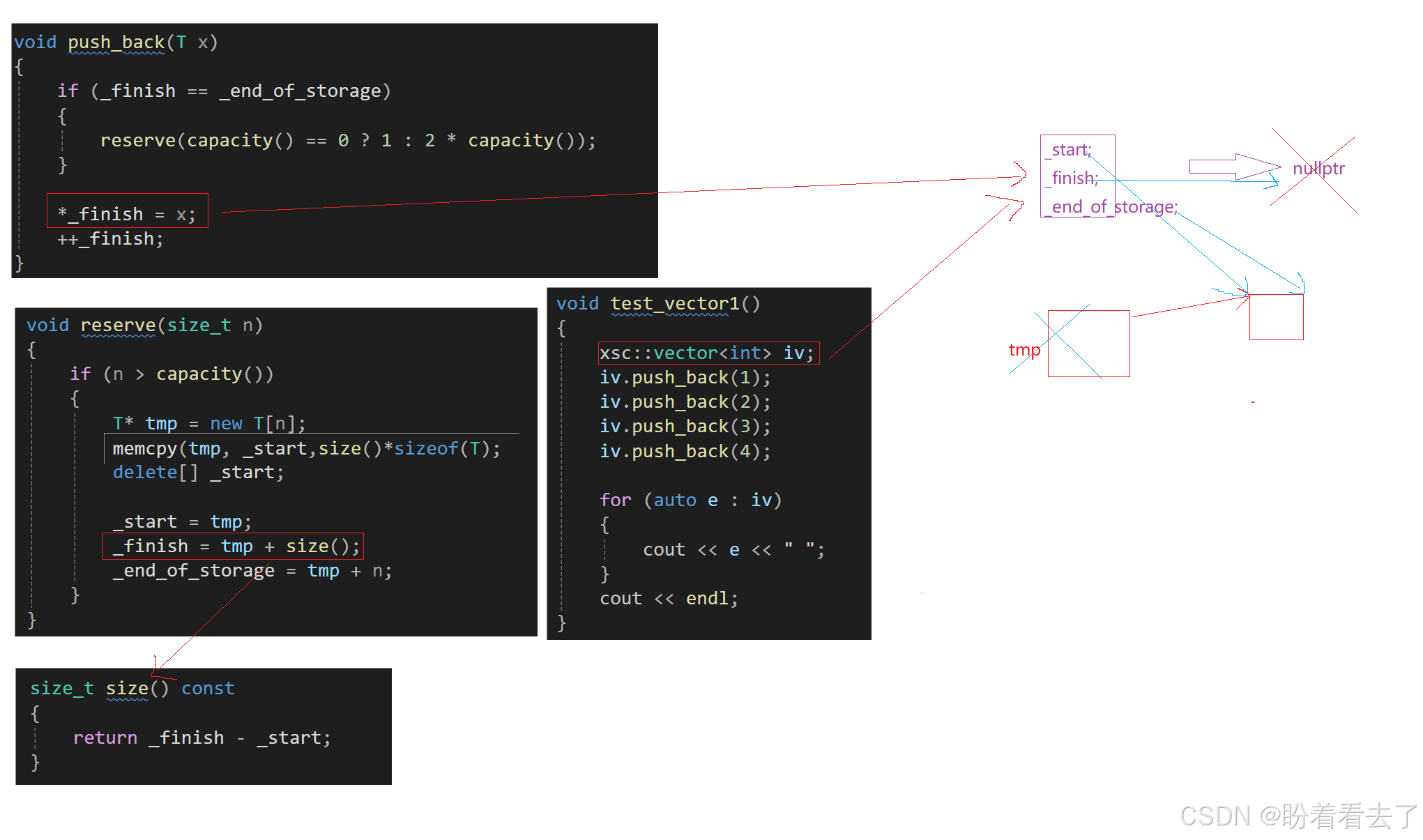
解决方式:1、问题就出在,_start已经更新了,调用size时,_finish还是旧的,导致size变化,所以我们可以在_start还没改变前,先改变_finish。
void reserve(size_t n)
{
if (n > capacity())
{
T* tmp = new T[n];
memcpy(tmp, _start,size()*sizeof(T));
delete[] _start;
_finish = tmp + size();
_start = tmp;
_end_of_storage = tmp + n;
}
}2、创建一个临时变量old_size来记下之前的数据个数,避免调用size()函数。
void reserve(size_t n)
{
if (n > capacity())
{
size_t old_size = size();
T* tmp = new T[n];
memcpy(tmp, _start,size()*sizeof(T));
delete[] _start;
_start = tmp;
_finish = tmp + old_size;
_end_of_storage = tmp + n;
}
} 经测试,这两种写法都可以解决该问题,但是为了可读性,建议写第二种
4.insert()
insert()在指定位置插入数据时,指定位置是一个迭代器,插入前也要先判断是否还有空间,没有就要扩容。
如果发生扩容就要谨慎,扩容之后_start,_finish,_end_of_storage都指向了新空间,如果不更新pos的话,pos还指向原来的空间,而原来的空间在扩容时就已经释放了,pos此时就类似一个野指针,此时直接插入的话就会导致程序崩溃,这就是一个简单的迭代器失效。
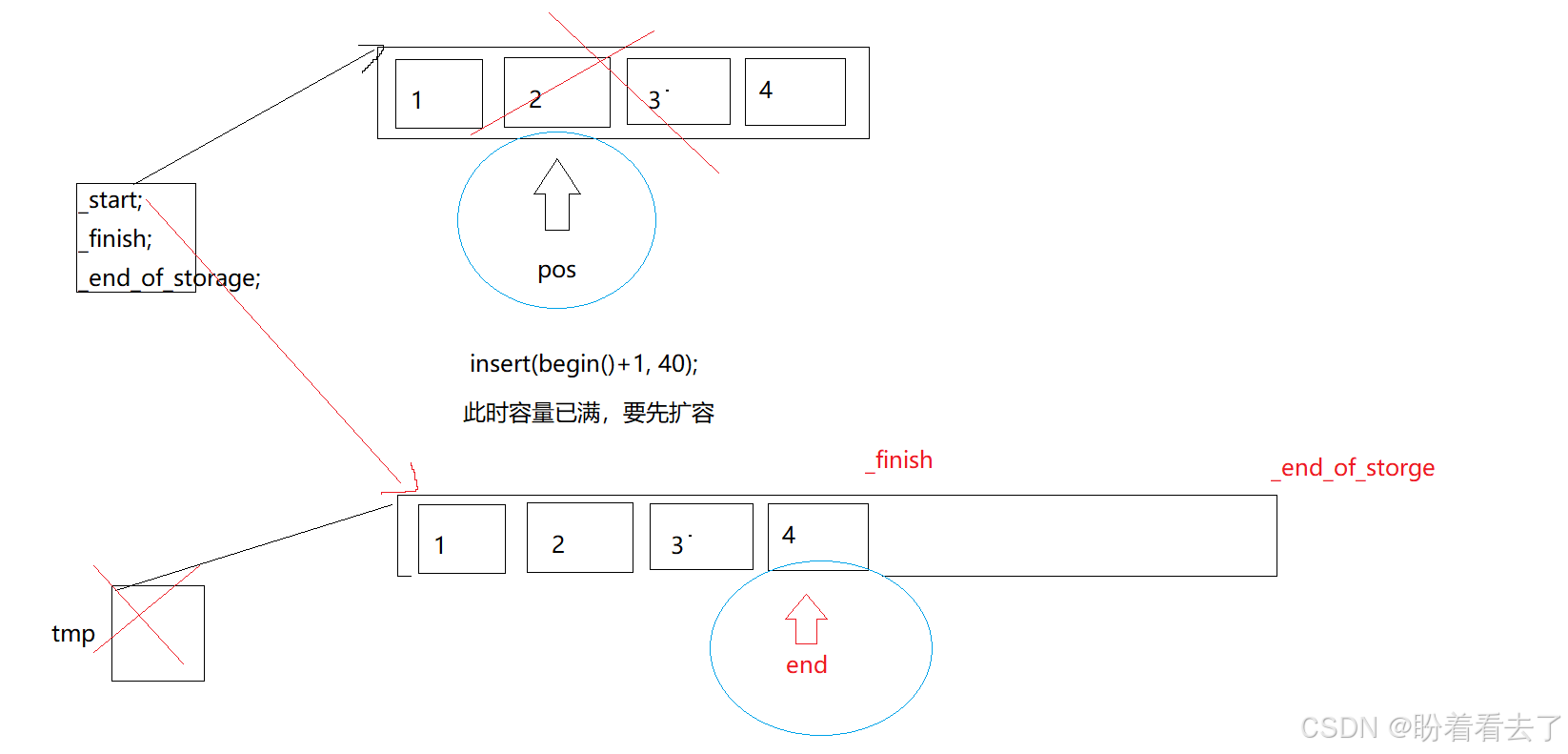
void insert(iterator pos, const T& x = T())
{
assert(pos <= _finish);
size_t len = pos - _start;
if (_finish == _end_of_storage)
{
reserve(capacity() == 0 ? 1 : 2 * capacity());
pos = _start + len;//更新pos位置,避免因为扩容导致pos还指向旧空间
}
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
--end;
}
*pos = x;
++_finish;
}测试insert():
void test_vector2()
{
xsc::vector<int> iv;
iv.push_back(1);
iv.push_back(2);
iv.push_back(3);
iv.push_back(4);
for (auto e : iv)
{
cout << e << " ";
}
cout << endl;
iv.insert(iv.begin() + 1, 40);
for (auto e : iv)
{
cout << e << " ";
}
cout << endl;
iv.insert(iv.begin(), 100);
for (auto e : iv)
{
cout << e << " ";
}
cout << endl;
iv.insert(iv.end(), 1200);
for (auto e : iv)
{
cout << e << " ";
}
cout << endl;
}
下面这段程序,当x=2时,结果是什么?
void test_vector3()
{
xsc::vector<int> iv;
iv.push_back(1);
iv.push_back(2);
iv.push_back(3);
iv.push_back(4);
iv.push_back(5);
for (auto e : iv)
{
cout << e << " ";
}
cout << endl;
int x = 0;
cin >> x;
auto pos = find(iv.begin(), iv.end(), x);
if (pos != iv.end())
{
iv.insert(pos, 40);
for (auto e : iv)
{
cout << e << " ";
}
cout << endl;
*pos *= 10;
for (auto e : iv)
{
cout << e << " ";
}
cout << endl;
}
cout << endl;
}我们在插入40之后,打印结果应该为1 40 2 3 4 5;然后我们对pos位置上的数乘等10,按照程序理解,结果应该为1 40 20 3 4 5;但实际上结果是1 400 2 3 4 5;
上面的结果还是没有扩容的情况,当扩容后在乘等的话,结果依旧是1 40 2 3 4;
发生这样的结果是为什么呢?其实这也是一种迭代器失效。
注意:insert以后pos就失效了,不要直接访问,要访问就要先更新pos。
情况一(未扩容):pos位置没有改变,但是插入数据之后,pos就指向了新插入的数据,原数据再pos的下一个位置上,所以结果是1 400 2 3 4.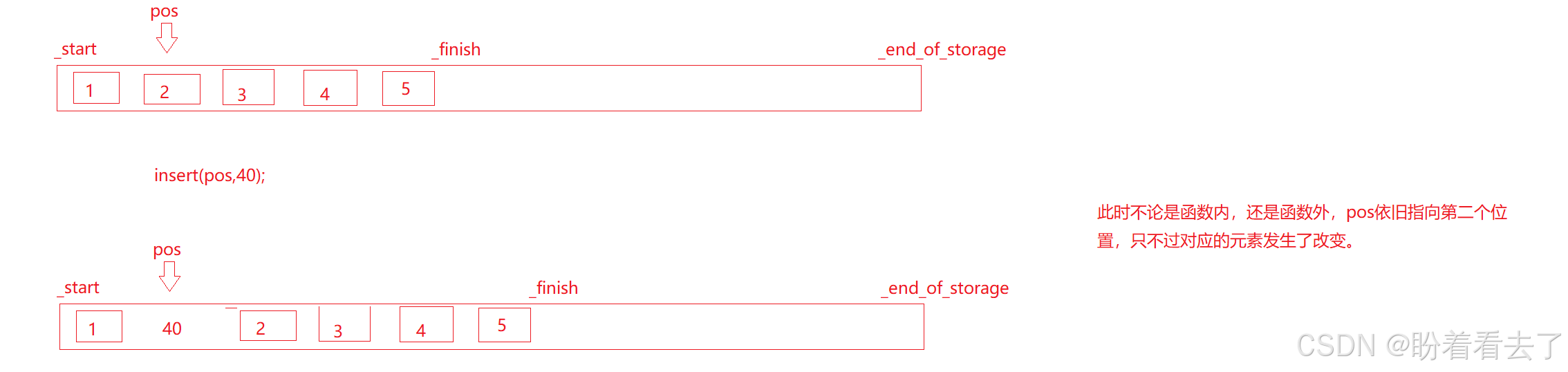
情况二(扩容):pos已经更新了,插入数之后,pos也指向了新数据,但是回到调用函数处,pos还指向的是之前的旧空间,虽然insert内部更新了,但是形参改变不影响实参。所以结果依旧是1 40 2 3 4 5.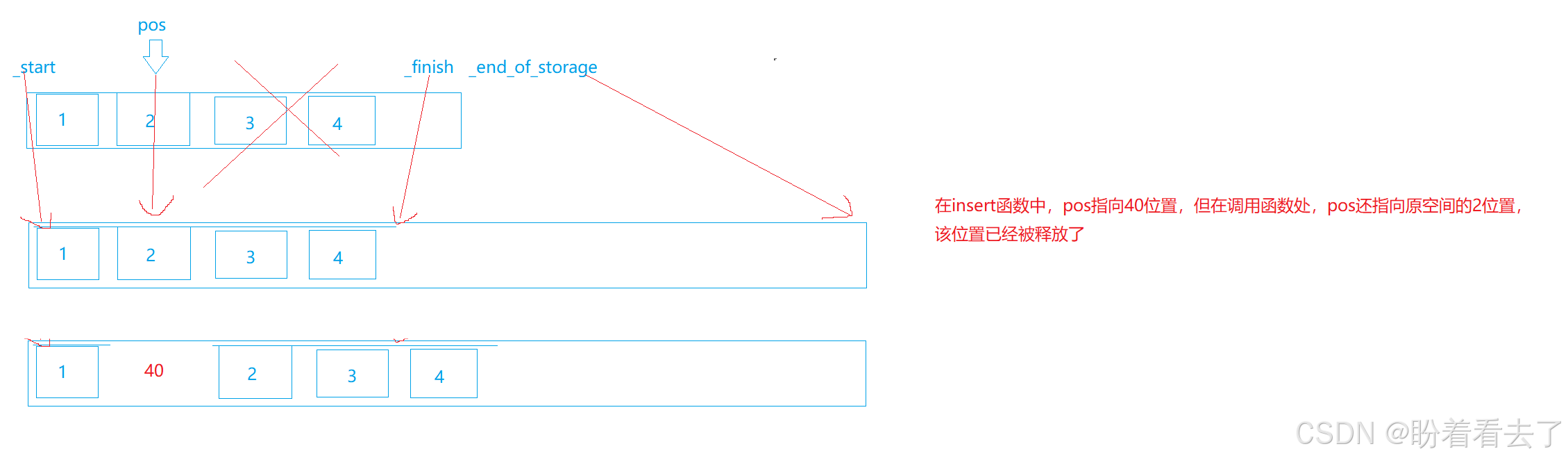
那我们是否在insert内部更新一下pos就可以了?
pos = pos + 1;答案是不行!我们传的是实参,改变的是形参,形参改变不影响实参。
那我们是否可以传pos的引用?
答案也是不行!如果写成了引用的话,就不再支持这样子的插入的了:
insert(iv.begin()+1,1);传第一个参数时,会先构造一个临时变量,而临时变量具有常性,常量不可以传给普通的引用。

其实标准库里面的insert是通过返回一个迭代器来结果这个问题的:
return pos;当我们在想给原pos位置操作时,就可以这样:
pos = iv.insert(pos, 40);
*(pos + 1) *= 10;5.迭代器失效
这里对迭代器失效进行总结:
迭代器失效目前了解了两种:
第一种就类似于野指针,当insert时需要扩容,会申请新空间,拷贝内容,释放旧空间,虽然在insert内部更新了pos,但是调用处的pos依旧指向已经被释放的空间。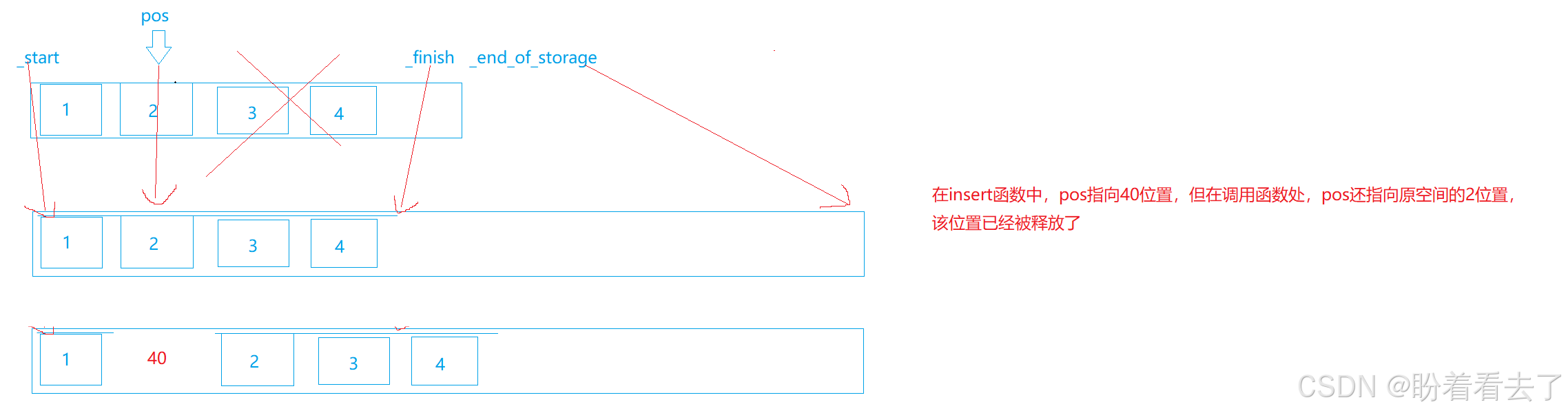
第二种就是pos指向的元素已经改变了,此种情况并未发生扩容,但是pos位置上的数据挪到了下一个位置,pos的意义已经改变了,不再指向原来的元素。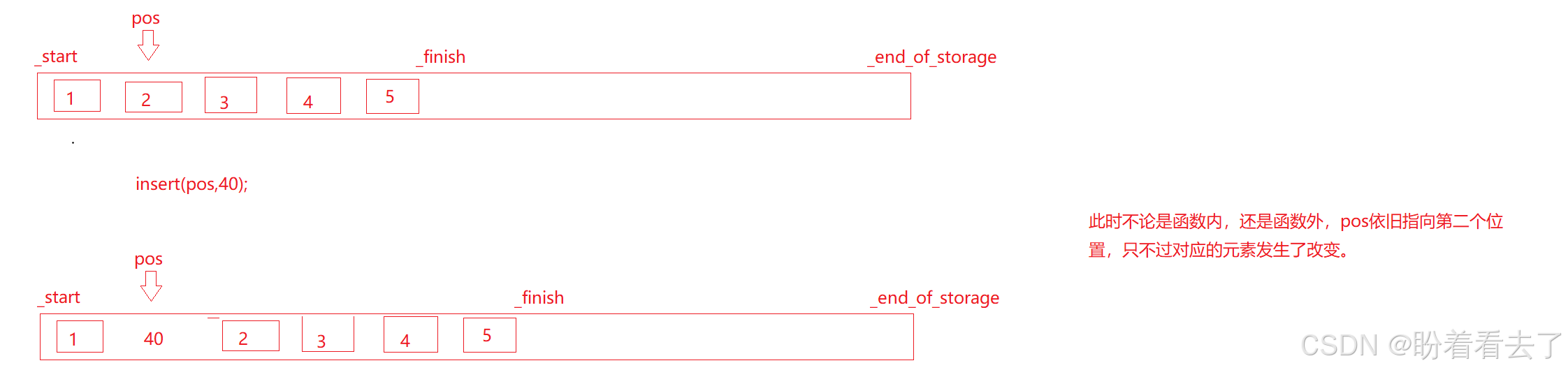
总之,再insert之后会导致迭代器失效,不要直接访问。
6.erase()
erase()删除一个指定迭代器位置上的数据,然后将后面的数据往前挪,最后还要--_finish。
void erase(iterator pos)
{
assert(pos < _finish);
auto it = pos + 1;
while (it != _finish)
{
*(it - 1) = *it;
++it;
}
--_finish;
}借助erase实现一个删除偶数的程序
void test_vector4()
{
xsc::vector<int> iv;
iv.push_back(1);
iv.push_back(2);
iv.push_back(3);
iv.push_back(4);
iv.push_back(5);
for (auto e : iv)
{
cout << e << " ";
}
cout << endl;
auto it = iv.begin();
while (it != iv.end())
{
if (*it % 2 == 0)
{
iv.erase(it);
}
++it;
}
for (auto e : iv)
{
cout << e << " ";
}
cout << endl;
}对这段程序进行测试,有下面三种情况
这是为什么呢?
在连续的偶数出现时,删除之后,it已经指向下一个元素了,这是有++it,导致跳过了4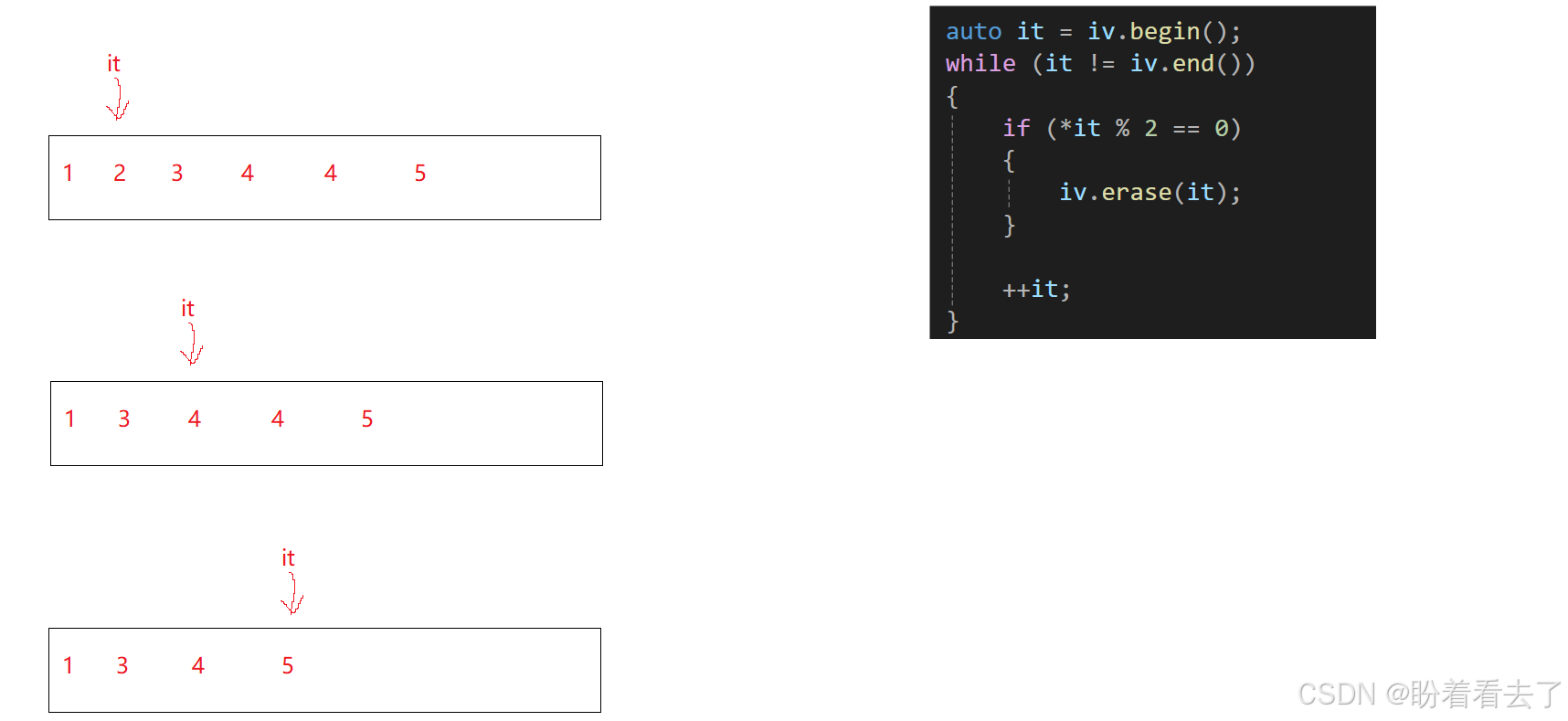
第二种情况在删除2之后,p++,跳过了一个元素,直接指向了最后一个元素4,此时进入erase内部,it就会指向p+1的位置也就是_finish的位置,导致不会挪动数据而直接--_finish,然后p++,再次进入(进入是因为原本的4还在这个位置上,只不过_finish--了而已),此时p就已经大于_finish了,导致断言错误。

这也是一种迭代器失效,所以在erase之后也不要直接访问。要解决这个问题,可以返回一个迭代器,指向删除元素的下一个元素。这就不会导致漏元素了。
iterator erase(iterator pos)
{
assert(pos < _finish);
auto it = pos + 1;
while (it != _finish)
{
*(it - 1) = *it;
++it;
}
--_finish;
return pos;
}
auto p = iv.begin();
while (p != iv.end())
{
if (*p % 2 == 0)
{
p = iv.erase(p);
}
else
{
++p;
}
}删除时也要改变逻辑,删除了就不需要++,否则会跳过元素。
需要注意的是:g++环境下,和我们实现的是相同的,它同样会犯那些错误。而vs下会直接报错,erase和insert之后都不允许访问。
7.resize()
resize是一个对size进行操作的接口,他有三种情况:
1、n<size(),此时需要删除数据
2、size()<n<capacity(),需要插入数据但不需要扩容
3、n>capacity(),需要插入数据,且需要扩容
我们在处理2、3情况时可以直接reserve(n),因为n<capacity是不会扩容的,所以没有影响。然后只需要放数据到数据个数为n。
void resize(size_t n, const T& val = T())
{
if (n < size())
{
_finish = _start + n;
}
else
{
reserve(n);
while (_finish < _start + n)
{
*finish = val;
++finish;
}
}
}需要注意的是,这里val给了缺省值,如果是自定义类型则会调用其默认构造,那内置类型呢?
在之前内置类型是没有构造函数这个概念的,但是随着发展,内置类型也支持了构造函数。
int i = int();
int j = int(1);
int k(2);
8.拷贝构造
vector(const vector<T>& v)
{
reserve(v.size());
for (auto& e : v)
{
push_back(e);
}
}但是当我们实现了拷贝构造之后,编译器便不会再自动生成默认构造,导致不支持这种写法
不写拷贝构造,编译器会生成一个拷贝构造,不写赋值运算符重载,编译器会生成一个赋值运算符重载,但是对于默认构造来说,是没有任何一个构造,编译器就会生成一个默认构造,只要有任何一种构造就不会再生成了。
所以还需要提供一个默认构造
//vector(){}
vector() = default;下面是C++11的写法,强制生成一个默认构造。
9.赋值运算符重载
现代写法
void swap(vector<T>& v)
{
std::swap(_start, v._start);
std::swap(_finish, v._finish);
std::swap(_end_of_storage, v._end_of_storage);
}
vector<T>& operator=(vector<T> v)
{
swap(v);
}10.其他构造
用n个val值初始化
vector(size_t n, const T& val = T())
{
reserve(n);
for (size_t i = 0; i < n; ++i)
{
push_back(val);
}
}用一段迭代器区间初始化
template <class InputIterator>
vector(InputIterator first, InputIterator last)
{
int len = last - first;
reserve(len);
while (first != last)
{
push_back(*first);
++first;
}
}但是当上面两个构造同时出现时,遇到下面这种初始化方式就会报错:
xsc::vector<int> iv2(10, 1);因为编译器会调用最匹配的函数,我们本意是用10个1来初始化,但是对于第一个函数来说,size_t和int之间要发生转换,第二个参数推成int
而对于第二个函数来说,会将1、2两个参数都推成int,更符合传参逻辑,所以就会调用该函数,但是在该函数内部,就会发生错误。
为了避免这种情况,我们可以写一个更加符合的函数,来避免调用不想调用的函数
vector(int n, const T& val = T())
{
reserve(n);
for (int i = 0; i < n; ++i)
{
push_back(val);
}
}11.当T是自定义类型,且需要扩容时
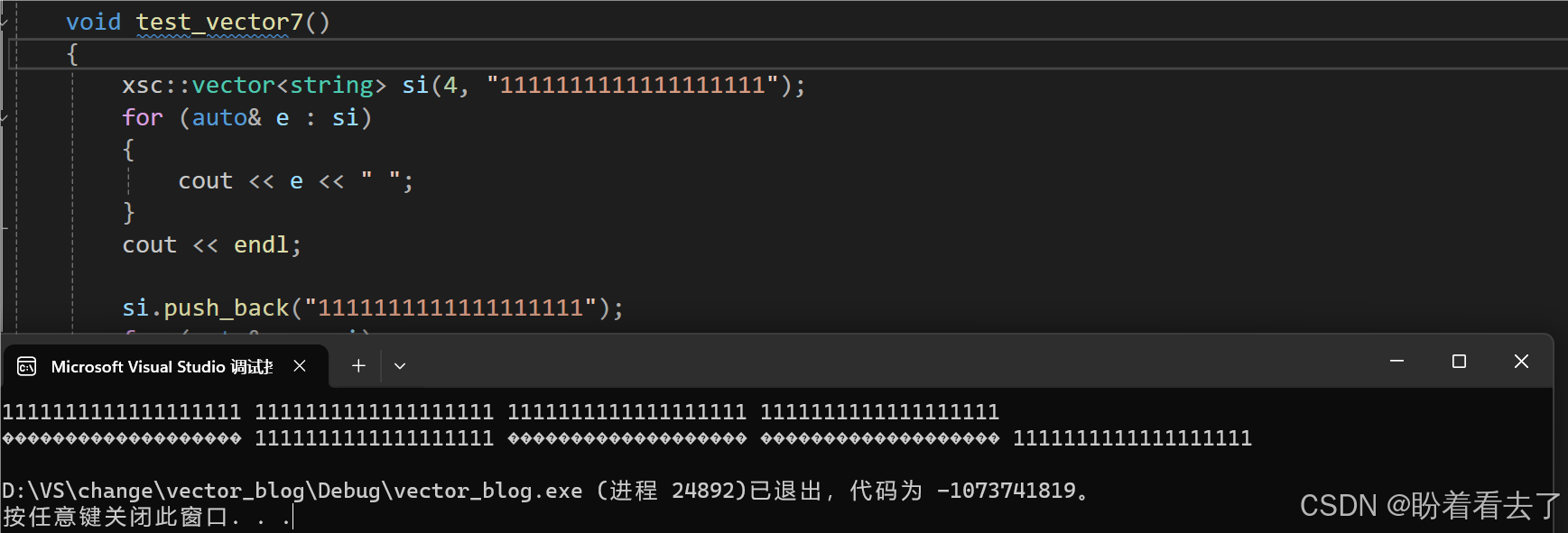
我们可以看到程序崩溃了,为什么内置类型就不会出错呢?
原因在于扩容时memcpy是浅拷贝,导致新空间和就空间指向的是同一块空间,程序结束时导致析构了两次。 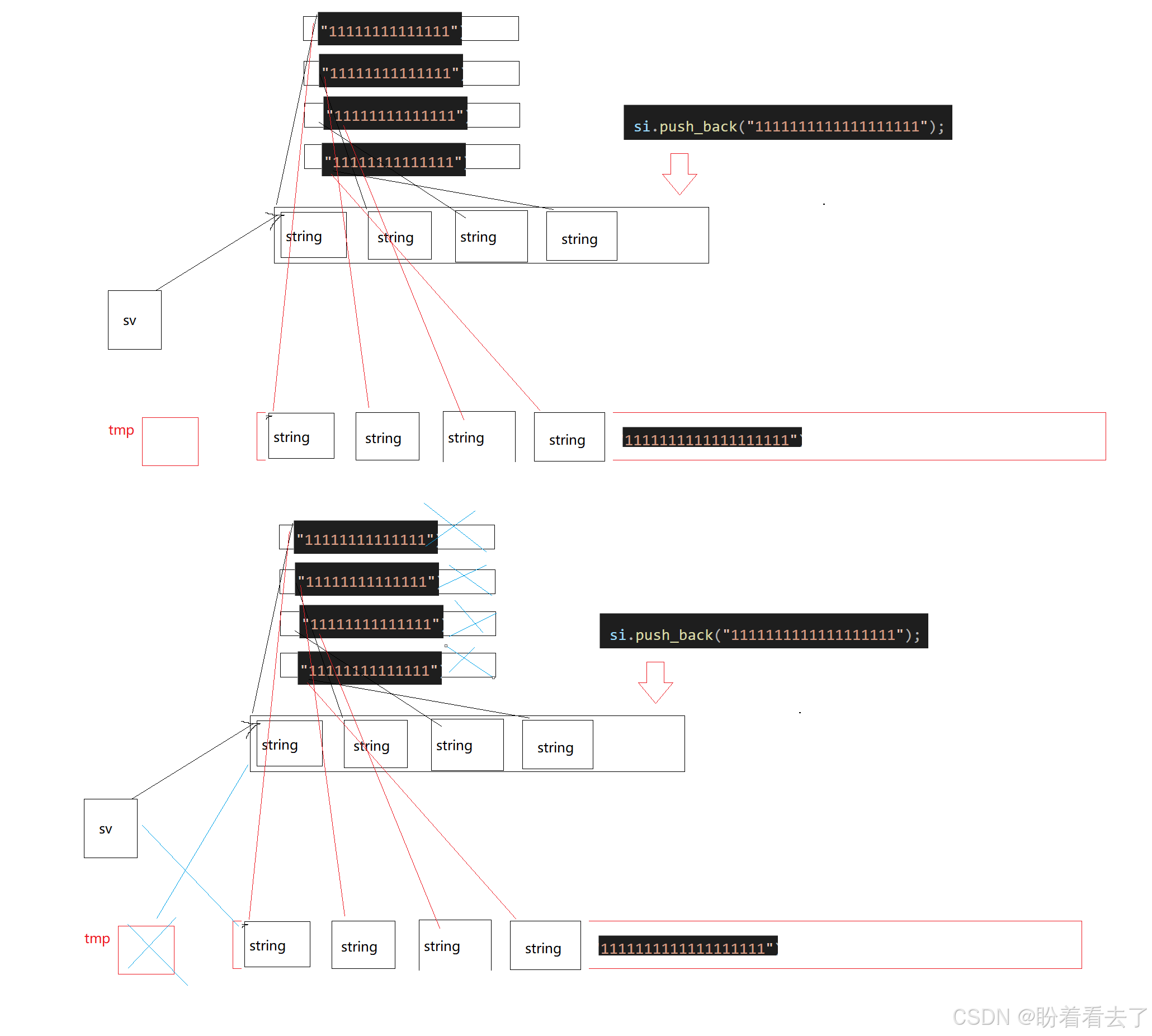
所以我们要避免浅拷贝,使用深拷贝:
void reserve(size_t n)
{
if (n > capacity())
{
size_t old_size = size();
T* tmp = new T[n];
//memcpy(tmp, _start,size()*sizeof(T));
for (size_t i = 0; i < size(); ++i)
{
tmp[i] = _start[i];
}
delete[] _start;
_start = tmp;
_finish = tmp + old_size;
_end_of_storage = tmp + n;
}
}

















 3248
3248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









