







 本文探讨了端到端语音识别技术的发展,介绍了使用CNN学习传统特征提取步骤的研究,并对比了几种不同网络结构如CLDNN和CNN+TDNN在语音识别任务上的表现。
本文探讨了端到端语音识别技术的发展,介绍了使用CNN学习传统特征提取步骤的研究,并对比了几种不同网络结构如CLDNN和CNN+TDNN在语音识别任务上的表现。
现在的端到端语音识别的第一个“端”大部分还是使用人为设定的语音特征,比如FBANK/PLP,更高级的端到端语音识别输入是语音波形,输出是文字。
近几年也有一些工作是使用神经网络(比如CNN)来学习传统的特征提取步骤,取得了跟使用传统的语音特征相当的结果,当前这部分工作绝大多数还是基于传统的HMM框架来做,还没有跟CTC或者encoder-decoder相结合。
CNN
Google[1]分析了CNN跟mel-scale filterbank之间的关系,convolution layer相当于学习一组FIR滤波器,学习到的这组filter对应的中心频率曲线跟mel-fb类似。
CLDNN
Google[2]使用一层CNN来抽取特征,声学模型使用CLDNN,在2000h数据集上取得了跟log-mel filterbank特征相当的效果。
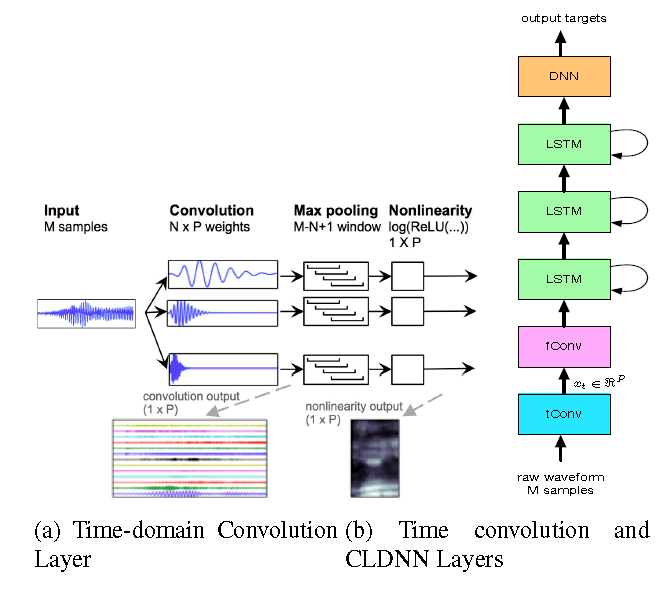
第一层称为time-convolutional layer,用来学习滤波器参数。
- 每次输入M个采样点,帧移10ms
- 使用P个filter,对应于最后的P个频率输出
- max pooling,移除语音的short term phase信息
后面使用CLDNN的网络结构,这里面的convolutional layer称为fConv layer,相当于与频域信号做卷积,减少spectral variations。
CNN+TDNN
[3]提出了CNN+TDNN的网络结构,相比于[2]来讲,抽取特征使用NIN的非线性变换来替换pooling,获得了更快的收敛速度。
Reference
[1].SPEECH ACOUSTIC MODELING FROM RAW MULTICHANNEL WAVEFORMS
[2].Learning the Speech Front-end With RawWaveform CLDNNs
[3].Acoustic modelling from the signal domain using CNNs
后面的技术分享转移到微信公众号上面更新了,【欢迎扫码关注交流】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









