







 本文详细介绍了TiDB的数据管理工具,包括Dumpling用于数据导出,TiDBLightning快速导入大量数据,DataMigration(DM)进行全量数据迁移和增量同步,Backup&Restore(BR)进行大规模备份恢复,以及Binlog和TiCDC实现数据同步和实时备份。这些工具覆盖了从数据备份、恢复、迁移、同步的全方位需求,为企业级数据库管理提供了高效解决方案。
本文详细介绍了TiDB的数据管理工具,包括Dumpling用于数据导出,TiDBLightning快速导入大量数据,DataMigration(DM)进行全量数据迁移和增量同步,Backup&Restore(BR)进行大规模备份恢复,以及Binlog和TiCDC实现数据同步和实时备份。这些工具覆盖了从数据备份、恢复、迁移、同步的全方位需求,为企业级数据库管理提供了高效解决方案。
一、 Dumpling
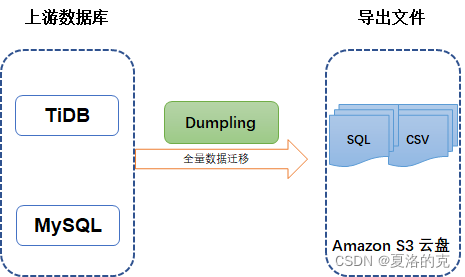
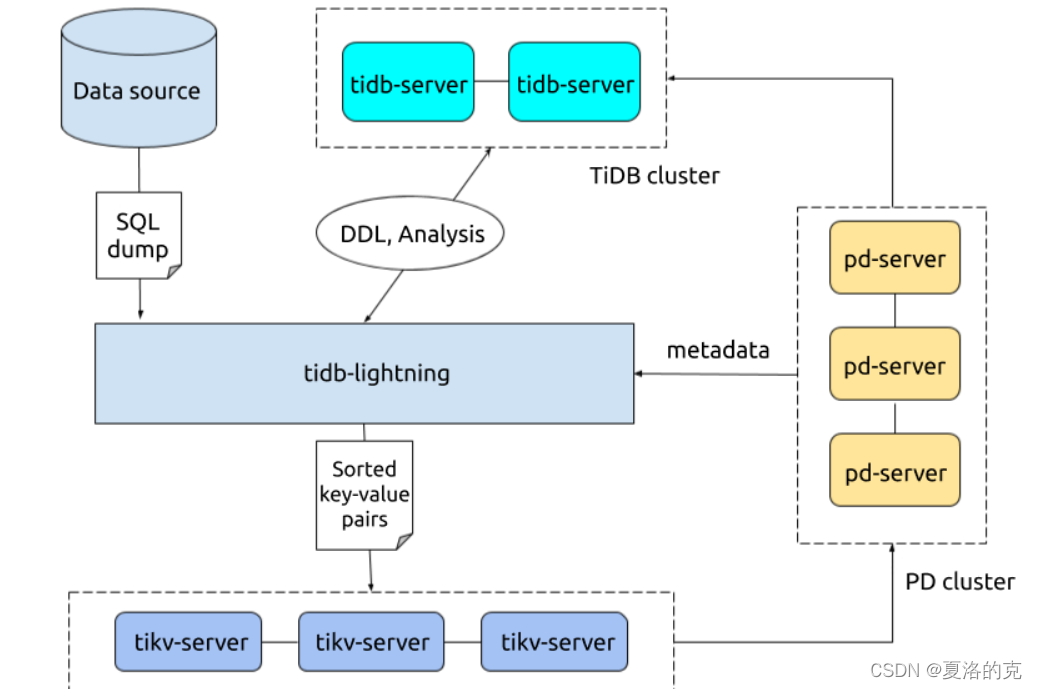
二、 Lightning
TiDB Lightning 有以下两个主要的使用场景:
- 迅速导入大量新数据。
- 恢复所有备份数据。
目前,TiDB Lightning 支持:
- 导入 Dumpling、CSV 或 Amazon Aurora Parquet 输出格式的数据源。
- 从本地盘或 Amazon S3 云盘读取数据。
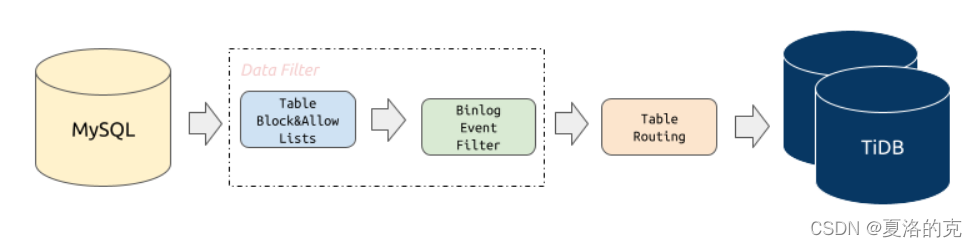
三、 Data Migration(DM)
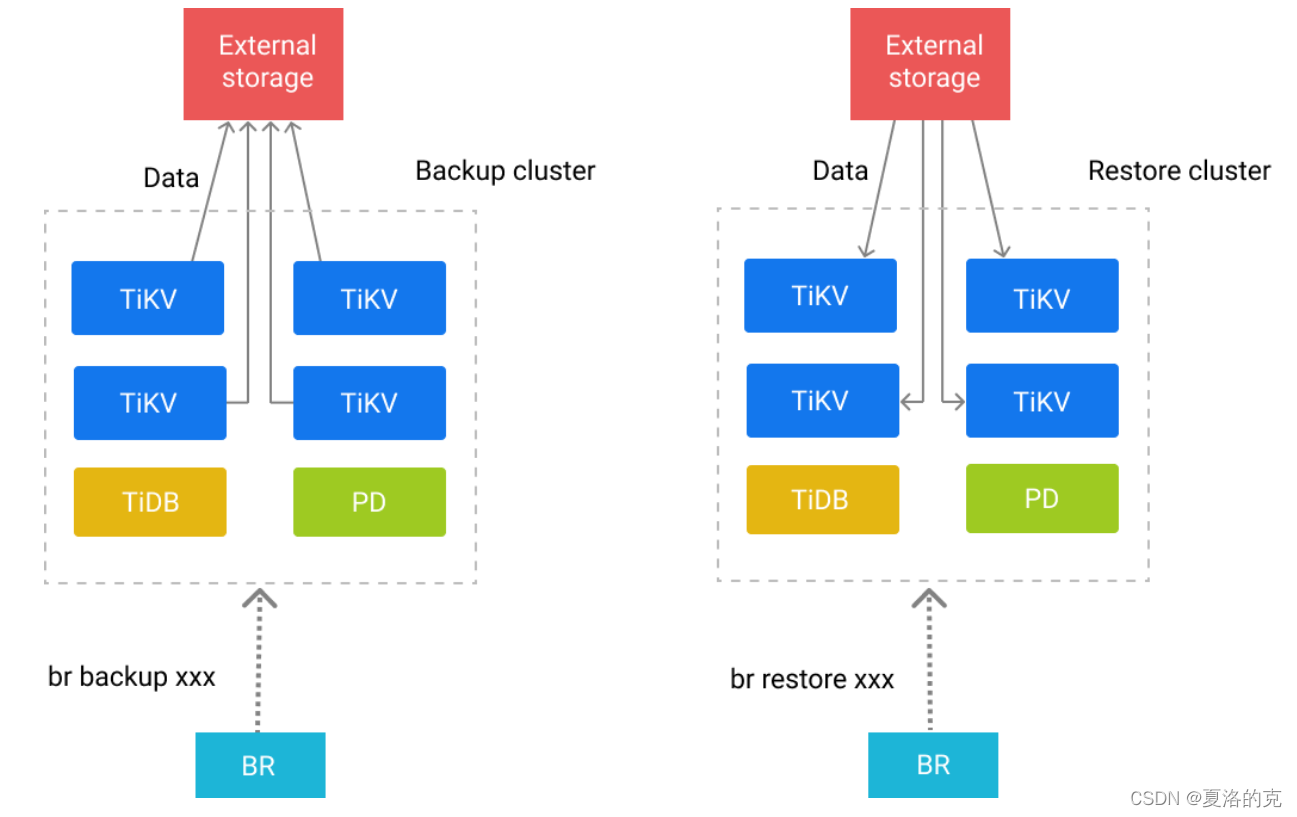
四、 Backup & Restore (BR)
BR 除了可以用来进行常规备份恢复外,也可以在保证兼容性前提下用来做大规模的数据迁移。
本文介绍了 BR 的工作原理、推荐部署配置、使用限制以及几种使用方式。
工作原理:BR 将备份或恢复操作命令下发到各个 TiKV 节点。TiKV 收到命令后执行相应的备份或恢复操作。
在一次备份或恢复中,各个 TiKV 节点都会有一个对应的备份路径,TiKV 备份时产生的备份文件将会保存在该路径下,恢复时也会从该路径读取相应的备份文件。
备份文件类型
备份路径下会生成以下两种类型文件:
- SST 文件:存储 TiKV 备份下来的数据信息
backupmeta文件:存储本次备份的元信息,包括备份文件数、备份文件的 Key 区间、备份文件大小和备份文件 Hash (sha256) 值backup.lock文件:用于防止多次备份到同一目录
SST 文件命名格式
SST 文件以 storeID_regionID_regionEpoch_keyHash_cf 的格式命名。格式名的解释如下:
- storeID:TiKV 节点编号
- regionID:Region 编号
- regionEpoch:Region 版本号
- keyHash:Range startKey 的 Hash (sha256) 值,确保唯一性
- cf:RocksDB 的 ColumnFamily(默认为
default或write)
使用限制
下面是使用 BR 进行备份恢复的几条限制:
- BR 恢复到 TiCDC / Drainer 的上游集群时,恢复数据无法由 TiCDC / Drainer 同步到下游。
- BR 只支持在
new_collations_enabled_on_first_bootstrap开关值相同的集群之间进行操作。这是因为 BR 仅备份 KV 数据。如果备份集群和恢复集群采用不同的排序规则,数据校验会不通过。所以恢复集群时,你需要确保select VARIABLE_VALUE from mysql.tidb where VARIABLE_NAME='new_collation_enabled';语句的开关值查询结果与备份时的查询结果相一致,才可以进行恢复。
五、 Binlog
TiDB Binlog 是一个用于收集 TiDB 的 binlog,并提供准实时备份和同步功能的商业工具。
TiDB Binlog 支持以下功能场景:
- 数据同步:同步 TiDB 集群数据到其他数据库
- 实时备份和恢复:备份 TiDB 集群数据,同时可以用于 TiDB 集群故障时恢复
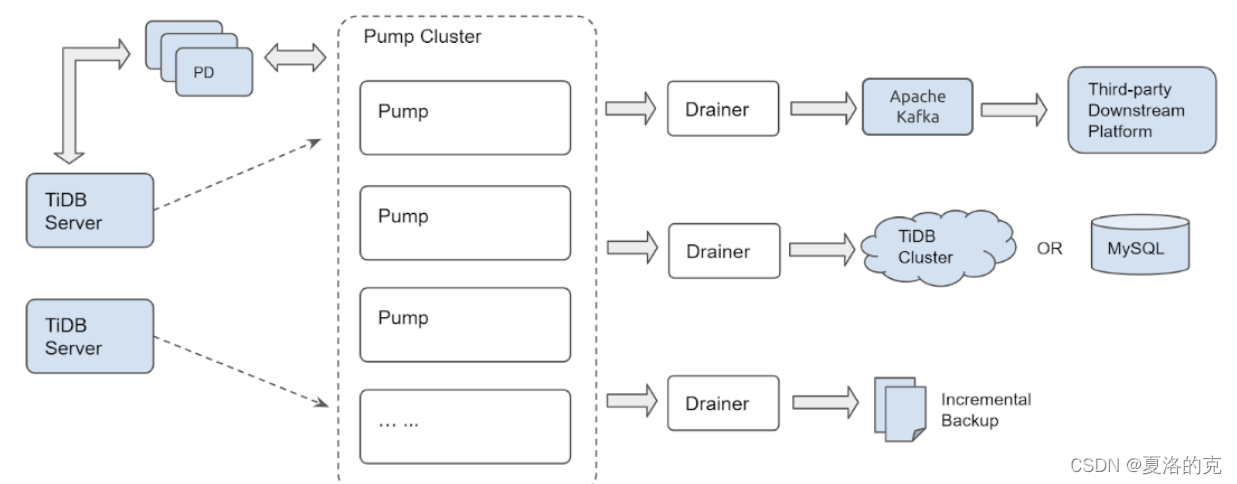
TiDB Binlog 集群主要分为 Pump 和 Drainer 两个组件,以及 binlogctl 工具:
Pump
Pump 用于实时记录 TiDB 产生的 Binlog,并将 Binlog 按照事务的提交时间进行排序,再提供给 Drainer 进行消费。
Drainer
Drainer 从各个 Pump 中收集 Binlog 进行归并,再将 Binlog 转化成 SQL 或者指定格式的数据,最终同步到下游。
binlogctl 工具
binlogctl 是一个 TiDB Binlog 配套的运维工具,具有如下功能:
- 获取 TiDB 集群当前的 TSO
- 查看 Pump/Drainer 状态
- 修改 Pump/Drainer 状态
- 暂停/下线 Pump/Drainer
主要特性
- 多个 Pump 形成一个集群,可以水平扩容。
- TiDB 通过内置的 Pump Client 将 Binlog 分发到各个 Pump。
- Pump 负责存储 Binlog,并将 Binlog 按顺序提供给 Drainer。
- Drainer 负责读取各个 Pump 的 Binlog,归并排序后发送到下游。
- Drainer 支持 relay log 功能,通过 relay log 保证下游集群的一致性状态。
六、 TiCDC
TiCDC 是一款通过拉取 TiKV 变更日志实现的 TiDB 增量数据同步工具,具有将数据还原到与上游任意 TSO 一致状态的能力,同时提供开放数据协议 (TiCDC Open Protocol),支持其他系统订阅数据变更。
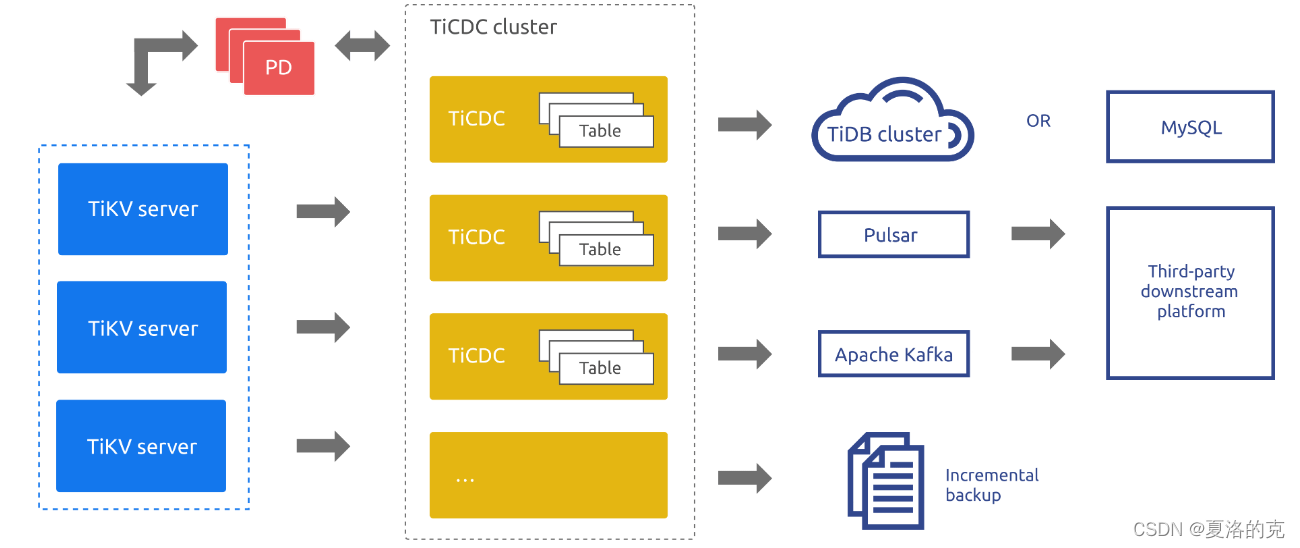
系统角色
- TiKV CDC 组件:只输出 key-value (KV) change log。
- 内部逻辑拼装 KV change log。
- 提供输出 KV change log 的接口,发送数据包括实时 change log 和增量扫的 change log。
capture:TiCDC 运行进程,多个capture组成一个 TiCDC 集群,负责 KV change log 的同步。- 每个
capture负责拉取一部分 KV change log。 - 对拉取的一个或多个 KV change log 进行排序。
- 向下游还原事务或按照 TiCDC Open Protocol 进行输出。
- 每个
同步功能介绍
本部分介绍 TiCDC 的同步功能。
sink 支持
目前 TiCDC sink 模块支持同步数据到以下下游:
- MySQL 协议兼容的数据库,提供最终一致性支持。
- 以 TiCDC Open Protocol 输出到 Kafka,可实现行级别有序、最终一致性或严格事务一致性三种一致性保证。
同步顺序保证和一致性保证
数据同步顺序
- TiCDC 对于所有的 DDL/DML 都能对外输出至少一次。
- TiCDC 在 TiKV/TiCDC 集群故障期间可能会重复发相同的 DDL/DML。对于重复的 DDL/DML:
- MySQL sink 可以重复执行 DDL,对于在下游可重入的 DDL (譬如 truncate table)直接执行成功;对于在下游不可重入的 DDL(譬如 create table),执行失败,TiCDC 会忽略错误继续同步。
- Kafka sink 会发送重复的消息,但重复消息不会破坏 Resolved Ts 的约束,用户可以在 Kafka 消费端进行过滤。
数据同步一致性
- MySQL sink
- TiCDC 不拆分单表事务,保证单表事务的原子性。
- TiCDC 不保证下游事务的执行顺序和上游完全一致。
- TiCDC 以表为单位拆分跨表事务,不保证跨表事务的原子性。
- TiCDC 保证单行的更新与上游更新顺序一致。
- Kafka sink
- TiCDC 提供不同的数据分发策略,可以按照表、主键或 ts 等策略分发数据到不同 Kafka partition。
- 不同分发策略下 consumer 的不同实现方式,可以实现不同级别的一致性,包括行级别有序、最终一致性或跨表事务一致性。
- TiCDC 没有提供 Kafka 消费端实现,只提供了 TiCDC 开放数据协议,用户可以依据该协议实现 Kafka 数据的消费端。
同步限制
使用 TiCDC 进行同步的时候,请注意以下相关限制要求以及暂不支持的场景。
有效索引的相关要求
TiCDC 只能同步至少存在一个有效索引的表,有效索引的定义如下:
- 主键 (
PRIMARY KEY) 为有效索引。 - 同时满足下列条件的唯一索引 (
UNIQUE INDEX) 为有效索引:- 索引中每一列在表结构中明确定义非空 (
NOT NULL)。 - 索引中不存在虚拟生成列 (
VIRTUAL GENERATED COLUMNS)。
- 索引中每一列在表结构中明确定义非空 (
TiCDC 从 4.0.8 版本开始,可通过修改任务配置来同步没有有效索引的表,但在数据一致性的保证上有所减弱。具体使用方法和注意事项参考同步没有有效索引的表。
暂不支持的场景
目前 TiCDC 暂不支持的场景如下:
- 暂不支持单独使用 RawKV 的 TiKV 集群。
- 暂不支持在 TiDB 中创建 SEQUENCE 的 DDL 操作和 SEQUENCE 函数。在上游 TiDB 使用 SEQUENCE 时,TiCDC 将会忽略掉上游执行的 SEQUENCE DDL 操作/函数,但是使用 SEQUENCE 函数的 DML 操作可以正确地同步。
- 对上游存在较大事务的场景提供部分支持,详见



















 1250
1250

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











