 爬取网易云音乐数据:Python实战
爬取网易云音乐数据:Python实战





 本文介绍如何使用Python的Requests和BeautifulSoup库抓取网易云音乐中特定艺人的专辑信息,并进一步获取每张专辑内歌曲的详细数据,最终将数据存储到Excel表格中。通过分析网页接口,调整URL参数实现数据获取,并利用开发者工具辅助查找所需数据。
本文介绍如何使用Python的Requests和BeautifulSoup库抓取网易云音乐中特定艺人的专辑信息,并进一步获取每张专辑内歌曲的详细数据,最终将数据存储到Excel表格中。通过分析网页接口,调整URL参数实现数据获取,并利用开发者工具辅助查找所需数据。
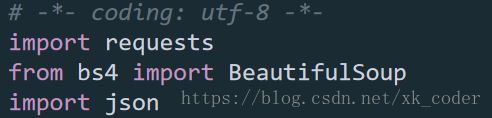
1.首先导入2个第三方库,json库是标准库,用到的有Requests库,Beautisoup库,json库
2.分析网站,当然是f12 开发者工具了,firefox浏览器的开发者工具个人用着比chrome的好用一点。 用开发者工具之前要先明白你要找什么数据,我想抓取的是霹雳布袋戏的所有歌曲信息(顺便安利下霹雳布袋戏)
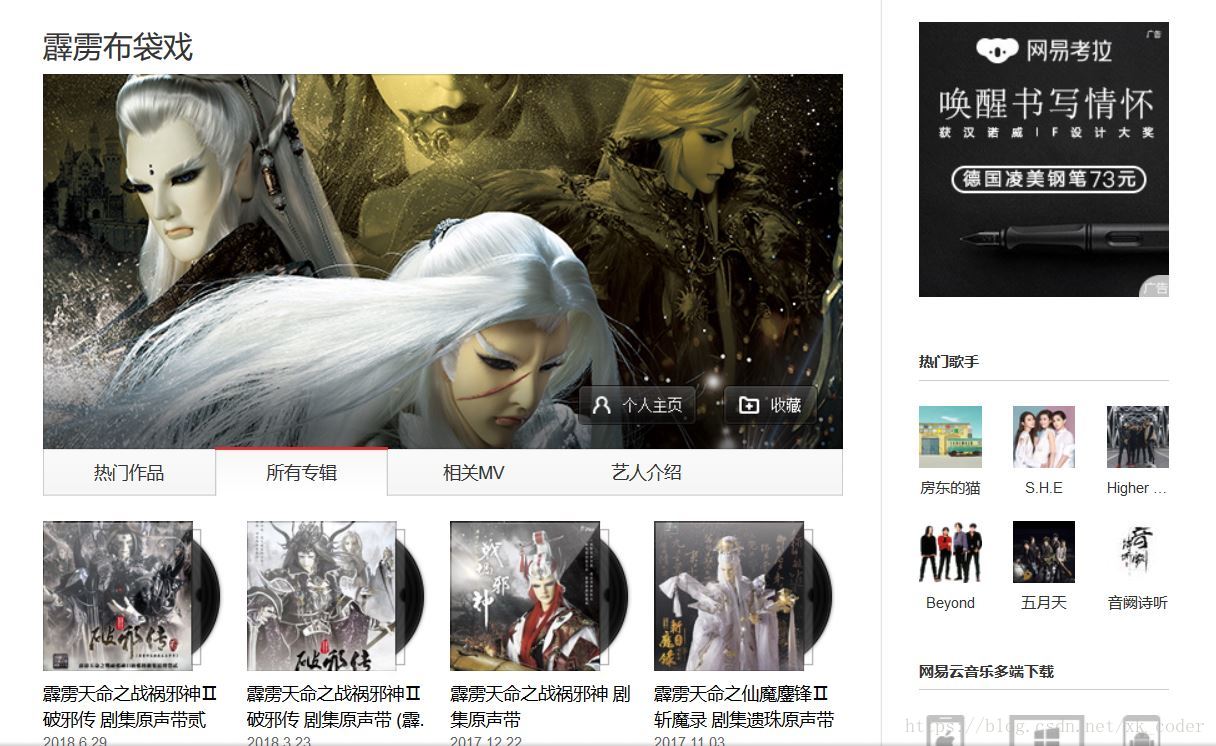
抖个机灵,通过我仔细观察,我发现通过改url的limit参数(每页显示的专辑数量),offset参数(当前页)就能获取某用户的所有专辑,这样能避免抓取的数据有很多页而要考虑下一页的情况。
"https://music.163.com/artist/album?id=12639&limit=200&offset=0"
为了验证我的想法,我用的是chrome的servistate插件,
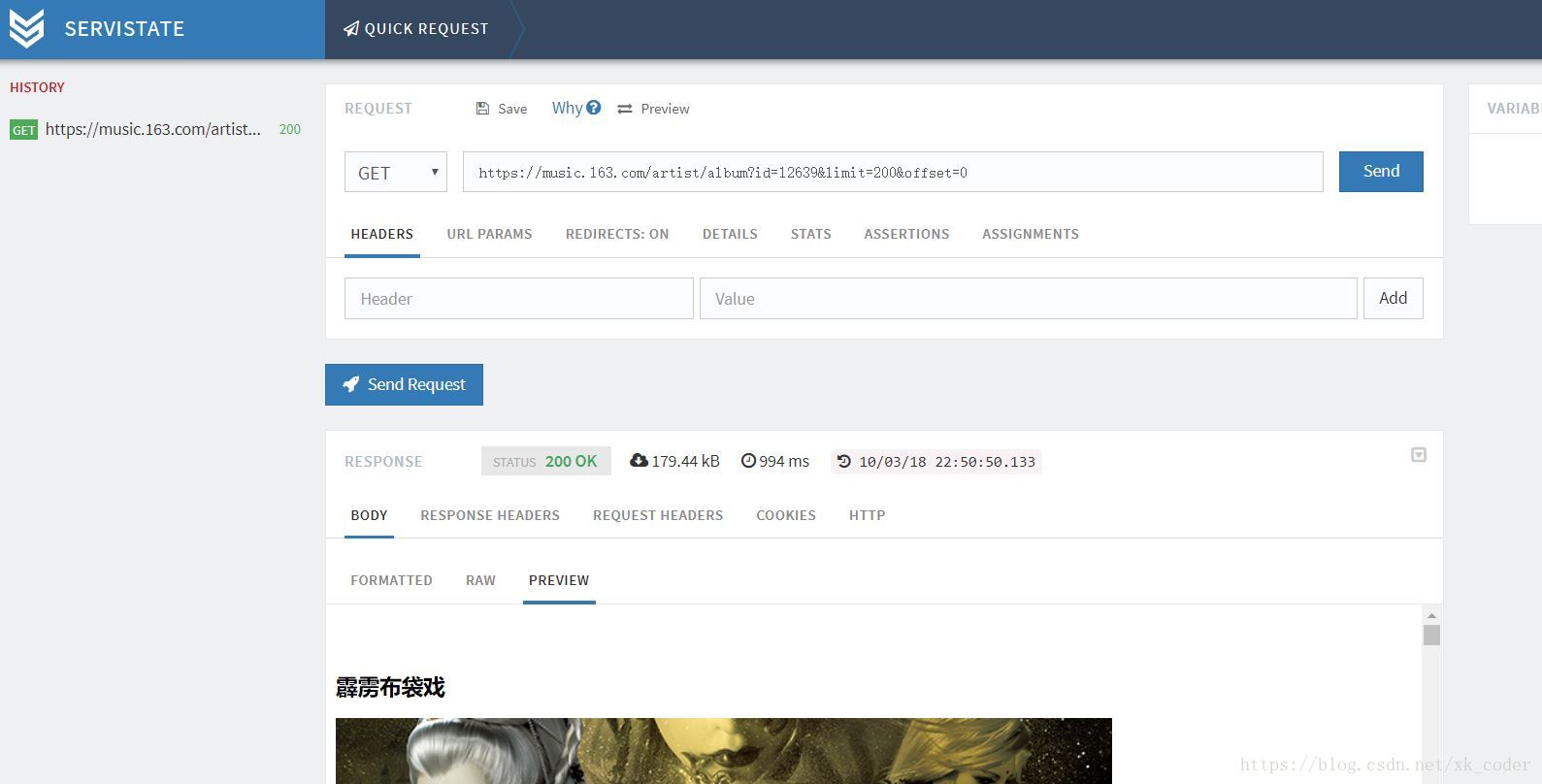
确认这个接口就是我们需要的。
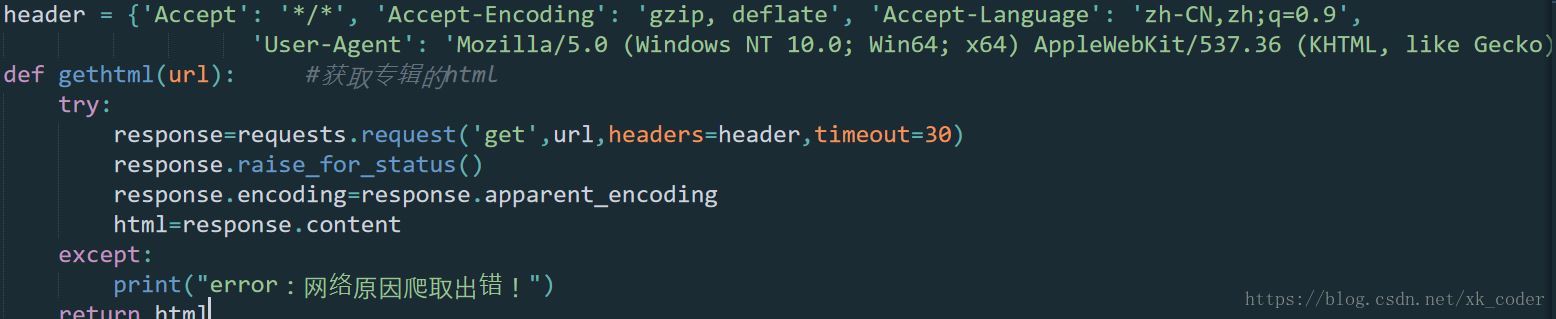
3.动手写第一个函数,发送request请求,返回它的二进制格式,因为这个函数请求json数据的时候也会用到。
4.然后就是beautifulsoup库提取出我们想要的数据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 532
532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









