




 本文是《数据密集型应用系统设计》的读书笔记,主要探讨了数据密集型应用的特征,区分了数据密集型与计算密集型应用。内容涵盖数据系统的可靠性(包括硬件故障、软件错误和人为失误的处理)、可扩展性(垂直扩展、水平扩展和自动弹性扩展)和可维护性(包括系统设计原则和运维策略)。此外,还深入讲解了数据存储和检索,尤其是哈希索引、SSTables、LSM-Tree和B-tree在数据存储中的作用和性能优化策略。
本文是《数据密集型应用系统设计》的读书笔记,主要探讨了数据密集型应用的特征,区分了数据密集型与计算密集型应用。内容涵盖数据系统的可靠性(包括硬件故障、软件错误和人为失误的处理)、可扩展性(垂直扩展、水平扩展和自动弹性扩展)和可维护性(包括系统设计原则和运维策略)。此外,还深入讲解了数据存储和检索,尤其是哈希索引、SSTables、LSM-Tree和B-tree在数据存储中的作用和性能优化策略。
本篇章内容为阅读《数据密集型应用系统设计》一书的读书笔记。
作为个人成长学习使用,同时希望对刷到的朋友有所帮助,一起加油哦!
生命就像一朵花,要拼尽全力绽放,芳香四溢,在风中舞蹈!
写在前面:
为什么读这本书?
作为刚踏入数据库行业的初学者,我心怀憧憬地迎接这个新的挑战,并未料到工作中竟有机会遇到一位深具经验的导师,值得我万分庆幸。正是这位资深大佬热情推荐这本书给我,才让我真正接触到了它的魅力。第一章的阅读让我感到震撼,书中所探讨的内容令我大开眼界。其中蕴含着丰富的知识点,需要细致品味,耐心思考。
这本书并不枯燥,而是以其别出心裁的插图点缀其间。有些插图更是妙趣横生,将技术层面展示得更加清晰易懂;而其他一些插图则简直堪比艺术品,令人陶醉其中。当我阅读时,作者的表达方式也同样令我深感喜爱。他用朴实诚恳的语言贯穿全文(在我阅读的过程中,我真切地感受到他的诚意),将与数据相关的知识点从整体到局部、由浅入深地分析讲解,无微不至。他的用心与良苦想必是为了将更多的知识传授给我。
在此,我真心感谢我的导师和作者Martin Kleppmann。为回报他们的悉心指导与付出,我决定全力以赴地阅读这本书,并尽可能地撰写优秀的读书笔记,以期能够融会贯通、吸收更多的精华知识。
第一部分 数据系统基础
(图太美了,不得不贴)
我的第一个问题:书名是《数据密集型应用系统设计》,那么首先需要清楚一个概念,什么叫数据密集型应用?(第一章有答案)
数据密集型应用——数据(数据量、数据复杂度、数据变化速度)是主要挑战的这类应用。
计算密集型应用——CPU处理能力是第一限制性因素,计算量大,主要以追求计算速度为主要指标的这类应用。
1可靠、可扩展与可维护的应用系统
1.1 认识数据系统
本书认为数据系统的范围包括:数据库、队列、高速缓存等。
原因:
这些用于数据存储和处理的各种工具,不再适合归类为传统系统。
单个工具已经不能满足应用系统需求,需要分解任务,由每个工具高效完成各子任务,并依靠应用层代码有组织的衔接起来。
示例:
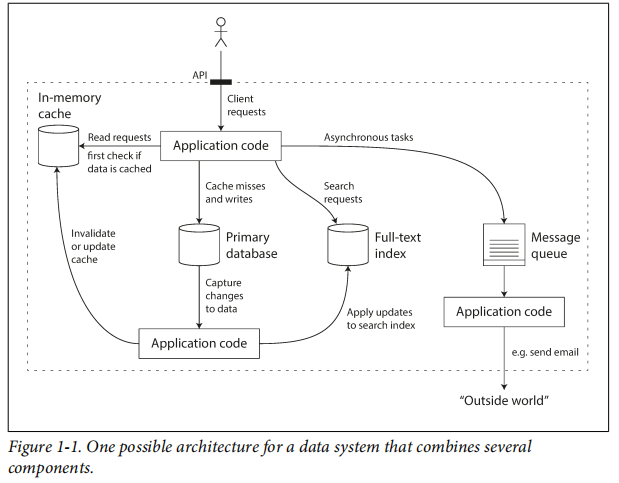
大多数软件系统都极为重要的三个问题:
可靠性:系统在某些错误(硬件问题、软件故障、人为失误等)情况下仍能正常工作;
可扩展性:系统有合理方式匹配规模(数据量、流量、复杂性等)增长;
可维护性:系统的开发和运维易于掌握。
1.2 可靠性
定义
可能出错的事情称为错误或故障;
系统可应对错误称为容错或者弹性;
容错总是指特定类型的故障,有范围约束;
故障与失效不同:故障通常指组件偏
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1146
1146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









