







 对于刚入门自然语言处理的小白,了解基本原理和项目运行流程很有必要。本文介绍了自然语言处理项目中各Python文件的作用,包括语料集文件、数据处理文件、多线程训练文件、模型构建文件等,还说明了参数定义、模型训练和测试等内容。
对于刚入门自然语言处理的小白,了解基本原理和项目运行流程很有必要。本文介绍了自然语言处理项目中各Python文件的作用,包括语料集文件、数据处理文件、多线程训练文件、模型构建文件等,还说明了参数定义、模型训练和测试等内容。
检查程序,对于刚入门自然语言处理小白来说,很有必要搞清楚基本原理和项目运行的流程,以应对提问。
(1)介绍各python文件作用
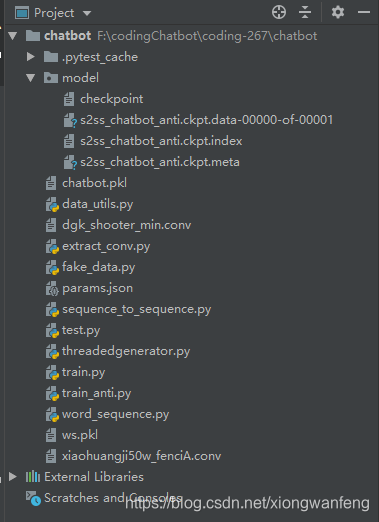
1、xiaohuangji50w_fenciA.conv:是小黄鸡语料集(本项目使用)、
dgk_shooter_min.conv:是电影的对话集
2、extract_conv.py:清洗处理数据、训练语料问答对的处理、数据模型打包处理
word_sequence.py:数据处理—句子编码化处理(字典定义及转换、训练字典、句子和向量之间的转换)
运行extract_conv.py文件之后,会将问答对数据、聊天数据模型保存在chatbot.pkl和ws.pkl模型文件中,供后面使用
3、threadedgenerator.py:由于训练的数据量大,所以将每一次训练的内容都变成一个新的线程,然后再进行训练,实现多任务并行,提高效率
4、data_utils.py:封装常用的代码模块,在训练过程中,获取当前gpu数量、根据输入输出的字典大小选择在cpu还是在gpu上进行运行等
5、sequence_to_sequence.py:基本参数保存和参数验证、构建模型、构建一个单独的GNN cell、构建单独的编码器cell、构建解码器、构建优化器、输入检查、训练模型、预测模型
6、params.json:定义模型训练时需要的参数表——是否使用双向网络、残差网络、dropout,定义深度、隐藏层单元数、优化器类型,设置初始学习率0.001
7、train_anti.py:先用word_sequence进行初始化,然后对sequence_to_sequence模型进行参数组合测试,评估不同参数下模型训练的效果,从前面生成的chatbot.pkl和ws.pkl文件中取数据,定义训练的轮次
8、test.py:根据训练好的train_anti.py文件进行模型的预测,利用flask发布成webService接口

















 3112
3112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









