







1 DataFrame 对象
1.0 概述
这个对象类似SQL的数据表、VB.NET的DataTable等,首先需要重点把握行、列等数据,这样才可以更好的操纵表。
参考文献:
[1]. 获取dataframe的列、行名称
1.1 Index:获取行名称
pandas中,dataframe获取行名称,可以有如下两种方式。
代码:
data = {
'name': ['a', 'a', 'a', 'b', 'b', 'c', 'c', 'c'],
's1': [1, 2, 3, 4, 5, 6, 7, 8],
's2': [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8]
}
df = pd.DataFrame(data)
row_index = df.index
print("row_index is: ", row_index)
print("type(row_index) is: ", type(row_index))
rows_f1 = df.index.values
print("rows_f1 is: ", rows_f1)
print("type(rows_f1) is: ", type(rows_f1))
rows_f1 = rows_f1.tolist()
print("rows_f1 is: ", rows_f1)
rows_f2 = [row for row in df.index]
print("rows_f2 is: ", rows_f2)
运行结果:
row_index is: RangeIndex(start=0, stop=8, step=1)
type(row_index) is: <class ‘pandas.core.indexes.range.RangeIndex’>
rows_f1 is: [0 1 2 3 4 5 6 7]
type(rows_f1) is: <class ‘numpy.ndarray’>
rows_f1 is: [0, 1, 2, 3, 4, 5, 6, 7]
rows_f2 is: [0, 1, 2, 3, 4, 5, 6, 7]
利用这个,获取DF的index,从而操纵其行对象。
df.index为RangeIndex类型,df.index.values属性会输出一个numpy.ndarray类型的数组,将这个数组转化为list,就可以得到所有行名称的list。
1.2 Columns:获取列名称属性
关于列,不能直接获取,需要间接操纵。
def check_columns():
data = {
'name': ['a', 'a', 'a', 'b', 'b', 'c', 'c', 'c'],
's1': [1, 2, 3, 4, 5, 6, 7, 8],
's2': [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8]
}
df = pd.DataFrame(data)
columns_name_f1 = [column for column in df]
print("columns_name_f1 is: ", columns_name_f1)
columns = df.columns
print("df.columns is: ", columns)
print("type(df.columns) is: ", type(df.columns))
columns_name_f2 = [column for column in df.columns]
print("columns_name_f2 is: ", columns_name_f2)
columns_name_f2 = df.columns.values.tolist()
print("columns_name_f2 is: ", columns_name_f2)
columns_name_f2 = df.columns.tolist()
print("columns_name_f2 is: ", columns_name_f2)
columns_name_f3 = list(df)
print("columns_name_f3 is: ", columns_name_f3)
check_columns()
第一种方式: 直接列表推导 [column for column in df]
第二种方式: df.columns返回的是Index类型,然后将该Index转成list即可。
第三种方式:直接使用list(df),就返回列名的list。
代码最后输出为:
columns_name_f1 is: [‘name’, ‘s1’, ‘s2’]
df.columns is: Index([‘name’, ‘s1’, ‘s2’], dtype=‘object’)
type(df.columns) is: <class ‘pandas.core.indexes.base.Index’>
columns_name_f2 is: [‘name’, ‘s1’, ‘s2’]
columns_name_f2 is: [‘name’, ‘s1’, ‘s2’]
columns_name_f2 is: [‘name’, ‘s1’, ‘s2’]
columns_name_f3 is: [‘name’, ‘s1’, ‘s2’]
1.3 访问列、行、元素
- loc属性:loc[索引标签(行),列标签(列)]
df.loc[0:2, ['age','workclass']]
- iloc属性:iloc[行的位置索引,列的位置索引]
df.iloc[100:103, :]
- df[列名称]:获取指定列
数据的引用方法
DF数据的引用方法分为五种:
- 切片
- 属性引用
- bool类型的引用
- where方法
- qurey方法
读取文件
(1)读取CSV文件指定行、列的数据
pd.read_csv('data/ex2.csv', usecols=['name','weight'],skiprows=[2], nrows=2)
#读取CSV文件时候,指定列:['name','weight'];指定行:跳过去0、1行,读取2行,意味着读取第2~4行数据。
(2)skipfooter不支持C语言,需要指定python语言解析器
pd.read_csv('../data/ex2.csv', skipfooter=1, engine='python')
2 根据程序结果去设计如何取值
根据执行的结果 所属的对象/类型,使用其属性、方法,获取下一层级想要的内容。
这里就类似 VBNET的“类型转换”的感觉。
获取DF的列名称——>
Index对象——>
根据这个对象,使用其values属性——>
得到array对象——>
使用array的tolist()方法——>
转换成为了一个列表
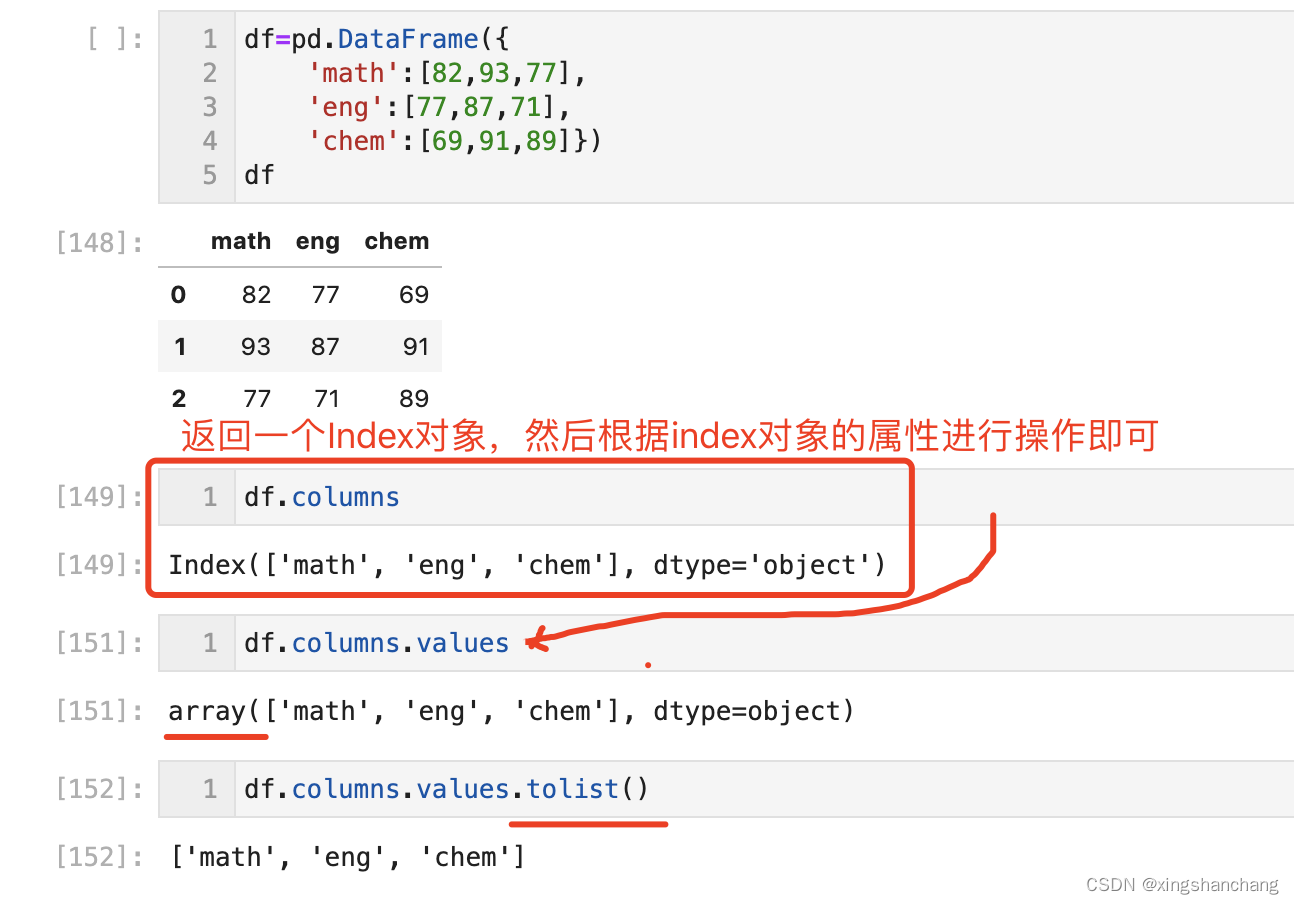
代码:
df=pd.DataFrame({
'math':[82,93,77],
'eng':[77,87,71],
'chem':[69,91,89]})
df
df.columns
df.columns.values
df.columns.values.tolist()
3 一些技巧
清空当前jupterlab中的变量
%reset
#清除变量
%whos
#查看所有变量
Interactive namespace is empty.
前面定义的变量就已经全部被清除了

















 684
684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









