







目录
2、MAT(Memory Analyzer Tool):分析堆转储文件
3、Arthas:在线诊断工具(动态查看类加载、方法执行耗时)
一、命令行指令
监控流程:先用 jps 定位进程,jstat 分析 GC,jstack 查线程,jmap 抓堆快照。
1、jps:查看 Java 进程状态
用途:快速查看当前运行的 Java 进程及其进程 ID(PID)、主类名、JVM 启动参数等
常用命令:
jps -l # 显示进程id、主类全名或 JAR 路径
jps -v # 显示进程id、JVM 启动参数(如 -Xms、-Xmx)
jps -m # 显示进程id、传递给 main() 方法的参数关键输出:输出 PID 和主类名称,便于后续工具(如 jstack、jmap)定位目标进程
2、jinfo:查看JVM参数
用途:查看JVM参数或动态修改 JVM 参数(仅限支持动态调整的参数)
常用命令:
jinfo -flags <pid> # 查看所有 JVM 参数 -flags 打印所有参数
jinfo -flag MaxHeapSize <pid> # 查看最大堆内存设置 -flag 打印指定名称的参数
jinfo -flag +PrintGC <pid> # 动态开启 GC 日志打印 -flag [+|-] 打开或关闭参数 -flag = 设置参数注意:部分参数(如堆大小)需重启生效,动态修改需谨慎
常用JVM参数:
-Xms:初始堆大小,默认为物理内存的1/64(<1GB);默认(MinHeapFreeRatio参数可以调整)空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制
-Xmx:最大堆大小,默认(MaxHeapFreeRatio参数可以调整)空余堆内存大于70%时,JVM会减少堆直到 -Xms的最小限制
-Xmn:新生代的内存空间大小,注意:此处的大小是(eden+ 2 survivor space)。与jmap -heap中显示的New gen是不同的。整个堆大小=新生代大小 + 老生代大小 + 永久代大小。在保证堆大小不变的情况下,增大新生代后,将会减小老生代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-XX:SurvivorRatio:新生代中Eden区域与Survivor区域的容量比值,默认值为8。两个Survivor区与一个Eden区的比值为2:8,一个Survivor区占整个年轻代的1/10。
-Xss:每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。应根据应用的线程所需内存大小进行适当调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。一般小的应用, 如果栈不是很深, 应该是128k够用的,大的应用建议使用256k。这个选项对性能影响比较大,需要严格的测试。和threadstacksize选项解释很类似,官方文档似乎没有解释,
在论坛中有这样一句话:"-Xss ``is translated ``in a VM flag named ThreadStackSize”一般设置这个值就可以了。
-XX:PermSize:设置永久代(perm gen)初始值。默认值为物理内存的1/64。
-XX:MaxPermSize:设置持久代最大值。物理内存的1/4。
3、jstat:监控GC、类加载、编译情况
JVM Statistics Monitoring Tool:JVM统计监视工具
用途:实时监控 JVM 运行时状态,包括垃圾回收(GC)、类加载、JIT 编译等统计信息
常用命令:
jstat -gcutil <pid> 1000 5 # 每 1 秒打印一次 GC 各区域使用百分比,共 5 次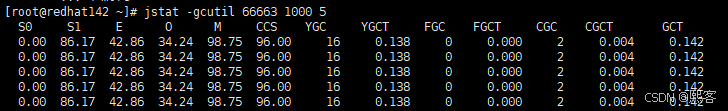
字段解释:
S0 survivor0使用百分比
S1 survivor1使用百分比
E Eden区使用百分比
O 老年代使用百分比
M 元数据区使用百分比
CCS 压缩使用百分比
YGC 年轻代垃圾回收次数
YGCT 年轻代垃圾回收消耗时间(单位:秒)
FGC Full GC垃圾回收次数
FGCT Full GC垃圾回收消耗时间(单位:秒)
GCT 垃圾回收消耗总时间(单位:秒)
jstat -gc <pid> # 显示堆内存各区域(Eden/Survivor/Old)的实际容量和使用量
gc和-gcutil参数类似,只不过输出字段不是百分比,而是实际的值。
字段解释:
S0C survivor0大小
S1C survivor1大小
S0U survivor0已使用大小
S1U survivor1已使用大小
EC Eden区大小
EU Eden区已使用大小
OC 老年代大小
OU 老年代已使用大小
MC 方法区大小
MU 方法区已使用大小
CCSC 压缩类空间大小
CCSU 压缩类空间已使用大小
YGC 年轻代垃圾回收次数
YGCT 年轻代垃圾回收消耗时间(单位:秒)
FGC Full GC垃圾回收次数
FGCT Full GC垃圾回收消耗时间(单位:秒)
GCT 垃圾回收消耗总时间(单位:秒)
jstat -class <pid> # 显示类加载/卸载数量及耗时![]()
关键指标:
YGC/YGCT:年轻代 GC 次数和耗时。
FGC/FGCT:Full GC 次数和耗时。
O:老年代使用百分比
4、jstack:抓取线程快照
用途:生成线程快照,定位死锁、线程阻塞或 CPU 占用过高问题
常用命令:
jstack -l <pid> # 显示线程堆栈及锁信息
jstack -F <pid> # 强制生成快照(适用于进程无响应)关键输出:
BLOCKED:线程因锁阻塞。
WAITING:线程处于等待状态(如 Object.wait())。
deadlock:死锁
示例:cpu占用过高问题(快速查看热点方法)
1> 通过命令 top -Hp <pid> 找到高 CPU 线程
top -H -p <pid> # 查看线程 CPU 占用2> 将线程id转换为16进制
printf "%x\n" <线程ID> # 将线程 ID 转为十六进制3> 使用 jstack -l <pid>查看进程快照,在快照中找到nid=16进制的线程id的信息,并分析对应代码
jstack <pid> > thread_dump.txt
grep <十六进制线程ID> thread_dump.txt # 定位线程栈5、jmap:生成堆转储文件
用途:生成堆转储快照(Heap Dump),分析内存泄漏或对象分布
jmap -dump:live,format=b,file=heap.hprof <pid> # 生成存活对象的堆转储文件
# live 只转储存活的对象,如果没有指定则转储所有对象
# format=b 二进制格式
# file= 转储文件到
jhsdb jmap --heap --pid <pid> # 显示堆内存配置(GC 算法、分代大小等)
jmap -histo <pid> # 统计堆中对象数量及占用内存(按类排序)调优场景:结合 MAT 或 jhat(JDK 9+ 已废弃) 分析内存泄漏、大对象问题
6、jcmd:整合工具
用途:多功能工具,整合了 jps、jstat、jmap 等功能
jcmd <pid> GC.run # 手动触发 GC
jcmd <pid> VM.native_memory # 显示本地内存使用情况
jcmd <pid> help # 列出支持的所有命令优势:一条命令替代多个工具,适合脚本化监控
二、可视化监控
1、Jconsole(JDK自带)
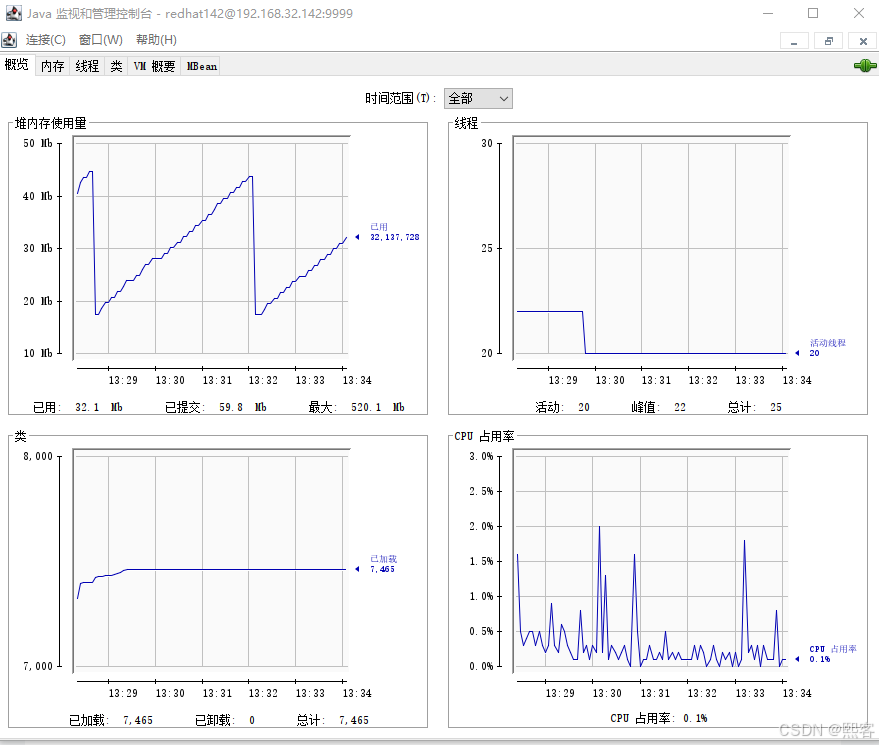
功能:监控堆内存、线程、类加载、CPU 使用率等基础指标,支持本地和远程连接
本地监控:直接双击 ${JAVA_HOME}/bin/jconsole.exe
远程监控:在win上,连接Linux上的JDK
1> 启动 Java 应用时开启 JMX 远程监控
在 Linux 上运行 Java 程序时,需添加以下参数:
java -Dcom.sun.management.jmxremote \
-Dcom.sun.management.jmxremote.port=9999 \ # JMX 服务监听端口
-Dcom.sun.management.jmxremote.authenticate=false \ # 禁用认证(测试用)
-Dcom.sun.management.jmxremote.ssl=false \ # 禁用 SSL(测试用)
-Djava.rmi.server.hostname=<Linux服务器IP> \ # 服务器公网IP或域名
-jar your-app.jar2> 确保 Linux 防火墙允许 JMX 端口(如 9999)的入站流量:
# 如果使用 iptables
sudo iptables -A INPUT -p tcp --dport 9999 -j ACCEPT
sudo service iptables save && sudo service iptables restart
# 如果使用 firewalld(CentOS/RHEL)
sudo firewall-cmd --zone=public --add-port=9999/tcp --permanent
sudo firewall-cmd --reload3> 打开win上的 ${JAVA_HOME}/bin/jconsole.exe 进行连接
2、MAT(Memory Analyzer Tool):分析堆转储文件
功能:分析堆转储文件(Heap Dump),定位内存泄漏、大对象问题
1> 下载与安装
下载地址:MAT官网下载
解压安装:
-
下载后解压到任意目录(无需安装程序)。
-
启动方式:
-
Windows: 运行
MemoryAnalyzer.exe -
macOS/Linux: 运行
mat脚本(位于解压后的根目录)
-
配置 JDK 路径(可选)
如果默认 JDK 版本不兼容(需 Java 8+),可修改 MemoryAnalyzer.ini 文件,添加:
-vm
C:\Program Files\Java\jdk-17\bin\javaw.exe # 替换为你的 JDK 路径2> 生成堆转储文件(Heap Dump)
方法 1:使用 jmap 工具
jmap -dump:format=b,file=heapdump.hprof <pid> # <pid> 为目标 Java 进程的 ID方法 2:JVM 参数自动生成
在 Java 应用启动时添加参数,当发生 OutOfMemoryError 时自动生成堆转储
java -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./heapdump.hprof -jar app.jar3> 使用 MAT 分析堆转储
步骤 1:打开堆转储文件
-
启动 MAT,点击 File > Open Heap Dump,选择
.hprof文件。 -
MAT 会自动解析并生成分析报告。
步骤 2:分析内存泄漏
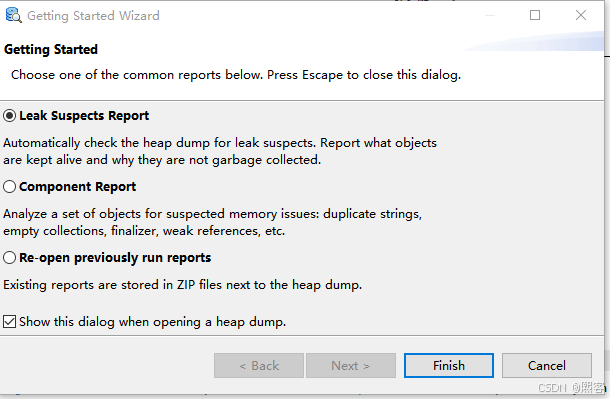
Leak Suspects Report(泄漏怀疑报告)
-
默认生成的报告中会列出可能的内存泄漏对象(按占用内存排序)。
-
点击 Details 查看对象引用链,定位到具体代码位置。
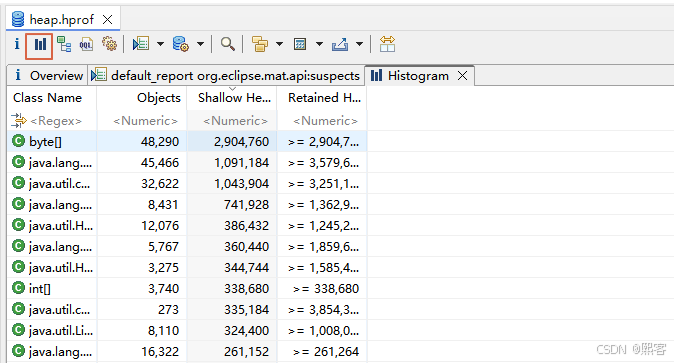
Histogram(直方图)
-
查看所有类的实例数和内存占用:
-
按类名筛选(支持正则表达式)。
-
右键点击类名,选择 Merge Shortest Paths to GC Roots,查看哪些 GC Root 引用了这些对象。
-
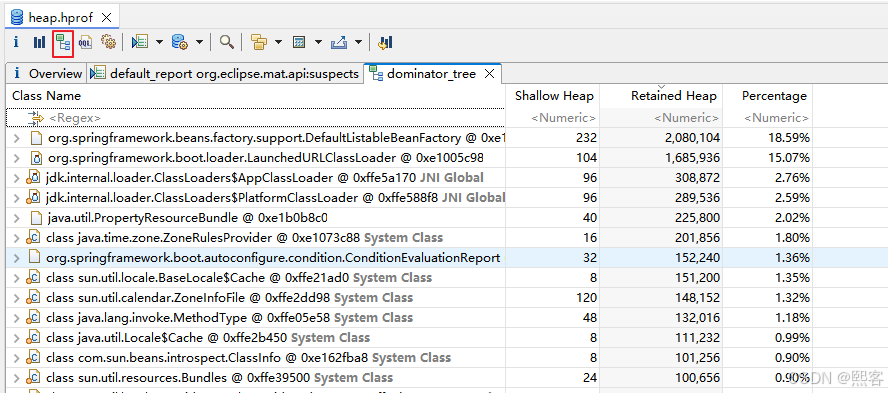
Dominator Tree(支配树)
-
显示占用内存最多的对象及其引用关系,查找未释放的引用。
-
快速定位内存瓶颈。
更多可参考:深度讲解MAT
3、Arthas:在线诊断工具(动态查看类加载、方法执行耗时)
功能:在线诊断工具,能够在不重启应用的情况下快速定位生产环境中的性能问题、代码逻辑异常和运行状态监控
1> 安装与启动
# 下载并启动 Arthas(自动检测本地 Java 进程)
curl -O https://arthas.aliyun.com/arthas-boot.jar
java -jar arthas-boot.jar选择要监控的项目

退出命令
stop2> 核心功能和命令
# 1、实时监控与系统状态
# dashboard:实时监控线程、内存、GC、类加载等核心指标
dashboard -i 2000 # 每2秒刷新一次
# sysenv/sysprop:查看 JVM 环境变量和系统属性
sysprop java.version # 查看 Java 版本
# 2、线程与堆栈分析
thread # 查看所有线程状态
thread -n 3 # 显示前3个高 CPU 线程
thread <线程ID> # 查看线程完整堆栈
thread -b # 检测死锁(Blocked 线程)
# heapdump:生成堆转储文件,结合 MAT 分析
heapdump /tmp/heapdump.hprof # 导出堆转储
# vmtool:强制触发 GC 或查看对象分布
vmtool --action getInstances --className com.example.MyCache --limit 10 # 查看 MyCache 实例
# 3、类与方法诊断
# jad:反编译类文件,查看源码(支持动态修改后的代码)
jad com.example.MyService # 反编译指定类
# mc/redefine 热更新代码(无需重启应用)
mc -c <ClassLoaderHash> /tmp/MyService.java # 1. 修改源码后编译为 .class 文件
redefine /tmp/MyService.class # 2. 重新加载类
# watch:监控方法入参、返回值、异常和耗时
watch com.example.MyService getUserInfo "{params, returnObj}" -x 3 # 打印参数和返回值,深度 3
# trace:追踪方法调用链路及耗时
trace com.example.MyService processOrder '#cost > 50' # 只显示耗时超过 50ms 的调用
# stack:查看某个方法的调用路径
stack com.example.MyService validateUser # 显示调用链
# monitor:统计方法调用次数、成功率和平均耗时
monitor -c 5 com.example.MyService queryData # 每 5 秒统计一次
# 4、性能分析与火焰图
# profiler:生成 CPU 或内存火焰图,定位性能瓶颈
profiler start # 开始采样
profiler stop --format svg -o /tmp/flamegraph.svg # 生成 SVG 格式火焰图
# 5、安全关闭 Arthas 服务,避免残留
stop # 退出并清理 Arthas 资源3> 常见案例
案例1:接口超时分析
# 1. 查看高耗时方法
trace com.example.OrderService createOrder '#cost > 1000'
# 2. 监控方法参数和返回值
watch com.example.OrderService queryInventory "{params, returnObj}" -x 2
# 3. 生成火焰图定位 CPU 热点
profiler start
profiler stop -f /tmp/order_flame.svg案例2:动态修复配置
# 1. 查看当前配置值
ognl '@com.example.Config@get("timeout")'
# 2. 动态修改配置(需确保类可热更新)
ognl '@com.example.Config@set("timeout", 5000)'官方文档:Arthas用户手册
推荐博客:Arthas使用教程(8大分类)
三、GC日志
GC日志记录了每一次的GC的执行时间和执行结果,通过分析GC日志可以优化堆设置和GC设置,或者改进应用程序的对象分配模式。
调优重点:结合 GC 日志(-Xloggc)和堆转储文件,优化内存分配与回收策略
1、启用GC日志
JDK8及之前:
java -XX:+PrintGCDetails \
-XX:+PrintGCDateStamps \
-XX:+PrintGCApplicationStoppedTime \
-XX:+UseGCLogFileRotation \
-XX:NumberOfGCLogFiles=5 \
-XX:GCLogFileSize=10M \
-Xloggc:/var/log/gc.log \
-jar app.jar参数说明:
-XX:+PrintGCDetails:打印 GC 详细信息(如回收区域、耗时)。
-XX:+PrintGCDateStamps:添加时间戳(便于分析时序)。
-Xloggc:gc.log:将日志输出到 gc.log 文件。
-XX:NumberOfGCLogFiles:保留最多 5 个日志文件。
-XX:GCLogFileSize:每个文件最大 10MB,超过后滚动。
-XX:+PrintGCApplicationStoppedTime:打印 GC 导致的停顿时间
-XX:+PrintHeapAtGC:输出 GC 前后的堆内存详情
JDK9及更高版本:
java -Xlog:gc*=info:file=/var/log/gc.log:time,uptime,level,tags:filecount=5,filesize=10M \
-jar app.jar参数说明:
gc*:记录所有 GC 相关事件。
file=gc.log:输出到文件 gc.log。
time:添加时间戳(格式:UTC 时间)。
filecount=5,filesize=10M:最多保留 5 个文件,每个 10MB。
gc=debug:设置日志级别为 debug(更详细)。
tags:显示事件类型(如 gc,heap)。
-Xlog:gc*:stdout -Xlog:gc*:file=gc.log:多目标输出(同时输出到控制台和文件)
验证GC日志是否生效
tail -f /var/log/gc.log # 实时查看日志内容2、GC日志分析
Young GC 日志示例(G1 收集器)
[2024-05-01T14:30:00.123+0800] GC(10) Pause Young (G1 Evacuation Pause)
Heap: 1024M->512M(2048M), 0.025 secs
Eden: 800M->0M(1024M)
Survivors: 128M->128M(128M)
Old: 256M->512M(1024M)
User=0.02s Sys=0.00s Real=0.03s关键字段:
GC(10):第 10 次 GC。
Pause Young:Young GC 类型。
Heap:堆内存变化(回收前 -> 回收后,堆总容量)。
Eden/Survivors/Old:各区域内存变化。
Real=0.03s:实际停顿时间(STW)。
Full GC 日志示例(CMS 收集器)
[2024-05-01T14:35:00.456+0800] GC(20) Pause Full (Allocation Failure)
Heap before GC: 2048M(2048M)->1024M(2048M), 0.500 secs
Metaspace: 256M->256M(512M)
User=0.45s Sys=0.05s Real=0.50s关键字段:
Pause Full:Full GC 类型。
Allocation Failure:触发原因(分配失败)。
Real=0.50s:较长的停顿时间(需警惕)。
手动分析 GC 日志的步骤
1>. 统计 GC 频率和耗时
Young GC 频率:统计日志中 Pause Young 出现的次数,结合时间戳计算平均间隔。
Full GC 次数:若频繁出现 Pause Full(如每分钟多次),可能存在内存泄漏或堆容量不足。
2>. 观察内存回收效率
Eden 区回收:每次 Young GC 后 Eden 是否完全清空(如 Eden: 800M->0M 表示回收彻底)。
晋升到老年代的对象量:若每次 Young GC 后 Old 区大幅增长(如 Old: 256M->512M),可能存在过早晋升(检查新生代大小是否合理)。
3>. 识别异常指标
长时间停顿:若 Real 时间超过 1 秒(如 Full GC 耗时 5 秒),需优化 GC 策略或堆大小。
频繁 Full GC:常见原因包括:
老年代空间不足(需增大 -XX:OldSize)。
内存泄漏(对象无法回收,持续占用老年代)。
3、日志分析工具
3.1 GCViewer(离线分析工具)
适用场景:快速生成详细GC输出的可视化报告,适合本地或生产环境日志
下载地址:GCViewer
打开命令
java -jar gcviewer-1.37-SNAPSHOT.jar
打开之后,点击File->Open File打开我们的GC日志,可以看到图
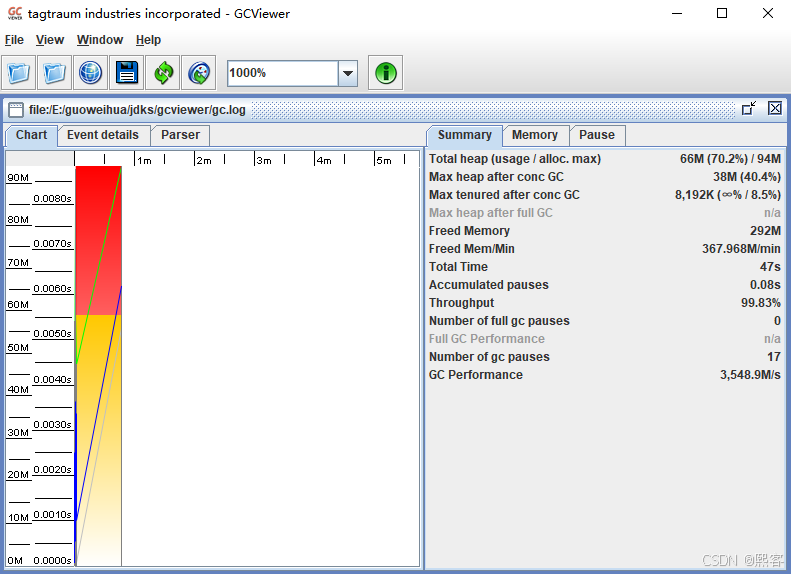
关键指标:
Throughput:应用运行时间占比(越高越好,一般需 >95%)。
Pause Time:总停顿时间和最大单次停顿。
Heap Size:堆内存使用趋势图。
具体的可以看下GitHub中的描述:https://github.com/chewiebug/GCViewer
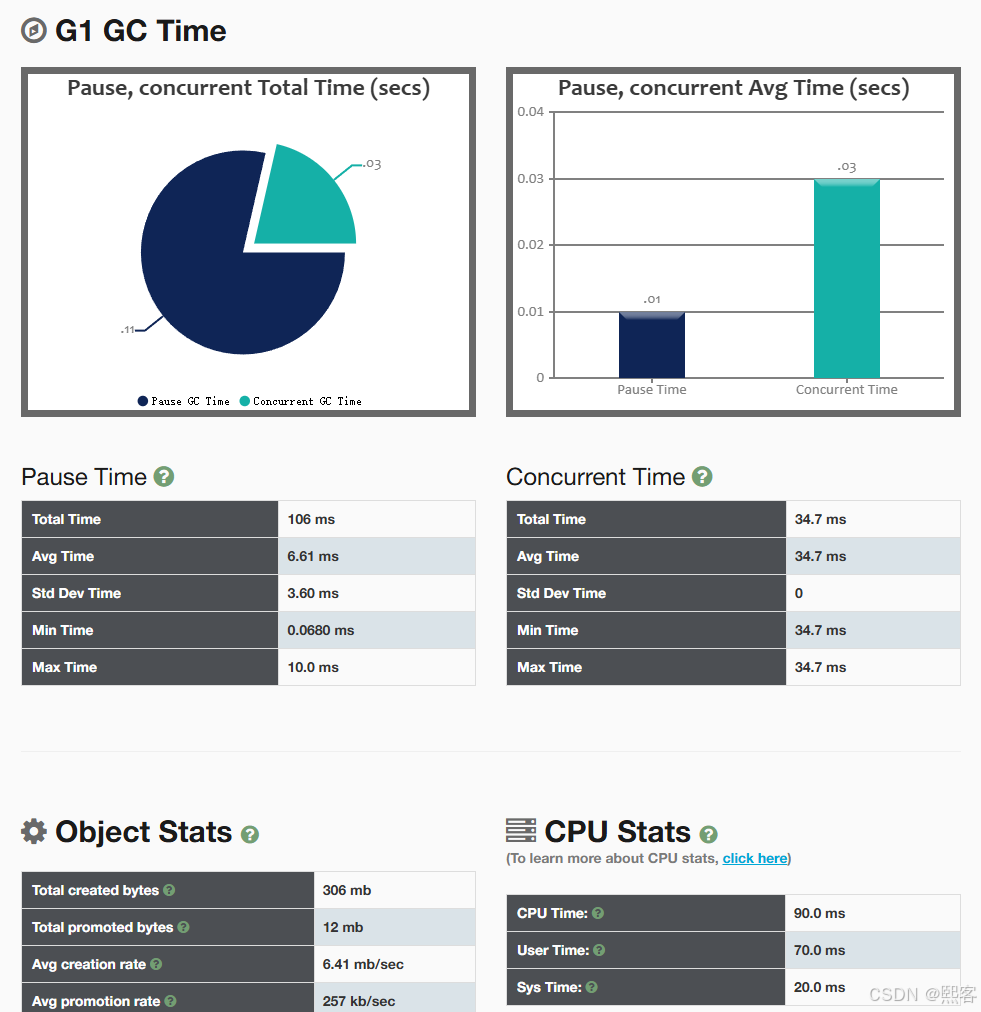
3.2 GCEasy(在线分析工具)
适用场景:无需安装,快速生成详细报告。
上传 gc.log 文件,自动生成分析报告
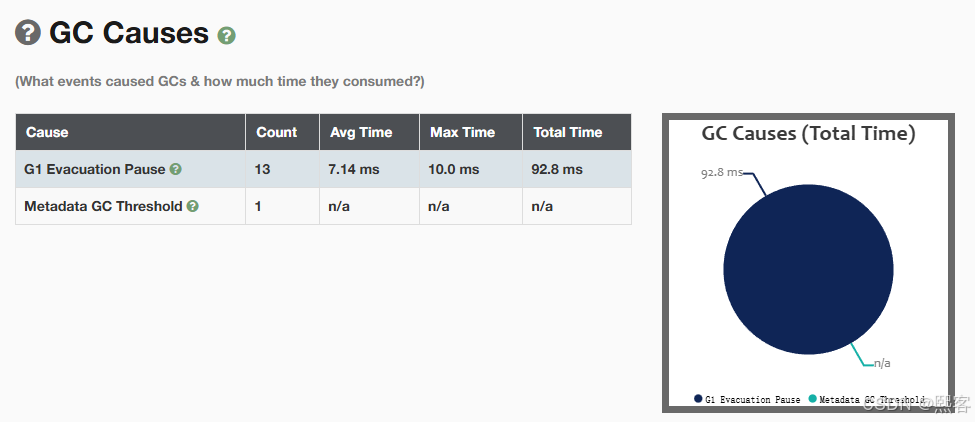
核心功能:
GC 原因统计(如 Allocation Failure、Metadata GC Threshold)。
内存泄漏检测:通过老年代增长趋势判断。
停顿时间分布:识别长时间 GC 事件。
jvm堆:
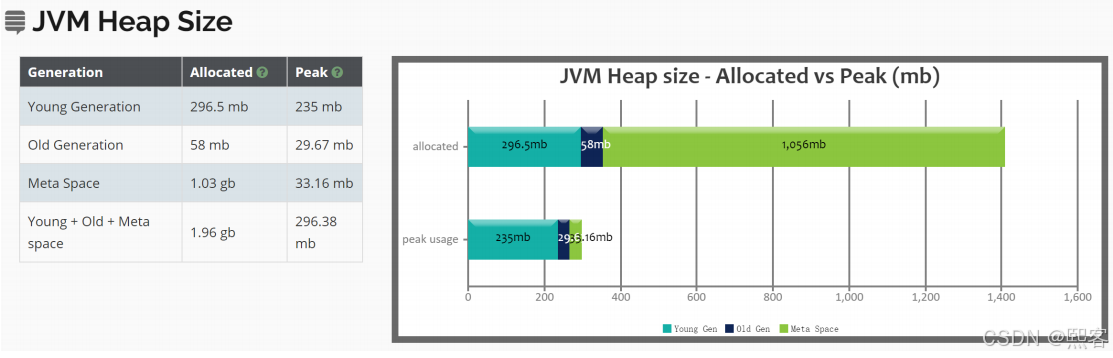
Allocated:各部分分配大小
Peak:峰值内存使用量
关键绩效指标:
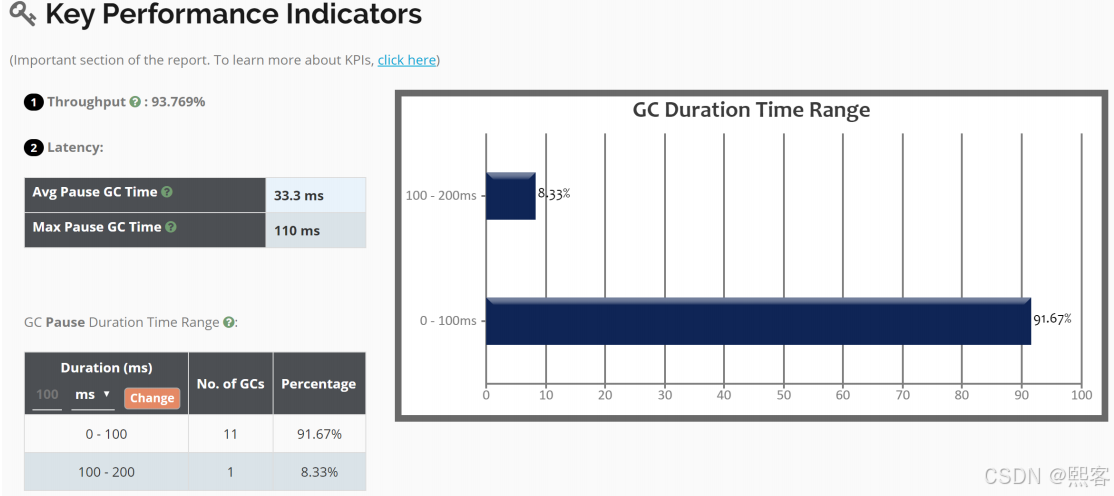
吞吐量:93.769%,运行应用程序的时间/(GC时间的比值+运行应用程序的时间)
平均GC停顿时间
最大GC停顿时间
GC停顿持续时间范围:时间范围、GC数量、百分百
交互式图表:
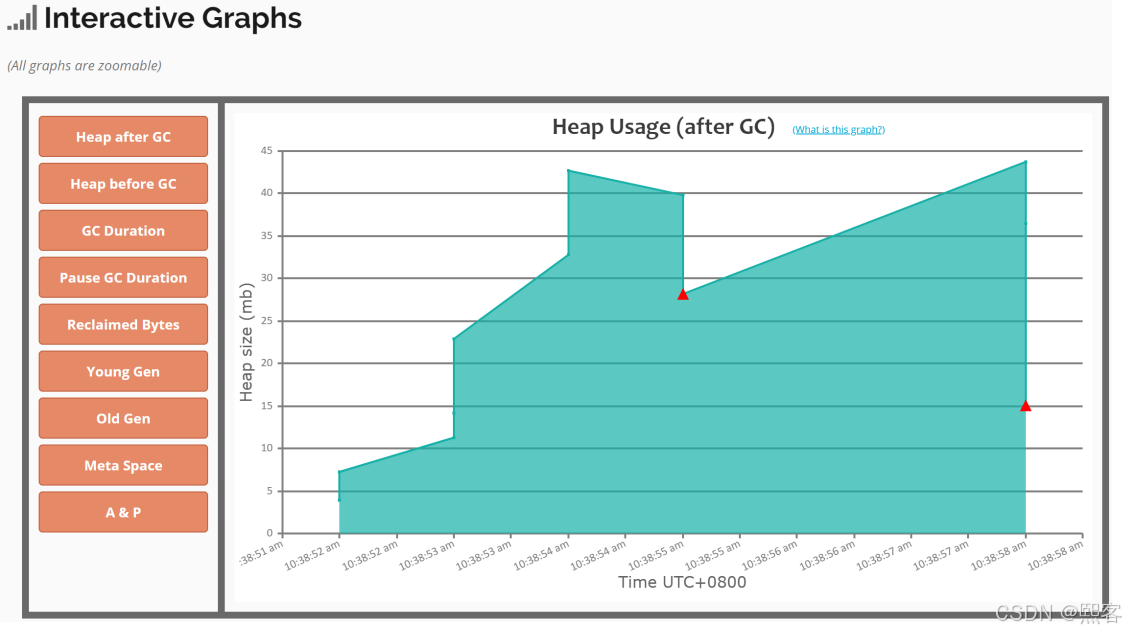
左边菜单有很多:
GC之前的堆、GC之后的堆、GC持续时间、GC停顿持续时间、回收的内存字节、Young区内存变化、Old区内存变
化、Metaspace内存变化、分配对象大小、对象从Young到Old内存大小变化
后序的内容有:GC统计信息、Minor GC/Full GC信息、内存泄漏、GC的原因等等

















 381
381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









