



多模态视频检索:告别“大海捞针”,AI如何精准捕捉视频里的每一个关键信息?
打开视频平台想找一段“猫咪踩奶配治愈BGM”的片段,却只能输入文字关键词反复翻页;监控后台要排查“有人翻越围墙”的画面,得逐帧观看几小时甚至几天的录像;教育工作者想从海量课件视频中截取“微积分导数讲解”的片段,只能靠模糊的时间戳慢慢定位…… 这些场景背后,都指向同一个核心需求——多模态视频检索。与图像-文本检索相比,视频本身包含图像、音频、文本(字幕/标题)、时序动作等多维度信息,“模态更复杂、信息密度更高、时序性更强”的特性,让它成为多模态检索领域的“硬骨头”。但随着大模型技术的爆发,多模态视频检索正从“片段匹配”迈向“语义理解”,彻底改变我们与海量视频数据交互的方式。本文就来拆解这项技术的核心逻辑、主流方案与落地前景。
一、为什么多模态视频检索这么难?三大核心痛点解析
视频的本质是“时空多模态数据的集合”:视觉上有连续的帧图像、动态的动作序列;听觉上有语音、背景音乐、环境音效;文本上有内嵌字幕、标题描述、弹幕评论。传统视频检索方法(如基于关键帧图像匹配、基于文本标题检索)之所以效果差,核心是没解决这三大痛点:
-
多模态信息“割裂”,缺乏统一语义关联:传统方法往往单独处理某一种模态——比如靠关键帧图像匹配视觉内容,靠字幕文本匹配语言信息,却忽略了模态间的关联(比如“雨滴落下的画面”应对应“哗啦啦的雨声”,“老师板书的动作”应对应“知识点讲解的语音”)。这种“各管各”的处理方式,导致检索时容易出现“视觉匹配但语义不符”的问题(比如检索“有人弹钢琴”,却匹配到“有人摆着钢琴的静态画面”)。
-
时序信息“丢失”,动态语义难以捕捉:视频的核心是“动态过程”,很多语义依赖时序逻辑(比如“打开冰箱→拿出牛奶→倒入杯子”的动作序列,单独看某一帧只能看到“冰箱”“牛奶”“杯子”,却无法理解“倒牛奶”的完整语义)。传统方法多采用“抽取关键帧”的方式压缩视频信息,很容易丢失关键的时序动作,导致无法检索到依赖动态过程的内容。
-
数据冗余“过载”,检索效率与精度难平衡:一段10分钟的视频包含18000帧图像(按30帧/秒计算),再加上音频、字幕等信息,数据量极大。如果逐帧处理所有信息,检索速度会极慢;如果过度压缩信息,又会导致检索精度下降。这一“效率-精度”的矛盾,是多模态视频检索落地的核心障碍。
而多模态视频检索技术的核心目标,就是打破模态割裂、捕捉时序语义、平衡效率与精度,让机器能像人一样“看懂”“听懂”视频的完整语义,从而实现精准检索。
二、核心技术路径:从“多模态融合”到“时序语义对齐”
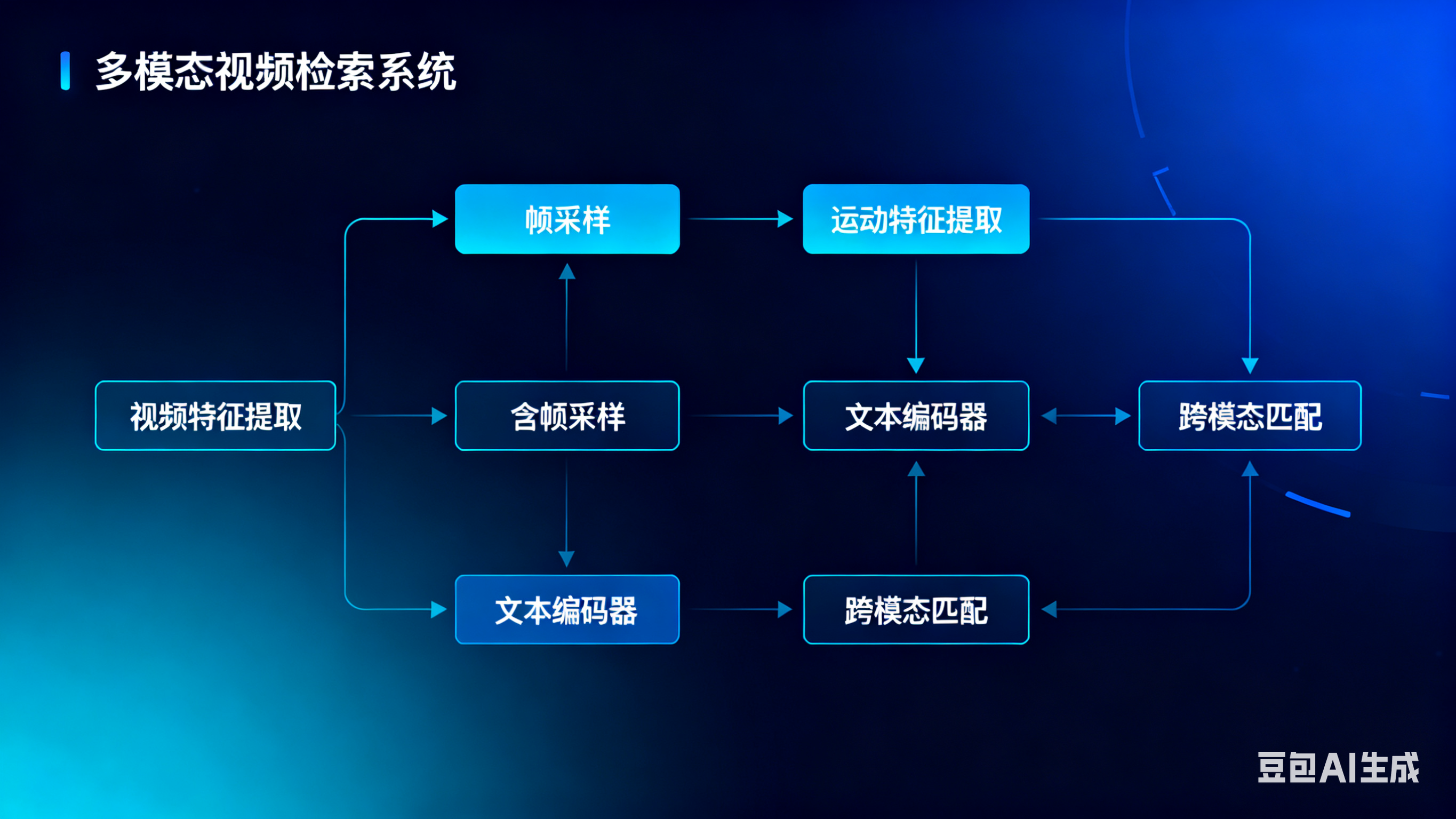
近年来,多模态视频检索的技术突破,主要源于“大模型+多模态融合+时序建模”的组合拳。主流技术路径可概括为“多模态特征提取→跨模态与时序对齐→统一语义表示→检索匹配”四大步骤,其中后三步是解决痛点的关键:
2.1 多模态特征提取:给视频的“每个维度”贴标签
第一步是从视频中提取各模态的基础特征,相当于给视频的“视觉、听觉、文本”三个维度分别建立“特征档案”:
-
视觉特征:采用3D CNN(如C3D、I3D)或Vision Transformer的时序变体(如Video Swin Transformer),不仅能提取单帧图像的物体、场景特征(如“钢琴”“客厅”),还能捕捉帧间的动作特征(如“手指按压琴键”“身体晃动”);
-
音频特征:通过MFCC(梅尔频率倒谱系数)提取音频的频谱特征,再结合音频Transformer或Wav2Vec 2.0等模型,识别语音内容(如“唱歌声”“钢琴声”)、环境音效(如“掌声”“雨声”)和情感基调(如“治愈”“激昂”);
-
文本特征:利用BERT、RoBERTa等预训练语言模型,处理视频的字幕、标题、描述文本,提取语义特征(如“猫咪踩奶”“微积分导数讲解”)。
2.2 跨模态与时序对齐:让不同模态“同频共振”
这是解决“模态割裂”和“时序丢失”的核心步骤。一方面,通过“跨模态注意力机制”让视觉、音频、文本特征建立关联(比如让“钢琴弹奏的画面”与“钢琴声”“‘弹钢琴’字幕”的特征距离拉近);另一方面,通过“时序编码”捕捉动态语义:
比如VideoCLIP(CLIP的视频版本)采用“视频片段-文本对比学习”,将视频分割成多个短片段,提取每个片段的视觉特征后,与文本特征进行对比训练,让模型学会“视频片段时序组合”与“文本语义”的对应关系。而后续的X-CLIP则进一步优化了时序对齐,通过“跨片段注意力”融合不同时间段的特征,能更好地理解长视频的完整语义(如“从开门到走进房间”的完整动作序列)。
2.3 统一语义表示与检索匹配:建立“视频语义检索库”
通过上述步骤,将视频的多模态特征融合成一个统一的语义向量(相当于给整个视频/视频片段一个“语义身份证”),同时将用户的检索查询(文本、图像、音频均可)也编码成相同维度的语义向量。检索时,只需计算查询向量与视频语义向量的相似度,就能快速匹配出最相关的视频内容。
比如用户输入文本查询“有人弹钢琴唱歌”,系统会将其编码成语义向量,然后与视频库中所有视频的语义向量对比,那些视觉特征包含“弹钢琴动作”、音频特征包含“钢琴声+唱歌声”、文本特征包含“弹钢琴”“唱歌”的视频,会因为语义向量相似度高而被优先检索出来。

三、主流模型与性能突破:从实验室到落地的关键
随着技术的发展,一批优秀的多模态视频检索模型相继出现,它们在公开数据集上的性能突破,为技术落地奠定了基础。以下是主流模型在核心数据集上的表现(核心指标为R@1、R@5、R@10,数值越高表示检索精度越好):
3.1 核心数据集介绍
目前多模态视频检索的主流测试数据集包括:
-
MSR-VTT:包含10000个视频片段(平均时长20秒),每个片段对应20条文本描述,涵盖日常生活、娱乐、教育等多个场景;
-
LSMDC:聚焦影视片段检索,包含11819个电影片段,每个片段对应1条文本描述,侧重动态动作和剧情语义的匹配;
-
ActivityNet:面向长视频检索,包含20379个长视频(平均时长3分钟),涵盖200种人类活动,考验模型对长时序语义的理解能力。
3.2 主流模型性能对比
| 模型 | 数据集 | 视频检索文本 R@1 | 视频检索文本 R@10 | 文本检索视频 R@1 | 文本检索视频 R@10 |
|---|---|---|---|---|---|
| 传统方法(3D CNN+BERT) | MSR-VTT | 22.5% | 58.3% | 21.8% | 57.6% |
| VideoCLIP | MSR-VTT | 45.2% | 82.1% | 43.7% | 80.5% |
| X-CLIP | MSR-VTT | 56.8% | 89.7% | 55.3% | 88.2% |
| UniVL | MSR-VTT | 60.1% | 91.5% | 58.7% | 90.3% |
| 从表格可以看出,基于大模型的多模态视频检索模型,性能较传统方法实现了翻倍式提升。尤其是X-CLIP和UniVL,通过优化跨模态对齐和时序建模,在长视频、复杂场景的检索任务中表现更为突出。 |
四、典型应用场景:多模态视频检索的“落地成绩单”
随着技术的成熟,多模态视频检索已在多个领域落地,成为提升效率的核心工具:
-
影视娱乐领域:视频平台(如B站、爱奇艺)利用该技术实现“精准片段检索”——用户输入“甄嬛传 华妃怒摔东西”,能直接定位到对应片段;影视剪辑师可通过“音频+文本”检索(如“找有海浪声+‘自由’台词的片段”),快速筛选素材,提升剪辑效率。
-
安防监控领域:传统监控检索需逐帧观看,而多模态视频检索可实现“动作+音频”联合检索(如“找有人翻越围墙+伴随警报声的片段”),大幅缩短排查时间,助力安防人员快速定位异常事件。
-
教育科研领域:在线教育平台(如网易云课堂、学堂在线)利用该技术实现“课件片段精准检索”——教师输入“微积分 洛必达法则 例题讲解”,能直接找到对应课程片段;科研人员可检索“实验室操作 细胞培养 步骤”的视频,快速获取实验参考内容。
-
工业质检领域:在生产线监控中,通过“视觉动作+音频”检索(如“找机械臂卡顿+伴随异响的片段”),能快速定位设备故障点,助力生产线高效运维。
五、当前挑战与未来展望
尽管多模态视频检索已取得显著突破,但在实际落地中仍面临三大挑战,这也是未来的核心研究方向:
-
长视频检索效率难题:对于时长数小时的长视频(如电影、直播回放),完整提取多模态特征耗时极长,难以满足实时检索需求。未来需研究“分层特征压缩”“增量检索”技术,在保证精度的前提下,提升长视频检索效率。
-
细粒度语义检索不足:现有模型难以区分相似但不同的语义(如“弹钢琴”和“弹电子琴”、“猫咪踩奶”和“猫咪挠痒”)。未来需结合“视觉细粒度识别”“音频情感细分”技术,提升细粒度语义的匹配精度。
-
低资源场景泛化能力弱:在医疗、军事等低资源领域(如医疗手术视频、军事演练视频),缺乏足够的多模态训练数据,模型泛化能力差。未来需研究“零样本/小样本多模态检索”技术,通过预训练模型微调、Prompt Tuning等方法,适配低资源场景。
此外,结合生成式AI技术(如文本生成视频、视频生成文本),构建“检索-生成”一体化系统,也是未来的重要发展方向。比如用户输入文本“一只猫咪在阳光下踩奶,伴随舒缓的钢琴声”,系统不仅能检索到对应视频片段,还能生成相似的视频内容,进一步拓展技术的应用边界。
六、总结
多模态视频检索的核心价值,在于打破了视频数据的“信息孤岛”,让机器从“被动存储”转向“主动理解”,从而实现对海量视频数据的高效利用。从技术演进来看,“大模型+多模态融合+时序建模”是解决核心痛点的关键,而从实验室性能突破到行业落地应用,核心在于平衡“精度、效率、泛化能力”三大指标。
未来,随着技术的不断优化,多模态视频检索必将在更多领域发挥作用——无论是提升个人用户的视频查找效率,还是助力企业实现视频数据的智能化管理,这项技术都将成为AI落地的重要抓手。对于技术研究者而言,聚焦长视频效率、细粒度语义、低资源泛化等核心挑战,将是产出有价值成果的关键;对于企业而言,结合具体场景优化模型,解决实际业务中的效率问题,将是技术落地的核心路径。


















 1786
1786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









