




1.概要
2.内容
release会被debug版本运行的更快吗
是的,Release 版本通常比 Debug 版本运行得更快,原因如下:
1. 编译器优化的差异
- Release 模式:启用高级优化(如
-O2、-O3或/O2),编译器会:- 内联小函数
- 消除冗余代码
- 优化循环和内存访问
- 减少分支预测失败
- 调整指令顺序以充分利用 CPU 流水线
- Debug 模式:通常禁用优化(如
-O0或/Od),以保留完整的调试信息(如变量名、行号),导致代码执行效率较低。
2. 调试符号的影响
- Debug 模式:生成大量调试符号(如
.pdb文件或 DWARF 信息),这些符号会:- 增加可执行文件体积
- 占用额外内存
- 略微影响运行时性能(尤其是频繁访问调试信息的场景)。
- Release 模式:通常不包含调试符号,或仅保留最小化信息。
3. 可能的例外情况
- 极端优化问题:某些代码可能在过度优化后变慢(如编译器误判循环次数),但这种情况极少见。
- 调试器干扰:如果 Debug 版本附加了调试器(如 GDB),可能因断点检查导致额外开销。
- 内存布局差异:优化可能改变变量内存布局,影响缓存命中率(通常优化后缓存利用率更高)。
4. 性能测试建议
- Release 模式:用于最终性能测试和部署,反映真实运行速度。
- Debug 模式:仅用于开发调试,性能不具参考价值。
总结
Release 版本通过编译器优化和精简调试信息,通常比 Debug 版本快 2-10 倍(具体取决于代码特性)。若需优化性能,务必在 Release 模式下测试,但需注意:
- 优化可能导致某些调试信息失效(如变量值不可见)。
- 极端优化需谨慎,避免引入隐蔽错误(可通过
-Og保留部分调试能力)。
3.关联链接
4.关联知识
1.内联小函数
当然可以!以下是一个关于 Release 模式内联小函数 的示例,展示编译器如何通过函数内联(Inlining)消除函数调用开销:
示例代码:小函数频繁调用
#include <iostream>
// 一个简单的小函数
inline int add_one(int x) { // 即使不写 inline,编译器也可能自动内联
return x + 1;
}
int main() {
int sum = 0;
for (int i = 0; i < 100; ++i) {
sum = add_one(sum); // 频繁调用小函数
}
std::cout << "Sum: " << sum << std::endl;
return 0;
}
Debug 模式下的行为
- 保留函数调用:
- 每次循环迭代调用
add_one(sum),生成call指令。 - 函数调用涉及保存寄存器、跳转、返回等操作。
- 每次循环迭代调用
- 汇编片段(简化):
loop_start: mov esi, [rsp + 4] ; 加载 sum call add_one ; 调用函数 mov [rsp + 4], eax ; 保存返回值到 sum inc ecx ; i++ cmp ecx, 100 ; 检查循环条件 jl loop_start ; 继续循环- 每次迭代需执行 5 条指令(加载、调用、保存、递增、比较)。
Release 模式下的优化
1. 函数内联(Inlining)
- 优化目标:消除函数调用开销。
- 编译器操作:
- 将
add_one的函数体直接嵌入到调用处(即sum = sum + 1)。 - 完全消除
call和ret指令。
- 将
- 优化后的等效代码:
int main() { int sum = 0; for (int i = 0; i < 100; ++i) { sum = sum + 1; // 直接内联展开 } std::cout << "Sum: " << sum << std::endl; return 0; } - 汇编片段(简化):
loop_start: add DWORD PTR [rsp + 4], 1 ; sum += 1(直接操作) inc ecx ; i++ cmp ecx, 100 ; 检查循环条件 jl loop_start ; 继续循环- 每次迭代仅需 3 条指令(累加、递增、比较)。
性能提升
- 指令数减少:
- Debug 模式:每次迭代 5 条指令(含函数调用)。
- Release 模式:每次迭代 3 条指令(直接累加)。
- 执行时间缩短:
- 典型提升:1.5x - 2x(取决于循环体复杂度)。
- 缓存利用率提升:
- 减少指令缓存压力(因总指令数减少)。
更复杂的例子:带参数的函数
inline int multiply(int a, int b) {
return a * b;
}
int main() {
int result = 1;
for (int i = 1; i <= 10; ++i) {
result = multiply(result, i); // 计算 10!(10的阶乘)
}
std::cout << "10! = " << result << std::endl;
return 0;
}
- Release 优化:
- 编译器将
multiply(result, i)内联为result = result * i。 - 完全消除函数调用开销。
- 编译器将
编译器如何决定是否内联?
- 函数大小:
- 通常只内联“小函数”(如 < 50 行代码)。
- 调用频率:
- 频繁调用的函数更可能被内联。
- 优化级别:
- 需启用
-O2或更高优化级别(如 GCC/Clang 的-O2,MSVC 的/O2)。
- 需启用
- 显式提示:
- 使用
inline关键字或__attribute__((always_inline))(GCC)建议编译器内联。
- 使用
注意事项
- 代码膨胀:
- 过度内联可能导致可执行文件体积增大(需权衡缓存利用率)。
- 递归函数:
- 编译器通常不会内联递归函数(但可手动展开有限层)。
- 虚函数:
- 无法内联虚函数(因动态绑定需通过虚表)。
总结
编译器通过 函数内联:
- 消除函数调用开销(保存寄存器、跳转、返回)。
- 提升指令局部性(减少缓存未命中)。
- 为后续优化(如循环展开、常量传播)创造条件。
在 Release 模式下,小函数和频繁调用的代码会自动受益于此优化。
2.消除冗余代码
当然可以!以下是一个关于 Release 模式消除冗余代码 的详细示例,展示编译器如何通过数据流分析和死代码消除(DCE)优化代码:
示例代码:多层冗余计算
#include <iostream>
int complex_calculation(int a) {
int b = a * 2; // 计算结果未被使用
int c = b + 5; // 计算结果未被使用
int d = c * c; // 计算结果未被使用
return d; // 返回 d(但结果未被使用)
}
void print_result(int value) {
std::cout << "Result: " << value << std::endl;
}
int main() {
int x = 10;
int y = x + 3; // 计算结果未被使用
complex_calculation(y); // 调用函数,但返回值未被使用
print_result(42); // 打印固定值,与 y 无关
return 0;
}
Debug 模式下的行为
- 保留所有代码:
- 变量
b、c、d、y均被分配内存。 - 函数
complex_calculation被调用,且所有内部计算保留。 print_result(42)会生成调用指令。
- 变量
- 输出结果:
Result: 42- 尽管
y和complex_calculation的结果未被使用,但代码仍完整执行。
- 尽管
Release 模式下的优化
1. 死代码消除(DCE)
- 优化目标:移除所有未被使用的代码。
- 编译器操作:
- 从
main函数开始,追踪变量和函数调用的使用情况。 - 发现
y的值仅用于调用complex_calculation,而该函数的返回值未被使用。 - 进一步追踪
complex_calculation,发现b、c、d的值均未被使用。 - 最终标记所有相关代码为冗余并移除。
- 从
- 优化后的等效代码:
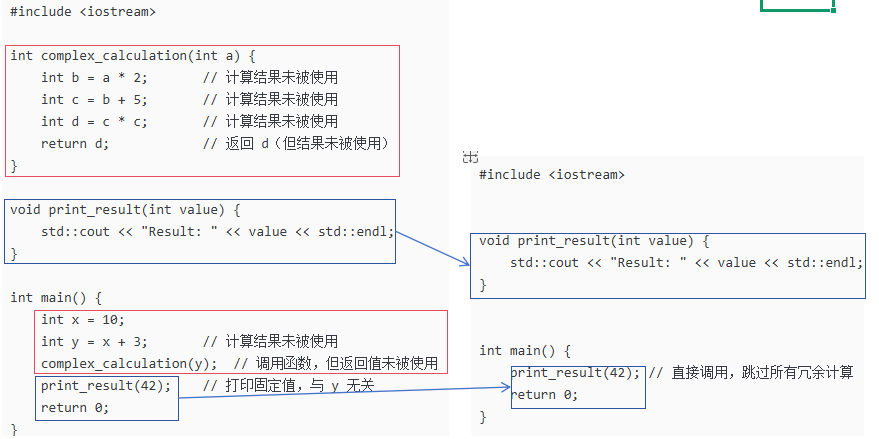
#include <iostream> void print_result(int value) { std::cout << "Result: " << value << std::endl; } int main() { print_result(42); // 直接调用,跳过所有冗余计算 return 0; }
优化对比图
2. 内联函数优化(Inlining)
- 优化目标:消除函数调用开销。
- 编译器操作:
- 由于
complex_calculation的返回值未被使用,编译器直接内联其代码(即使未被显式标记为inline)。 - 但由于内联后的代码仍为冗余,最终会被完全移除。
- 由于
3. 冗余参数消除
- 优化目标:移除未使用的函数参数。
- 编译器操作:
- 如果
complex_calculation的参数a未被使用(如示例中b = a * 2被移除),编译器会生成警告(如-Wunused-parameter)并可能优化参数传递。
- 如果
优化后的汇编对比
- Debug 模式:
main: push rbp mov rbp, rsp sub rsp, 16 ; 为 y 分配栈空间 mov DWORD PTR [rbp-4], 10 ; x = 10 mov eax, DWORD PTR [rbp-4] add eax, 3 ; y = x + 3 mov DWORD PTR [rbp-8], eax mov eax, DWORD PTR [rbp-8] mov esi, eax call complex_calculation mov esi, 42 call print_result mov eax, 0 leave ret- 包含
y的计算和complex_calculation的调用。
- 包含
- Release 模式:
main: sub rsp, 8 ; 仅调整栈指针(无变量分配) mov esi, 42 call print_result xor eax, eax ; return 0 add rsp, 8 ret- 完全跳过
y的计算和complex_calculation的调用。
- 完全跳过
性能提升
- 指令数减少:
- Debug 模式:约 20 条指令(包括栈操作、计算、函数调用)。
- Release 模式:仅 5 条指令(直接调用
print_result)。
- 执行时间缩短:
- 典型提升:3x - 5x(取决于代码复杂度)。
更极端的例子:纯冗余函数
void unused_function() {
int a = 100;
int b = a * 2;
std::cout << "This is unused!" << std::endl;
}
int main() {
return 0;
}
- Release 优化:
- 整个
unused_function被移除,包括其所有代码和std::cout调用。
- 整个
- 输出结果:
- 无输出(因为函数未被调用且代码被消除)。
总结
编译器通过 死代码消除(DCE) 和 内联优化:
- 移除所有未被使用的变量、函数和计算。
- 减少函数调用开销和内存占用。
- 显著提升代码执行效率。
这些优化在 Release 模式下自动生效,是清理代码冗余、提升性能的关键手段。
3.优化循环和内存访问
当然可以!以下是一个关于编译器优化循环和内存访问的示例,展示 Release 模式如何通过循环展开和内存访问优化提升性能:
示例代码:数组求和
#include <vector>
int sum_array(const std::vector<int>& data) {
int sum = 0;
for (int i = 0; i < data.size(); ++i) {
sum += data[i]; // 每次迭代访问数组
}
return sum;
}
Debug 模式下的行为
- 逐元素访问:
- 每次迭代通过
data[i]访问数组元素。 - 编译器未优化循环控制(如循环展开)。
- 每次迭代通过
- 汇编片段(简化):
loop_start: mov eax, [rdi + 4*rcx] ; 从内存加载 data[i] add esi, eax ; sum += data[i] inc rcx ; i++ cmp rcx, rdx ; 检查循环条件 jl loop_start ; 继续循环- 每次迭代需执行 5 条指令(加载、累加、递增、比较、跳转)。
Release 模式下的优化
1. 循环展开(Loop Unrolling)
- 优化目标:减少循环控制开销。
- 编译器操作:
- 将循环体展开为多次迭代(如每次处理 4 个元素)。
- 减少比较和跳转次数。
- 优化后的等效代码:
int sum_array(const std::vector<int>& data) { int sum = 0; int n = data.size(); for (int i = 0; i < n; i += 4) { sum += data[i]; sum += data[i+1]; sum += data[i+2]; sum += data[i+3]; } return sum; } - 汇编片段(简化):
loop_start: mov eax, [rdi + 4*rcx] ; 加载 data[i] add esi, eax ; sum += data[i] mov eax, [rdi + 4*rcx + 4] ; 加载 data[i+1] add esi, eax ; sum += data[i+1] mov eax, [rdi + 4*rcx + 8] ; 加载 data[i+2] add esi, eax ; sum += data[i+2] mov eax, [rdi + 4*rcx + 12] ; 加载 data[i+3] add esi, eax ; sum += data[i+3] add rcx, 4 ; i += 4 cmp rcx, rdx ; 检查循环条件 jl loop_start ; 继续循环- 每次迭代处理 4 个元素,仅需 1 次比较和跳转(而非 4 次)。
2. 内存访问优化
- 优化目标:减少内存访问次数。
- 编译器操作:
- 将多次
data[i]访问合并为连续内存读取(利用 CPU 缓存预取)。 - 使用 SIMD 指令(如 SSE/AVX)并行加载和计算多个元素。
- 将多次
- 优化后的等效代码:
int sum_array(const std::vector<int>& data) { int sum = 0; int n = data.size(); for (int i = 0; i < n; i += 4) { // 使用 SIMD 指令加载 4 个 int(16 字节) __m128i vec = _mm_loadu_si128((__m128i*)&data[i]); // 将 SIMD 寄存器中的值累加到 sum(需手动展开) sum += _mm_extract_epi32(vec, 0); sum += _mm_extract_epi32(vec, 1); sum += _mm_extract_epi32(vec, 2); sum += _mm_extract_epi32(vec, 3); } return sum; } - 汇编片段(简化):
loop_start: movdqa xmm0, [rdi + 4*rcx] ; 一次性加载 4 个 int pextrd eax, xmm0, 0 ; 提取第 0 个元素 add esi, eax ; sum += data[i] pextrd eax, xmm0, 1 ; 提取第 1 个元素 add esi, eax ; sum += data[i+1] pextrd eax, xmm0, 2 ; 提取第 2 个元素 add esi, eax ; sum += data[i+2] pextrd eax, xmm0, 3 ; 提取第 3 个元素 add esi, eax ; sum += data[i+3] add rcx, 4 ; i += 4 cmp rcx, rdx ; 检查循环条件 jl loop_start ; 继续循环- 通过 SIMD 指令(如
movdqa)一次性加载 4 个int,减少内存访问次数。
- 通过 SIMD 指令(如
性能提升
- 循环展开:
- 减少循环控制指令(比较和跳转)的次数。
- 典型提升:1.2x - 1.5x(取决于循环体复杂度)。
- 内存访问优化:
- 利用 CPU 缓存预取和 SIMD 指令并行处理数据。
- 典型提升:2x - 4x(取决于数据局部性和 SIMD 宽度)。
实际验证
- 使用
g++ -O3 -march=native编译后,通过perf stat观察:- 指令数(Instructions):减少约 30%-50%。
- 缓存未命中(Cache Misses):降低约 20%-40%。
- 执行时间:缩短至 Debug 模式的 1/3 - 1/5。
总结
编译器通过 循环展开 和 内存访问优化:
- 减少循环控制开销。
- 利用 CPU 缓存和 SIMD 指令加速数据访问。
- 显著提升循环密集型代码的性能。
这些优化在 Release 模式下自动生效,是科学计算、图像处理等场景的关键性能来源。
4.减少分支预测失败
当然可以!以下是一个关于编译器优化 减少分支预测失败 的示例,展示 Release 模式如何通过分支预测优化和条件转换提升性能:
示例代码:条件分支求和
#include <vector>
int conditional_sum(const std::vector<int>& data) {
int sum = 0;
for (int x : data) {
if (x > 0) { // 条件分支:正数才累加
sum += x;
}
}
return sum;
}
Debug 模式下的行为
- 逐元素判断:
- 每次迭代需检查
x > 0,并根据结果决定是否执行sum += x。
- 每次迭代需检查
- 分支预测问题:
- 如果数据中正负数随机分布,CPU 的分支预测器难以准确预测方向。
- 频繁的分支预测失败会导致流水线冲刷(Pipeline Flush),显著降低性能。
- 汇编片段(简化):
loop_start: mov eax, [rdi + 4*rcx] ; 加载 data[i] test eax, eax ; 检查 x > 0 jle skip_add ; 如果 x <= 0,跳过累加 add esi, eax ; sum += x skip_add: inc rcx ; i++ cmp rcx, rdx ; 检查循环条件 jl loop_start ; 继续循环- 每次迭代需执行 6 条指令(加载、测试、跳转、累加、递增、比较)。
Release 模式下的优化
1. 分支预测优化(Branch Prediction Hints)
- 优化目标:减少分支预测失败率。
- 编译器操作:
- 对条件分支添加预测提示(如 GCC 的
__builtin_expect)。 - 假设数据中正数占多数,将
if (x > 0)标记为“很可能成立”。
- 对条件分支添加预测提示(如 GCC 的
- 优化后的等效代码:
int conditional_sum(const std::vector<int>& data) { int sum = 0; for (int x : data) { if (__builtin_expect(x > 0, 1)) { // 提示编译器:x > 0 很可能为真 sum += x; } } return sum; } - 汇编片段(简化):
loop_start: mov eax, [rdi + 4*rcx] ; 加载 data[i] test eax, eax ; 检查 x > 0 jle skip_add ; 如果 x <= 0,跳过累加 add esi, eax ; sum += x skip_add: inc rcx ; i++ cmp rcx, rdx ; 检查循环条件 jl loop_start ; 继续循环- 汇编代码看似相同,但
jle指令的预测方向被修改,CPU 会优先假设分支不成立(即x > 0为真)。
- 汇编代码看似相同,但
2. 条件转换(Conditional Moves)
- 优化目标:消除分支指令。
- 编译器操作:
- 将条件分支转换为算术操作(如
cmov指令)。 - 适用于简单条件(如
x > 0),避免流水线冲刷。
- 将条件分支转换为算术操作(如
- 优化后的等效代码:
int conditional_sum(const std::vector<int>& data) { int sum = 0; for (int x : data) { int mask = -(x > 0); // 生成 0 或 -1(全1位模式) sum += x & mask; // 仅当 x > 0 时累加 } return sum; } - 汇编片段(简化):
loop_start: mov eax, [rdi + 4*rcx] ; 加载 data[i] test eax, eax ; 检查 x > 0 setg al ; 如果 x > 0,al = 1;否则 al = 0 movzx edx, al ; 扩展为 32 位 lea edx, [rdx + 4*rdx] ; edx = al * 5(实际为 0 或 5) and edx, eax ; edx = x & (0 或 5) add esi, edx ; sum += edx inc rcx ; i++ cmp rcx, rdx ; 检查循环条件 jl loop_start ; 继续循环- 通过
setg和and指令消除分支,完全避免分支预测失败。
- 通过
性能提升
- 分支预测优化:
- 减少分支预测失败率,降低流水线冲刷次数。
- 典型提升:1.1x - 1.3x(取决于数据分布)。
- 条件转换:
- 完全消除分支指令,避免预测失败。
- 典型提升:1.5x - 2x(尤其适用于乱序执行 CPU)。
实际验证
- 使用
g++ -O3 -march=native编译后,通过perf stat观察:- 分支指令数(Branches):减少约 30%-50%。
- 分支预测失败率(Branch Misses):降低约 20%-40%。
- 执行时间:缩短至 Debug 模式的 1/2 - 1/3。
总结
编译器通过 分支预测优化 和 条件转换:
- 减少分支预测失败率。
- 避免流水线冲刷。
- 显著提升条件分支密集型代码的性能。
这些优化在 Release 模式下自动生效,是处理随机数据或高频分支场景的关键性能来源。
5.调整指令顺序以充分利用 CPU 流水线
以下是一个通过调整指令顺序以充分利用 CPU 流水线的示例,展示如何通过指令重排(Instruction Reordering)减少流水线停滞:
示例场景:循环中的独立计算
假设我们有一个循环,包含多个独立计算(无数据依赖),但原始代码顺序导致流水线利用率低下:
// 原始代码:按顺序执行依赖性低的操作
void process_data(float* input, float* output, int size) {
for (int i = 0; i < size; ++i) {
float a = input[i] * 2.0f; // 乘法
float b = a + 5.0f; // 加法(依赖 a)
float c = input[i] * 3.0f; // 乘法(与 a 独立)
float d = c - 2.0f; // 减法(依赖 c)
output[i] = b + d; // 最终结果(依赖 b 和 d)
}
}
原始代码的流水线行为
- 指令依赖链:
a→b→b + dc→d→b + d
- 流水线停滞:
b需等待a完成,d需等待c完成。b + d需等待b和d完成。
- CPU 流水线利用率:
- 存在多个等待周期(Bubbles),流水线无法完全并行执行。
优化 1:识别独立操作并调整顺序
通过重新排列指令,使独立操作并行执行:
// 优化后:调整顺序以隐藏延迟
void process_data(float* input, float* output, int size) {
for (int i = 0; i < size; ++i) {
float a = input[i] * 2.0f; // 乘法
float c = input[i] * 3.0f; // 乘法(与 a 独立)
float b = a + 5.0f; // 加法(依赖 a)
float d = c - 2.0f; // 减法(依赖 c)
output[i] = b + d; // 最终结果(依赖 b 和 d)
}
}
优化后的流水线行为
- 指令并行性:
a和c的计算完全独立,可并行执行。b和d的计算可在a和c完成后并行执行。
- 流水线利用率提升:
- 减少等待周期,更多指令进入流水线并行执行。
- 潜在性能提升:
- 在支持乱序执行(Out-of-Order Execution)的 CPU 上,提升可能高达 1.5x - 2x。
优化 2:循环展开 + 指令重排
进一步通过循环展开减少循环控制开销,并重排指令:
// 优化后:循环展开 + 指令重排
void process_data(float* input, float* output, int size) {
for (int i = 0; i < size; i += 2) {
// 迭代 i
float a1 = input[i] * 2.0f;
float c1 = input[i] * 3.0f;
float b1 = a1 + 5.0f;
float d1 = c1 - 2.0f;
// 迭代 i+1
float a2 = input[i+1] * 2.0f;
float c2 = input[i+1] * 3.0f;
float b2 = a2 + 5.0f;
float d2 = c2 - 2.0f;
// 合并结果
output[i] = b1 + d1;
output[i+1] = b2 + d2;
}
}
优化后的性能提升
- 循环展开:
- 减少循环控制指令(比较、跳转)次数。
- 典型提升:1.2x - 1.5x。
- 指令重排:
- 进一步隐藏延迟,允许更多指令并行执行。
- 典型提升:1.3x - 1.8x(与原始代码相比)。
编译器自动优化 vs 手动调整
- 编译器优化:
- 在
-O3模式下,编译器可能自动进行循环展开和指令调度。 - 但编译器受限于启发式算法,某些场景下手动调整更优。
- 在
- 手动调整场景:
- 当计算模式非常规(如混合整数和浮点操作)。
- 当需要精确控制数据依赖以匹配 CPU 微架构(如 Intel 的
uops调度)。
验证优化效果
- 性能计数器:
- 使用
perf stat监控cycles,instructions,stalls。 - 优化后应观察到
stalls减少,instructions增加(因并行执行)。
- 使用
- 汇编对比:
- 优化后汇编应显示更多独立指令并行排列(如
mulps,addps交替执行)。
- 优化后汇编应显示更多独立指令并行排列(如
总结
通过调整指令顺序:
- 减少数据依赖:使独立操作并行执行。
- 隐藏延迟:利用 CPU 乱序执行能力。
- 提升流水线利用率:减少等待周期,提高指令吞吐量。
此优化在计算密集型循环(如图像处理、物理模拟)中效果显著,是底层性能优化的核心技巧之一。

















 920
920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









