







引言
网络是容器之间通信的基础,而Kubernetes并没有提供开箱即用的网络连接功能。相反,它提出了两个基本要求:
- Pod可以与任何其他节点上的所有其他Pod进行通信,无需网络地址转换(NAT)。
- 节点上的代理(例如系统守护进程、kubelet)可以与该节点上的所有Pod进行通信。
这些网络功能的实现通常依赖于CNI插件。
IP地址管理(IPAM)
Kubernetes的网络模型要求每个Pod都有一个唯一的IP地址。管理和分配这些IP地址的职责由IP地址管理(IPAM)承担,它是CNI插件的重要组成部分。
一种常见的IPAM实现方式是为每个节点分配一个无类别域间路由(CIDR),然后在该CIDR内分配Pod的IP地址。
例如,为每个节点设置CIDR:
apiVersion: v1
kind: Node
metadata:
name: node01
spec:
podCIDR: 192.168.1.0/24
podCIDRs:
- 192.168.1.0/24
---
apiVersion: v1
kind: Node
metadata:
name: node02
spec:
podCIDR: 192.168.2.0/24
podCIDRs:
- 192.168.2.0/24
在这个例子中:
- node01的podCIDR是192.168.1.0/24(地址范围:192.168.1.0 ~ 192.168.1.255),因此该节点的Pod IP范围是192.168.1.1 ~ 192.168.1.254(第一个和最后一个地址保留用于其他目的)。
- node02的podCIDR是192.168.2.0/24(地址范围:192.168.2.0 ~ 192.168.2.255),因此该节点的Pod IP范围是192.168.2.1 ~ 192.168.2.254。
这本质上是为每个节点分配了一个小子网,同一节点上的所有Pod IP都在同一子网内。
注意!这只是IPAM的一种可能实现方式。不同的CNI插件可能提供其他实现方式。
Linux虚拟以太网(VETH)和网桥
Pod的IP地址分配好后,下一个挑战是如何在集群内实现通信。
Linux提供了多种虚拟网络接口类型来支持复杂的网络环境。其中,虚拟以太网(VETH)和网桥是两种关键类型。
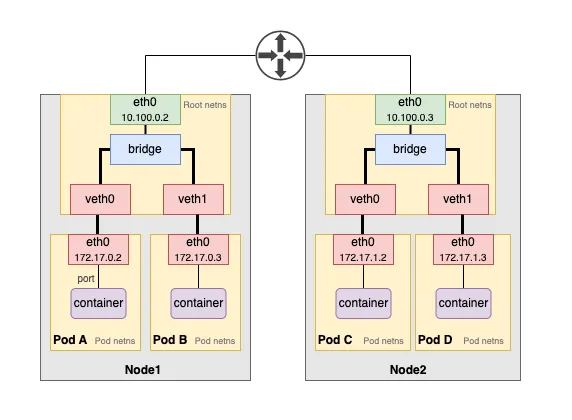
如上图所示,每个Pod都有自己的网络命名空间,通过一对VETH连接到根命名空间(主机网络命名空间)。然后使用一个网桥(通常命名为cni0或docker0)将所有VETH对连接在一起。
需要注意的是,VETH和网桥是独立的技术。如果我们使用一对VETH直接连接两个Pod,这些Pod可以相互通信。然而,随着Pod数量的增加,仅使用VETH对会导致数量难以管理,这就是使用网桥的原因之一。
同一节点上Pod之间的通信很直接,VETH对和网桥在本地处理。
但是,当通信跨节点时会发生什么呢?我们可能会认为网桥会简单地将流量转发到根命名空间的eth0物理网络接口。真的这么简单吗?
当然不是!节点可能是虚拟机或物理机,通过虚拟网络或物理路由器和交换机连接。关键问题是:连接节点的网络设备(虚拟/物理的 路由器/交换机/其他设备)能否直接路由Pod的MAC/IP地址?(对节点IP进行路由是自然的,但节点内Pod的IP怎么路由呢?)
如果答案是肯定的,那么CNI插件可以仅使用VETH和网桥在集群内实现完整的容器网络。这是本文讨论的第一种CNI网络模型。在Cilium中,这种模型称为Native-Routing,而在Flannel中,它被称为host-gw模式。
Overlay覆盖网络
如前所述,如果节点之间的路由设备无法路由Pod的IP地址,我们如何确保集群范围内的通信呢?答案是使用覆盖网络。
由于节点之间可以通信(节点IP是可路由的),原始数据包在传输前会被封装,例如使用VXLAN封装:
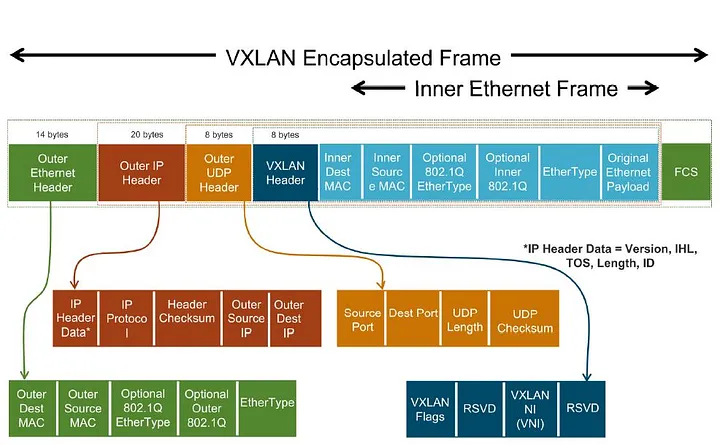
如所示,原始的Pod IP地址被封装在内部以太网帧内,节点IP地址添加到外层。由于节点IP是可路由的,数据包被转发到目标节点,在那里它被解封装,并根据内部的Pod IP转发到正确的Pod。
覆盖网络通过在现有网络之上封装额外的网络层,允许Pod跨节点通信。
覆盖网络可以通过多种方式实现,VXLAN是一种常见的方法。其他方法包括IP-in-IP等。Linux内核直接支持VXLAN,不过不同的CNI插件可能在内核之外实现自己的VXLAN封装和解封装方法。
这是本文讨论的第二种CNI网络模型:覆盖网络。
边界网关协议(BGP)
在多集群或混合云场景中,有时集群内的Pod需要对外可访问。在这些情况下,边界网关协议(BGP)是一种解决方案。
BGP广泛用于大规模数据中心或骨干网络的路由。它允许不同的自治系统(AS)交换路由信息。
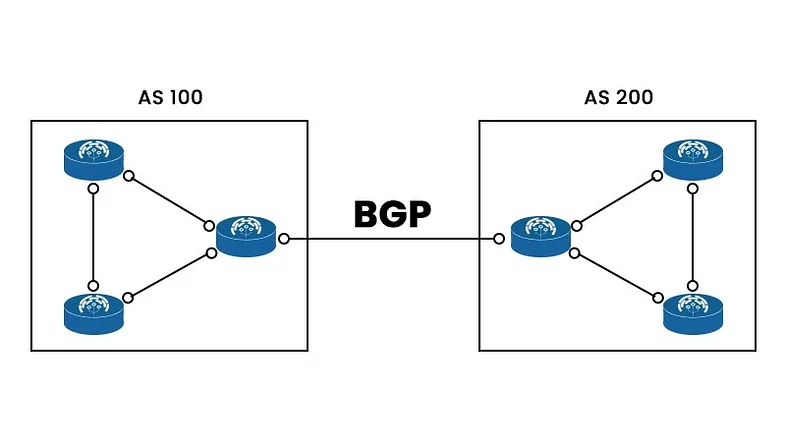
在Kubernetes中,一个集群可以被视为一个AS,并且可以使用BGP来交换路由信息。这使得可以从集群外部直接路由到Pod,确保其外部可访问性。
鉴于BGP可以交换路由信息,那么使用BGP在集群内交换所有Pod的IP地址,从而直接使用第一种CNI模型(Native-Routing)是否可行呢?虽然可行,但由于BGP在数据路径中缺乏可编程性,不建议这样做。
结论
本文介绍了三种CNI网络模型:Native-Routing、覆盖网络和BGP。Native-Routing的前提是集群内的Pod IP必须是可路由的,但通常情况并非如此。因此,许多CNI插件使用VXLAN或IP-in-IP等技术实现覆盖网络以确保连接性。在更复杂的场景中,如多集群或混合云环境,可以使用BGP实现Pod的外部访问。
参考
- https://kubernetes.io/docs/concepts/services-networking/
- https://kubernetes.io/docs/concepts/cluster-administration/addons/
- https://developers.redhat.com/blog/2018/10/22/introduction-to-linux-interfaces-for-virtual-networking
- https://docs.cilium.io/en/stable/network/concepts/routing/
- https://docs.tigera.io/calico/latest/networking/configuring/vxlan-ipip
- https://github.com/flannel-io/flannel/blob/master/Documentation/backends.md


















 6776
6776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











